Desmodium mottle virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_003029545.2 |
| Isolate |
Uganda |
| Release date |
2018/12/27 |
| Submitter |
Mollel,H.G., Sseruwagi,P., Ndunguru,J., Alicai,T., Colvin,J., Navas-Castillo,J., Fiallo-Olive,E. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
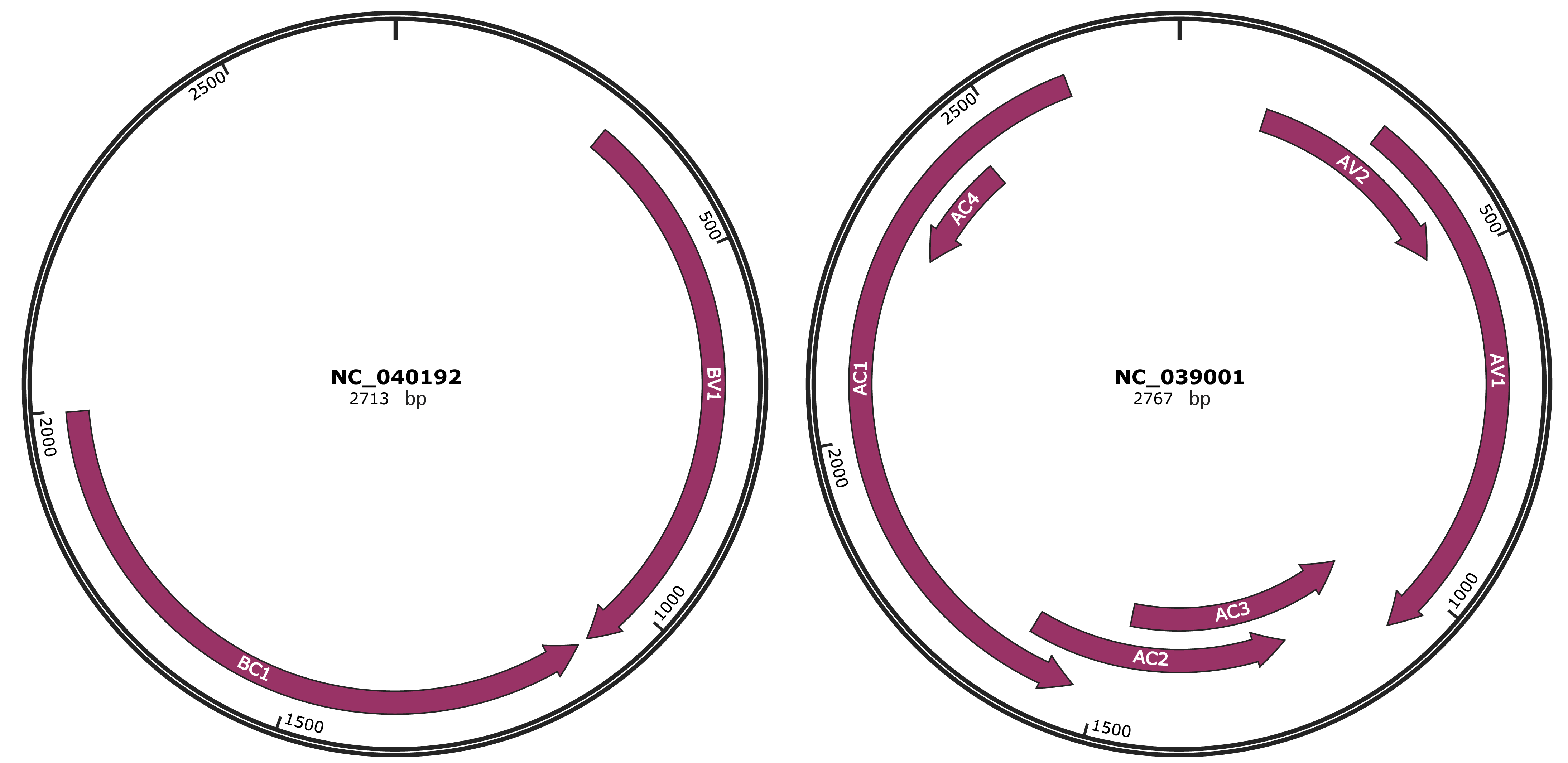
JBrowse
Genome
ACCGGATGGCCGCGCCCGCCCTTTTATAGTGGGCCCCACTCTGGTGGTCCCCTACCCCGCACTACTCCTACGTGTTACGCATCTGGCCGTTCATATTAAGTAGTTTGAATGTTATATTGTACGGTTTTGTCATGTAGTGCGGGTATTTTTTATATTGGTTCTCAATTAAGGCCGTGGATGTGTATTATTTTGTGCTCAAATTACTTTAGTTTTGCTCAGCAATAACCCTCATGCGTAAGATATTTTTTAACCAATATAAAAATGGAATTCGTTGCCGTGAGGTTCTATCACTGGGTAAATGTGGTCTCCTAGATTTAAGGGAAGACGGAGGTTTGACCGGTCTAAGGTTTCCGGTTACCGGATACCAACTACAACGCCTTCTAGGCGTTACAAGAGTCAAGGTTTTTCTCGTGGTGGTGTTTCTCGTTCTCTGACGTATGAACGTGTTGAGCGCCCGTTGGGCTACAAGTGTTTAATGGAACGACATCATGGTGATGCGTTCGCCTTGACCAGTAATTGTGATACTACGTCATTCATTAGTTACCCTGTACGTGCCCTCTCTGGAGAAGGACGTTCTCGTGACTACATTAAATTGCTAAGCATACGTGCATCAGGCGTCATTAATGTTAAAGGCCTGGTTAAACATGACGCCATGGAGAGGTCGACAAACTTCTCTGGCGTTTTTGTGATGGCGTTGGTGATGGACATGAAGCCATATTTGCCGGAAGGAAGCAACCAACTCCCCTCGTTTGTGGAGTTGTTTGGACCCTATTCATCTGCATATGTGACTCTTCGTTTGTTGGACAATCAAACCAGTAGGTTTAGGATACTAACGAGCGTGAGCAAAATGGTGTACACGCAGGACGATAGTAGAGTCCTCCAGTTTAAGTGTTATAGGCGTTTTACGCACTCGAGGTATCCCATATGGGCCTCATTTTACGACCATGACATCGGTAATAGTGGGGGAAATTATAGGAATATTTCTAGGAATGCGGTGTTAGTCAGCTATGCATTTGTATCGGAACAGTCGATGTCATGTGTACCATTTGTTCAATTGGAAACGCGTTATATTGGATAATTAAATGTTTACATTTACAAGTTTTTAAGGCTACTGCCTCTTTGTGCGATTAAGCACTTATTTACAGTTTGTTCTACAATGGACTCAATGTCCGCCTTGCTGAGCGCATTTGACGTTGTTTGGGAAATTGAATCTCCTGGGTCTAGTGATGCTTCAGGTAGCTTGTGCAGTCCTTGTAAGGGGAACTCCGCGTCGGAACAAGCACTCTGTGTGCGTAAGGTGGAACCCGTATGCATTGGTTGCGACGTTGTTAGTCGCATGGACGAAGACCTGCCTATAGTCGATTTGGTGGCCCATGTTTCACCGGGTTGTATTTGAACGGCCCGGTAATGCCCTGCAAGACTGGACTCTGTTGTTGGGCCTGGGTTAATGAGTCGCCTAATCGGTTTGGGCTTTCCAACGGACCAGAAGTCCACACAGTCCGCGTTGTAATCCTTTGAGAGGATTTTTATTGTGGGTTGCTTAAACCTTATGTCCGTTGAGTGCGTTGCGGATGATAACTTAAGCTTGGCCTTGATTTGCGCAAACGTTACTCCGTCCTTCACATTTGAGTCCTCTACTTTGTAAAATAACTCCCACGGTGCTTTATCTTCTAGGGAGAAGAAGGAGGCGGAGAAGTAATGTAGGTCGACATTACAGCCTATAGGAAATGTGAACTGGGCTTGGTCTTGTTGTTCTTCGCTAAGCCTTGTGTCACGGATTGTGACAATCACCGAGCCTTGGGCATTAAACGGAACCTGGTTACGGTATTCGATGATTACGTGGTCGACCTTCATGCATTTTCCCATTATTCGGACTCGTACCTTTTCCAGTGATGACGGGAATTGTAACGAAATTGGGGTTTCGTTATTTGTAAGTCTGTATTCAGACCTTGTGCTTTGAATGTATTCGCTATGCATCACTGGAATTGAAGTGTCCATGTCCCTGAAAACAAATATAAGCCCGTTAAAGGCAACTAGGATGTAGTCACATAGATGAAATGTGACCCCCCAAGGCAAATGTCCCTAAGCATGATTCTATTGTTTTCAATGGCCGCGCAGCGGAAATATTATGACATTTATCTCAGGCGGAGAATAATTACGGGAGTAATTATGCATTCATACAAATTTTGTACAGCTGTAATGTTGTCTTACGAATTGCATAGATTTTACCTCTTTGTTGCTCACAGATCCAGGTTGTACAGCTCGCGCAAGACGTGATGTCTTCTTCCTTATGCTTAATCCAAGCTCTGTGCAATTCGACATTAGTAACGTGTGCTTTTATACATCTCCATGTGTTTATTTATGGATCTGCCTGTAATTTTTATTGGTCGCGAATAAAAATTATAATGAACGTCGATTAATCCTTGCATATCATAACGCAAGGTGTTGTTGCGTTTTTACAAGTTTCTCTCTCCAGCGTAAAGCGAAATATCAAAACGCAAGGTTTGGTTGCGTTTTGCTAAGCGTCTCTCTCTAGCGCATCGCGCAAAAGCGTTTCTCTCTCTAGCGGAATGGCATTTTCGTGAATATGAGCGTGTACCCCCGATTCGAGCTCGCATTAAAATCCTGTGAATCGGGGGTACTGGGGGTACATTTATACCTCTTCCAAAACTCTCAAATAGCCACGTGGAAAGCGGCCATCCTATATAATATT
ACCGGATGGCCGCGCCCCCCCCCTTTTATAGTGGACCCCACATGCTCGCTAAAGAAGGACCGGGAAGGGTCCCTCAAGCGTTAGATATTTGTTTTGAGATTATAAACTTGTGGACCAAGTTGTGTTTGAATTAAAGATGTGGGACCCTCTTGAACATCCATTCCCCCATACCGTTTACGGTGTCAGGTGTATGCTTGCGGTGAAATACGTGCAACTTGTGATTGCCACGTATCCCGTCGATAGTATTGGGGAGGATCTTTTACGCCGTCTAATTCAGATTCTACGGTGCAGGAACCATGACGAAGCGGAGTTACGATACAGCCTTCTCTACGCCGATGTCGAGCGCACGGAGGCGTCTGACCTTCGCAACCCCTCTGGCGCTCCCTGCACCTGCCGGAGCTGCCCCAAACACGTACAAACGAAGGGCCTGGAGGAACCGGCCCATGTACAGGAAGCCCAAGATATACAGGGTTTACCGTTCAAGTGATGTACCCAAGGGCTGTGAAGGCCCCTGTAAGGTCCAGTCTTATGACCAGAGGTTTGATTGTAAACACACTGGTAGTGTTCTCTGTGTGTCAGATATTACCCGTGGTAGTGGCTTGACTCATCGCGTAGGCAAACGCTTTTGCGTGAAGTCCATCATGTTTAGGGGTAAAGTCTGGATGGACGATAACATCAAATCTAAGAGTCATACGAACCATGTGATGTTTTTTTTGGTTCGTGACCGACGCCCGTATGGAACTCCACCTGACTTTGGTCAAGTGTTTAACATGTTTGACAATGAGCCTACCACTGCTACTGTGAAACAAGATTTCCGTGATCGTTTTCAAGTAAAGAGGCGTTGGTGGGTTGGTGTAACCGGTGGACAGTATGCGTCGAAGGAACAGGCGATAGTCAACAAGTTCGTTTATTTAAACAATTATGTTGTTTACAATCACCAAGAAGCTGGGAAGTACGAGAATCACACTGAGAACGCTATGTTATTGTATATGGCATGTACTCATGCATCAAACCCTGTGTATGCAACTCTAAAAATACGGGTGTATTTTTATGACTCAATTGGCAATTAATAAATGTTGAATTTTATTTCATGTTGCAAATCGCATTCGATTACATTTGTGAGTTGGTCGAACAATACATGATTCACAGCTCGAATTACATTATTAATGGAAATAACACCTAAGCGTTTTAAATACACCTTAACTAAATATTTAAACGCCCCAAAGAAACGCGAGTTCATCGCTTGTGAGTGGAGTGATATCGTCCAGGTGAGGAAGCACTTGTGAATCTCCAACCTCTTCTTGAGGCAGTGGTTGAACATTATGCGAACCTTCAGGTGGTCGTAAGGTTGGTTCATCACCCCATAGTCTTCTCGGAGGAGTTTGAAAGACAGGGGATTGTTCAGCTCCCAGATATACTCGCCACGCTCTGCTTCCGATGGAGTGAGTAACTCCTTTGTGCGTGAATCCATTGTGGCTACAGTTGATGTGTACGTATATCGAGCACCCGCACGGACAATCTATTCGGCGTCTCCTAGTCGCCCTCTGCCGTTTCGCCTTGCTGTGTTGAGCCTTGATGCTCGGAGGAGAACAGTGGCTCTTTGATGGTGTAGAATATCGCATTCTTGCTTGCCCACTCCTTTAGCGGTGCATTATGCTCCTCTTCCAAATATTCTTTATAGGAAGATTTGGGCCCCGCGTTGCACAGAAATATCGTGGGAATGCCTCCTTTAATTTGAGTGGGCTTTCCGTATTTCACGTTGCTTTGCCAGTCCTTCTGGGCCCCCATGAATTCCTTTAGGTGCTTTAGATAGTGCGGATCTACGTCATCGATTACGTTGTACCACGCATCGTTTGAATAGACCTTGGCGCTAAGATCCAAATGGCCACATAGGTAATTGTGCCTACCCAACGCCCTGGCCCACATGGTCTTCCCTGTTCTAGACTCACCCTCAAGAACGATGCTTATAGGTCTCATCGGCCGCGCAGCGGAATCCTTCACATTTTCAGCAGCCCAGCGAGTTAATACTTCTGGCACATTGTTAAATTGTTCAACAGTAAAGGGCGATTTGTATATCGCCGTTTTAGGTGTGAATATGCGTTCGAGGTTGCCCATGAGATTGTGATATTGGAAAATATAATCCTTGGGAAGCTGCTCCTTAATGATGGCTAATGCAGCTTCCGCTGAACCTGCATTTAATGCATTTGCGCACGTGTCGTTTGCATTTTGGCAACCTCCTCTAGCACTTCGACCGTCGATCTGAAACGTTCCCCAGTCTAGGGTATCTCCATCTTTATCAATGTATTTTTTGACGTCGGAGCTTGATTTAGCTCCCTGAATGTTCGGATGGTAATGTGTTGATCGCACTGGGGATACGAGGTCGAAGTGTTTCTGGTTAGTGATTTGACACTTTCCCTCAAACTGGATAAGCACATGGAGATGTGGTTCCCCATCCTCGTGTAGTTCACGAGCTATCTTGATAAATTTCTTGTTAGAAGAACAGTGTATGTTTTGTAATTGGGAAAGTGTTTCCTCCTTTGTGAGAGCGCACCTGGGATATGTGAGGAAAATATTTTTTGCCTTCACACAAAAAGACCCTCTCCGTGGCATATTTGTAAATAAGAGCGTGTACCCCCGATTGCTCTCGGCTATTAAAATCCTATGAATCGGGGGTACTGGGGGTACATTTATACCTCTTCTCAATTAAATCCCCTTTAGCGAGATTTTGAAATCCGCCACGTCACCCGCGGCCATCCTATATAATATT
Gene Information
|
NCBI Accession
|
YP_009547944.1
|
|
Location
|
299-1078 |
|
Gene Name
|
BV1 |
|
Protein Name
|
NSP |
|
Coding Region
|
ATGTGGTCTCCTAGATTTAAGGGAAGACGGAGGTTTGACCGGTCTAAGGTTTCCGGTTACCGGATACCAACTACAACGCCTTCTAGGCGTTACAAGAGTCAAGGTTTTTCTCGTGGTGGTGTTTCTCGTTCTCTGACGTATGAACGTGTTGAGCGCCCGTTGGGCTACAAGTGTTTAATGGAACGACATCATGGTGATGCGTTCGCCTTGACCAGTAATTGTGATACTACGTCATTCATTAGTTACCCTGTACGTGCCCTCTCTGGAGAAGGACGTTCTCGTGACTACATTAAATTGCTAAGCATACGTGCATCAGGCGTCATTAATGTTAAAGGCCTGGTTAAACATGACGCCATGGAGAGGTCGACAAACTTCTCTGGCGTTTTTGTGATGGCGTTGGTGATGGACATGAAGCCATATTTGCCGGAAGGAAGCAACCAACTCCCCTCGTTTGTGGAGTTGTTTGGACCCTATTCATCTGCATATGTGACTCTTCGTTTGTTGGACAATCAAACCAGTAGGTTTAGGATACTAACGAGCGTGAGCAAAATGGTGTACACGCAGGACGATAGTAGAGTCCTCCAGTTTAAGTGTTATAGGCGTTTTACGCACTCGAGGTATCCCATATGGGCCTCATTTTACGACCATGACATCGGTAATAGTGGGGGAAATTATAGGAATATTTCTAGGAATGCGGTGTTAGTCAGCTATGCATTTGTATCGGAACAGTCGATGTCATGTGTACCATTTGTTCAATTGGAAACGCGTTATATTGGATAA |
|
Protein Sequence
|
MWSPRFKGRRRFDRSKVSGYRIPTTTPSRRYKSQGFSRGGVSRSLTYERVERPLGYKCLMERHHGDAFALTSNCDTTSFISYPVRALSGEGRSRDYIKLLSIRASGVINVKGLVKHDAMERSTNFSGVFVMALVMDMKPYLPEGSNQLPSFVELFGPYSSAYVTLRLLDNQTSRFRILTSVSKMVYTQDDSRVLQFKCYRRFTHSRYPIWASFYDHDIGNSGGNYRNISRNAVLVSYAFVSEQSMSCVPFVQLETRYIG |
|
NCBI Accession
|
YP_009547945.1
|
|
Location
|
1093-1998 |
|
Gene Name
|
BC1 |
|
Protein Name
|
MP |
|
Coding Region
|
ATGGACACTTCAATTCCAGTGATGCATAGCGAATACATTCAAAGCACAAGGTCTGAATACAGACTTACAAATAACGAAACCCCAATTTCGTTACAATTCCCGTCATCACTGGAAAAGGTACGAGTCCGAATAATGGGAAAATGCATGAAGGTCGACCACGTAATCATCGAATACCGTAACCAGGTTCCGTTTAATGCCCAAGGCTCGGTGATTGTCACAATCCGTGACACAAGGCTTAGCGAAGAACAACAAGACCAAGCCCAGTTCACATTTCCTATAGGCTGTAATGTCGACCTACATTACTTCTCCGCCTCCTTCTTCTCCCTAGAAGATAAAGCACCGTGGGAGTTATTTTACAAAGTAGAGGACTCAAATGTGAAGGACGGAGTAACGTTTGCGCAAATCAAGGCCAAGCTTAAGTTATCATCCGCAACGCACTCAACGGACATAAGGTTTAAGCAACCCACAATAAAAATCCTCTCAAAGGATTACAACGCGGACTGTGTGGACTTCTGGTCCGTTGGAAAGCCCAAACCGATTAGGCGACTCATTAACCCAGGCCCAACAACAGAGTCCAGTCTTGCAGGGCATTACCGGGCCGTTCAAATACAACCCGGTGAAACATGGGCCACCAAATCGACTATAGGCAGGTCTTCGTCCATGCGACTAACAACGTCGCAACCAATGCATACGGGTTCCACCTTACGCACACAGAGTGCTTGTTCCGACGCGGAGTTCCCCTTACAAGGACTGCACAAGCTACCTGAAGCATCACTAGACCCAGGAGATTCAATTTCCCAAACAACGTCAAATGCGCTCAGCAAGGCGGACATTGAGTCCATTGTAGAACAAACTGTAAATAAGTGCTTAATCGCACAAAGAGGCAGTAGCCTTAAAAACTTGTAA |
|
Protein Sequence
|
MDTSIPVMHSEYIQSTRSEYRLTNNETPISLQFPSSLEKVRVRIMGKCMKVDHVIIEYRNQVPFNAQGSVIVTIRDTRLSEEQQDQAQFTFPIGCNVDLHYFSASFFSLEDKAPWELFYKVEDSNVKDGVTFAQIKAKLKLSSATHSTDIRFKQPTIKILSKDYNADCVDFWSVGKPKPIRRLINPGPTTESSLAGHYRAVQIQPGETWATKSTIGRSSSMRLTTSQPMHTGSTLRTQSACSDAEFPLQGLHKLPEASLDPGDSISQTTSNALSKADIESIVEQTVNKCLIAQRGSSLKNL |
|
NCBI Accession
|
YP_009508449.1
|
|
Location
|
137-487 |
|
Gene Name
|
AV2 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGTGGGACCCTCTTGAACATCCATTCCCCCATACCGTTTACGGTGTCAGGTGTATGCTTGCGGTGAAATACGTGCAACTTGTGATTGCCACGTATCCCGTCGATAGTATTGGGGAGGATCTTTTACGCCGTCTAATTCAGATTCTACGGTGCAGGAACCATGACGAAGCGGAGTTACGATACAGCCTTCTCTACGCCGATGTCGAGCGCACGGAGGCGTCTGACCTTCGCAACCCCTCTGGCGCTCCCTGCACCTGCCGGAGCTGCCCCAAACACGTACAAACGAAGGGCCTGGAGGAACCGGCCCATGTACAGGAAGCCCAAGATATACAGGGTTTACCGTTCAAGTGA |
|
Protein Sequence
|
MWDPLEHPFPHTVYGVRCMLAVKYVQLVIATYPVDSIGEDLLRRLIQILRCRNHDEAELRYSLLYADVERTEASDLRNPSGAPCTCRSCPKHVQTKGLEEPAHVQEAQDIQGLPFK |
|
NCBI Accession
|
YP_009508450.1
|
|
Location
|
297-1070 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGACGAAGCGGAGTTACGATACAGCCTTCTCTACGCCGATGTCGAGCGCACGGAGGCGTCTGACCTTCGCAACCCCTCTGGCGCTCCCTGCACCTGCCGGAGCTGCCCCAAACACGTACAAACGAAGGGCCTGGAGGAACCGGCCCATGTACAGGAAGCCCAAGATATACAGGGTTTACCGTTCAAGTGATGTACCCAAGGGCTGTGAAGGCCCCTGTAAGGTCCAGTCTTATGACCAGAGGTTTGATTGTAAACACACTGGTAGTGTTCTCTGTGTGTCAGATATTACCCGTGGTAGTGGCTTGACTCATCGCGTAGGCAAACGCTTTTGCGTGAAGTCCATCATGTTTAGGGGTAAAGTCTGGATGGACGATAACATCAAATCTAAGAGTCATACGAACCATGTGATGTTTTTTTTGGTTCGTGACCGACGCCCGTATGGAACTCCACCTGACTTTGGTCAAGTGTTTAACATGTTTGACAATGAGCCTACCACTGCTACTGTGAAACAAGATTTCCGTGATCGTTTTCAAGTAAAGAGGCGTTGGTGGGTTGGTGTAACCGGTGGACAGTATGCGTCGAAGGAACAGGCGATAGTCAACAAGTTCGTTTATTTAAACAATTATGTTGTTTACAATCACCAAGAAGCTGGGAAGTACGAGAATCACACTGAGAACGCTATGTTATTGTATATGGCATGTACTCATGCATCAAACCCTGTGTATGCAACTCTAAAAATACGGGTGTATTTTTATGACTCAATTGGCAATTAA |
|
Protein Sequence
|
MTKRSYDTAFSTPMSSARRRLTFATPLALPAPAGAAPNTYKRRAWRNRPMYRKPKIYRVYRSSDVPKGCEGPCKVQSYDQRFDCKHTGSVLCVSDITRGSGLTHRVGKRFCVKSIMFRGKVWMDDNIKSKSHTNHVMFFLVRDRRPYGTPPDFGQVFNMFDNEPTTATVKQDFRDRFQVKRRWWVGVTGGQYASKEQAIVNKFVYLNNYVVYNHQEAGKYENHTENAMLLYMACTHASNPVYATLKIRVYFYDSIGN |
|
NCBI Accession
|
YP_009508451.1
|
|
Location
|
1067-1471 |
|
Gene Name
|
AC3 |
|
Protein Name
|
REn |
|
Coding Region
|
ATGGATTCACGCACAAAGGAGTTACTCACTCCATCGGAAGCAGAGCGTGGCGAGTATATCTGGGAGCTGAACAATCCCCTGTCTTTCAAACTCCTCCGAGAAGACTATGGGGTGATGAACCAACCTTACGACCACCTGAAGGTTCGCATAATGTTCAACCACTGCCTCAAGAAGAGGTTGGAGATTCACAAGTGCTTCCTCACCTGGACGATATCACTCCACTCACAAGCGATGAACTCGCGTTTCTTTGGGGCGTTTAAATATTTAGTTAAGGTGTATTTAAAACGCTTAGGTGTTATTTCCATTAATAATGTAATTCGAGCTGTGAATCATGTATTGTTCGACCAACTCACAAATGTAATCGAATGCGATTTGCAACATGAAATAAAATTCAACATTTATTAA |
|
Protein Sequence
|
MDSRTKELLTPSEAERGEYIWELNNPLSFKLLREDYGVMNQPYDHLKVRIMFNHCLKKRLEIHKCFLTWTISLHSQAMNSRFFGAFKYLVKVYLKRLGVISINNVIRAVNHVLFDQLTNVIECDLQHEIKFNIY |
|
NCBI Accession
|
YP_009508452.1
|
|
Location
|
1212-1622 |
|
Gene Name
|
AC2 |
|
Protein Name
|
TrAP |
|
Coding Region
|
ATGCGATATTCTACACCATCAAAGAGCCACTGTTCTCCTCCGAGCATCAAGGCTCAACACAGCAAGGCGAAACGGCAGAGGGCGACTAGGAGACGCCGAATAGATTGTCCGTGCGGGTGCTCGATATACGTACACATCAACTGTAGCCACAATGGATTCACGCACAAAGGAGTTACTCACTCCATCGGAAGCAGAGCGTGGCGAGTATATCTGGGAGCTGAACAATCCCCTGTCTTTCAAACTCCTCCGAGAAGACTATGGGGTGATGAACCAACCTTACGACCACCTGAAGGTTCGCATAATGTTCAACCACTGCCTCAAGAAGAGGTTGGAGATTCACAAGTGCTTCCTCACCTGGACGATATCACTCCACTCACAAGCGATGAACTCGCGTTTCTTTGGGGCGTTTAA |
|
Protein Sequence
|
MRYSTPSKSHCSPPSIKAQHSKAKRQRATRRRRIDCPCGCSIYVHINCSHNGFTHKGVTHSIGSRAWRVYLGAEQSPVFQTPPRRLWGDEPTLRPPEGSHNVQPLPQEEVGDSQVLPHLDDITPLTSDELAFLWGV |
|
NCBI Accession
|
YP_009508453.1
|
|
Location
|
1534-2610 |
|
Gene Name
|
AC1 |
|
Protein Name
|
Rep |
|
Coding Region
|
ATGCCACGGAGAGGGTCTTTTTGTGTGAAGGCAAAAAATATTTTCCTCACATATCCCAGGTGCGCTCTCACAAAGGAGGAAACACTTTCCCAATTACAAAACATACACTGTTCTTCTAACAAGAAATTTATCAAGATAGCTCGTGAACTACACGAGGATGGGGAACCACATCTCCATGTGCTTATCCAGTTTGAGGGAAAGTGTCAAATCACTAACCAGAAACACTTCGACCTCGTATCCCCAGTGCGATCAACACATTACCATCCGAACATTCAGGGAGCTAAATCAAGCTCCGACGTCAAAAAATACATTGATAAAGATGGAGATACCCTAGACTGGGGAACGTTTCAGATCGACGGTCGAAGTGCTAGAGGAGGTTGCCAAAATGCAAACGACACGTGCGCAAATGCATTAAATGCAGGTTCAGCGGAAGCTGCATTAGCCATCATTAAGGAGCAGCTTCCCAAGGATTATATTTTCCAATATCACAATCTCATGGGCAACCTCGAACGCATATTCACACCTAAAACGGCGATATACAAATCGCCCTTTACTGTTGAACAATTTAACAATGTGCCAGAAGTATTAACTCGCTGGGCTGCTGAAAATGTGAAGGATTCCGCTGCGCGGCCGATGAGACCTATAAGCATCGTTCTTGAGGGTGAGTCTAGAACAGGGAAGACCATGTGGGCCAGGGCGTTGGGTAGGCACAATTACCTATGTGGCCATTTGGATCTTAGCGCCAAGGTCTATTCAAACGATGCGTGGTACAACGTAATCGATGACGTAGATCCGCACTATCTAAAGCACCTAAAGGAATTCATGGGGGCCCAGAAGGACTGGCAAAGCAACGTGAAATACGGAAAGCCCACTCAAATTAAAGGAGGCATTCCCACGATATTTCTGTGCAACGCGGGGCCCAAATCTTCCTATAAAGAATATTTGGAAGAGGAGCATAATGCACCGCTAAAGGAGTGGGCAAGCAAGAATGCGATATTCTACACCATCAAAGAGCCACTGTTCTCCTCCGAGCATCAAGGCTCAACACAGCAAGGCGAAACGGCAGAGGGCGACTAG |
|
Protein Sequence
|
MPRRGSFCVKAKNIFLTYPRCALTKEETLSQLQNIHCSSNKKFIKIARELHEDGEPHLHVLIQFEGKCQITNQKHFDLVSPVRSTHYHPNIQGAKSSSDVKKYIDKDGDTLDWGTFQIDGRSARGGCQNANDTCANALNAGSAEAALAIIKEQLPKDYIFQYHNLMGNLERIFTPKTAIYKSPFTVEQFNNVPEVLTRWAAENVKDSAARPMRPISIVLEGESRTGKTMWARALGRHNYLCGHLDLSAKVYSNDAWYNVIDDVDPHYLKHLKEFMGAQKDWQSNVKYGKPTQIKGGIPTIFLCNAGPKSSYKEYLEEEHNAPLKEWASKNAIFYTIKEPLFSSEHQGSTQQGETAEGD |
|
NCBI Accession
|
YP_009508454.1
|
|
Location
|
2277-2453 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGGAACCACATCTCCATGTGCTTATCCAGTTTGAGGGAAAGTGTCAAATCACTAACCAGAAACACTTCGACCTCGTATCCCCAGTGCGATCAACACATTACCATCCGAACATTCAGGGAGCTAAATCAAGCTCCGACGTCAAAAAATACATTGATAAAGATGGAGATACCCTAG |
|
Protein Sequence
|
MGNHISMCLSSLRESVKSLTRNTSTSYPQCDQHITIRTFRELNQAPTSKNTLIKMEIP |