African cassava mosaic Burkina Faso virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_004786835.1 |
| Isolate |
Burkina Faso:Ouagadougou |
| Release date |
2021/6/1 |
| Submitter |
Tiendrebeogo,F., Lefeuvre,P., Hoareau,M., Harimalala,M.A., Villemot,J., Traore,V.S.E., Konate,G., Traore,A.S., Barro,N., Reynaud,B., Traore,O., Lett,J.M. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
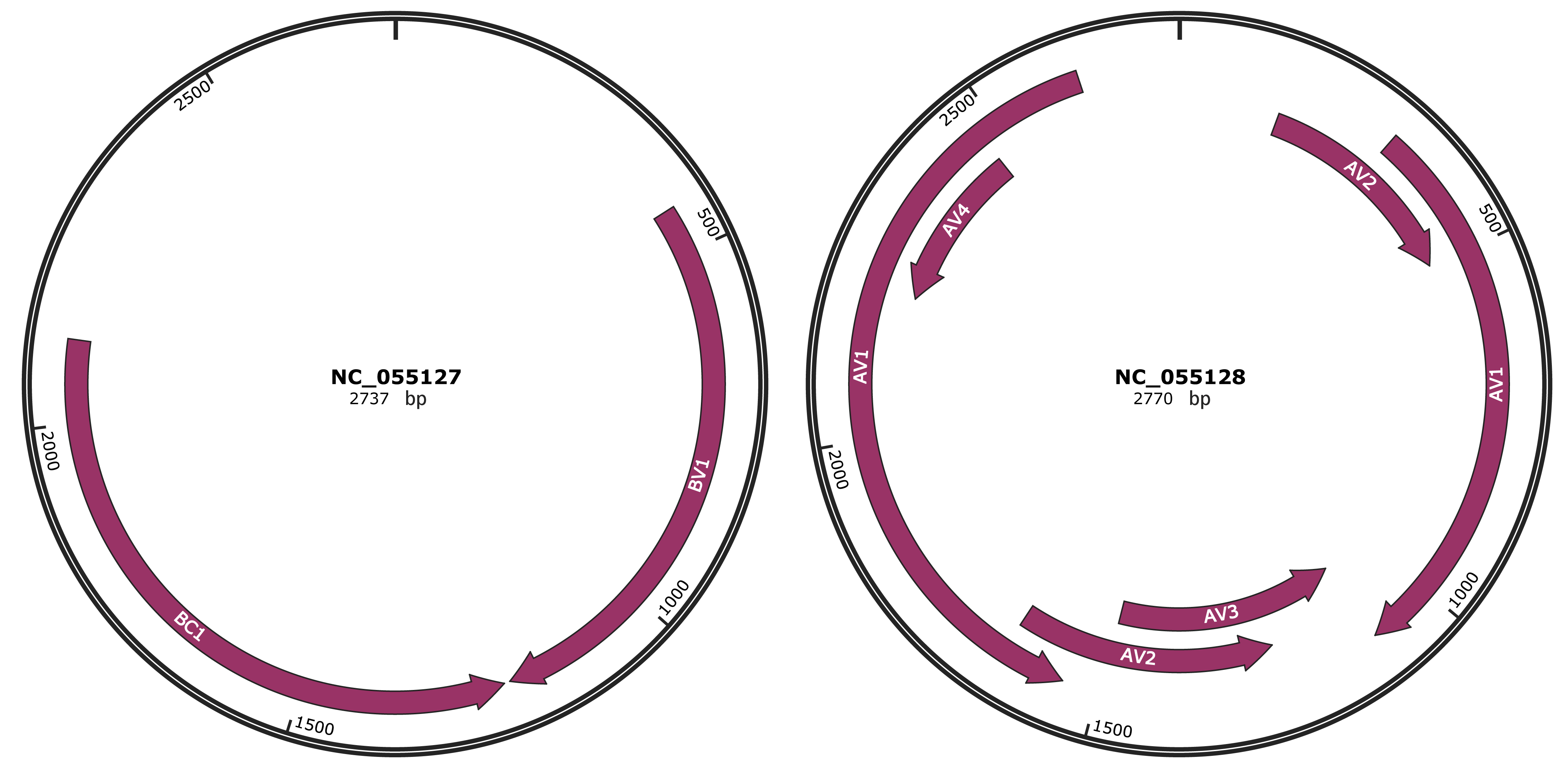
JBrowse
Genome
ACCGGTTGGCCCCGCCCCCCTTTAAACGTGGTCCCCTCGCACATGTTGGCCTCGCCTTTTTTTTTGAAAGGGGTCCCCCCCACATGTTTCTCTTACCTGCGTATACTACGGTGGTCCCCGCATGCATGTGTTGTCTGCTATGGATAATGCATGTGTGGCCCACATGCAAATAAATGATCTGCGGGCCTATCGAATGACAGCCTGTGCTACTAAATTATATTTAGTATATTGGTCATTTCTCTGAGTTAATAAAATGGTATATTTTATTGAACTGTTAATATTGCCATTCGATAGTAGTGATTTATAATCATCAATCTGACAACGATCATGAAGGACAATTAAGGCTAGTAGCGTAATCGTGTATGTATTATATATAGGGTTCTAACATGCATGAGTTGGAGTATATCAGGTATCGGAATTATATACATTGATTTGTAATGTATACTATCAGGAAGCAGTCTAGAAACTTCCAAAGGAAATTTAACAGCAATACCACTAACAGATATCCAATCAGGCGTAAGTATGTTGGTGGGCATACTAGACCATCTGTTAGGCGAAGATTGTCATATGAGCCAGTGGAGAGACCGTTGGTCCATAATGTTTTATGTGAGAAGCAACATGGTGATGTGTTTAATTTGCAGCAGAACACAAGTTACACGTCATTTGTGACTTATCCTTCCAGGGGACCATCTGGTGATGGGCGTAGTCGGGATTACATCAAGTTGCAAAGTATGTCCGTCTCGGGAGTGATACATGCGAAGGCGAATGGCATTGATGATCCTATGGAGGTGTCTAATGTAGTTAATGGAGTGTTCGTGTTTAGTGTAATCATGGACACAAAGCCTTATTTACCTGCCGGTGTTCAAGCTCTTCCGACATTTGAAGAGCTGTTCGGATCATATTCCGCTTGTTACGTTAATTTAAGATTATTGAATAATCAACAGCATCGATATAGGGTCTTGCACAGCGTGAAACGTTTCGTGTCATCTGCAGGAGATACTAAGGTATCGCAATTTAGGTTTAATAAGCGATTGAGCACCAGGCGATATAATATTTGGACATCATTCCATGATGGGGATATGGTAAATGCAGGTGGAAATTATAGGAACATAAGCAAGAATGCTATTCTTGTTAGTTATGCTTTTGTATCAGAGCATTCAATGTCTTGTAATCCATTTGTACAAATAGAAACATCCTATGTTGGATGATGTATTATTCATAAATCTTTATGGCTACTGCCTCTATGTGCTATTAAGCACTTGTTTACAGTGTGTTCTATAATGCTTTCAATGTCCTTTTTCGACATGGAGTGGGTTTGTGAAACGGAGTCCCCTGGATCTAGGGAAGCTTCAGGTAGCTTGTGTAGTCCTCGAAGTGGGAATTCAGCCTCAGAGGCATACTGCTTGGAGGATGATTCGTCGAAATCAATTTGTTTGGGGCCTGTGTATCTGATGCTGGTAGAGCGCCCAATTGTGGATTTTGTAGCCCATGTTTCCCCTGGTTGGACCGTGATGGGCCTATATTTAGGCCCAGTGTCATAATCTGTACCGGTCTCATTCTGAATGAGCCTTCGAATGGGCTTAGGTTTTCCAACGGACCAGAAGTCCACACAGTCAGGCCCATAGTCTTTGGATAGTATTTTTATAGTGGGCTGTTTAAATCGAATGTCCGTTGAATGTTTGGCAGCTGACAGCTTCAGTTTTGCCTTAATTTGGGCAAATGTGATGCCATTCTTTACGTTTGAGTCTTCAACCTTATACAGCAGCTGCCATGGTACGTTATCATCAATTGAAAAGTAAGATGCAGAGAAATAATGGAGGTCCACATTACACCCAATGGGAAATGTGAATTGGGCTTGGTCTTGTTGCTCATCACTGAGCCTAGTGTCCCGAATGGTAACGATAACAGAACCCTGTGCATTAAAGGGCACTTGATTCCTGTATTCAATGACGACATGGTCGACCTTCATGCATTTGCCCATGATACGTACCCTTGTTCTTTCAAGGGTCGAAGGAAATTGAAGTGTAATCGGTGATTCATCATTCGTCAGTTTGTATTCTGTTCTTGCTGATTGAATATAGTCGCTGGATATGACAGGTACAGATGTATCCATAGTCAACACTCGGATTATAAGCGTGTCAAAGCCACAGCACCTGTCTCATGATAAACATGAATAATCTATTATTAAACTGGCCGCGCAGCGGAATGGCTTTAATGCAAGATAAATCAGAAGCTTTTGTCAACAGGGTAAACATATTGTAGAAATATATACATATATGTGGTATCCTATCGGAAAAATGCGTCTATGTTTAATCCAAATCAAACATATATACATGCATACAGCATTAGTCGTTGAAACATTATTTATATATAGATATGTACCTGATAATAACTTAAATTGGATATCTGCTGGAGTGGAATGTGGATAGTCTTATTAGCAAAGTGGTCATATAAATATGTTTTATATATTTATTAAGGAGTTATCCAACGAGTGATAGTTTACGTTGTTAGATTTGCATGTTCAAATCTAAAATAAGCAACTACACTATAGTGAGAGAAAGTTAGAGAGAGACGCTCTCAACTAGCACCGATTGACTGCCCTGGATACTTCTCCCCTGTTAATTGGGGTCCTATATATAGTTTGCACCAAATGGCATAATGGTAATAAGTTCAACTTTAATTTGAATGAAAAGGCTCAAAATGCGCAGAACACCCAAGGGGCCAACCGTATAATATT
ACCGGTGGGCGCGAAAAAAAAAAAAGTGGTCCCCTCCCCCCTTTAAACGTGGTCCCCGCGCACTATGTATGTCGGCCAATCATGCTGTAGCGTTAAAGGTCATTTAATAGTGGTGGACCACTATATACTTACAGGCGAAGTTGTTGCTAGTGCGCAATGTGGGATCCACTGGTGAATGAGTTTCCAGACTCGGTGCATGGGCTGAGGTGTATGCTTGCAATTAAATATTTGCAGGCCTTAGAGGATACATACGAGCCCAGTACTTTGGGCCACGATCTGTTTAGAGATCTAATCTCGGTTATCAGGGCTCGTAATTATGTCGAAGCGTCCAGGAGATATCATCATTTCCACGCCAGGATCCAAGGTTCGTCGAAGGCTGAACTTCGACAGCCCATACAGGAACCGTGCTACTGCCCCCACTGTCCACGTCACAAATCGAAAACGGGCCTGGATGAACAGGCCCATGTACAGAAAGCCCATGATGTACAGGATGTATAGAAGCCCAGACATACCTAGGGGCTGTGAAGGTCCATGTAAGGTCCAGTCGTTTGAGCAGAGGGATGATGTGAAGCACCTTGGTATCTGTAAGGTGATTAGTGATGTGACACGTGGGCCTGGGCTGACACACAGAGTCGGTAAGAGGTTTTGTATCAAGTCCATTTACATTCTTGGTAAGATCTGGATGGATGAAAATATTAAGAAGCAGAATCACACGAATAATGTAATGTTTTATCTGCTTAGGGATAGAAGGCCTTATGGCAATACGCCCCAAGACTTTGGGCAGATATTTAACATGTTTGATAATGAGCCCAGTACTGCAACAATTAAGAACGATTTGAGGGATAGGTTTCAGGTTTTGAGGAAATTTCATGCCACTGTTATTGGTGGTCCATCTGGCATGAAGGAGCAGGCGTTGGTGAAAAGGTTTTACAGGTTGAATCATCACGTGACATATAATCATCAAGAGGCAGGGAAATACGAGAATCACACAGAGAATGCATTGCTTTTGTATATGGCATGTACTCATGCCTCCAATCCTGTATATGCTACGTTGAAAATACGTATATACTTCTATGACAGTATTGGGAATTAATAAACATTGAATTTTATTTCATGAGTCAACTGACACTCAATAGTTTTTTCAATTACATTGAACAAAACATGATCAGAAGCTCTAATTACACTGTTAATTGAGATAACACCTATATTATCCAAGTATTTAAGTACTTGGTATCTAAAGACCCTTAAGAAAAGACCAGTCTGAGGCCGTAAGGTCGTCCAGATCCTGAAGGTTAGAAAACATTTGTGAATCCCCAACTCCTTCCTCAGGTTGTGATTGAATCGAACTTGGACGGTTATGATGTCCTGGTTCATCAGGAATGGGCGTTGTTGGTGCTCGGTTATTGTGAAATACAGGGGATTGTTTATTTCCCAGGTATACACGCCATTCATTGCTTGAGGAGCAGTGATGAGTTCCCCTGTGCGTAAATCCATGATTGGAGCAGTTGATATGGAGGTAATATGAACAGCCACAAACAAGATCCACTCTCCTACGCCGGATGGCTCGCGTCTTGAATTGTCTGTGACTGACTTTGATTGGAACCGGAGTAGAGTGGTTCTGTGAGGGTGATGAAGATTGCATTCTTTAATGCCCAGGCCTTTAGCGCTTGTTGCTTTTCCTCGTCTAGGAACTCTTTATAGGACGAGGTAGGTCCTGGATTGCAGAGGAAGATAGTGGGAATTCCACCTTTAATTTGAATGGGCTTCCCGTATTTGGTGTTGCTTTGCCAGTCTCTTTGGGCCCCCATGAACTCTTTAAAGTGTTTGAGATAGTGGGGATCGACGTCATCAATGACGTTATACCAAGCATCATTTGAATACACCTTTGGACTCAGATCTAGATGCCCACACAAGTAATTGTGTGGACCTAATGACCTGGCCCACATTGTCTTGCCTGTACGACTATCACCTTCAATAACTATACTAGTCGGTCTCCAAGGCCGCGCAGCGGAACTCATGACGTTCTCAGAAACCCAGTCTTCAAGTTCTTCCGGAACGTGAGTAAAAGAAGAAGATAAAAAAGGAGAAATATATGGCTCTGGAGGGGCCATGAAAATCCTATCTAAATTATTTTTTAAATTATGATATTGAAAAATAAATTCTTTAGGGAGTTTCTCCCTAATAATAGCCATAGCGGCGTCAGCGGAACCTGCATTTAAGGCCTCTGCTGCAGCGTCGTTAGCGTTCTGGCAGCCTCCCCTAGCACTTCTTCCGTCGACCTGGAATTCTCCCCATTCAAGGGTGTCTCCGTCCTTGTCGATGTAGGACTTGACATCGGAGCTTGATTTAGCTCCTTGAATGTTTGGATGGAAATGTGCTGACCTGGTTGGGGATACCAGGTCGAAGAATCGTTGATTTTGGCAGTTGTATTTTCCTTCGAACTGAATAAGCACATGGAGATGAGGCTCCCCATCGTCGTGTAATTCTTTGCAGATTTTGATGTATTTTTTGTTTGTTGGTGTTTCTAAGTTTCTGATTTGGGAAAGTGCTTCGTCTTTTGTGAGAGAGCATTTGGGATATGTGAGGAAATAATTTTTGGAGTTAATTCTGAATTTTCGAGGAGGAGCCATTTGGTCAACTAGCACCGATTGACTCTTCTGTGATTTATCCCTAGTGTATTGGGGTTCTATATATACTTAGCACCAAATGGCATTGTCGTAATAATCCCAACAAATTTTGAACCCCCATTAGCGCCCACCGTTCTAATATT
Gene Information
|
NCBI Accession
|
YP_010084323.1
|
|
Location
|
438-1208 |
|
Gene Name
|
BV1 |
|
Protein Name
|
movement protein (MP) |
|
Coding Region
|
ATGTATACTATCAGGAAGCAGTCTAGAAACTTCCAAAGGAAATTTAACAGCAATACCACTAACAGATATCCAATCAGGCGTAAGTATGTTGGTGGGCATACTAGACCATCTGTTAGGCGAAGATTGTCATATGAGCCAGTGGAGAGACCGTTGGTCCATAATGTTTTATGTGAGAAGCAACATGGTGATGTGTTTAATTTGCAGCAGAACACAAGTTACACGTCATTTGTGACTTATCCTTCCAGGGGACCATCTGGTGATGGGCGTAGTCGGGATTACATCAAGTTGCAAAGTATGTCCGTCTCGGGAGTGATACATGCGAAGGCGAATGGCATTGATGATCCTATGGAGGTGTCTAATGTAGTTAATGGAGTGTTCGTGTTTAGTGTAATCATGGACACAAAGCCTTATTTACCTGCCGGTGTTCAAGCTCTTCCGACATTTGAAGAGCTGTTCGGATCATATTCCGCTTGTTACGTTAATTTAAGATTATTGAATAATCAACAGCATCGATATAGGGTCTTGCACAGCGTGAAACGTTTCGTGTCATCTGCAGGAGATACTAAGGTATCGCAATTTAGGTTTAATAAGCGATTGAGCACCAGGCGATATAATATTTGGACATCATTCCATGATGGGGATATGGTAAATGCAGGTGGAAATTATAGGAACATAAGCAAGAATGCTATTCTTGTTAGTTATGCTTTTGTATCAGAGCATTCAATGTCTTGTAATCCATTTGTACAAATAGAAACATCCTATGTTGGATGA |
|
Protein Sequence
|
MYTIRKQSRNFQRKFNSNTTNRYPIRRKYVGGHTRPSVRRRLSYEPVERPLVHNVLCEKQHGDVFNLQQNTSYTSFVTYPSRGPSGDGRSRDYIKLQSMSVSGVIHAKANGIDDPMEVSNVVNGVFVFSVIMDTKPYLPAGVQALPTFEELFGSYSACYVNLRLLNNQQHRYRVLHSVKRFVSSAGDTKVSQFRFNKRLSTRRYNIWTSFHDGDMVNAGGNYRNISKNAILVSYAFVSEHSMSCNPFVQIETSYVG |
|
NCBI Accession
|
YP_010084324.1
|
|
Location
|
1217-2113 |
|
Gene Name
|
BC1 |
|
Protein Name
|
nuclear shuttle protein (NSP) |
|
Coding Region
|
ATGGATACATCTGTACCTGTCATATCCAGCGACTATATTCAATCAGCAAGAACAGAATACAAACTGACGAATGATGAATCACCGATTACACTTCAATTTCCTTCGACCCTTGAAAGAACAAGGGTACGTATCATGGGCAAATGCATGAAGGTCGACCATGTCGTCATTGAATACAGGAATCAAGTGCCCTTTAATGCACAGGGTTCTGTTATCGTTACCATTCGGGACACTAGGCTCAGTGATGAGCAACAAGACCAAGCCCAATTCACATTTCCCATTGGGTGTAATGTGGACCTCCATTATTTCTCTGCATCTTACTTTTCAATTGATGATAACGTACCATGGCAGCTGCTGTATAAGGTTGAAGACTCAAACGTAAAGAATGGCATCACATTTGCCCAAATTAAGGCAAAACTGAAGCTGTCAGCTGCCAAACATTCAACGGACATTCGATTTAAACAGCCCACTATAAAAATACTATCCAAAGACTATGGGCCTGACTGTGTGGACTTCTGGTCCGTTGGAAAACCTAAGCCCATTCGAAGGCTCATTCAGAATGAGACCGGTACAGATTATGACACTGGGCCTAAATATAGGCCCATCACGGTCCAACCAGGGGAAACATGGGCTACAAAATCCACAATTGGGCGCTCTACCAGCATCAGATACACAGGCCCCAAACAAATTGATTTCGACGAATCATCCTCCAAGCAGTATGCCTCTGAGGCTGAATTCCCACTTCGAGGACTACACAAGCTACCTGAAGCTTCCCTAGATCCAGGGGACTCCGTTTCACAAACCCACTCCATGTCGAAAAAGGACATTGAAAGCATTATAGAACACACTGTAAACAAGTGCTTAATAGCACATAGAGGCAGTAGCCATAAAGATTTATGA |
|
Protein Sequence
|
MDTSVPVISSDYIQSARTEYKLTNDESPITLQFPSTLERTRVRIMGKCMKVDHVVIEYRNQVPFNAQGSVIVTIRDTRLSDEQQDQAQFTFPIGCNVDLHYFSASYFSIDDNVPWQLLYKVEDSNVKNGITFAQIKAKLKLSAAKHSTDIRFKQPTIKILSKDYGPDCVDFWSVGKPKPIRRLIQNETGTDYDTGPKYRPITVQPGETWATKSTIGRSTSIRYTGPKQIDFDESSSKQYASEAEFPLRGLHKLPEASLDPGDSVSQTHSMSKKDIESIIEHTVNKCLIAHRGSSHKDL |
|
NCBI Accession
|
YP_010084325.1
|
|
Location
|
157-498 |
|
Gene Name
|
AV2 |
|
Protein Name
|
AV2 protein |
|
Coding Region
|
ATGTGGGATCCACTGGTGAATGAGTTTCCAGACTCGGTGCATGGGCTGAGGTGTATGCTTGCAATTAAATATTTGCAGGCCTTAGAGGATACATACGAGCCCAGTACTTTGGGCCACGATCTGTTTAGAGATCTAATCTCGGTTATCAGGGCTCGTAATTATGTCGAAGCGTCCAGGAGATATCATCATTTCCACGCCAGGATCCAAGGTTCGTCGAAGGCTGAACTTCGACAGCCCATACAGGAACCGTGCTACTGCCCCCACTGTCCACGTCACAAATCGAAAACGGGCCTGGATGAACAGGCCCATGTACAGAAAGCCCATGATGTACAGGATGTATAG |
|
Protein Sequence
|
MWDPLVNEFPDSVHGLRCMLAIKYLQALEDTYEPSTLGHDLFRDLISVIRARNYVEASRRYHHFHARIQGSSKAELRQPIQEPCYCPHCPRHKSKTGLDEQAHVQKAHDVQDV |
|
NCBI Accession
|
YP_010084326.1
|
|
Location
|
317-1093 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein (CP) |
|
Coding Region
|
ATGTCGAAGCGTCCAGGAGATATCATCATTTCCACGCCAGGATCCAAGGTTCGTCGAAGGCTGAACTTCGACAGCCCATACAGGAACCGTGCTACTGCCCCCACTGTCCACGTCACAAATCGAAAACGGGCCTGGATGAACAGGCCCATGTACAGAAAGCCCATGATGTACAGGATGTATAGAAGCCCAGACATACCTAGGGGCTGTGAAGGTCCATGTAAGGTCCAGTCGTTTGAGCAGAGGGATGATGTGAAGCACCTTGGTATCTGTAAGGTGATTAGTGATGTGACACGTGGGCCTGGGCTGACACACAGAGTCGGTAAGAGGTTTTGTATCAAGTCCATTTACATTCTTGGTAAGATCTGGATGGATGAAAATATTAAGAAGCAGAATCACACGAATAATGTAATGTTTTATCTGCTTAGGGATAGAAGGCCTTATGGCAATACGCCCCAAGACTTTGGGCAGATATTTAACATGTTTGATAATGAGCCCAGTACTGCAACAATTAAGAACGATTTGAGGGATAGGTTTCAGGTTTTGAGGAAATTTCATGCCACTGTTATTGGTGGTCCATCTGGCATGAAGGAGCAGGCGTTGGTGAAAAGGTTTTACAGGTTGAATCATCACGTGACATATAATCATCAAGAGGCAGGGAAATACGAGAATCACACAGAGAATGCATTGCTTTTGTATATGGCATGTACTCATGCCTCCAATCCTGTATATGCTACGTTGAAAATACGTATATACTTCTATGACAGTATTGGGAATTAA |
|
Protein Sequence
|
MSKRPGDIIISTPGSKVRRRLNFDSPYRNRATAPTVHVTNRKRAWMNRPMYRKPMMYRMYRSPDIPRGCEGPCKVQSFEQRDDVKHLGICKVISDVTRGPGLTHRVGKRFCIKSIYILGKIWMDENIKKQNHTNNVMFYLLRDRRPYGNTPQDFGQIFNMFDNEPSTATIKNDLRDRFQVLRKFHATVIGGPSGMKEQALVKRFYRLNHHVTYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIGN |
|
NCBI Accession
|
YP_010084327.1
|
|
Location
|
1090-1494 |
|
Gene Name
|
AV3 |
|
Protein Name
|
replication enhancer protein (REn) |
|
Coding Region
|
ATGGATTTACGCACAGGGGAACTCATCACTGCTCCTCAAGCAATGAATGGCGTGTATACCTGGGAAATAAACAATCCCCTGTATTTCACAATAACCGAGCACCAACAACGCCCATTCCTGATGAACCAGGACATCATAACCGTCCAAGTTCGATTCAATCACAACCTGAGGAAGGAGTTGGGGATTCACAAATGTTTTCTAACCTTCAGGATCTGGACGACCTTACGGCCTCAGACTGGTCTTTTCTTAAGGGTCTTTAGATACCAAGTACTTAAATACTTGGATAATATAGGTGTTATCTCAATTAACAGTGTAATTAGAGCTTCTGATCATGTTTTGTTCAATGTAATTGAAAAAACTATTGAGTGTCAGTTGACTCATGAAATAAAATTCAATGTTTATTAA |
|
Protein Sequence
|
MDLRTGELITAPQAMNGVYTWEINNPLYFTITEHQQRPFLMNQDIITVQVRFNHNLRKELGIHKCFLTFRIWTTLRPQTGLFLRVFRYQVLKYLDNIGVISINSVIRASDHVLFNVIEKTIECQLTHEIKFNVY |
|
NCBI Accession
|
YP_010084328.1
|
|
Location
|
1235-1642 |
|
Gene Name
|
AV2 |
|
Protein Name
|
transcription activator protein (TrAP) |
|
Coding Region
|
ATGCAATCTTCATCACCCTCACAGAACCACTCTACTCCGGTTCCAATCAAAGTCAGTCACAGACAATTCAAGACGCGAGCCATCCGGCGTAGGAGAGTGGATCTTGTTTGTGGCTGTTCATATTACCTCCATATCAACTGCTCCAATCATGGATTTACGCACAGGGGAACTCATCACTGCTCCTCAAGCAATGAATGGCGTGTATACCTGGGAAATAAACAATCCCCTGTATTTCACAATAACCGAGCACCAACAACGCCCATTCCTGATGAACCAGGACATCATAACCGTCCAAGTTCGATTCAATCACAACCTGAGGAAGGAGTTGGGGATTCACAAATGTTTTCTAACCTTCAGGATCTGGACGACCTTACGGCCTCAGACTGGTCTTTTCTTAAGGGTCTTTAG |
|
Protein Sequence
|
MQSSSPSQNHSTPVPIKVSHRQFKTRAIRRRRVDLVCGCSYYLHINCSNHGFTHRGTHHCSSSNEWRVYLGNKQSPVFHNNRAPTTPIPDEPGHHNRPSSIQSQPEEGVGDSQMFSNLQDLDDLTASDWSFLKGL |
|
NCBI Accession
|
YP_010084329.1
|
|
Location
|
1551-2630 |
|
Gene Name
|
AV1 |
|
Protein Name
|
replication associated protein (Rep) |
|
Coding Region
|
ATGGCTCCTCCTCGAAAATTCAGAATTAACTCCAAAAATTATTTCCTCACATATCCCAAATGCTCTCTCACAAAAGACGAAGCACTTTCCCAAATCAGAAACTTAGAAACACCAACAAACAAAAAATACATCAAAATCTGCAAAGAATTACACGACGATGGGGAGCCTCATCTCCATGTGCTTATTCAGTTCGAAGGAAAATACAACTGCCAAAATCAACGATTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCAAACATTCAAGGAGCTAAATCAAGCTCCGATGTCAAGTCCTACATCGACAAGGACGGAGACACCCTTGAATGGGGAGAATTCCAGGTCGACGGAAGAAGTGCTAGGGGAGGCTGCCAGAACGCTAACGACGCTGCAGCAGAGGCCTTAAATGCAGGTTCCGCTGACGCCGCTATGGCTATTATTAGGGAGAAACTCCCTAAAGAATTTATTTTTCAATATCATAATTTAAAAAATAATTTAGATAGGATTTTCATGGCCCCTCCAGAGCCATATATTTCTCCTTTTTTATCTTCTTCTTTTACTCACGTTCCGGAAGAACTTGAAGACTGGGTTTCTGAGAACGTCATGAGTTCCGCTGCGCGGCCTTGGAGACCGACTAGTATAGTTATTGAAGGTGATAGTCGTACAGGCAAGACAATGTGGGCCAGGTCATTAGGTCCACACAATTACTTGTGTGGGCATCTAGATCTGAGTCCAAAGGTGTATTCAAATGATGCTTGGTATAACGTCATTGATGACGTCGATCCCCACTATCTCAAACACTTTAAAGAGTTCATGGGGGCCCAAAGAGACTGGCAAAGCAACACCAAATACGGGAAGCCCATTCAAATTAAAGGTGGAATTCCCACTATCTTCCTCTGCAATCCAGGACCTACCTCGTCCTATAAAGAGTTCCTAGACGAGGAAAAGCAACAAGCGCTAAAGGCCTGGGCATTAAAGAATGCAATCTTCATCACCCTCACAGAACCACTCTACTCCGGTTCCAATCAAAGTCAGTCACAGACAATTCAAGACGCGAGCCATCCGGCGTAG |
|
Protein Sequence
|
MAPPRKFRINSKNYFLTYPKCSLTKDEALSQIRNLETPTNKKYIKICKELHDDGEPHLHVLIQFEGKYNCQNQRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQVDGRSARGGCQNANDAAAEALNAGSADAAMAIIREKLPKEFIFQYHNLKNNLDRIFMAPPEPYISPFLSSSFTHVPEELEDWVSENVMSSAARPWRPTSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEFLDEEKQQALKAWALKNAIFITLTEPLYSGSNQSQSQTIQDASHPA |
|
NCBI Accession
|
YP_010084330.1
|
|
Location
|
2216-2473 |
|
Gene Name
|
AV4 |
|
Protein Name
|
AV4 protein |
|
Coding Region
|
ATGGGGAGCCTCATCTCCATGTGCTTATTCAGTTCGAAGGAAAATACAACTGCCAAAATCAACGATTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCAAACATTCAAGGAGCTAAATCAAGCTCCGATGTCAAGTCCTACATCGACAAGGACGGAGACACCCTTGAATGGGGAGAATTCCAGGTCGACGGAAGAAGTGCTAGGGGAGGCTGCCAGAACGCTAACGACGCTGCAGCAGAGGCCTTAA |
|
Protein Sequence
|
MGSLISMCLFSSKENTTAKINDSSTWYPQPGQHISIQTFKELNQAPMSSPTSTRTETPLNGENSRSTEEVLGEAARTLTTLQQRP |