Cowpea golden mosaic virus
Basic Information
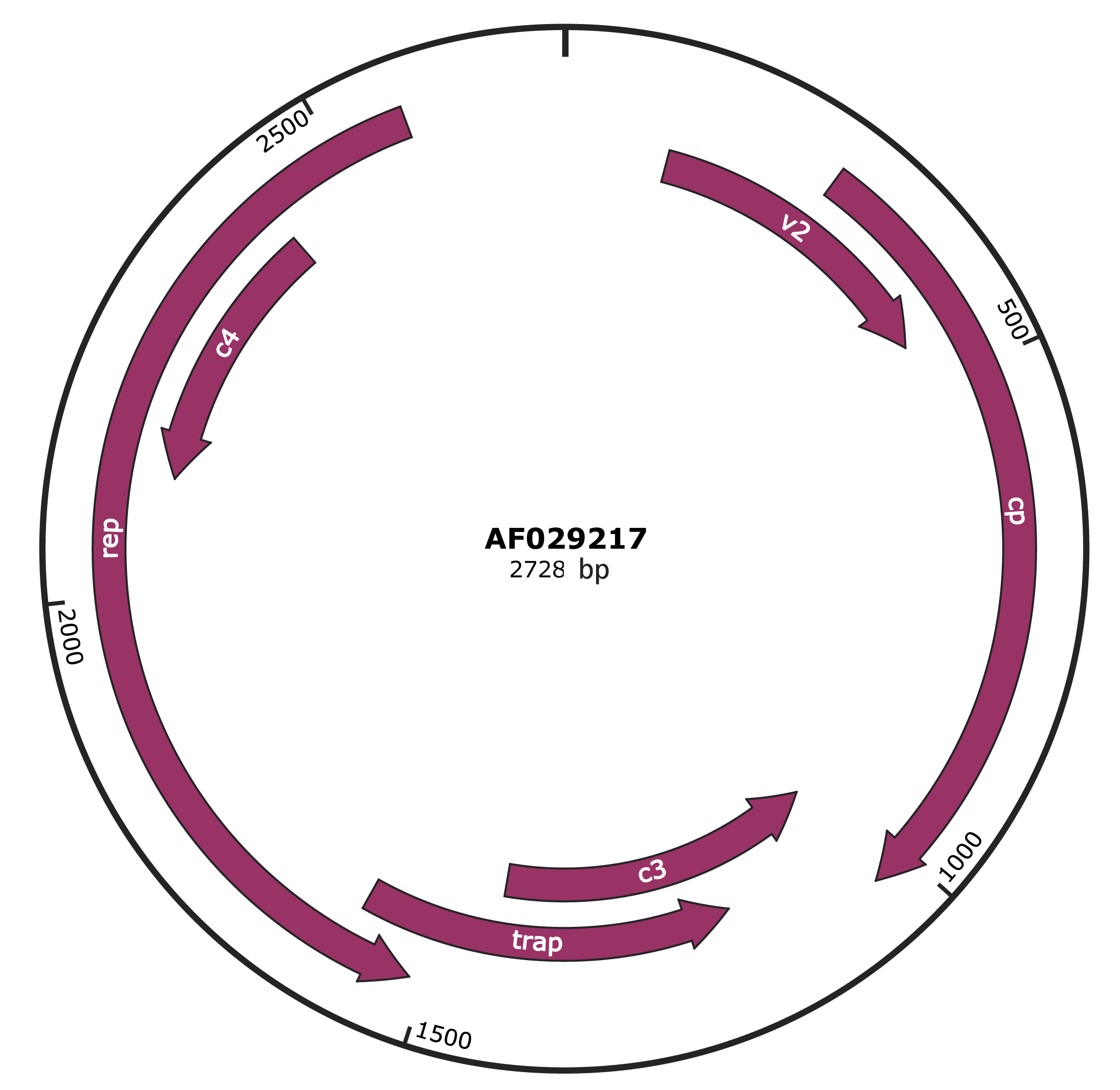
Genomic Organization
JBrowse
Genome
ACCTGAGGGCCGCTTTCGGTGTACCCCACGCACCAATCAGGATGCGCCATTTGCGCTTATTTATTAACTGGGCCTCTATATATTGGGCTTTGTTGTGTATTGGATTTGCACCATGTTTAACCCACTAACTGAACCCCTCCCAGTTACTCCTCACGGTTTGATGTGTATGTTGGCTTTGAAATATTTGCAGGAGTTCGAGAAATCTGTACATTTGACTCCGTGTGATAATACTGAGTTGTTGTTACTCCGCCGTGTTATTCGTGCAAGGACTTACGATGAAGCGAAGCGCCGATACCATATATTCCACACCTTCCAAGGCTCGAAGGAGGTTGACGTTCGACACCCCTCGTGCGACTCCTGCGTCCTTAGGGCGTTCCAACAAAAGGCGGGCTTGGGAGAACCGGCCCATGAACCGCAAGCCCATGATGTACCGGCTTTGGAGGAGTCCTGATGTTCCGTATGGTTGTGAGGGTCCATGTAAGGTTCAGTCTTTCGAGGCCAGACACGACGTCAAACACACGGGAACTTTTCAGTGTTGTTCAGACGTTACTCGGGGAATGGGTTTGACTCATCGCGTTGGGAAGCGTTTCACCATAAAGACTATCGGTATCTGGGGCAAGATCTGGATGGATGATAACATCAAGTTGAAGAACCACACTAACATAGTCATCTTTTTCTTAGTGCGTGACCGGCGTCCTAGTGGAGAACCAGTTTCTTTTGGAAGTTTGTTTAATATGTTCGATAACGAGCCAACTACGGCCACTGTGAAGCAAGAATATCGTGATCGTTTTCAGGTTATGAGGAGGTTTCATGCATCTGTTACCGGTGGACAGTACGCTTCAAAGGAACAGGCGTTGGTTAAGCGTTTTTTCAGGAACATTAATCATCGAGTTGTTTACAACCAACAAGAAGGCGCAGAGTACAAGAATCATCATGAAAATGCTTTGATGTTGTATATGGCATGTAGTCATGCCTCTAATCCTGTGTACGCGACAATTAAAGTTCGCATTTATTTTTACGACTCCATTACGAATTAATAAAGATTGAATATTATTTCATATTTTGGGTCTACATCAATTGTTCCATGAATTACATCAAACAACACATGATCGCACGCTAAAATACATGTATTAATTGAAATGACACCTAATCTATCTAAATAACGCATAACTTGTGTTTTAAAGACTCTCAAGAAACGCCAGGTCTGACTCCGTAAGACTGTTGAGATAGTCAATGTCATCCAGCATTTGTGAATCCCCAAGGCTTTCCTGAGGTTGTGGTTGAACTGGAGTCGAATTACTATTTCGTGGAACGGTAATCCCATTACCCATTCGTGGTGGCTCATCACCTTGAAATATATTGCATTTGGGACTGTCCAGATATAGGCGCCATTCTGCGCTTGAGCTGCAGTGATGGACTCCCCTGTGCGTAAATCCATGGTTGGCACACTCTATTGCGAGGTAGTATGAACAACCACAGGTTAAATCAACTCGTCGGCGCCTGATCTGTTTCTTTTTAGCTATTCTGTGTCTGACTTTTATTGGAATTTGAGTAGAGCGGGAAGGAGATGTCGACGAAGATTGCATTCTTTAATGCCCACTGCTTTAAATCTTTATTTTTATCTTCATCCAAGAAGCTTTTATAGGAGCTATTTGGTCCTGGATTGCAGAGGAAGATAGTGGGAATTCCTCCTTTAATTTGAATTGGTTTCCCGTACTTTGTGTTGCTTTGCCAATCGTGCTGGGCACCCATGAATTCTTTAAAGTGCTTTAGATAGTGCGGATCGACGTCATCGATGACGTTATACCAGGCATTATTGCTATACACTTTTGGACTTAGGTCCAGATGACCGCATAGGTAATTGTGCGCACCTAATGATCTGGCCCACATTGTTTTCCCTGTTCTTGACTCCCCTTCAATGACTATGCTAATCGGTCTATCCGGCCGCGCAGCGGCATCCACCACGTTGATTGACGCCCAATCTTTCATGATCTGAGGAACGTTATTGAATGAGTTTAACCTAAACGGACAAGAATAGGGCTCTAATGGCTTACTGAAAATGCGATCTAAGTTGCTTTTAATGTTGTGGTAATGTAAGACGAAGTCCTTCGGAGCAAGTTCTTTCACAATGTTGAGAGCCTTCGTCGGACTTCCAGAGTTAATTGCTGCGGCGTAAGCGTCGTTGGCTGATTGTTGTCCTCCTCGGCTAGATCTTCCATCGATCTGGAATTCGCCCCATGAGATGGTGTCTCCATCCTTCTCGATATAGGACTTGACGTCGGAGCTCGATTTTGCTCCCTGAATGTTTGGATGAAACACGGCAGATCTGTTTCCAGAGACAAGGTCGAACAGTCTTGGATTTGTGATCTGGAGCTTACCTTCGAATTGTAGCAGTACGTGCAGATGAGGTTCCCCATCTTCGTGTAATTCCCTTGCTACCTTGATGAATTTCTTATTGACGGCTGTTGGTATCTGCCGGAGAAGCTCTAGGGCTTCCTCTTTCGGAAGAGAGCATCTGGGATAAGTGGCGAAAATGTTTTTGGCATTCACTCTAAACGCTCCGCTGCGTGGCATATTTGCAATTCTTGCGTTTACACCGATTGCTCTCAAAATCTTTTATCGCATATATTGGTGTAACGGGGTACCTAATATACTATATACCCCAATACACCTGGTAGTGACATCTGTCCCTAGTCCCCACACCTTTAGCGGCCCTCAGTATAATATT
Gene Information
|
NCBI Accession
|
AAB87605.1
|
|
Location
|
113-451 |
|
Gene Name
|
v2 |
|
Protein Name
|
precoat protein |
|
Coding Region
|
ATGTTTAACCCACTAACTGAACCCCTCCCAGTTACTCCTCACGGTTTGATGTGTATGTTGGCTTTGAAATATTTGCAGGAGTTCGAGAAATCTGTACATTTGACTCCGTGTGATAATACTGAGTTGTTGTTACTCCGCCGTGTTATTCGTGCAAGGACTTACGATGAAGCGAAGCGCCGATACCATATATTCCACACCTTCCAAGGCTCGAAGGAGGTTGACGTTCGACACCCCTCGTGCGACTCCTGCGTCCTTAGGGCGTTCCAACAAAAGGCGGGCTTGGGAGAACCGGCCCATGAACCGCAAGCCCATGATGTACCGGCTTTGGAGGAGTCCTGA |
|
Protein Sequence
|
MFNPLTEPLPVTPHGLMCMLALKYLQEFEKSVHLTPCDNTELLLLRRVIRARTYDEAKRRYHIFHTFQGSKEVDVRHPSCDSCVLRAFQQKAGLGEPAHEPQAHDVPALEES |
|
NCBI Accession
|
AAB87606.1
|
|
Location
|
276-1037 |
|
Gene Name
|
cp |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGAAGCGAAGCGCCGATACCATATATTCCACACCTTCCAAGGCTCGAAGGAGGTTGACGTTCGACACCCCTCGTGCGACTCCTGCGTCCTTAGGGCGTTCCAACAAAAGGCGGGCTTGGGAGAACCGGCCCATGAACCGCAAGCCCATGATGTACCGGCTTTGGAGGAGTCCTGATGTTCCGTATGGTTGTGAGGGTCCATGTAAGGTTCAGTCTTTCGAGGCCAGACACGACGTCAAACACACGGGAACTTTTCAGTGTTGTTCAGACGTTACTCGGGGAATGGGTTTGACTCATCGCGTTGGGAAGCGTTTCACCATAAAGACTATCGGTATCTGGGGCAAGATCTGGATGGATGATAACATCAAGTTGAAGAACCACACTAACATAGTCATCTTTTTCTTAGTGCGTGACCGGCGTCCTAGTGGAGAACCAGTTTCTTTTGGAAGTTTGTTTAATATGTTCGATAACGAGCCAACTACGGCCACTGTGAAGCAAGAATATCGTGATCGTTTTCAGGTTATGAGGAGGTTTCATGCATCTGTTACCGGTGGACAGTACGCTTCAAAGGAACAGGCGTTGGTTAAGCGTTTTTTCAGGAACATTAATCATCGAGTTGTTTACAACCAACAAGAAGGCGCAGAGTACAAGAATCATCATGAAAATGCTTTGATGTTGTATATGGCATGTAGTCATGCCTCTAATCCTGTGTACGCGACAATTAAAGTTCGCATTTATTTTTACGACTCCATTACGAATTAA |
|
Protein Sequence
|
MKRSADTIYSTPSKARRRLTFDTPRATPASLGRSNKRRAWENRPMNRKPMMYRLWRSPDVPYGCEGPCKVQSFEARHDVKHTGTFQCCSDVTRGMGLTHRVGKRFTIKTIGIWGKIWMDDNIKLKNHTNIVIFFLVRDRRPSGEPVSFGSLFNMFDNEPTTATVKQEYRDRFQVMRRFHASVTGGQYASKEQALVKRFFRNINHRVVYNQQEGAEYKNHHENALMLYMACSHASNPVYATIKVRIYFYDSITN |
|
NCBI Accession
|
AAB87609.1
|
|
Location
|
1034-1438 |
|
Gene Name
|
c3 |
|
Protein Name
|
c3 protein |
|
Coding Region
|
ATGGATTTACGCACAGGGGAGTCCATCACTGCAGCTCAAGCGCAGAATGGCGCCTATATCTGGACAGTCCCAAATGCAATATATTTCAAGGTGATGAGCCACCACGAATGGGTAATGGGATTACCGTTCCACGAAATAGTAATTCGACTCCAGTTCAACCACAACCTCAGGAAAGCCTTGGGGATTCACAAATGCTGGATGACATTGACTATCTCAACAGTCTTACGGAGTCAGACCTGGCGTTTCTTGAGAGTCTTTAAAACACAAGTTATGCGTTATTTAGATAGATTAGGTGTCATTTCAATTAATACATGTATTTTAGCGTGCGATCATGTGTTGTTTGATGTAATTCATGGAACAATTGATGTAGACCCAAAATATGAAATAATATTCAATCTTTATTAA |
|
Protein Sequence
|
MDLRTGESITAAQAQNGAYIWTVPNAIYFKVMSHHEWVMGLPFHEIVIRLQFNHNLRKALGIHKCWMTLTISTVLRSQTWRFLRVFKTQVMRYLDRLGVISINTCILACDHVLFDVIHGTIDVDPKYEIIFNLY |
|
NCBI Accession
|
AAB87608.1
|
|
Location
|
1179-1586 |
|
Gene Name
|
trap |
|
Protein Name
|
transcription activation protein |
|
Coding Region
|
ATGCAATCTTCGTCGACATCTCCTTCCCGCTCTACTCAAATTCCAATAAAAGTCAGACACAGAATAGCTAAAAAGAAACAGATCAGGCGCCGACGAGTTGATTTAACCTGTGGTTGTTCATACTACCTCGCAATAGAGTGTGCCAACCATGGATTTACGCACAGGGGAGTCCATCACTGCAGCTCAAGCGCAGAATGGCGCCTATATCTGGACAGTCCCAAATGCAATATATTTCAAGGTGATGAGCCACCACGAATGGGTAATGGGATTACCGTTCCACGAAATAGTAATTCGACTCCAGTTCAACCACAACCTCAGGAAAGCCTTGGGGATTCACAAATGCTGGATGACATTGACTATCTCAACAGTCTTACGGAGTCAGACCTGGCGTTTCTTGAGAGTCTTTAA |
|
Protein Sequence
|
MQSSSTSPSRSTQIPIKVRHRIAKKKQIRRRRVDLTCGCSYYLAIECANHGFTHRGVHHCSSSAEWRLYLDSPKCNIFQGDEPPRMGNGITVPRNSNSTPVQPQPQESLGDSQMLDDIDYLNSLTESDLAFLESL |
|
NCBI Accession
|
AAB87607.1
|
|
Location
|
1516-2574 |
|
Gene Name
|
rep |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCACGCAGCGGAGCGTTTAGAGTGAATGCCAAAAACATTTTCGCCACTTATCCCAGATGCTCTCTTCCGAAAGAGGAAGCCCTAGAGCTTCTCCGGCAGATACCAACAGCCGTCAATAAGAAATTCATCAAGGTAGCAAGGGAATTACACGAAGATGGGGAACCTCATCTGCACGTACTGCTACAATTCGAAGGTAAGCTCCAGATCACAAATCCAAGACTGTTCGACCTTGTCTCTGGAAACAGATCTGCCGTGTTTCATCCAAACATTCAGGGAGCAAAATCGAGCTCCGACGTCAAGTCCTATATCGAGAAGGATGGAGACACCATCTCATGGGGCGAATTCCAGATCGATGGAAGATCTAGCCGAGGAGGACAACAATCAGCCAACGACGCTTACGCCGCAGCAATTAACTCTGGAAGTCCGACGAAGGCTCTCAACATTGTGAAAGAACTTGCTCCGAAGGACTTCGTCTTACATTACCACAACATTAAAAGCAACTTAGATCGCATTTTCAGTAAGCCATTAGAGCCCTATTCTTGTCCGTTTAGGTTAAACTCATTCAATAACGTTCCTCAGATCATGAAAGATTGGGCGTCAATCAACGTGGTGGATGCCGCTGCGCGGCCGGATAGACCGATTAGCATAGTCATTGAAGGGGAGTCAAGAACAGGGAAAACAATGTGGGCCAGATCATTAGGTGCGCACAATTACCTATGCGGTCATCTGGACCTAAGTCCAAAAGTGTATAGCAATAATGCCTGGTATAACGTCATCGATGACGTCGATCCGCACTATCTAAAGCACTTTAAAGAATTCATGGGTGCCCAGCACGATTGGCAAAGCAACACAAAGTACGGGAAACCAATTCAAATTAAAGGAGGAATTCCCACTATCTTCCTCTGCAATCCAGGACCAAATAGCTCCTATAAAAGCTTCTTGGATGAAGATAAAAATAAAGATTTAAAGCAGTGGGCATTAAAGAATGCAATCTTCGTCGACATCTCCTTCCCGCTCTACTCAAATTCCAATAAAAGTCAGACACAGAATAGCTAA |
|
Protein Sequence
|
MPRSGAFRVNAKNIFATYPRCSLPKEEALELLRQIPTAVNKKFIKVARELHEDGEPHLHVLLQFEGKLQITNPRLFDLVSGNRSAVFHPNIQGAKSSSDVKSYIEKDGDTISWGEFQIDGRSSRGGQQSANDAYAAAINSGSPTKALNIVKELAPKDFVLHYHNIKSNLDRIFSKPLEPYSCPFRLNSFNNVPQIMKDWASINVVDAAARPDRPISIVIEGESRTGKTMWARSLGAHNYLCGHLDLSPKVYSNNAWYNVIDDVDPHYLKHFKEFMGAQHDWQSNTKYGKPIQIKGGIPTIFLCNPGPNSSYKSFLDEDKNKDLKQWALKNAIFVDISFPLYSNSNKSQTQNS |
|
NCBI Accession
|
AAB87610.1
|
|
Location
|
2124-2417 |
|
Gene Name
|
c4 |
|
Protein Name
|
c4 protein |
|
Coding Region
|
ATGGGGAACCTCATCTGCACGTACTGCTACAATTCGAAGGTAAGCTCCAGATCACAAATCCAAGACTGTTCGACCTTGTCTCTGGAAACAGATCTGCCGTGTTTCATCCAAACATTCAGGGAGCAAAATCGAGCTCCGACGTCAAGTCCTATATCGAGAAGGATGGAGACACCATCTCATGGGGCGAATTCCAGATCGATGGAAGATCTAGCCGAGGAGGACAACAATCAGCCAACGACGCTTACGCCGCAGCAATTAACTCTGGAAGTCCGACGAAGGCTCTCAACATTGTGA |
|
Protein Sequence
|
MGNLICTYCYNSKVSSRSQIQDCSTLSLETDLPCFIQTFREQNRAPTSSPISRRMETPSHGANSRSMEDLAEEDNNQPTTLTPQQLTLEVRRRLSTL |