Duranta leaf curl virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_003029245.1 |
| Isolate |
Pakistan: Bhera |
| Release date |
2018/8/26 |
| Submitter |
Anwar,S., Tahir,M. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
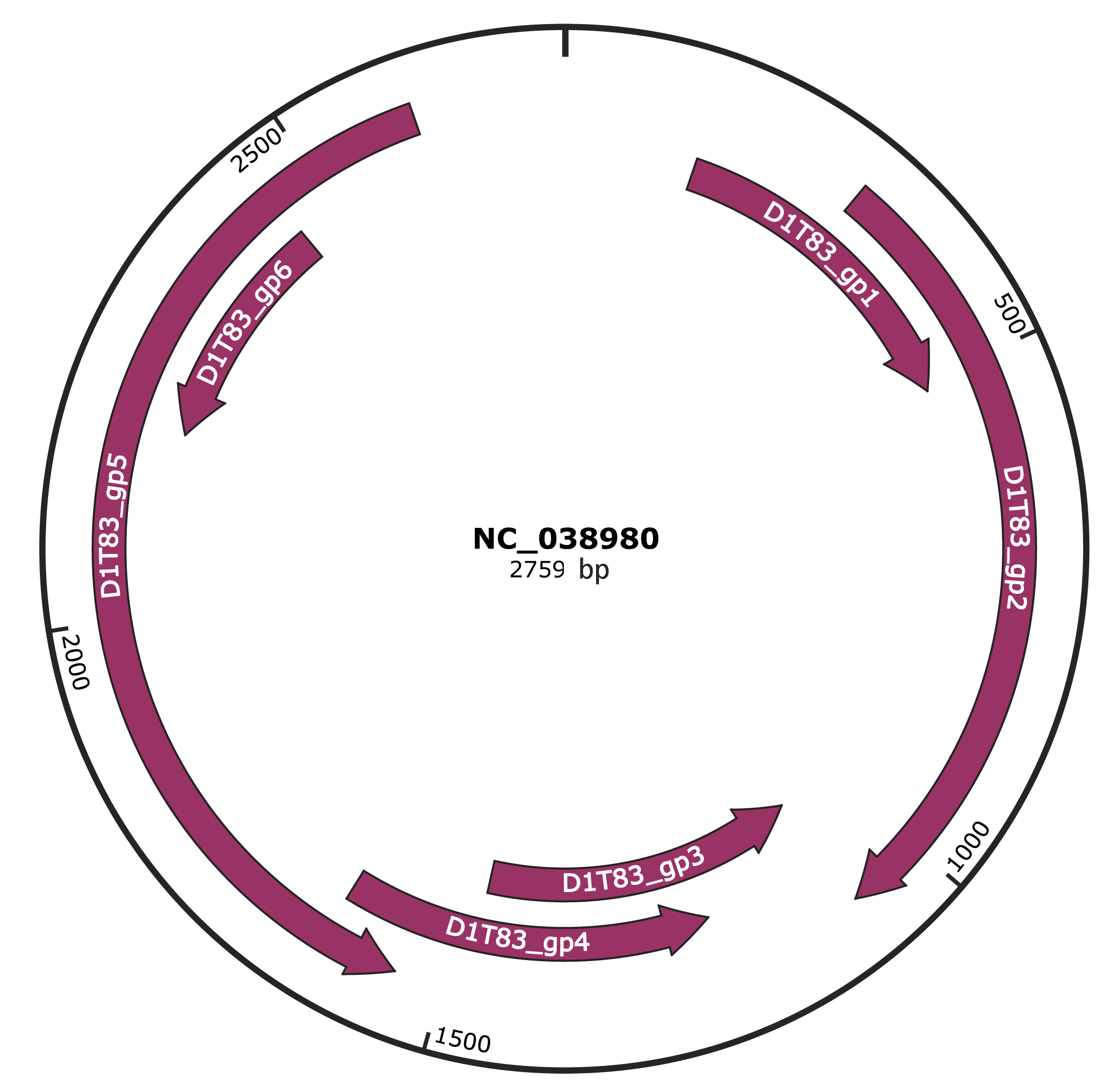
JBrowse
Genome
ACCGGATGGCCGCGATTTTTTTGTCCCCTCGTGGGTCCCACCAAGTGGTCCATGGACAAATGGCCCAATCAAAAGCACTTCTGAAAGCTTTATTGATGTGTGGGCCCCATATATAATGACTTGCTGAGTAAGTTTGTTGTAAACATGTGGGACCCACTATTGAATGAGTTCCCAGAAACTGTTCATGGGTTTAGGTGTATGCTAGCAATTAAATACTTGCAGCTAGTAGAAAATACGTATTCCCCAGATACTCTGGGATACGATTTAATTAGGGATTTGATTTCAGTTATTAGGGCTAGAAATTATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCCTCGAAGGTACGCCGCCGTCTCAACTTCGACAGCCCATATGCGAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACAAAGGCAAGGGCATGGGCGAACAGGCCCATGAACAGAAAGCCCAGGATATACAGGATGTACAGAAGCCCAGATGTTCCGAGGGGATGTGAAGGCCCATGCAAGGTCCAGTCATTTGAGTCCAGACATGATATCCAGCACATTGGTAAAGTCATGTGTGTTAGTGATGTTACTCGTGGTATTGGACTGACCCACAGGGTTGGCAAGAGGTTCTGTGTGAAGTCCGTTTATGTTCTGGGCAAGATCTGGATGGATGAGAACATCAAGACTAAGAATCATACGAATAGTGTTATGTTTTTCCTTGTACGTGATAGGCGTCCTGTTGACAAGCCTCAAGATTTTGGTGATGTGTTCAACATGTTTGATAATGAGCCCAGCACGGCGACTGTGAAGAATGTGCATCGTGATAGGTACCAGGTGCTTAGGAAGTGGCATGCAACGGTTACAGGCGGTCTGTATGCATCGAAGGAGCAGGCTCTCGTGAAGAAGTTTATTAGGGTTAATAATTATGTTGTGTACAACCAGCAAGAGGCTGGGAAATATGAGAATCATACTGAGAATGCATTGATGTTGTATATGGCGTGTACCCACGCCTCTAACCCTGTGTATGCTACACTGAAGATACGGATCTACTTCTATGATTCAGTATCGAATTAATAAATTTTAAATTTTATATCATGATCCTCAATTACATCAATTGTGTCATGGAGTACATCATATAGTACATGTTTAAATGCCCTAATACAATTATTTATACTAAGCACTCCTAATCTATCTAAATATCTTAAAACTTGAGTCTTAAAGACTCTTAAGAAATGCCCAGTCTGAGGATGTAAACGAGTGTGGATCCTCAAGCCCAAGAAACACTTCATTATCCCCAGTTCCTTCCTGATGTTGTGATTGAACTGGACCCTGATGTGGATGATGTCGTGGTTCATGTTGAGTGGCCTTTGGTCGTGGTCTGAGATCTTGAAATAAAGGGGATTTGGGACTTCCCAGATATACACGCCATTCATTGCTTGAGCTGCAGTGATGGATTCCCCTGTGCGTGAATCCATGGTTGTGGCAGTTGATGTGTACGTAGTATGAGCAGCCACACTCGAGGTCAACCCTCTTACGCCGGATGGCTCTACGCTTGGCTAGCCTGTGTTGGACCTTGATTGGTACCTGAGTACAGTGGCTCTGTGAGGGTGATGAATTCTGCATTCTTTATAGCCCACGACTTCAGTGCTGAGTTCTTTTCCTCCTCTAAGAACTCTTTATAGCTGGAGTTGGGCCCAGGATTGCATAGGAAGATAGTGGGAATACCACCTTTAATTTGAACTGGCTTCCCGTACTTTGTGTTGCTTTGCCAGTCCCTCTGGGCCCCCATGAACTCTTTAAAGTGCTTTAGATAGTGGGGGTCTACGTCATCAATGATGTTGTACCATGCATCATTTGAATAGATTTTAGGGCTCAGATCTAAATGGCCACATAAATAATTATGTGGACCCAGTGACCTAGCCCACATCGTCTTCCCCGTTCTACTATCACCCTCTATGACGATACTTTTAGGTCTCAAAGGCCGCGCAGCGGCACCCACCACATTTTCAGAGGCCCATTCCTCTATGGCCTCTGGGACTTGATCAAACGAAGAAGAAAGAAAAGGGGAAACATAAACCTCCATTGGAGGTGCAAAAATCCTATCTAAATTATTTTTTAAATTATGATATTGAAAAATAAAATCTTTAGGGAGTTTCTCCCTAATTATTGCTAAAGCTGCTTCAGCTGAACCTGCATTTAGCGCCTTTGCTGCAACATCATTAGCTGTCTGTTGACCTCCTCTAGCAGATCTTCCATCGATCTGAAACTGACCCCAGTCGATGTAATCACCGTCCTTCTCGATGTAGGACTTGACATCGGATGAGGACTTAGCTCCCTGGAAGTTTGGGTGGAATTGTGTGGATGTATTAGGGTGAGTGACATCGAAATGTCTGGGGTTTCTGAACTGGGATTTACCCTTGAACTGGATGAGGGCATGGATATGCAGAGACCCATCTTGGTGTTTTTCCTGTGACACTCTGATAAATAATTTATCAGAAGGACAAGAAATATTTTTAAGGAGTTCGAGCATTTGCTCTTTGGGTATTGGGCATTTTGGATAAGTGAGGAAGATATTTTTGGCTTTAACTTGGAACTGATGAGTACGAGGCATATTGAATTGGGTGCTCTCTAAAACTCTGAGGAATGGGGATCTTTGGGTGCCTATTTATATGGAGCACCCAAATGGCCTTTTCGTAATTTTGACATAAAATTCAAAATTCAAATTTCAAATCCCAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_009508378.1
|
|
Location
|
145-510 |
|
Protein Name
|
V2 |
|
Coding Region
|
ATGTGGGACCCACTATTGAATGAGTTCCCAGAAACTGTTCATGGGTTTAGGTGTATGCTAGCAATTAAATACTTGCAGCTAGTAGAAAATACGTATTCCCCAGATACTCTGGGATACGATTTAATTAGGGATTTGATTTCAGTTATTAGGGCTAGAAATTATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCCTCGAAGGTACGCCGCCGTCTCAACTTCGACAGCCCATATGCGAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACAAAGGCAAGGGCATGGGCGAACAGGCCCATGAACAGAAAGCCCAGGATATACAGGATGTACAGAAGCCCAGATGTTCCGAGGGGATGTGA |
|
Protein Sequence
|
MWDPLLNEFPETVHGFRCMLAIKYLQLVENTYSPDTLGYDLIRDLISVIRARNYVEATSRYNHFHARLEGTPPSQLRQPICEPCCCPHCPRHKGKGMGEQAHEQKAQDIQDVQKPRCSEGM |
|
NCBI Accession
|
YP_009508379.1
|
|
Location
|
305-1075 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCCTCGAAGGTACGCCGCCGTCTCAACTTCGACAGCCCATATGCGAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACAAAGGCAAGGGCATGGGCGAACAGGCCCATGAACAGAAAGCCCAGGATATACAGGATGTACAGAAGCCCAGATGTTCCGAGGGGATGTGAAGGCCCATGCAAGGTCCAGTCATTTGAGTCCAGACATGATATCCAGCACATTGGTAAAGTCATGTGTGTTAGTGATGTTACTCGTGGTATTGGACTGACCCACAGGGTTGGCAAGAGGTTCTGTGTGAAGTCCGTTTATGTTCTGGGCAAGATCTGGATGGATGAGAACATCAAGACTAAGAATCATACGAATAGTGTTATGTTTTTCCTTGTACGTGATAGGCGTCCTGTTGACAAGCCTCAAGATTTTGGTGATGTGTTCAACATGTTTGATAATGAGCCCAGCACGGCGACTGTGAAGAATGTGCATCGTGATAGGTACCAGGTGCTTAGGAAGTGGCATGCAACGGTTACAGGCGGTCTGTATGCATCGAAGGAGCAGGCTCTCGTGAAGAAGTTTATTAGGGTTAATAATTATGTTGTGTACAACCAGCAAGAGGCTGGGAAATATGAGAATCATACTGAGAATGCATTGATGTTGTATATGGCGTGTACCCACGCCTCTAACCCTGTGTATGCTACACTGAAGATACGGATCTACTTCTATGATTCAGTATCGAATTAA |
|
Protein Sequence
|
MSKRPADIIISTPASKVRRRLNFDSPYASRAAAPIVRVTKARAWANRPMNRKPRIYRMYRSPDVPRGCEGPCKVQSFESRHDIQHIGKVMCVSDVTRGIGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNSVMFFLVRDRRPVDKPQDFGDVFNMFDNEPSTATVKNVHRDRYQVLRKWHATVTGGLYASKEQALVKKFIRVNNYVVYNQQEAGKYENHTENALMLYMACTHASNPVYATLKIRIYFYDSVSN |
|
NCBI Accession
|
YP_009508380.1
|
|
Location
|
1072-1476 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAATCCATCACTGCAGCTCAAGCAATGAATGGCGTGTATATCTGGGAAGTCCCAAATCCCCTTTATTTCAAGATCTCAGACCACGACCAAAGGCCACTCAACATGAACCACGACATCATCCACATCAGGGTCCAGTTCAATCACAACATCAGGAAGGAACTGGGGATAATGAAGTGTTTCTTGGGCTTGAGGATCCACACTCGTTTACATCCTCAGACTGGGCATTTCTTAAGAGTCTTTAAGACTCAAGTTTTAAGATATTTAGATAGATTAGGAGTGCTTAGTATAAATAATTGTATTAGGGCATTTAAACATGTACTATATGATGTACTCCATGACACAATTGATGTAATTGAGGATCATGATATAAAATTTAAAATTTATTAA |
|
Protein Sequence
|
MDSRTGESITAAQAMNGVYIWEVPNPLYFKISDHDQRPLNMNHDIIHIRVQFNHNIRKELGIMKCFLGLRIHTRLHPQTGHFLRVFKTQVLRYLDRLGVLSINNCIRAFKHVLYDVLHDTIDVIEDHDIKFKIY |
|
NCBI Accession
|
YP_009508381.1
|
|
Location
|
1217-1624 |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCAGAATTCATCACCCTCACAGAGCCACTGTACTCAGGTACCAATCAAGGTCCAACACAGGCTAGCCAAGCGTAGAGCCATCCGGCGTAAGAGGGTTGACCTCGAGTGTGGCTGCTCATACTACGTACACATCAACTGCCACAACCATGGATTCACGCACAGGGGAATCCATCACTGCAGCTCAAGCAATGAATGGCGTGTATATCTGGGAAGTCCCAAATCCCCTTTATTTCAAGATCTCAGACCACGACCAAAGGCCACTCAACATGAACCACGACATCATCCACATCAGGGTCCAGTTCAATCACAACATCAGGAAGGAACTGGGGATAATGAAGTGTTTCTTGGGCTTGAGGATCCACACTCGTTTACATCCTCAGACTGGGCATTTCTTAAGAGTCTTTAA |
|
Protein Sequence
|
MQNSSPSQSHCTQVPIKVQHRLAKRRAIRRKRVDLECGCSYYVHINCHNHGFTHRGIHHCSSSNEWRVYLGSPKSPLFQDLRPRPKATQHEPRHHPHQGPVQSQHQEGTGDNEVFLGLEDPHSFTSSDWAFLKSL |
|
NCBI Accession
|
YP_009508382.1
|
|
Location
|
1548-2612 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGCCTCGTACTCATCAGTTCCAAGTTAAAGCCAAAAATATCTTCCTCACTTATCCAAAATGCCCAATACCCAAAGAGCAAATGCTCGAACTCCTTAAAAATATTTCTTGTCCTTCTGATAAATTATTTATCAGAGTGTCACAGGAAAAACACCAAGATGGGTCTCTGCATATCCATGCCCTCATCCAGTTCAAGGGTAAATCCCAGTTCAGAAACCCCAGACATTTCGATGTCACTCACCCTAATACATCCACACAATTCCACCCAAACTTCCAGGGAGCTAAGTCCTCATCCGATGTCAAGTCCTACATCGAGAAGGACGGTGATTACATCGACTGGGGTCAGTTTCAGATCGATGGAAGATCTGCTAGAGGAGGTCAACAGACAGCTAATGATGTTGCAGCAAAGGCGCTAAATGCAGGTTCAGCTGAAGCAGCTTTAGCAATAATTAGGGAGAAACTCCCTAAAGATTTTATTTTTCAATATCATAATTTAAAAAATAATTTAGATAGGATTTTTGCACCTCCAATGGAGGTTTATGTTTCCCCTTTTCTTTCTTCTTCGTTTGATCAAGTCCCAGAGGCCATAGAGGAATGGGCCTCTGAAAATGTGGTGGGTGCCGCTGCGCGGCCTTTGAGACCTAAAAGTATCGTCATAGAGGGTGATAGTAGAACGGGGAAGACGATGTGGGCTAGGTCACTGGGTCCACATAATTATTTATGTGGCCATTTAGATCTGAGCCCTAAAATCTATTCAAATGATGCATGGTACAACATCATTGATGACGTAGACCCCCACTATCTAAAGCACTTTAAAGAGTTCATGGGGGCCCAGAGGGACTGGCAAAGCAACACAAAGTACGGGAAGCCAGTTCAAATTAAAGGTGGTATTCCCACTATCTTCCTATGCAATCCTGGGCCCAACTCCAGCTATAAAGAGTTCTTAGAGGAGGAAAAGAACTCAGCACTGAAGTCGTGGGCTATAAAGAATGCAGAATTCATCACCCTCACAGAGCCACTGTACTCAGGTACCAATCAAGGTCCAACACAGGCTAGCCAAGCGTAG |
|
Protein Sequence
|
MPRTHQFQVKAKNIFLTYPKCPIPKEQMLELLKNISCPSDKLFIRVSQEKHQDGSLHIHALIQFKGKSQFRNPRHFDVTHPNTSTQFHPNFQGAKSSSDVKSYIEKDGDYIDWGQFQIDGRSARGGQQTANDVAAKALNAGSAEAALAIIREKLPKDFIFQYHNLKNNLDRIFAPPMEVYVSPFLSSSFDQVPEAIEEWASENVVGAAARPLRPKSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKIYSNDAWYNIIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLEEEKNSALKSWAIKNAEFITLTEPLYSGTNQGPTQASQA |
|
NCBI Accession
|
YP_009508383.1
|
|
Location
|
2198-2455 |
|
Protein Name
|
C4 |
|
Coding Region
|
ATGGGTCTCTGCATATCCATGCCCTCATCCAGTTCAAGGGTAAATCCCAGTTCAGAAACCCCAGACATTTCGATGTCACTCACCCTAATACATCCACACAATTCCACCCAAACTTCCAGGGAGCTAAGTCCTCATCCGATGTCAAGTCCTACATCGAGAAGGACGGTGATTACATCGACTGGGGTCAGTTTCAGATCGATGGAAGATCTGCTAGAGGAGGTCAACAGACAGCTAATGATGTTGCAGCAAAGGCGCTAA |
|
Protein Sequence
|
MGLCISMPSSSSRVNPSSETPDISMSLTLIHPHNSTQTSRELSPHPMSSPTSRRTVITSTGVSFRSMEDLLEEVNRQLMMLQQRR |