Croton golden mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_013087355.1 |
| Isolate |
Colombia |
| Release date |
2021/6/1 |
| Submitter |
Vaca-Vaca,J.C., Jara-Tejada,F., Lopez-Lopez,K. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
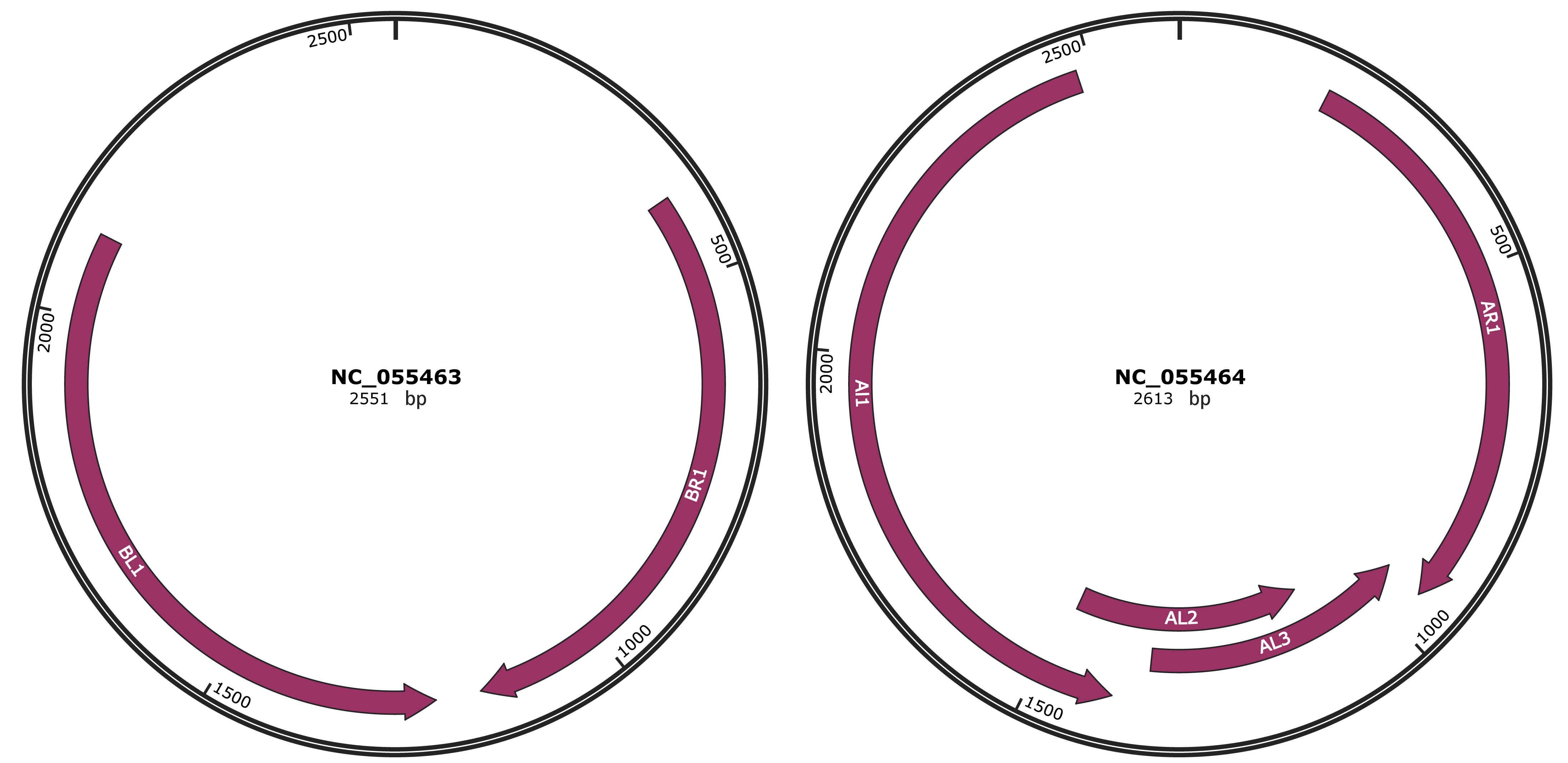
JBrowse
Genome
ACCGGATGGCCGCGCCCCCCTTTAGTAGTGGGCTTTTATTTGGTCGTCCATTGGGCCTATATTATGTTTTTATAGCCCATCAACTTCTTAGTTGATTTTAGTTTTGGTCCCCAATGCTTTTGACTGATCTTTAATTTGAAATAAAGTACATGTAATGACGCGCTATATTTATTGGGAAAATGAATTTTGTTTATCGCGTCTTTGTATTATGGTCCATTGTACGACATGATGGACGTGGCATATTGTATACCATACTTATGAGTCAATTAATGTGTTTCTTTGATATGCCTTTCCTATATATTGGATGCTGTCGACATATAATATTCAAGTGATTCATATGTCTACCACGTTTATAGTATTATGATTATTTGTATGTAATTATTGTATTTTGATAATGTTTACTTTTAGGAATAAACGTGGTTTCTCTTTTACTCTACGTCGTTCGTATTTGCGTAATAATGTGTTCAAGCGTCCTAATTTGGTTAAACGTCCCGACGTGAGACGTGGACTGGGCAATACATCGAAGCCAAATGATGAGCCTAAATTGTTATTGCAACGCATTCATGAGAATCAATATGGCCCAGAATTTGTTATGTCTCATAACTCTTCTATTGCCACTTTTATTAGCTATCCTTGTGTTAGCAAGTCAGAACCCAACCGAAGCAGATCATATATTAAACTTAAACGGCTACGTTTTAAAGGTACTGTGAAAATTGAACGTGTATTATCTGATATGAACATGGATGGTACGATATCCAAAATTGAAGGAGTATTTTCCCTTGTAATTGTTGTGGATCGTAAACCGCATTTGGCTCCGTCTGGTTGTCTGCACACATTTGATGAGCTATTTGGTGCTAGAATCCACAGTCATGGTAGTCTCAACATTACTCCTGCTTTGAAGGACCGTTATTACATTCGACATGTGTTTAAACGTGTAGTATCTGTGGAGAAGGACACTATGATGATCGATGTTGAAGGATCTACCATGCTATCTAGTAGGCGTTATAATTGTTGGTCGACCTTTAAGGATCTGGATCATGAATCATGTAAAGGTGTATATGATAATATTAGCAAGAACGCCCTGTTAGTTTATTATTGTTGGATGTCAGATTGTATGTCAAAAGCATCCTGTTATGTATCATTTGATTTGGATTATATTGGATAATGAATGATAAGTCAAGTCGATTATGCAATTGAACGATATTGTGTTGAACATGATAAATTTATTGTAATGTCTTTGCCTGAGAAACTTTACAATTATTACTAATACATTCATTGACCGTTGTTCTAACTATTTCGTTTAACTGACCCATGGATAATGTGATATTTGAATCACACCTTTGGGCACCTACAATAGAAGCAGACTCTCCTGGGTCTAAGACACTTGTTCCTAGTCTATGCAGATGTCTATATGGATGCATTGCATTCTGTACGTCTGATTCCGTATCTGAAGGACTTAAACCTATGGTACTTCTGGAAGCCCATGATTCTCCTGGTTTTATATCTATTGGGTTTGGTAGCCCAATTCGTGACATGGATGCGCATCTGATGGGCTTCCTTTCCCATTTTCCATAGTCTACGTGTGAGAAGTCCACATCCTTATCTGAAAACTGTTTTGAGAGTATCTTGACAGTCGGAGCCCGAAATGGAATATCAACTGAGTGTTTCGCCGTCGACAGTTTCAGTTTCCCTTTGAATTTGGCGAAGTGAGTTCTTTGATGAACATTCGTGTCACATACTCGATAATATAGCTTCCATGGAATAGGATCTTTGAGTGAGAAGAACGAAGCCGAGAAGTAGTGGAGATCAATGTTGCATCTTATTGGAAATGTCCATGACGCCTGTAATGACTCGTTGTCAGTCATACGTTTATCATGTATCTCCACGATTACAGACCCAGAGGCGTTGATAGGCACTTGTTGTCTGTATTCAATCACACAGTGATCTATTTTCATGCAGCTACGACTGAGTCTAGCCGTTAATTGTGACGCCGTTGAAGGAAATTGCAATACTATCTCAGTTAGGTCGTGCGAAAGCTGGTATTCGTCTCTATGAGATTCTATATAATTAAATGCGTTCGGAGGATTTGCTAACTGAGAATCCATATATGAAATTCTGGACGCGCAGCGTCACGGCTGGCAGAAAATGAACAAGAAACGAAGAGGATATGTTTTCTGGTGACCCAGAAAAGTTGATTAATAAACGGTAGATCTGCTCGAGGAGGCTGCCAGAGTGCTAACGAGACATATGCCAAGGATTAATTTGAGATAGTGAAGAAAGCTGTAGATGAAATTAGATATGTTGATTAGATATAACCGATATGTCGATATTTATAGCAAGATATGTCATGATATTGAATGAGGTAGTGGACGAGTAAAGATAAAGAGATATATAAAGGAAATTTAATAGTCGATGGCATTTTTGTAATAATGAGTGGTACTCCAAATGAGCTCTCTCAAAACTTGCTCATTCAATTGGAGTATTGGAGTTACTTAAATACTAGAACTCTCAATCTCTATTTTATACACGTGTCGGCCATCCGTCTAATATT
ACCGGATGGCCGCGCCCCCCTTTAGTAGTGGGCTTTCTCACGCCCACTGGGCTTCGCTTTATTTATATCACTCGGCCCAATGTCCATCCAATCATTTGTCGTTATGTGAGTCTAATTATGAACAACTTCGCCTCGAAGTTGTGGTCGTACATCTTTATAAAGAATGCCGAGTGATATGTGGCCCATGTATATTGAACATGCCTAAGCGTGATGCCCCATGGCGTTCAATGGCGGGAACCTCAAAGGTTAGCCGCAACGCCAATTATTCGCCTCGTGGAGGCATGGGCCCTAAGTTTGACAAGGCCGCTGCTTGGGTTAACAGGCCCATGTACAGGAAACCCAGGATCTACCGGATGGTGAGAACCCCCGACGTTCCAAAAGGATGTGAAGGCCCTTGTAAAGTCCAGTCATTCGAGCAGCGACATGATGTCTCTCATGTAGGTAAGGTGATATGTCTCTCCGATGTGACACGTGGTAATGGTATTACCCACCGTGTTGGTAAGCGTTTCTGTGTCAAGTCTGTGTATATCCTAGGCAAGATATGGATGGACGAGAATATCAAGCTGAAGAACCACACCAACAGCGTCATGTTCTGGTTGGTTAGAGATCGAAGACCCTATGGCACTCCTATGGACTTTGGCCAAGTGTTCAACATGTACGACAATGAGCCTAGCACTGCGACTGTGAAAAACGATCTTCGTGATCGTTTCCAGGTTATGCATCGGTTCCATGCCAAAGTCACCGGAGGTCAGTATGCCAGCAACGAGCAGGCGTTAGTGAGGCGTTTTTGGAAGGTGAACAATCATGTGGTGTACAACCACCAAGAAGCTGGCAAATACGAGAATCATACGGAGAATGCTTTGCTATTGTACATGGCATGTACGCATGCCTCTAATCCTGTATATGCGACATTGAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAATAAATTTTATATTTTATTATATGATTCTCAATTACACTGTGCACATACTGTCTATCTGTTGCAAAACGAACAGCTCTAATGACATTATTAATCGATATGACACCTAATTGATCTAAATACATTAAAACCAATTGCCTAAATCTAACTAAATAGCTCGTCCCAGAAGTTGTCAGAGAAGTCGTCCAGACTTGGAAGTTCAGGTAGGCTTTGTGTAGATGCAATTGGTTCCTCAGGTTGTGGTTGAACCGTATTTGTACATGAAATATCCTCGTTCGTGTGTATTGTGGATCCTCTACTCCGTTGATCCTGAAATATAGGGGATTTATTATTTCCCAAATATAGACGCCACTCTCTGCCTGACGTGCAGTGATGAGCTCCCCTGTGCGTGAATCCATGTCCCGTGCAGTCGATATGCTGATATATAGAGCAGCCGCACTGTAAATCAATCCGTCTTCTCCTGATGACTTTCTTCTTCGTTTGTCGCGGCTGCTTCTTGATAGAGAGGGGAGTCGAGGAAGATGAATCTTGCATTATGAAGAGTCCAGGCTCTCAGTGCATGATTATCCTGTTTGTCCAGGAAATCTTTATAGCTCGACCCCTCACCTGGATTGCAAAGCACGATTGATGGGATACCTCCTTTAATTTGAACTGGCTTTCCATATTTACAGTTGGACTGCCAATCCCTTTGGGCCCCCATCAATTCTTTCCAGTGCTTCATCTTTAGATATTGCGGAGCCACGTCATCAATGACGTTATATTCCACTTGATTTGAATAGACCCTTGAATTGAAATCCAGGTGTCCACTCAAATAATTATGTGGTCCTAATGCACGTGCCCACATTGTCTTTCCAGTACGACTATCTCCTTCGACGATGATACTAATAGGTCTCTCCGGCCGCGCAGCGGCACCCCTTCCAAAATAATCATCCGCCCATTCTTGCATCTCGACAGGAACGTTAGTGAACGAAGAGAGTCGATATGGAGGAACCCACGGTTCCGGAGCCTTCTGAAATATTTTGGATGCGTTGCTAACGAGATTGTGATGTTGAAGGAAGAAATGTTGCGGTTGTTCTTCTTTTATGATCTGCAGAGCTTCTTCTGCAGAGGTTGCATTTAACGCCTTGGCATATGTCTCGTTAGCACTCTGGCAGCCTCCTCGAGCAGATCTACCGTCGATCTGGAATTCTCCCCATTCAATTGTATCCCCGTCTTTGTCGATGTAGGACTTGACGTCGGAGCTAGATTTAGCTCCCTGTATGTTTGGATGGAAGTGGGCTGAACGTGACGGGGATACCAGATCGAAGAATCTGTTATTCGTGCACTGGTATTTGCCTTCGAATTGGATAAGCACGTGGATATGAGGCTGCCCATTCTCATGAAACTCCCTGCAGATCTTGATGAATTTCTTGTTTACGGGAGTCGCTAGGTTTTGTAATTGGGAAAGTGCCTCTTCTTTGGTAAGAGAGCACTGGGGATATGTGAGAAAATAATTTTTCGACTGAACTCTAAACTTCTTAACCGATGGCATTTTTGTAATAATGAGTGGTACTCCAAATGAGCTCTCTCAAAACTTGCTCATTCAATTGGAGTATTGGAGTTACTTAAATACTAGAACTCTCAATCTCTATTTTATACACGTGTCGGCCATCCGTCTAATATT
Gene Information
|
NCBI Accession
|
YP_010086588.1
|
|
Location
|
395-1165 |
|
Gene Name
|
BR1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTTTACTTTTAGGAATAAACGTGGTTTCTCTTTTACTCTACGTCGTTCGTATTTGCGTAATAATGTGTTCAAGCGTCCTAATTTGGTTAAACGTCCCGACGTGAGACGTGGACTGGGCAATACATCGAAGCCAAATGATGAGCCTAAATTGTTATTGCAACGCATTCATGAGAATCAATATGGCCCAGAATTTGTTATGTCTCATAACTCTTCTATTGCCACTTTTATTAGCTATCCTTGTGTTAGCAAGTCAGAACCCAACCGAAGCAGATCATATATTAAACTTAAACGGCTACGTTTTAAAGGTACTGTGAAAATTGAACGTGTATTATCTGATATGAACATGGATGGTACGATATCCAAAATTGAAGGAGTATTTTCCCTTGTAATTGTTGTGGATCGTAAACCGCATTTGGCTCCGTCTGGTTGTCTGCACACATTTGATGAGCTATTTGGTGCTAGAATCCACAGTCATGGTAGTCTCAACATTACTCCTGCTTTGAAGGACCGTTATTACATTCGACATGTGTTTAAACGTGTAGTATCTGTGGAGAAGGACACTATGATGATCGATGTTGAAGGATCTACCATGCTATCTAGTAGGCGTTATAATTGTTGGTCGACCTTTAAGGATCTGGATCATGAATCATGTAAAGGTGTATATGATAATATTAGCAAGAACGCCCTGTTAGTTTATTATTGTTGGATGTCAGATTGTATGTCAAAAGCATCCTGTTATGTATCATTTGATTTGGATTATATTGGATAA |
|
Protein Sequence
|
MFTFRNKRGFSFTLRRSYLRNNVFKRPNLVKRPDVRRGLGNTSKPNDEPKLLLQRIHENQYGPEFVMSHNSSIATFISYPCVSKSEPNRSRSYIKLKRLRFKGTVKIERVLSDMNMDGTISKIEGVFSLVIVVDRKPHLAPSGCLHTFDELFGARIHSHGSLNITPALKDRYYIRHVFKRVVSVEKDTMMIDVEGSTMLSSRRYNCWSTFKDLDHESCKGVYDNISKNALLVYYCWMSDCMSKASCYVSFDLDYIG |
|
NCBI Accession
|
YP_010086589.1
|
|
Location
|
1224-2105 |
|
Gene Name
|
BL1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGATTCTCAGTTAGCAAATCCTCCGAACGCATTTAATTATATAGAATCTCATAGAGACGAATACCAGCTTTCGCACGACCTAACTGAGATAGTATTGCAATTTCCTTCAACGGCGTCACAATTAACGGCTAGACTCAGTCGTAGCTGCATGAAAATAGATCACTGTGTGATTGAATACAGACAACAAGTGCCTATCAACGCCTCTGGGTCTGTAATCGTGGAGATACATGATAAACGTATGACTGACAACGAGTCATTACAGGCGTCATGGACATTTCCAATAAGATGCAACATTGATCTCCACTACTTCTCGGCTTCGTTCTTCTCACTCAAAGATCCTATTCCATGGAAGCTATATTATCGAGTATGTGACACGAATGTTCATCAAAGAACTCACTTCGCCAAATTCAAAGGGAAACTGAAACTGTCGACGGCGAAACACTCAGTTGATATTCCATTTCGGGCTCCGACTGTCAAGATACTCTCAAAACAGTTTTCAGATAAGGATGTGGACTTCTCACACGTAGACTATGGAAAATGGGAAAGGAAGCCCATCAGATGCGCATCCATGTCACGAATTGGGCTACCAAACCCAATAGATATAAAACCAGGAGAATCATGGGCTTCCAGAAGTACCATAGGTTTAAGTCCTTCAGATACGGAATCAGACGTACAGAATGCAATGCATCCATATAGACATCTGCATAGACTAGGAACAAGTGTCTTAGACCCAGGAGAGTCTGCTTCTATTGTAGGTGCCCAAAGGTGTGATTCAAATATCACATTATCCATGGGTCAGTTAAACGAAATAGTTAGAACAACGGTCAATGAATGTATTAGTAATAATTGTAAAGTTTCTCAGGCAAAGACATTACAATAA |
|
Protein Sequence
|
MDSQLANPPNAFNYIESHRDEYQLSHDLTEIVLQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINASGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFSDKDVDFSHVDYGKWERKPIRCASMSRIGLPNPIDIKPGESWASRSTIGLSPSDTESDVQNAMHPYRHLHRLGTSVLDPGESASIVGAQRCDSNITLSMGQLNEIVRTTVNECISNNCKVSQAKTLQ |
|
NCBI Accession
|
YP_010086590.1
|
|
Location
|
198-953 |
|
Gene Name
|
AR1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGTGATGCCCCATGGCGTTCAATGGCGGGAACCTCAAAGGTTAGCCGCAACGCCAATTATTCGCCTCGTGGAGGCATGGGCCCTAAGTTTGACAAGGCCGCTGCTTGGGTTAACAGGCCCATGTACAGGAAACCCAGGATCTACCGGATGGTGAGAACCCCCGACGTTCCAAAAGGATGTGAAGGCCCTTGTAAAGTCCAGTCATTCGAGCAGCGACATGATGTCTCTCATGTAGGTAAGGTGATATGTCTCTCCGATGTGACACGTGGTAATGGTATTACCCACCGTGTTGGTAAGCGTTTCTGTGTCAAGTCTGTGTATATCCTAGGCAAGATATGGATGGACGAGAATATCAAGCTGAAGAACCACACCAACAGCGTCATGTTCTGGTTGGTTAGAGATCGAAGACCCTATGGCACTCCTATGGACTTTGGCCAAGTGTTCAACATGTACGACAATGAGCCTAGCACTGCGACTGTGAAAAACGATCTTCGTGATCGTTTCCAGGTTATGCATCGGTTCCATGCCAAAGTCACCGGAGGTCAGTATGCCAGCAACGAGCAGGCGTTAGTGAGGCGTTTTTGGAAGGTGAACAATCATGTGGTGTACAACCACCAAGAAGCTGGCAAATACGAGAATCATACGGAGAATGCTTTGCTATTGTACATGGCATGTACGCATGCCTCTAATCCTGTATATGCGACATTGAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAA |
|
Protein Sequence
|
MPKRDAPWRSMAGTSKVSRNANYSPRGGMGPKFDKAAAWVNRPMYRKPRIYRMVRTPDVPKGCEGPCKVQSFEQRHDVSHVGKVICLSDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMYDNEPSTATVKNDLRDRFQVMHRFHAKVTGGQYASNEQALVRRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_010086591.1
|
|
Location
|
950-1348 |
|
Gene Name
|
AL3 |
|
Protein Name
|
replication enhancement protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAGCTCATCACTGCACGTCAGGCAGAGAGTGGCGTCTATATTTGGGAAATAATAAATCCCCTATATTTCAGGATCAACGGAGTAGAGGATCCACAATACACACGAACGAGGATATTTCATGTACAAATACGGTTCAACCACAACCTGAGGAACCAATTGCATCTACACAAAGCCTACCTGAACTTCCAAGTCTGGACGACTTCTCTGACAACTTCTGGGACGAGCTATTTAGTTAGATTTAGGCAATTGGTTTTAATGTATTTAGATCAATTAGGTGTCATATCGATTAATAATGTCATTAGAGCTGTTCGTTTTGCAACAGATAGACAGTATGTGCACAGTGTAATTGAGAATCATATAATAAAATATAAAATTTATTAA |
|
Protein Sequence
|
MDSRTGELITARQAESGVYIWEIINPLYFRINGVEDPQYTRTRIFHVQIRFNHNLRNQLHLHKAYLNFQVWTTSLTTSGTSYLVRFRQLVLMYLDQLGVISINNVIRAVRFATDRQYVHSVIENHIIKYKIY |
|
NCBI Accession
|
YP_010086592.1
|
|
Location
|
1095-1484 |
|
Gene Name
|
AL2 |
|
Protein Name
|
transactivator protein |
|
Coding Region
|
ATGCAAGATTCATCTTCCTCGACTCCCCTCTCTATCAAGAAGCAGCCGCGACAAACGAAGAAGAAAGTCATCAGGAGAAGACGGATTGATTTACAGTGCGGCTGCTCTATATATCAGCATATCGACTGCACGGGACATGGATTCACGCACAGGGGAGCTCATCACTGCACGTCAGGCAGAGAGTGGCGTCTATATTTGGGAAATAATAAATCCCCTATATTTCAGGATCAACGGAGTAGAGGATCCACAATACACACGAACGAGGATATTTCATGTACAAATACGGTTCAACCACAACCTGAGGAACCAATTGCATCTACACAAAGCCTACCTGAACTTCCAAGTCTGGACGACTTCTCTGACAACTTCTGGGACGAGCTATTTAGTTAG |
|
Protein Sequence
|
MQDSSSSTPLSIKKQPRQTKKKVIRRRRIDLQCGCSIYQHIDCTGHGFTHRGAHHCTSGREWRLYLGNNKSPIFQDQRSRGSTIHTNEDISCTNTVQPQPEEPIASTQSLPELPSLDDFSDNFWDELFS |
|
NCBI Accession
|
YP_010086593.1
|
|
Location
|
1396-2481 |
|
Gene Name
|
Al1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGCCATCGGTTAAGAAGTTTAGAGTTCAGTCGAAAAATTATTTTCTCACATATCCCCAGTGCTCTCTTACCAAAGAAGAGGCACTTTCCCAATTACAAAACCTAGCGACTCCCGTAAACAAGAAATTCATCAAGATCTGCAGGGAGTTTCATGAGAATGGGCAGCCTCATATCCACGTGCTTATCCAATTCGAAGGCAAATACCAGTGCACGAATAACAGATTCTTCGATCTGGTATCCCCGTCACGTTCAGCCCACTTCCATCCAAACATACAGGGAGCTAAATCTAGCTCCGACGTCAAGTCCTACATCGACAAAGACGGGGATACAATTGAATGGGGAGAATTCCAGATCGACGGTAGATCTGCTCGAGGAGGCTGCCAGAGTGCTAACGAGACATATGCCAAGGCGTTAAATGCAACCTCTGCAGAAGAAGCTCTGCAGATCATAAAAGAAGAACAACCGCAACATTTCTTCCTTCAACATCACAATCTCGTTAGCAACGCATCCAAAATATTTCAGAAGGCTCCGGAACCGTGGGTTCCTCCATATCGACTCTCTTCGTTCACTAACGTTCCTGTCGAGATGCAAGAATGGGCGGATGATTATTTTGGAAGGGGTGCCGCTGCGCGGCCGGAGAGACCTATTAGTATCATCGTCGAAGGAGATAGTCGTACTGGAAAGACAATGTGGGCACGTGCATTAGGACCACATAATTATTTGAGTGGACACCTGGATTTCAATTCAAGGGTCTATTCAAATCAAGTGGAATATAACGTCATTGATGACGTGGCTCCGCAATATCTAAAGATGAAGCACTGGAAAGAATTGATGGGGGCCCAAAGGGATTGGCAGTCCAACTGTAAATATGGAAAGCCAGTTCAAATTAAAGGAGGTATCCCATCAATCGTGCTTTGCAATCCAGGTGAGGGGTCGAGCTATAAAGATTTCCTGGACAAACAGGATAATCATGCACTGAGAGCCTGGACTCTTCATAATGCAAGATTCATCTTCCTCGACTCCCCTCTCTATCAAGAAGCAGCCGCGACAAACGAAGAAGAAAGTCATCAGGAGAAGACGGATTGA |
|
Protein Sequence
|
MPSVKKFRVQSKNYFLTYPQCSLTKEEALSQLQNLATPVNKKFIKICREFHENGQPHIHVLIQFEGKYQCTNNRFFDLVSPSRSAHFHPNIQGAKSSSDVKSYIDKDGDTIEWGEFQIDGRSARGGCQSANETYAKALNATSAEEALQIIKEEQPQHFFLQHHNLVSNASKIFQKAPEPWVPPYRLSSFTNVPVEMQEWADDYFGRGAAARPERPISIIVEGDSRTGKTMWARALGPHNYLSGHLDFNSRVYSNQVEYNVIDDVAPQYLKMKHWKELMGAQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGSSYKDFLDKQDNHALRAWTLHNARFIFLDSPLYQEAAATNEEESHQEKTD |