Dolichos yellow mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_001343705.1 |
| Isolate |
India |
| Release date |
2015/10/17 |
| Submitter |
Akram,M., Naimuddin, Agnihotri,A.K., Gupta,S. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
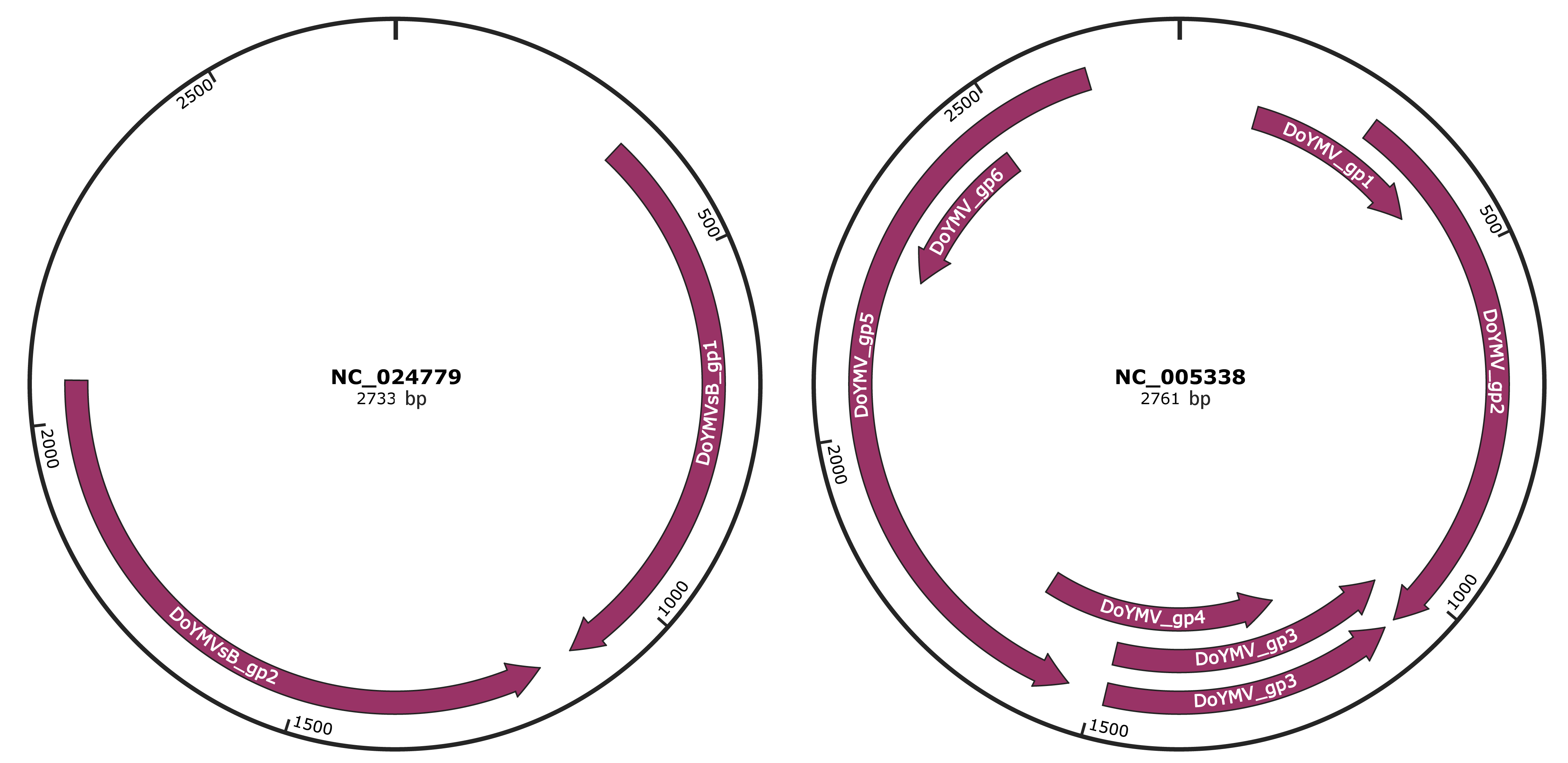
JBrowse
Genome
ACCGGATGGCCGCCCGGTGTCTTTGGTGTCGTGGGCCCCACACGTACGAACTGCTGTCGTGGCGCACTCTCGTTGCGTCCTGGAGGCTATTTTACGCACTCAACGCGGTCCCCACTAAATTCAATTCAAAGTGCGCCTTTGAATTGTCCATTTTGCCCTTCTCATCTTTTCCCATATCAAAGGCACCATTCGTGAGATAGGGGTATCGAACGTCCATCTAAAAACTATGACCGATATGACCGGTAGCCCTTTCCCACAACATGCAACGCCCATTTCTTCTTTAAATACCCGTTCTTAATAAGAACGGTCGTTCATATGTCATATCGGCATGTATCGCTCACGATCAACTCCCCTATCTGCTCGACGACCTCTGGTCAACCCGTTCGTCCGAGAACGGCAATTTGTTCCTCGTCGAACACCACGTTTTTTCAGAAAACGAGTTCATGCGACTCATCGTACGAGTCGCCGCCTATCTTACGAAAGAGTTGATCGTCCTATGTCCTTCAATGTCGTCGTTGAACGCCAACATGGTGATCATATGGCCCTGGTGAATAACCAGGACATTACATCTTTTATTGGCTATCCTATTCGTGGGTTCAACGAGGGACGATGCAGAGACTATATCAAGCTTCTGACACTCAATGTGTCAGGTATGATAACAGTCCGTTCGTTATCGACTGACGCCCCTATGTCCAGTAATGGCATCGTCAACGGAACCTTTGTTCTCTCGTTCGTATTGGACAAGAAGCCATATCTCCCTGATGGCGTTAACACGCTGCCCTCATTTGCGGAGCTATTTGGTCCATTCTCAGCGGCGTATTTCAACTTACGCCTGCTGGATTCTCAAAGAGAGAGGTTCAGATTATTGGGCAGCGTAAAGAAACATGTGTCATGTGGCGCTGATGAAGTAGAAGTCCCGTTCAAGTTCAAGAGGACCTTGTCGACAACAAGGTCTACTATGTGGGCCACGTTCAAGGACGTGGATATGGGCAATAGTGGAGGAAATTATAGAAATATCAGCAAGAACGCCATTTTAGTTAGTTATGCATTCGTTTCAATGCATAACATAAAGTGTGAACCATATGTACAATACGAACTGTCATATTTTGGTTAATAAAATCTCATTTTATTACATATCTTATTTATATCGTTGCTACACAATCACAACGCTTTACTGACATCAGTGCGTTGTTTTATCAAACATTTATTAACTGTCGACTCTACTATGTTCTCTATATCTGCCTTGGACAAATTCATCGAATTTGTTTGCGAAATTGAATCTCCGGGGTCTAATGATGTCTCGGGTAATTTGTGCAAGTGTCTAAGAGGAAACTCCGCGTCTGAATAAGTGTTCAGGCCCAATTCAGACTTTGGGCCTGATGTCGTATCCACGTCATATCGCATAGATGCGGATCTGCCAATCGTGGACCGCGTTGCCCAAGTCTCTCCTGGCATTAATTTGATCTGGTGGGCTCTTGGCCCATTAACAGCTGCGGGCTGGAGAAGCCTCCGAACAGCTTTGGGTTTGTCCACTGACCAGAAATCTACACAATCCTTTGTGTAGTTCTTTGACAGAATGTTAATCGTCGGAGGCTTGAAGGTTATGTCTGTGGAGTGTTTGGCTGACGACAATTTCAGCTTCGCCTTAATCTGTGCGAATGTCGTTCCGTCGACCACATTTGAGTCTTCCACTCTATACAAAAGCTCCCAGGGAGTCTCGTCCTTCAAGGAGAAGAAGGAGGAGGAAAAATAATGTAGGTCGACGTTGCAGCCTATGGGAAAGGTAAAAGCCGCCTGTGACGCCTCGTCGTCACTCAACCTGTTATCGCGTATGGTGACGATAACCGACCCCTTCGCATTAAAAGGCACCTGATTCCTGTATTCGATCACTATATGATCGACCTTCATGCACTTTCCCATCATTCGCACCTTTGTCTGCTCAAACGATGAAGGAAACTGAAGAGTGATCGGTGTCTCATTATTCGTCAGCCGATATTCACAGCGCTTGGACTCTATATAGCGGTTGTTCACGACCGCGCCGTTGAATGCTTCCATTTCAGAAAATATGCGAGAATCGCCCCTATGCTGTGAATCCTGTTAAATGCATCACAATCGAAAACAGAATGAGTAATAACTATTACGAATCTATCTAAGAACACGCATATTCACTAATCTGCCCTAATCGATGCATTTCTTTAACCTAGGCCGCGCAGCGGAAACCCTAGATTGTTCGATTGCCCTCTTTCATATGAACAATCCATCTAATTAAAAGCTAAGAACGATCATAATCCATGTCAACATAAGCAAAGAAAGACCATAAAGAAGAATTAAAGAAGATTGCTCGCCAATCTTCTGTAGCTTATTACCAAATCTCCACTGAACTGATGCGGTAGCTGTTCATGCCATGCCCTATTTATAGAAAGTAAAGCAAATTCATACATTTGCGTCTCATGGTCTTAATTATGAAAATAAAGAAGTTTATTTTCTAAAATGCCCTTGCTGACTTGGTGTGCTCAGCACGACATTCATATGAAGCTACTGTGAAGAAATCGTTTTGACAAAACGCGGAAACGAAACGACACAGAAAGCTCGCGTTTTGCTATGCAGTGCCACGTCATCGGTGTATCGGTGTCGCTTCAAAGTTCCCAGAATTGGTGTCATTGGTGTCGCATATATAGGTACCCCTAATATATGCTATATGCGCATTTGGTTGCGGCCATCCGCTATAATATT
ACCGGATGGCCGCCCGCCCGCCACGTGTCTCAATCCTGGCGCTCCGTGGAGTCTTATTTAGCGCTCCCGGATTTCAAATTTCACTATAAAACTTGGTCGACAAGTTTTACACATCAATCTAAATGTGGGTCCCATTAGTCAATGACTTTCCTGACACACTGCATGGATTGCGGTGTATGTTAGCTGTGAAATTTGTGCAGGAATTATTGGAGAGCTATCCGCGTGACTCTAATGGGCGCATCCTATTGGAGGAACTAATCCGGGTGTTGCGTTGTAAACGTTATGCCAAAGCGCAATTTCGATATGGCGTTTTCTACTCCAAGACCCAGCGTACGGCGAAGGCTCAACTTCGACACCCCATCTGCAACACCGATGTCAGTTCGTCGAACTCCGAGCACCAGTCGTCGTAGAGCATGGACCAATCGTCCAATGAATCGCAAACCGCGCATATATCGTCTATATCGCTCACGCGATGTACCATATGGGTGCGAGGGACCATGTAAAGTTCAATCCTTTGAACAACGGCATGATATCAGTCATACTGGTAAGGTCCTGTGTGTTTCCGATGTCACTAGAGGAAACAACCTTACTCATCGTGTTGGTAAACGATTTTGTGTTAAATCTGTTTACATTATTGGCAAAATTTGGATGGACGAGAACATTAAGACAAAGAACCATACAAACACAGTCATGTTTTGGCTAGTTCGTGATCGACGACCTTTTGGAACCCCAATGGACTTAGGGCAAGTGTTCAACATGTATGATAATGAACCCTCGACCGCCACTATCAAAAACGATCTTCGTGATCGTTACCAAGTTTTACGTAAGTTCGATTCAACTGTCACCGGAGGTCAATATGCGTCGAGGGAAGCAAATGTTATCAAGAGATTTTGGCGTGTCAACAATTATGTGGTGTACAACCACCAAGAAGCTGCTAAGTATGAAAATCATACTGAAAATGCATTATTATTGTATATGGCATGTACTCATGCCTCAAACCCAGTGTATGCAACATTAAAGATCAGGATCTATTTCTATGATTCTATCTCAAATTAATAAAATCTCATTTTTATTAATATAACTTCCATTGTACATTAAATTCGAAATCAACAGCTTCGACTCGCTGAAATACATCATACAATACATATTCGCAACTGCGTAATACATTGTTCATCGAAATAATTCCTAAATTATTTAAAAATCTAAAAAGGAAGTTCCTGAATACATTCAAGATCCGCCCAGATTGCGGAGTCAATCGATGGTAAATCACTAAATCCAAGAATGCCTTGTGTATCCCCAACGCTTTCTTCAACCCGTGGTTGAACATTATGCGGATCTTGGTTCTGTGTTGGTTCGGATCGAACATGAATCCCTCGTGATGCTCCAGGATCTTGAAAGACAGGGGATTCTTTAGCTCCCAGATAAACACGCCACTCTGTAGTTGAGCTGCAGTGATGGATTCCCCTGTGCGTGAATCCGTCATTCCGGCAGTTGATATTCAGGTAATACGAACAGCCACAGGTCAGATCGATTCGCTTACGCCGAATCGTTTTGCGCTTCTTCGCTTGTCGATGCTGTGCCTTGATGCTCGGTAGAGAACAATGGCTGTTCGAGGGTGATGAAGACCGCATTCTTGTAAGCCCACTCCTTCAATGATTCGTTCTGTTCCTCATCAAGGAACTCTTTATAGGACGAACGTGGTCCTGGATTGCAAAGAAAGATGGTGGGTATCCCACCTTTAATTTGAGTGGGCTTACCGTATTTGATGTTGCTTTGCCAGTCCATCTGGGCCCCCATAAACTCTTTAAAATGCTTTAGATAATGCGGATCAACGTCATCAATGACGTTATACCAAGCATCATTTGAAAATATCTTAGGGCTAAGATCCAGGTGTCCACACATGTAATTATGGACTCCTAATGACCGTGCCCATAACGTCTTCCCTGTTCTTGTTGCTCCTTCAACAACGATGCTCATCGGTCTTCTCGGCCGCGCAGCGGGGTCGCTCCTCCACGAAGGATCAACAACGTTATTTTCTGCCCATTCTGTCATAACAGACGGCACTTGACTAAAGTCGGCAGGCTTGTAATATGACGTGTAAACTGCAATCGGAGGAGCGAATATTCGTTCAAGGTTACATCTCAGATTATGATACTGGAACACATAATTGTGTGGAAGTAATTCTTTGATAATGTTCAGAGCACCTTGAACCGTACCGGAATTCAACGCCGATGCTACAGCATCGTCAGCTGTCTGACGACCTCCTCTAGCAGATCGTCCGTCGATCTGAAATGTTCCCCAGTCGACGTAATCACCGTCCTTGGTGATGTAGGATTTGACATCAGATGAGCTCTTTGCTCCCTGGACATTTCCATGGAAAACCTGTGTGCTATGAGGATGGGTAAGGTCGAAATGTCTTGCATTTCGGAACTGGGCCTTACCCTTGAACTGGACGAGGGCATGGAGATGCATAGTCCCATCTTGATGTGCTTCTTGTGCCACTCTGATGAACAATTTGTCCGACGGACACTCGATGCGACAGAGCTGCTCGAGAGCTTCTTCCTTTGAGAGAGAGCATTTGGGGTAGGTCAGAAATATATTTCTGGCAGATATGCGGAAGCCTGGAGCTCTCATTTTTTAAATGAGACTAATGCCACGTCATCGGTGTATCGGTGTCGCTTCAAAGTTCCCAGAATTGGTGTCTTTGGTGTCGCATATATAGGGGTCTCTAATAAGGGGTACGGCCATCCGCAATAATATT
Gene Information
|
NCBI Accession
|
YP_009055065.1
|
|
Location
|
329-1114 |
|
Protein Name
|
BV1 |
|
Coding Region
|
ATGTATCGCTCACGATCAACTCCCCTATCTGCTCGACGACCTCTGGTCAACCCGTTCGTCCGAGAACGGCAATTTGTTCCTCGTCGAACACCACGTTTTTTCAGAAAACGAGTTCATGCGACTCATCGTACGAGTCGCCGCCTATCTTACGAAAGAGTTGATCGTCCTATGTCCTTCAATGTCGTCGTTGAACGCCAACATGGTGATCATATGGCCCTGGTGAATAACCAGGACATTACATCTTTTATTGGCTATCCTATTCGTGGGTTCAACGAGGGACGATGCAGAGACTATATCAAGCTTCTGACACTCAATGTGTCAGGTATGATAACAGTCCGTTCGTTATCGACTGACGCCCCTATGTCCAGTAATGGCATCGTCAACGGAACCTTTGTTCTCTCGTTCGTATTGGACAAGAAGCCATATCTCCCTGATGGCGTTAACACGCTGCCCTCATTTGCGGAGCTATTTGGTCCATTCTCAGCGGCGTATTTCAACTTACGCCTGCTGGATTCTCAAAGAGAGAGGTTCAGATTATTGGGCAGCGTAAAGAAACATGTGTCATGTGGCGCTGATGAAGTAGAAGTCCCGTTCAAGTTCAAGAGGACCTTGTCGACAACAAGGTCTACTATGTGGGCCACGTTCAAGGACGTGGATATGGGCAATAGTGGAGGAAATTATAGAAATATCAGCAAGAACGCCATTTTAGTTAGTTATGCATTCGTTTCAATGCATAACATAAAGTGTGAACCATATGTACAATACGAACTGTCATATTTTGGTTAA |
|
Protein Sequence
|
MYRSRSTPLSARRPLVNPFVRERQFVPRRTPRFFRKRVHATHRTSRRLSYERVDRPMSFNVVVERQHGDHMALVNNQDITSFIGYPIRGFNEGRCRDYIKLLTLNVSGMITVRSLSTDAPMSSNGIVNGTFVLSFVLDKKPYLPDGVNTLPSFAELFGPFSAAYFNLRLLDSQRERFRLLGSVKKHVSCGADEVEVPFKFKRTLSTTRSTMWATFKDVDMGNSGGNYRNISKNAILVSYAFVSMHNIKCEPYVQYELSYFG |
|
NCBI Accession
|
YP_009055066.1
|
|
Location
|
1162-2055 |
|
Protein Name
|
BC1 |
|
Coding Region
|
ATGGAAGCATTCAACGGCGCGGTCGTGAACAACCGCTATATAGAGTCCAAGCGCTGTGAATATCGGCTGACGAATAATGAGACACCGATCACTCTTCAGTTTCCTTCATCGTTTGAGCAGACAAAGGTGCGAATGATGGGAAAGTGCATGAAGGTCGATCATATAGTGATCGAATACAGGAATCAGGTGCCTTTTAATGCGAAGGGGTCGGTTATCGTCACCATACGCGATAACAGGTTGAGTGACGACGAGGCGTCACAGGCGGCTTTTACCTTTCCCATAGGCTGCAACGTCGACCTACATTATTTTTCCTCCTCCTTCTTCTCCTTGAAGGACGAGACTCCCTGGGAGCTTTTGTATAGAGTGGAAGACTCAAATGTGGTCGACGGAACGACATTCGCACAGATTAAGGCGAAGCTGAAATTGTCGTCAGCCAAACACTCCACAGACATAACCTTCAAGCCTCCGACGATTAACATTCTGTCAAAGAACTACACAAAGGATTGTGTAGATTTCTGGTCAGTGGACAAACCCAAAGCTGTTCGGAGGCTTCTCCAGCCCGCAGCTGTTAATGGGCCAAGAGCCCACCAGATCAAATTAATGCCAGGAGAGACTTGGGCAACGCGGTCCACGATTGGCAGATCCGCATCTATGCGATATGACGTGGATACGACATCAGGCCCAAAGTCTGAATTGGGCCTGAACACTTATTCAGACGCGGAGTTTCCTCTTAGACACTTGCACAAATTACCCGAGACATCATTAGACCCCGGAGATTCAATTTCGCAAACAAATTCGATGAATTTGTCCAAGGCAGATATAGAGAACATAGTAGAGTCGACAGTTAATAAATGTTTGATAAAACAACGCACTGATGTCAGTAAAGCGTTGTGA |
|
Protein Sequence
|
MEAFNGAVVNNRYIESKRCEYRLTNNETPITLQFPSSFEQTKVRMMGKCMKVDHIVIEYRNQVPFNAKGSVIVTIRDNRLSDDEASQAAFTFPIGCNVDLHYFSSSFFSLKDETPWELLYRVEDSNVVDGTTFAQIKAKLKLSSAKHSTDITFKPPTINILSKNYTKDCVDFWSVDKPKAVRRLLQPAAVNGPRAHQIKLMPGETWATRSTIGRSASMRYDVDTTSGPKSELGLNTYSDAEFPLRHLHKLPETSLDPGDSISQTNSMNLSKADIENIVESTVNKCLIKQRTDVSKAL |
|
NCBI Accession
|
YP_009029988.1
|
|
Location
|
123-410 |
|
Protein Name
|
AV2 |
|
Coding Region
|
ATGTGGGTCCCATTAGTCAATGACTTTCCTGACACACTGCATGGATTGCGGTGTATGTTAGCTGTGAAATTTGTGCAGGAATTATTGGAGAGCTATCCGCGTGACTCTAATGGGCGCATCCTATTGGAGGAACTAATCCGGGTGTTGCGTTGTAAACGTTATGCCAAAGCGCAATTTCGATATGGCGTTTTCTACTCCAAGACCCAGCGTACGGCGAAGGCTCAACTTCGACACCCCATCTGCAACACCGATGTCAGTTCGTCGAACTCCGAGCACCAGTCGTCGTAG |
|
Protein Sequence
|
MWVPLVNDFPDTLHGLRCMLAVKFVQELLESYPRDSNGRILLEELIRVLRCKRYAKAQFRYGVFYSKTQRTAKAQLRHPICNTDVSSSNSEHQSS |
|
NCBI Accession
|
YP_009029989.1
|
|
Location
|
283-1056 |
|
Protein Name
|
AV1 |
|
Coding Region
|
ATGCCAAAGCGCAATTTCGATATGGCGTTTTCTACTCCAAGACCCAGCGTACGGCGAAGGCTCAACTTCGACACCCCATCTGCAACACCGATGTCAGTTCGTCGAACTCCGAGCACCAGTCGTCGTAGAGCATGGACCAATCGTCCAATGAATCGCAAACCGCGCATATATCGTCTATATCGCTCACGCGATGTACCATATGGGTGCGAGGGACCATGTAAAGTTCAATCCTTTGAACAACGGCATGATATCAGTCATACTGGTAAGGTCCTGTGTGTTTCCGATGTCACTAGAGGAAACAACCTTACTCATCGTGTTGGTAAACGATTTTGTGTTAAATCTGTTTACATTATTGGCAAAATTTGGATGGACGAGAACATTAAGACAAAGAACCATACAAACACAGTCATGTTTTGGCTAGTTCGTGATCGACGACCTTTTGGAACCCCAATGGACTTAGGGCAAGTGTTCAACATGTATGATAATGAACCCTCGACCGCCACTATCAAAAACGATCTTCGTGATCGTTACCAAGTTTTACGTAAGTTCGATTCAACTGTCACCGGAGGTCAATATGCGTCGAGGGAAGCAAATGTTATCAAGAGATTTTGGCGTGTCAACAATTATGTGGTGTACAACCACCAAGAAGCTGCTAAGTATGAAAATCATACTGAAAATGCATTATTATTGTATATGGCATGTACTCATGCCTCAAACCCAGTGTATGCAACATTAAAGATCAGGATCTATTTCTATGATTCTATCTCAAATTAA |
|
Protein Sequence
|
MPKRNFDMAFSTPRPSVRRRLNFDTPSATPMSVRRTPSTSRRRAWTNRPMNRKPRIYRLYRSRDVPYGCEGPCKVQSFEQRHDISHTGKVLCVSDVTRGNNLTHRVGKRFCVKSVYIIGKIWMDENIKTKNHTNTVMFWLVRDRRPFGTPMDLGQVFNMYDNEPSTATIKNDLRDRYQVLRKFDSTVTGGQYASREANVIKRFWRVNNYVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSISN |
|
NCBI Accession
|
YP_009029990.1
|
|
Location
|
1073-1483 |
|
Protein Name
|
AC3 |
|
Coding Region
|
ATGACGGATTCACGCACAGGGGAATCCATCACTGCAGCTCAACTACAGAGTGGCGTGTTTATCTGGGAGCTAAAGAATCCCCTGTCTTTCAAGATCCTGGAGCATCACGAGGGATTCATGTTCGATCCGAACCAACACAGAACCAAGATCCGCATAATGTTCAACCACGGGTTGAAGAAAGCGTTGGGGATACACAAGGCATTCTTGGATTTAGTGATTTACCATCGATTGACTCCGCAATCTGGGCGGATCTTGAATGTATTCAGGAACTTCCTTTTTAGATTTTTAAATAATTTAGGAATTATTTCGATGAACAATGTATTACGCAGTTGCGAATATGTATTGTATGATGTATTTCAGCGAGTCGAAGCTGTTGATTTCGAATTTAATGTACAATGGAAGTTATATTAA |
|
Protein Sequence
|
MTDSRTGESITAAQLQSGVFIWELKNPLSFKILEHHEGFMFDPNQHRTKIRIMFNHGLKKALGIHKAFLDLVIYHRLTPQSGRILNVFRNFLFRFLNNLGIISMNNVLRSCEYVLYDVFQRVEAVDFEFNVQWKLY |
|
NCBI Accession
|
YP_009029991.1
|
|
Location
|
1203-1631 |
|
Protein Name
|
AC2 |
|
Coding Region
|
ATGCGGTCTTCATCACCCTCGAACAGCCATTGTTCTCTACCGAGCATCAAGGCACAGCATCGACAAGCGAAGAAGCGCAAAACGATTCGGCGTAAGCGAATCGATCTGACCTGTGGCTGTTCGTATTACCTGAATATCAACTGCCGGAATGACGGATTCACGCACAGGGGAATCCATCACTGCAGCTCAACTACAGAGTGGCGTGTTTATCTGGGAGCTAAAGAATCCCCTGTCTTTCAAGATCCTGGAGCATCACGAGGGATTCATGTTCGATCCGAACCAACACAGAACCAAGATCCGCATAATGTTCAACCACGGGTTGAAGAAAGCGTTGGGGATACACAAGGCATTCTTGGATTTAGTGATTTACCATCGATTGACTCCGCAATCTGGGCGGATCTTGAATGTATTCAGGAACTTCCTTTTTAG |
|
Protein Sequence
|
MRSSSPSNSHCSLPSIKAQHRQAKKRKTIRRKRIDLTCGCSYYLNINCRNDGFTHRGIHHCSSTTEWRVYLGAKESPVFQDPGASRGIHVRSEPTQNQDPHNVQPRVEESVGDTQGILGFSDLPSIDSAIWADLECIQELPF |
|
NCBI Accession
|
YP_009029992.1
|
|
Location
|
1537-2634 |
|
Protein Name
|
AC1 |
|
Coding Region
|
ATGAGAGCTCCAGGCTTCCGCATATCTGCCAGAAATATATTTCTGACCTACCCCAAATGCTCTCTCTCAAAGGAAGAAGCTCTCGAGCAGCTCTGTCGCATCGAGTGTCCGTCGGACAAATTGTTCATCAGAGTGGCACAAGAAGCACATCAAGATGGGACTATGCATCTCCATGCCCTCGTCCAGTTCAAGGGTAAGGCCCAGTTCCGAAATGCAAGACATTTCGACCTTACCCATCCTCATAGCACACAGGTTTTCCATGGAAATGTCCAGGGAGCAAAGAGCTCATCTGATGTCAAATCCTACATCACCAAGGACGGTGATTACGTCGACTGGGGAACATTTCAGATCGACGGACGATCTGCTAGAGGAGGTCGTCAGACAGCTGACGATGCTGTAGCATCGGCGTTGAATTCCGGTACGGTTCAAGGTGCTCTGAACATTATCAAAGAATTACTTCCACACAATTATGTGTTCCAGTATCATAATCTGAGATGTAACCTTGAACGAATATTCGCTCCTCCGATTGCAGTTTACACGTCATATTACAAGCCTGCCGACTTTAGTCAAGTGCCGTCTGTTATGACAGAATGGGCAGAAAATAACGTTGTTGATCCTTCGTGGAGGAGCGACCCCGCTGCGCGGCCGAGAAGACCGATGAGCATCGTTGTTGAAGGAGCAACAAGAACAGGGAAGACGTTATGGGCACGGTCATTAGGAGTCCATAATTACATGTGTGGACACCTGGATCTTAGCCCTAAGATATTTTCAAATGATGCTTGGTATAACGTCATTGATGACGTTGATCCGCATTATCTAAAGCATTTTAAAGAGTTTATGGGGGCCCAGATGGACTGGCAAAGCAACATCAAATACGGTAAGCCCACTCAAATTAAAGGTGGGATACCCACCATCTTTCTTTGCAATCCAGGACCACGTTCGTCCTATAAAGAGTTCCTTGATGAGGAACAGAACGAATCATTGAAGGAGTGGGCTTACAAGAATGCGGTCTTCATCACCCTCGAACAGCCATTGTTCTCTACCGAGCATCAAGGCACAGCATCGACAAGCGAAGAAGCGCAAAACGATTCGGCGTAA |
|
Protein Sequence
|
MRAPGFRISARNIFLTYPKCSLSKEEALEQLCRIECPSDKLFIRVAQEAHQDGTMHLHALVQFKGKAQFRNARHFDLTHPHSTQVFHGNVQGAKSSSDVKSYITKDGDYVDWGTFQIDGRSARGGRQTADDAVASALNSGTVQGALNIIKELLPHNYVFQYHNLRCNLERIFAPPIAVYTSYYKPADFSQVPSVMTEWAENNVVDPSWRSDPAARPRRPMSIVVEGATRTGKTLWARSLGVHNYMCGHLDLSPKIFSNDAWYNVIDDVDPHYLKHFKEFMGAQMDWQSNIKYGKPTQIKGGIPTIFLCNPGPRSSYKEFLDEEQNESLKEWAYKNAVFITLEQPLFSTEHQGTASTSEEAQNDSA |
|
NCBI Accession
|
YP_009029993.1
|
|
Location
|
2235-2480 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGACTATGCATCTCCATGCCCTCGTCCAGTTCAAGGGTAAGGCCCAGTTCCGAAATGCAAGACATTTCGACCTTACCCATCCTCATAGCACACAGGTTTTCCATGGAAATGTCCAGGGAGCAAAGAGCTCATCTGATGTCAAATCCTACATCACCAAGGACGGTGATTACGTCGACTGGGGAACATTTCAGATCGACGGACGATCTGCTAGAGGAGGTCGTCAGACAGCTGACGATGCTGTAG |
|
Protein Sequence
|
MGLCISMPSSSSRVRPSSEMQDISTLPILIAHRFSMEMSREQRAHLMSNPTSPRTVITSTGEHFRSTDDLLEEVVRQLTML |