Datura leaf distortion virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000897735.1 |
| Isolate |
Venezuela |
| Release date |
2015/2/22 |
| Submitter |
Fiallo-Olive,E., Chirinos,D.T., Geraud-Pouey,F., Moriones,E., Navas-Castillo,J., Chirinos,D. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
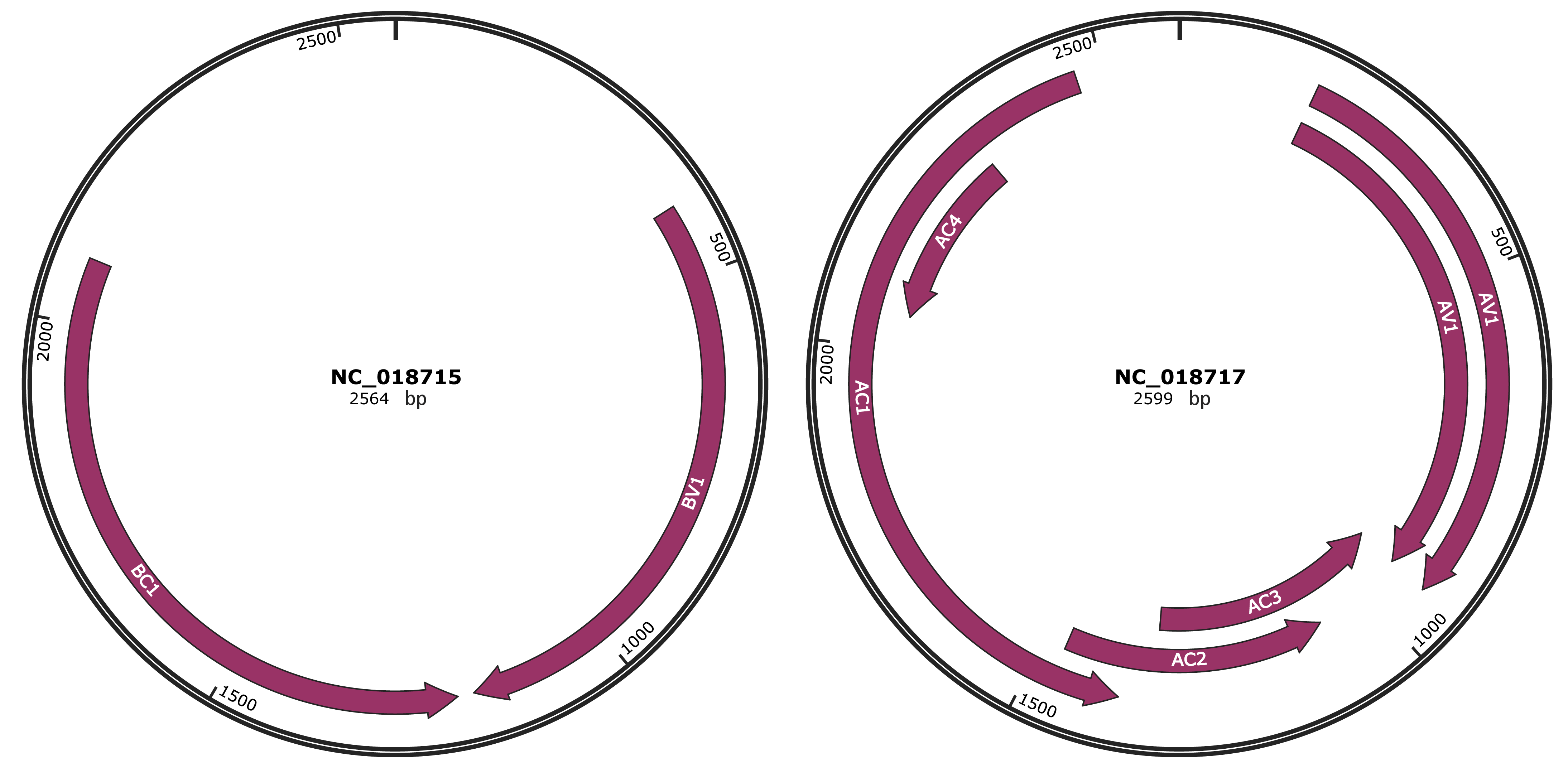
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTATAGTGGGCTTTTACTAAGGCCCAACTAGGATTGGACTAAAGGCCCATTACATACGGATGACTCTTGTTCCCAGAACTTTCTCCGTATGTCCCTTTACCTTTAATTTAAATCTCTCTTTATTATGTGTACAATTTCGACAGCTGTTCTGCACAATATACATACTGACTACGTGGGTAATTCTCGACCAAGTTACAGTGTTTAAGTCGAAATTGATTTTAACCTATCTCCATTTATGAGCTCATGTCTACTGAGTTGTACATTACACGTGTACCATTTAAATTGATCGGGTGGAGTCAATTTAAATAATTGTAAAACTTGACCTGTCTATATATTTGCTGACTAAGAATGAGCTCATTATTACGTGGGATAAAGACAATATATGATAATGTATCCTAATAGGCACAGACGTGCTTCTTTTTCTAGCCAACCACGTAATTACACACGTAATAATTTGATTAGACGGCAGTCATTATTCAAGCGTAATGATAGCAAACGACGACCATTTCAAACCGTGAAGACGGTTGATGAGTCCATGATGAAGGCGCAACGTATTCATGAGAATCAATACGGTCCAGATTTTTCACTGGCCCATAATACAGCCGTGTCCACATTCATTAGTTATCCTGATGTCGCCAAGTCTTTGCCCAATAGAACCAGGTCATATATTAAACTAAAACGACTTCGATTCAAGGGTATTGTGAAGGTGGAACGTGTACTTGCGGAGGTGAACATGGACTGTTCAGTGCCTAAGACCGAAGGAGTTTTCTCTTTGGTTATTGTAGTGGATCGTAAACCTCACATTGGACCCTCTGGGGGACTGCCTACATTCGACGAGTTATTTGGCGCTAGGATCCACAGTCATGGTAATTTGGCAATAGTTCCATCTCTAAAGGATCGGTTCTACATACGCCACGTACTAAAGCGTGTGATATCAGTCGAGAAGGACACCATGATGGTGGACATAGAAGGTGTTGCAGCCCTTTCTAACAAGCGTTTTAATTGTTGGGCTAGTTTTAAGGACCTTGACATAGAGACCCGAAAGGGCGTTTATGATAATATTAATAAGAACGCGCTGTTAGTTTATTATTGTTGGATGTCGGATACTGTATCTAAAGCATCCACATTTGTATCGTTTGATCTTGATTACATTGGATAAGTTTGTATAATAATAAAAATTTTATTTAAAATTTTTGGGCTGAGAACTATTACAACTACTCTTGATACATTCTTGGACAGTTGTCCTTACAAGTTCATTTAACTGGGCTACGGACATGGTTATGTTCGATTGGGCCCTGTTTGCACCAACTATAGATGCTGACTCTCCTGGATCTAGGACGCTGGCTCCTAGCCTCTGCATATCTCGATATGGATGTAGCTCGTTCTCTAGCTCTGACTCGCCCTCTGATTGACCCACTCCTATTGTACTCCTGGAAGCCCATGATTCACCAGGCCTTATTTCAATTGGGCCTCTGAGCCCAACTCTAGACATTGATGCGCATCTTATGGGCTTCCTCTCCCATCTCCCGTAGTCGACGTGCGAGAAATCCACATCCTTATCTGTGAACTGTTTTGACAGGATCTTGACAGTTGGTGCTCTGAAAGGAATGTCTACGGAATGCTTCGCCGTCGACAGCTTCAGCTTCCCTTTGAACTTGGCAAAGTGTGTCCGCTGATGAACGTTCGTGTCGGAAACTCTGTAATAGAGTTTCCATGGGATAGGATCTTTTAGGGAGAAAAAGGAAGCTGAAAAATAGTGGAGATCTATGTTGCATCTTATCGGGAACGTCCACGACGCTTGTAGTGATTCGTTGTCCGTCATCCTCTTGTCATGAATCTCCACTATTACAGAACCGGTGGCGTTGATGGGTACCTGCTGCCTGTACTCAATCACGCAGTGGTCTATCTTCATACAGCTACGACTGAGCCTTGCCGTTAACTGCGCCGCCGTCGACGGAAATTGCAGTATTATCTCAGTTAGGTCATGAGAAAGCTGATACTCGTCTCGCTGAGACTCTATGTAATTGAAAGCATGAGGAGGATTAACTAACTGAGAATTCATTTATTGAAAATAAGGCCGCGCAGCGGCACCGATACGAGAATATGATCAGGAAACGAAAATAATAAGGAAAATATGAACAGGAAAGGAGGATGTTAGGGTTTCGTCAGAAAGTTAAAGAAAAGAATATCATAATTGAAGGTGACTCTCGAACGGGCAAGATAATCTTCTCTATGAGAAGATAGAGAGAAGAAAAGTGTGCTATGGAAGAGTCTGAATATGATAAGATTCAAGGATTAGGTTGTTATATATAGGAGATGTTAATGATGAGTTTGCAATTAAGATATGTCCAATGATAATTAGACGATTAATAAAGAAGAAACTCTTGGTCGGGGCATTTTTGTAAATATTAGTGTTCCCCCGATATGTTCCCCCAATTGCTCTGGCTCTCAAAACTCTTATGAATTGGGGGAACTGGGGGAACTTATATAGTAGAAGTTCCTAAAAGCAGATCAACAACGTGGCGGCCATCCGTTATAATATT
ACCGGATGGCCGCGCGATTTTTTCTGCCCCCTCCGCTTTAATTCGAATTAAAGCGTGCTGCTTTCGTTTCGTCCAATGATATTGCGTCTGACGAGCTTAGATATTTGCAACAACTTGGGCGCTAAGTTGTTGGGTCTGGTCTATAAATTAAAGCCTCTTGGCCCACTATCTTTAACTCAAAATGCCTAAGCGCGATGCCCCATGGCGTTCAATGGCGGGAACCTCAAAGGTTAGCCGCAACGCTAATTACTCTCCTCGCTCAGGAATTGGGCCAAGAATAAACAAGGCCTCTGAATGGGTTAACAGGCCCATGTACAGGAAACCCAGGATCTACCGGACGCTGAGGACTCCTGACGTCCCAAGAGGCTGTGAAGGGCCTTGTAAGGTCCAGTCATTCGAGCAGCGACATGACATCTTACACACTGGCAAGGTAATATGTATATCTGACGTTACCCGCGGTAACGGTATTACCCATCGTGTCGGGAAGCGGTTTTGTGTTAAGTCTGTGTATATCCTTGGTAAGATATGGATGGACGAGAACATCAAGCTGAAGAACCACACCAACAGCGTCATGTTCTGGCTGGTCAGAGACAGAAGACCGTATGGAACGCCTATGGATTTCGGTCAGGTGTTCAACATGTTCGACAATGAGCCTAGCACAGCCACTGTTAAGAACGATCTTCGTGATCGTTATCAGGTCATGCATAAGTTCTACGGCAAGGTCACAGGTGGACAGTACGCCAGCAACGAGCAGGCTATTGTGAGGCGGTTCTGGAAGGTCAACAACCACGTTGTCTACAACCATCAAGAAGCTGGCAAGTACGAGAATCATACTGAGAACGCCCTATTATTGTACATGGCATGTACTCATGCCTCTAACCCTGTATATGCAACGCTTAAGATTCGGATCTATTTTTATGATTCGATCTTAAATTAATAAAATTTAAATTTTATTGAATGATCTTCAAGTACATAATTTACATATGATCGATCTGTTGCAAAATGAACAGCTCTAATTACATTGTTAATCGAAACAGCACCTAACCTATCTAAGTACAAAAGGACTAACTGTCTAAATCTAGCTAAATAAGTCGACCCAGAAGCTGTTATCGATGTCGTCCAGACTTGGAAGTTCAGGTAGGCTTTGTGGAGATCCAACGCTCTCCTGAGGTTGTGGTTGAACCGGATTTGGACGCTGTATATTCTGGTCCTGGTGTATAGTAAGTCCTCTATTCGGTTTATCTTGAAATAGAGGGGATTTTCTATCTCCCAGATAAACACGCCATTCTCTGCCTGACGTGCAGTGATGAGCTCCCCTGTGCGTGAATCCATGTCCTGCGCAGTCTATGTGGAAGTATATGGAGCAACCGCAGTCTAAGTCAATGCGTCTCCTCCTGATGGCCCTCCTCTTTGCTTGCCTGTGCGCCTTCTTGATAGAGGGGGGCTGTGAGGGTGATGAAGACCGCATTCTTTAGAGTCCAGTTTCTAAGAGACGCATTATCTTCTTTCTCGAGGAAAGCTTTATAGCTGGAACCCTCGCCAGGATTGCAGAGCACGATTGATGGGATACCTCCTTTAATTTGAACTGGCTTTCCGTACTTACAATTTGATTGCCAGTCTTTTTGGGCCCCAAGGAGTTCTTTCCAGTGCTTTAGCTTTAGATACTGCGGTGCGACGTCATCAATGACGTTATACTCCACTGCATTTGAATAGACCCTAGAATTGAAATCAAGATGACCGCTCAAGTAATTATGTGGGCCTAAGACCCTAGCCCACATCGTCTTCCCTGTTCTTGAATCACCTTCGACTATGAGACTCAATGGTCTTTCTGGCCGCGCAGCGGGACTTCTTCCAAAATAATCATCTGCCCACTCTTGCATCTCGTCGGGAACGTTAGTGAAAGAGGAGAGTGGAAACGGAGGAGTCCATGGCTCCGGAGCCTTTTGGAATATTCTGCTTGCGTTAGCAAGCAGGTTGTGATGTTGAAGGAAGAAATGTTGTGGTTGTTCTTCCTTTATTATTTGCAGAGCTGCCTCTGCCGATTCTGCATTTAACGCCTTGGCATATGTATCGTTAACTGACTGCTGACCTCCTCGAGCAGATCTGCCGTCGATCTGGAATTTTCCCCATTCAATTGTATCTCCATCTTTGTCGATGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGTTGACCTGGATGGGGAGACCAGATCGAAGAATCTATTATTCGTGCACTGGTATTTTCCTTCGAATTGGATGAGCATGTGGATATGAGGATCCCCATTTTCGTGAAGTTCTCTGCAGATTTTTATGAACTTCTTGTTAACTGGGGTTTTGATAGCTTGAATTTGGGAAAGTGCTTCCTCTTTAGTGAGAGAGCACTGGGGATAAGTGAGGAAATAGTTTTTGGAGTTCACTCTAAACTTCTTTGGTGGTGGCATTTTTGTAATAAGAGGGGTTTACACCGATTGAGCTCCTCTCAAACTTGCTCTATCAATTGGTGTATTGGGGTAACTTATATACTATAACCCTCAATAGTGGTTTGGGTACACGTGTCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_006860594.1
|
|
Location
|
410-1180 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTATCCTAATAGGCACAGACGTGCTTCTTTTTCTAGCCAACCACGTAATTACACACGTAATAATTTGATTAGACGGCAGTCATTATTCAAGCGTAATGATAGCAAACGACGACCATTTCAAACCGTGAAGACGGTTGATGAGTCCATGATGAAGGCGCAACGTATTCATGAGAATCAATACGGTCCAGATTTTTCACTGGCCCATAATACAGCCGTGTCCACATTCATTAGTTATCCTGATGTCGCCAAGTCTTTGCCCAATAGAACCAGGTCATATATTAAACTAAAACGACTTCGATTCAAGGGTATTGTGAAGGTGGAACGTGTACTTGCGGAGGTGAACATGGACTGTTCAGTGCCTAAGACCGAAGGAGTTTTCTCTTTGGTTATTGTAGTGGATCGTAAACCTCACATTGGACCCTCTGGGGGACTGCCTACATTCGACGAGTTATTTGGCGCTAGGATCCACAGTCATGGTAATTTGGCAATAGTTCCATCTCTAAAGGATCGGTTCTACATACGCCACGTACTAAAGCGTGTGATATCAGTCGAGAAGGACACCATGATGGTGGACATAGAAGGTGTTGCAGCCCTTTCTAACAAGCGTTTTAATTGTTGGGCTAGTTTTAAGGACCTTGACATAGAGACCCGAAAGGGCGTTTATGATAATATTAATAAGAACGCGCTGTTAGTTTATTATTGTTGGATGTCGGATACTGTATCTAAAGCATCCACATTTGTATCGTTTGATCTTGATTACATTGGATAA |
|
Protein Sequence
|
MYPNRHRRASFSSQPRNYTRNNLIRRQSLFKRNDSKRRPFQTVKTVDESMMKAQRIHENQYGPDFSLAHNTAVSTFISYPDVAKSLPNRTRSYIKLKRLRFKGIVKVERVLAEVNMDCSVPKTEGVFSLVIVVDRKPHIGPSGGLPTFDELFGARIHSHGNLAIVPSLKDRFYIRHVLKRVISVEKDTMMVDIEGVAALSNKRFNCWASFKDLDIETRKGVYDNINKNALLVYYCWMSDTVSKASTFVSFDLDYIG |
|
NCBI Accession
|
YP_006860595.1
|
|
Location
|
1202-2083 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGAATTCTCAGTTAGTTAATCCTCCTCATGCTTTCAATTACATAGAGTCTCAGCGAGACGAGTATCAGCTTTCTCATGACCTAACTGAGATAATACTGCAATTTCCGTCGACGGCGGCGCAGTTAACGGCAAGGCTCAGTCGTAGCTGTATGAAGATAGACCACTGCGTGATTGAGTACAGGCAGCAGGTACCCATCAACGCCACCGGTTCTGTAATAGTGGAGATTCATGACAAGAGGATGACGGACAACGAATCACTACAAGCGTCGTGGACGTTCCCGATAAGATGCAACATAGATCTCCACTATTTTTCAGCTTCCTTTTTCTCCCTAAAAGATCCTATCCCATGGAAACTCTATTACAGAGTTTCCGACACGAACGTTCATCAGCGGACACACTTTGCCAAGTTCAAAGGGAAGCTGAAGCTGTCGACGGCGAAGCATTCCGTAGACATTCCTTTCAGAGCACCAACTGTCAAGATCCTGTCAAAACAGTTCACAGATAAGGATGTGGATTTCTCGCACGTCGACTACGGGAGATGGGAGAGGAAGCCCATAAGATGCGCATCAATGTCTAGAGTTGGGCTCAGAGGCCCAATTGAAATAAGGCCTGGTGAATCATGGGCTTCCAGGAGTACAATAGGAGTGGGTCAATCAGAGGGCGAGTCAGAGCTAGAGAACGAGCTACATCCATATCGAGATATGCAGAGGCTAGGAGCCAGCGTCCTAGATCCAGGAGAGTCAGCATCTATAGTTGGTGCAAACAGGGCCCAATCGAACATAACCATGTCCGTAGCCCAGTTAAATGAACTTGTAAGGACAACTGTCCAAGAATGTATCAAGAGTAGTTGTAATAGTTCTCAGCCCAAAAATTTTAAATAA |
|
Protein Sequence
|
MNSQLVNPPHAFNYIESQRDEYQLSHDLTEIILQFPSTAAQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGRWERKPIRCASMSRVGLRGPIEIRPGESWASRSTIGVGQSEGESELENELHPYRDMQRLGASVLDPGESASIVGANRAQSNITMSVAQLNELVRTTVQECIKSSCNSSQPKNFK |
|
NCBI Accession
|
YP_006860601.1
|
|
Location
|
182-937 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGCGATGCCCCATGGCGTTCAATGGCGGGAACCTCAAAGGTTAGCCGCAACGCTAATTACTCTCCTCGCTCAGGAATTGGGCCAAGAATAAACAAGGCCTCTGAATGGGTTAACAGGCCCATGTACAGGAAACCCAGGATCTACCGGACGCTGAGGACTCCTGACGTCCCAAGAGGCTGTGAAGGGCCTTGTAAGGTCCAGTCATTCGAGCAGCGACATGACATCTTACACACTGGCAAGGTAATATGTATATCTGACGTTACCCGCGGTAACGGTATTACCCATCGTGTCGGGAAGCGGTTTTGTGTTAAGTCTGTGTATATCCTTGGTAAGATATGGATGGACGAGAACATCAAGCTGAAGAACCACACCAACAGCGTCATGTTCTGGCTGGTCAGAGACAGAAGACCGTATGGAACGCCTATGGATTTCGGTCAGGTGTTCAACATGTTCGACAATGAGCCTAGCACAGCCACTGTTAAGAACGATCTTCGTGATCGTTATCAGGTCATGCATAAGTTCTACGGCAAGGTCACAGGTGGACAGTACGCCAGCAACGAGCAGGCTATTGTGAGGCGGTTCTGGAAGGTCAACAACCACGTTGTCTACAACCATCAAGAAGCTGGCAAGTACGAGAATCATACTGAGAACGCCCTATTATTGTACATGGCATGTACTCATGCCTCTAACCCTGTATATGCAACGCTTAAGATTCGGATCTATTTTTATGATTCGATCTTAAATTAA |
|
Protein Sequence
|
MPKRDAPWRSMAGTSKVSRNANYSPRSGIGPRINKASEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSFEQRHDILHTGKVICISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYGKVTGGQYASNEQAIVRRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSILN |
|
NCBI Accession
|
YP_006860602.1
|
|
Location
|
934-1332 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancement protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAGCTCATCACTGCACGTCAGGCAGAGAATGGCGTGTTTATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATAAACCGAATAGAGGACTTACTATACACCAGGACCAGAATATACAGCGTCCAAATCCGGTTCAACCACAACCTCAGGAGAGCGTTGGATCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGATAACAGCTTCTGGGTCGACTTATTTAGCTAGATTTAGACAGTTAGTCCTTTTGTACTTAGATAGGTTAGGTGCTGTTTCGATTAACAATGTAATTAGAGCTGTTCATTTTGCAACAGATCGATCATATGTAAATTATGTACTTGAAGATCATTCAATAAAATTTAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGELITARQAENGVFIWEIENPLYFKINRIEDLLYTRTRIYSVQIRFNHNLRRALDLHKAYLNFQVWTTSITASGSTYLARFRQLVLLYLDRLGAVSINNVIRAVHFATDRSYVNYVLEDHSIKFKFY |
|
NCBI Accession
|
YP_006860603.1
|
|
Location
|
1079-1468 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transactivator protein |
|
Coding Region
|
ATGCGGTCTTCATCACCCTCACAGCCCCCCTCTATCAAGAAGGCGCACAGGCAAGCAAAGAGGAGGGCCATCAGGAGGAGACGCATTGACTTAGACTGCGGTTGCTCCATATACTTCCACATAGACTGCGCAGGACATGGATTCACGCACAGGGGAGCTCATCACTGCACGTCAGGCAGAGAATGGCGTGTTTATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATAAACCGAATAGAGGACTTACTATACACCAGGACCAGAATATACAGCGTCCAAATCCGGTTCAACCACAACCTCAGGAGAGCGTTGGATCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGATAACAGCTTCTGGGTCGACTTATTTAGCTAG |
|
Protein Sequence
|
MRSSSPSQPPSIKKAHRQAKRRAIRRRRIDLDCGCSIYFHIDCAGHGFTHRGAHHCTSGREWRVYLGDRKSPLFQDKPNRGLTIHQDQNIQRPNPVQPQPQESVGSPQSLPELPSLDDIDNSFWVDLFS |
|
NCBI Accession
|
YP_006860604.1
|
|
Location
|
1380-2465 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGCCACCACCAAAGAAGTTTAGAGTGAACTCCAAAAACTATTTCCTCACTTATCCCCAGTGCTCTCTCACTAAAGAGGAAGCACTTTCCCAAATTCAAGCTATCAAAACCCCAGTTAACAAGAAGTTCATAAAAATCTGCAGAGAACTTCACGAAAATGGGGATCCTCATATCCACATGCTCATCCAATTCGAAGGAAAATACCAGTGCACGAATAATAGATTCTTCGATCTGGTCTCCCCATCCAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAAGATGGAGATACAATTGAATGGGGAAAATTCCAGATCGACGGCAGATCTGCTCGAGGAGGTCAGCAGTCAGTTAACGATACATATGCCAAGGCGTTAAATGCAGAATCGGCAGAGGCAGCTCTGCAAATAATAAAGGAAGAACAACCACAACATTTCTTCCTTCAACATCACAACCTGCTTGCTAACGCAAGCAGAATATTCCAAAAGGCTCCGGAGCCATGGACTCCTCCGTTTCCACTCTCCTCTTTCACTAACGTTCCCGACGAGATGCAAGAGTGGGCAGATGATTATTTTGGAAGAAGTCCCGCTGCGCGGCCAGAAAGACCATTGAGTCTCATAGTCGAAGGTGATTCAAGAACAGGGAAGACGATGTGGGCTAGGGTCTTAGGCCCACATAATTACTTGAGCGGTCATCTTGATTTCAATTCTAGGGTCTATTCAAATGCAGTGGAGTATAACGTCATTGATGACGTCGCACCGCAGTATCTAAAGCTAAAGCACTGGAAAGAACTCCTTGGGGCCCAAAAAGACTGGCAATCAAATTGTAAGTACGGAAAGCCAGTTCAAATTAAAGGAGGTATCCCATCAATCGTGCTCTGCAATCCTGGCGAGGGTTCCAGCTATAAAGCTTTCCTCGAGAAAGAAGATAATGCGTCTCTTAGAAACTGGACTCTAAAGAATGCGGTCTTCATCACCCTCACAGCCCCCCTCTATCAAGAAGGCGCACAGGCAAGCAAAGAGGAGGGCCATCAGGAGGAGACGCATTGA |
|
Protein Sequence
|
MPPPKKFRVNSKNYFLTYPQCSLTKEEALSQIQAIKTPVNKKFIKICRELHENGDPHIHMLIQFEGKYQCTNNRFFDLVSPSRSTHFHPNIQGAKSSSDVKSYIDKDGDTIEWGKFQIDGRSARGGQQSVNDTYAKALNAESAEAALQIIKEEQPQHFFLQHHNLLANASRIFQKAPEPWTPPFPLSSFTNVPDEMQEWADDYFGRSPAARPERPLSLIVEGDSRTGKTMWARVLGPHNYLSGHLDFNSRVYSNAVEYNVIDDVAPQYLKLKHWKELLGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGSSYKAFLEKEDNASLRNWTLKNAVFITLTAPLYQEGAQASKEEGHQEETH |
|
NCBI Accession
|
YP_006860605.1
|
|
Location
|
2051-2308 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGGATCCTCATATCCACATGCTCATCCAATTCGAAGGAAAATACCAGTGCACGAATAATAGATTCTTCGATCTGGTCTCCCCATCCAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAAGATGGAGATACAATTGAATGGGGAAAATTCCAGATCGACGGCAGATCTGCTCGAGGAGGTCAGCAGTCAGTTAACGATACATATGCCAAGGCGTTAA |
|
Protein Sequence
|
MGILISTCSSNSKENTSARIIDSSIWSPHPGQHISIRTFRELNPAPTSSPTSTKMEIQLNGENSRSTADLLEEVSSQLTIHMPRR |