Corchorus yellow vein virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000845265.1 |
| Isolate |
Viet Nam |
| Release date |
2015/2/12 |
| Submitter |
Ha,C., Coombs,S., Revill,P., Harding,R., Vu,M., Dale,J., Ha,C.V., Revill,P.A., Harding,R.M., Vu,M.T., Dale,J.L. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
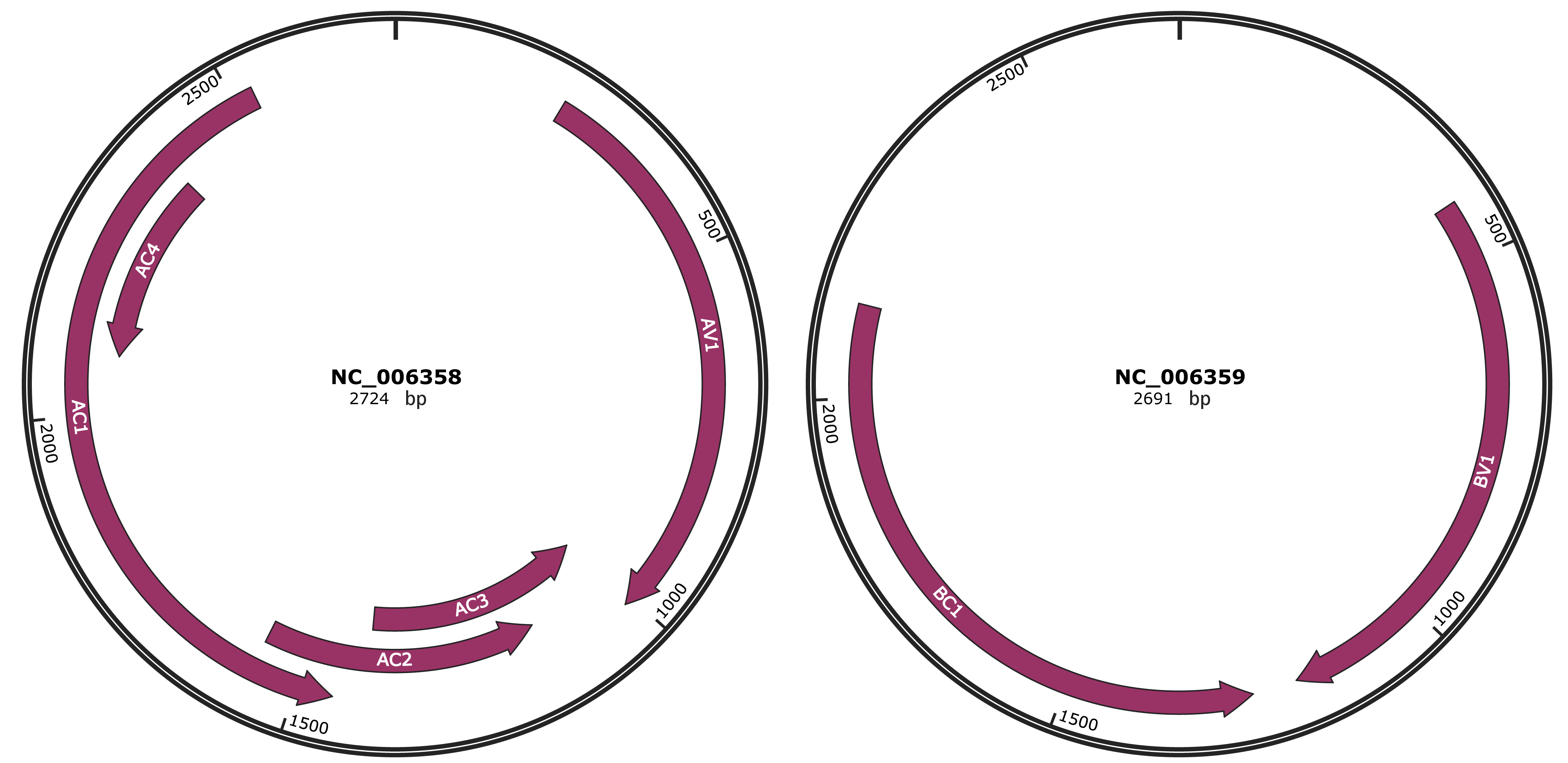
JBrowse
Genome
ACCGTGCAGCAGCCCCGCTTTTGCCGTACGCTTTACACGTGGGTGACGATTTTATTGGAATTTGCAAAAGTAAAGTTATTTGTTTTATTCAGCCAATCATTGAATGATTGGCGCGCCTAATTGTTAGTGCCGGTACTTGCTGCGTAAGTTTCAAGAGAATATTAACTGCTTTGCGCTATTATAAATTGAATTTGAATTGGATTGTACTGCTGTGGGTCCTTATTCGATAAGGATAATGCCTAAGCGCGATGCCCCATGGCGCTTGATGGCGGGAACCAGTAAGGTTAGCCGCTCATCTAATTATTCGCCTCGTGGAGGCGTTTCCGACTCAGGTTCTTATCTTCCACGTAGATTTAGCAGGGCCTCACTATGGGCAAACAGGCCCATGTATAGGAAGCCCAGGATCTATCGGACCTATAGGTCCCCTGACGTTCCTAAAGGTTGTGAAGGGCCTTGTAAGGTCCAGTCATTTGAACAGCGTCACGATATTGCTCATACAGGGAAGGTCATATGTTTATCAGATGTTACACGTGGTAATGGTATTACCCACCGTGTTGGTAAACGTTTCTGTGTTAAGTCTGTATATATTTTAGGTAAAATATGGATGGATGAGAATATTAAAGTTAAGAATCACACTAACAGTGTTATGTTCTGGTTAGTTAGGGATAGAAGGCCGTTTGGTTCACCGATGGATTTTGGACAGGTGTTCAACATGTATGATAATGAGCCAAGTACAGCGACAGTTAAGAACGATCTCCGTGATCGTTATCAGGTCATGCATCGGTTTTCTGCAAAGGTTACTGGTGGACAGTATGCTAGCAATGAGCAGGCTCTCGTGAGGCGTTTTTGGAAGGTCAATAACCATGTGGTTTATAACCATCAAGAAGCCGCTAAGTACGAGAATCACACGGAGAATGCGTTGTTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCAACTTTGAAGATACGGATCTACTTTTATGATTCGATATCTAATTAATAAAGATTGAATTTTATTATATGCTGTTGTTCATTACATTCAACATAAGGCAGTGAATCCACGGCATATTGAATCGCTCTAATTACATTATTAATGCCTATAACACCTATATTATATAAATAACGATTAATCCTTGAACAAAAAACTTGAAAAAAACTCCTGATCAGCCAACTGGATGTCGTCCAGATGCGGAAATTCAGGAAACACTTGTGAAGATGAAGACGCCTCCGCAAGTTGTGGTTGAACCGGATCTGGAACATTAGTATGTTCCTCCGGTTGTATTCCCAGGCGTCGATTATCCTGAAATAGAGGGGATTTGGAACCTCCCAGATAAAAGCGGAATTCTCTGCCTGAGACGCAGTGATGGGTTCCGCGGTGCGTAAATCCATCTTCACGGCAGCTTATGCTGACGTAGATGGTGCAGCCACACTCCAGATCAATACGTCTCCGACGAACCACTTTCTTGGCGTGACGATGTCGAGGCTTGATCGACGGTGCTGTAGAGAGGCTCCGTGATGGTGATGTAGATGGAGTTCTTCTTGGCCCAGTCATTGATTGCTTTGTTCTTTTCCTCTTCGAAGAACTCCTTATATGAAGATTGTGGACCAGGATTGCAGAGGAAGATTGTTGGGATTCCTCCTTTAATTTGAATAGGTTTCCCGTACTTGCAGTTCGATTGCCAGTCTCTCTGGGCCCCCATAAATTCCTTCATATGTTTGAGGAAGTGCGGATCTACGTCATCAATGACGTTATACCACGCATTATTAGAGTATACTTTTGGGCTAAGATCCAAATGCCCACACAGATAATTGTGAGGGCCTAAACTCCTGGCCCATAATGTTTTACCTGTTCTGGATGGGCCTTCGATTATTATGGATATAGGTCTGAAAGGCCGCGCAGCGGAATCGGCCACATTTGTTGTGACCCAATCTGTTAATGCTTCCGGTACATTGTTAAACGTCGTCGTTTGGAATGGCGGCATGTATACTGTTGTTGGTGGAGCGAATATTCGCTCTAGATTAGCGTTAAGATTATGATACTGTAAAACATAATCTTTTGGAAGTAATTCCTTAATTATTGTGAGAGCTTCGTCCTTACCTCCGCTGTTAAGTGCTTTAGCGTATGCATCGTTTGCGGATTGTTGTCCTCCTCTGGATGATCGGCCGTCGATCTTGAATTCACCCCATTCGCAGAATACTCCATCTTTTTCGATGTACGATTTGGCGTCGGAGGAGGAGCGTGCAGTCTGTATATTACAATGGTATTGTTGTGATGAATTTGGATTGGATAGATCGAACAATCTGCAGTTCGTGCATCTGTACTTCTTCTGGAATTGAACCAGGGCATGCAGATGCGGAGAGCCATCTTGATGTTTTTCTTCGCAAACCCTAATATAGACGATATTAGTTGGAAGGGAAAGTGTTTTAATTTGCTCTAAGGCTGACTCTTTGTTGATTGGGCATCTAGGCCAAGTTAAAAAAAAAGAAGATGCTGTTTTAACAAAACGACTTCCCATCTTGCGTTTTATATCGGTACACACCAAAGTCTCTGTGTACCGATATATCGGTACACAATATATACTAGTGGCCTCTATAATGCTACTAGGCGTGCAGCGCCTTGATATTCCGGACGCGAGGGGTATTCATGGTCATTTGCCACTCAGTTTAGCGCTATTTTTGGGTTCCGATCCGCTGCTGCACGCCTATAATATT
ACCGTGCAGCAGCCCCCGCTTTTGCCGTACGCTATAGCCGTTGCGATTATGCAACGTGGCGGTATTAGATACCGCCCATTGTAGGTTCTGCAATACACGCGCGGGAAACATGAAAAAAGTAAGGAAAAGACGCGCGTCAATGAAATTAAAATTGGACTATACCTGACATAGTTGGACACGTGGTCCATTCCTTTTAGTTGCTGTACGTCTATTAACGACTGTAATGGATAACCTTAACGACGAAGGACCCACCCATTCATTGGCTATGAACCTATTTGATATGACAATACCAAGTATAAAAGGACTATATCTCTTTACGTTTTCATTTGAATTTGAATTGCATTTCATTTCTATTAGTTTTGTTAACTATATTAATTGTTTTATTCTAATATAGTCTTTGACAGACTCCTCAACATCTAAGCATGTATACTATGCGGTATAGACATGGAGCTCCTCTCTCTGTACGACGACCAATTTATAGACGGACTTATGTCCGTCGGTTCCCGGTTAGACGTCCTCCCGTCCGACGTCAGCTCTCGTTTTCCAACAAACCCGCTGATGATAAGATGACCAAACAGCGTCTCCATGAGAATCAATATGGCACACAGTATGCCATATCCAACAACACTTCTATCCCGTCTTTTGTGACATACCCACGCCTAGGTGGACCTTCTCCCAATAGGTCCAGGGATTACATGAAGCTGAACCGTCTGCGGTACAAGGGTACCGTTACCATAAACAACACCCAGCCCGATGTTACAATGTCTGGAGAAACCAAGATAGAGGGTGTATTCACAATGGCGATTGTGATGGACCGGAAACCACATGTTGGCCCATCTGGTTCGCTTCCCAAGTTTGAGGAGCTTTTTGGTGCAAATACCTTCAGTCATGGCAGTCTTGACATTGCGGCCCATTTGAAGGACCGGTACTATGTGCGTCACGTTTGTAAACGGGTTATATCTATGGAGAAGGACTCTACCATTTTGAACTTGACTGGGTCCATGAGTTTATCTTCATCACGATTCACGTGTTGGGCCTCGTTCAAGGATTTGAATGTTGATAGTTGTAATGGGGCGTACAGTAACGTCGCCAAGAACGCCATACTTGTATATTATTGTTGGATGTCGGACGAACCGTCACGTGCATCCACGTTTGTATCGTTTGATTTGGATTACTTGGGTTAATAAAATTGAATTTTGTAGTTATAATAGTAGAGTAACAATTTAATATAATTAATAGTTTTATTTATAATGGTTTCGCCTGATGGGGCGTACAATTACGATTAATACAATGTTCGACCGTGCTACTGACTAGTTCCTGCAACTGGGCTCTAGTAAGTGTTATGTTGGACTCAGCCCGGGAAGCACCGATCATTGAGGCGGAGTCCCCTGGATCCAGCATACTTGTGCTGAGTCTGTTGAGTTCACGATACGGGTGGTTCCTGTTGTGCACCTCGGATTCTGTCTCCATGGTATCAGGCCCAATACAGCTACGCGTGGCCCATGATTCACCAGGCCTTAATTCTATTGCCGAGTGCAGGCCCAGTCGACTGGAGGACTCGCACTTCACCAGCTTCCTCTCGACCTTGCCGTAGTCCACATGGGAAAAGTCGATATCTTTGCCGGTGAACTGCTTGGAGAGTATCTTTACCGTCGGGGAACGGAATATGACATCAACAGAGTGCTTTGCTGTCGACATCTTCAGTTTGCCCTTGAATTTTGCGAAATGGGTCCCCTGATGTACATTGGTATCAGATACCCTGTAGTACAGCTTCCATGGGATGGGATCTTTCAGAGAGAAGAAAGAGGCGGAGAAATAGTGCAGATCTATGTTGCACCTTATGGGAAAGGTGTACGACGCCTGTAAGGACTCGTTATCCGTCATGCGCTTGTCGTGAATCTCCACTATGACGGACCCTGTGGCGTTAATCGGTACCTGTTGTCGGTACTCTATGACGCAGTGGTCGATCTTCATGCATCGACGCCTGACAGTCGCACCCCACTGTTCCGCCGTAGACGGAAACTGTAGAACAATCTCTGTTAGGTCATGAGTCAGACGATATTCGTCCCTATGTGATTCTATGTAATTAAAAGAACTAGGAGCTTGAGCTAATTGTGATTCCATTTAAGAAAATTAGGTCGCGCAGCGAGACAGGACTAACTAGATGGGTTATTACCAAACTGGGTGATAAAATAAGAAAGAGATTTGCGATAAACTATTTACAGAGATAACAGTGTATCCAGTAACTGGGGAAAGAGATGAAGGTATGATGTCTTCCTGGAACGATGGAACTGGTTATATAGACCAATATAGTACGGATAATATGTTTAATCTGAAAAGATGTATTGTTCATAATAATTAGAAACATGAAGGGTATTTATCACTAATAACACATATTATGTATCTTAAATATGTTTAACTGTTATAACGCTTCTTTTTAATAAATGTTTTAAGTGAAACGACACAACAGCTTGCGTTTTATATCGGTACACACCAAAGTCTCTGTGTACCGATATATCGGTACACAATATATACTAGTGGCCTCTATAATGCTACTAAGGCGTGCAGTTCCACCTAGGCGTGGGAAGAAGGGTATTTAGTGTCTTTTCACTATTTGTTTGTAAAGGGTTTGATATCCGCATAAGGGTATTTGTGTAACTTACCACACCGCTGCTGCACGCCTTTAATATT
Gene Information
|
NCBI Accession
|
YP_115508.1
|
|
Location
|
236-1012 |
|
Gene Name
|
AV1 |
|
Protein Name
|
CP protein |
|
Coding Region
|
ATGCCTAAGCGCGATGCCCCATGGCGCTTGATGGCGGGAACCAGTAAGGTTAGCCGCTCATCTAATTATTCGCCTCGTGGAGGCGTTTCCGACTCAGGTTCTTATCTTCCACGTAGATTTAGCAGGGCCTCACTATGGGCAAACAGGCCCATGTATAGGAAGCCCAGGATCTATCGGACCTATAGGTCCCCTGACGTTCCTAAAGGTTGTGAAGGGCCTTGTAAGGTCCAGTCATTTGAACAGCGTCACGATATTGCTCATACAGGGAAGGTCATATGTTTATCAGATGTTACACGTGGTAATGGTATTACCCACCGTGTTGGTAAACGTTTCTGTGTTAAGTCTGTATATATTTTAGGTAAAATATGGATGGATGAGAATATTAAAGTTAAGAATCACACTAACAGTGTTATGTTCTGGTTAGTTAGGGATAGAAGGCCGTTTGGTTCACCGATGGATTTTGGACAGGTGTTCAACATGTATGATAATGAGCCAAGTACAGCGACAGTTAAGAACGATCTCCGTGATCGTTATCAGGTCATGCATCGGTTTTCTGCAAAGGTTACTGGTGGACAGTATGCTAGCAATGAGCAGGCTCTCGTGAGGCGTTTTTGGAAGGTCAATAACCATGTGGTTTATAACCATCAAGAAGCCGCTAAGTACGAGAATCACACGGAGAATGCGTTGTTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCAACTTTGAAGATACGGATCTACTTTTATGATTCGATATCTAATTAA |
|
Protein Sequence
|
MPKRDAPWRLMAGTSKVSRSSNYSPRGGVSDSGSYLPRRFSRASLWANRPMYRKPRIYRTYRSPDVPKGCEGPCKVQSFEQRHDIAHTGKVICLSDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKVKNHTNSVMFWLVRDRRPFGSPMDFGQVFNMYDNEPSTATVKNDLRDRYQVMHRFSAKVTGGQYASNEQALVRRFWKVNNHVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSISN |
|
NCBI Accession
|
YP_115509.1
|
|
Location
|
1009-1401 |
|
Gene Name
|
AC3 |
|
Protein Name
|
REn protein |
|
Coding Region
|
ATGGATTTACGCACCGCGGAACCCATCACTGCGTCTCAGGCAGAGAATTCCGCTTTTATCTGGGAGGTTCCAAATCCCCTCTATTTCAGGATAATCGACGCCTGGGAATACAACCGGAGGAACATACTAATGTTCCAGATCCGGTTCAACCACAACTTGCGGAGGCGTCTTCATCTTCACAAGTGTTTCCTGAATTTCCGCATCTGGACGACATCCAGTTGGCTGATCAGGAGTTTTTTTCAAGTTTTTTGTTCAAGGATTAATCGTTATTTATATAATATAGGTGTTATAGGCATTAATAATGTAATTAGAGCGATTCAATATGCCGTGGATTCACTGCCTTATGTTGAATGTAATGAACAACAGCATATAATAAAATTCAATCTTTATTAA |
|
Protein Sequence
|
MDLRTAEPITASQAENSAFIWEVPNPLYFRIIDAWEYNRRNILMFQIRFNHNLRRRLHLHKCFLNFRIWTTSSWLIRSFFQVFCSRINRYLYNIGVIGINNVIRAIQYAVDSLPYVECNEQQHIIKFNLY |
|
NCBI Accession
|
YP_115510.1
|
|
Location
|
1139-1564 |
|
Gene Name
|
AC2 |
|
Protein Name
|
TrAP protein |
|
Coding Region
|
ATGACTGGGCCAAGAAGAACTCCATCTACATCACCATCACGGAGCCTCTCTACAGCACCGTCGATCAAGCCTCGACATCGTCACGCCAAGAAAGTGGTTCGTCGGAGACGTATTGATCTGGAGTGTGGCTGCACCATCTACGTCAGCATAAGCTGCCGTGAAGATGGATTTACGCACCGCGGAACCCATCACTGCGTCTCAGGCAGAGAATTCCGCTTTTATCTGGGAGGTTCCAAATCCCCTCTATTTCAGGATAATCGACGCCTGGGAATACAACCGGAGGAACATACTAATGTTCCAGATCCGGTTCAACCACAACTTGCGGAGGCGTCTTCATCTTCACAAGTGTTTCCTGAATTTCCGCATCTGGACGACATCCAGTTGGCTGATCAGGAGTTTTTTTCAAGTTTTTTGTTCAAGGATTAA |
|
Protein Sequence
|
MTGPRRTPSTSPSRSLSTAPSIKPRHRHAKKVVRRRRIDLECGCTIYVSISCREDGFTHRGTHHCVSGREFRFYLGGSKSPLFQDNRRLGIQPEEHTNVPDPVQPQLAEASSSSQVFPEFPHLDDIQLADQEFFSSFLFKD |
|
NCBI Accession
|
YP_115511.1
|
|
Location
|
1449-2528 |
|
Gene Name
|
AC1 |
|
Protein Name
|
rep protein |
|
Coding Region
|
ATGGGAAGTCGTTTTGTTAAAACAGCATCTTCTTTTTTTTTAACTTGGCCTAGATGCCCAATCAACAAAGAGTCAGCCTTAGAGCAAATTAAAACACTTTCCCTTCCAACTAATATCGTCTATATTAGGGTTTGCGAAGAAAAACATCAAGATGGCTCTCCGCATCTGCATGCCCTGGTTCAATTCCAGAAGAAGTACAGATGCACGAACTGCAGATTGTTCGATCTATCCAATCCAAATTCATCACAACAATACCATTGTAATATACAGACTGCACGCTCCTCCTCCGACGCCAAATCGTACATCGAAAAAGATGGAGTATTCTGCGAATGGGGTGAATTCAAGATCGACGGCCGATCATCCAGAGGAGGACAACAATCCGCAAACGATGCATACGCTAAAGCACTTAACAGCGGAGGTAAGGACGAAGCTCTCACAATAATTAAGGAATTACTTCCAAAAGATTATGTTTTACAGTATCATAATCTTAACGCTAATCTAGAGCGAATATTCGCTCCACCAACAACAGTATACATGCCGCCATTCCAAACGACGACGTTTAACAATGTACCGGAAGCATTAACAGATTGGGTCACAACAAATGTGGCCGATTCCGCTGCGCGGCCTTTCAGACCTATATCCATAATAATCGAAGGCCCATCCAGAACAGGTAAAACATTATGGGCCAGGAGTTTAGGCCCTCACAATTATCTGTGTGGGCATTTGGATCTTAGCCCAAAAGTATACTCTAATAATGCGTGGTATAACGTCATTGATGACGTAGATCCGCACTTCCTCAAACATATGAAGGAATTTATGGGGGCCCAGAGAGACTGGCAATCGAACTGCAAGTACGGGAAACCTATTCAAATTAAAGGAGGAATCCCAACAATCTTCCTCTGCAATCCTGGTCCACAATCTTCATATAAGGAGTTCTTCGAAGAGGAAAAGAACAAAGCAATCAATGACTGGGCCAAGAAGAACTCCATCTACATCACCATCACGGAGCCTCTCTACAGCACCGTCGATCAAGCCTCGACATCGTCACGCCAAGAAAGTGGTTCGTCGGAGACGTATTGA |
|
Protein Sequence
|
MGSRFVKTASSFFLTWPRCPINKESALEQIKTLSLPTNIVYIRVCEEKHQDGSPHLHALVQFQKKYRCTNCRLFDLSNPNSSQQYHCNIQTARSSSDAKSYIEKDGVFCEWGEFKIDGRSSRGGQQSANDAYAKALNSGGKDEALTIIKELLPKDYVLQYHNLNANLERIFAPPTTVYMPPFQTTTFNNVPEALTDWVTTNVADSAARPFRPISIIIEGPSRTGKTLWARSLGPHNYLCGHLDLSPKVYSNNAWYNVIDDVDPHFLKHMKEFMGAQRDWQSNCKYGKPIQIKGGIPTIFLCNPGPQSSYKEFFEEEKNKAINDWAKKNSIYITITEPLYSTVDQASTSSRQESGSSETY |
|
NCBI Accession
|
YP_115512.1
|
|
Location
|
2087-2377 |
|
Gene Name
|
AC4 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGCTCTCCGCATCTGCATGCCCTGGTTCAATTCCAGAAGAAGTACAGATGCACGAACTGCAGATTGTTCGATCTATCCAATCCAAATTCATCACAACAATACCATTGTAATATACAGACTGCACGCTCCTCCTCCGACGCCAAATCGTACATCGAAAAAGATGGAGTATTCTGCGAATGGGGTGAATTCAAGATCGACGGCCGATCATCCAGAGGAGGACAACAATCCGCAAACGATGCATACGCTAAAGCACTTAACAGCGGAGGTAAGGACGAAGCTCTCACAATAA |
|
Protein Sequence
|
MALRICMPWFNSRRSTDARTADCSIYPIQIHHNNTIVIYRLHAPPPTPNRTSKKMEYSANGVNSRSTADHPEEDNNPQTMHTLKHLTAEVRTKLSQ |
|
NCBI Accession
|
YP_115513.1
|
|
Location
|
423-1184 |
|
Gene Name
|
BV1 |
|
Protein Name
|
NSP protein |
|
Coding Region
|
ATGTATACTATGCGGTATAGACATGGAGCTCCTCTCTCTGTACGACGACCAATTTATAGACGGACTTATGTCCGTCGGTTCCCGGTTAGACGTCCTCCCGTCCGACGTCAGCTCTCGTTTTCCAACAAACCCGCTGATGATAAGATGACCAAACAGCGTCTCCATGAGAATCAATATGGCACACAGTATGCCATATCCAACAACACTTCTATCCCGTCTTTTGTGACATACCCACGCCTAGGTGGACCTTCTCCCAATAGGTCCAGGGATTACATGAAGCTGAACCGTCTGCGGTACAAGGGTACCGTTACCATAAACAACACCCAGCCCGATGTTACAATGTCTGGAGAAACCAAGATAGAGGGTGTATTCACAATGGCGATTGTGATGGACCGGAAACCACATGTTGGCCCATCTGGTTCGCTTCCCAAGTTTGAGGAGCTTTTTGGTGCAAATACCTTCAGTCATGGCAGTCTTGACATTGCGGCCCATTTGAAGGACCGGTACTATGTGCGTCACGTTTGTAAACGGGTTATATCTATGGAGAAGGACTCTACCATTTTGAACTTGACTGGGTCCATGAGTTTATCTTCATCACGATTCACGTGTTGGGCCTCGTTCAAGGATTTGAATGTTGATAGTTGTAATGGGGCGTACAGTAACGTCGCCAAGAACGCCATACTTGTATATTATTGTTGGATGTCGGACGAACCGTCACGTGCATCCACGTTTGTATCGTTTGATTTGGATTACTTGGGTTAA |
|
Protein Sequence
|
MYTMRYRHGAPLSVRRPIYRRTYVRRFPVRRPPVRRQLSFSNKPADDKMTKQRLHENQYGTQYAISNNTSIPSFVTYPRLGGPSPNRSRDYMKLNRLRYKGTVTINNTQPDVTMSGETKIEGVFTMAIVMDRKPHVGPSGSLPKFEELFGANTFSHGSLDIAAHLKDRYYVRHVCKRVISMEKDSTILNLTGSMSLSSSRFTCWASFKDLNVDSCNGAYSNVAKNAILVYYCWMSDEPSRASTFVSFDLDYLG |
|
NCBI Accession
|
YP_115514.1
|
|
Location
|
1246-2124 |
|
Gene Name
|
BC1 |
|
Protein Name
|
MP protein |
|
Coding Region
|
ATGGAATCACAATTAGCTCAAGCTCCTAGTTCTTTTAATTACATAGAATCACATAGGGACGAATATCGTCTGACTCATGACCTAACAGAGATTGTTCTACAGTTTCCGTCTACGGCGGAACAGTGGGGTGCGACTGTCAGGCGTCGATGCATGAAGATCGACCACTGCGTCATAGAGTACCGACAACAGGTACCGATTAACGCCACAGGGTCCGTCATAGTGGAGATTCACGACAAGCGCATGACGGATAACGAGTCCTTACAGGCGTCGTACACCTTTCCCATAAGGTGCAACATAGATCTGCACTATTTCTCCGCCTCTTTCTTCTCTCTGAAAGATCCCATCCCATGGAAGCTGTACTACAGGGTATCTGATACCAATGTACATCAGGGGACCCATTTCGCAAAATTCAAGGGCAAACTGAAGATGTCGACAGCAAAGCACTCTGTTGATGTCATATTCCGTTCCCCGACGGTAAAGATACTCTCCAAGCAGTTCACCGGCAAAGATATCGACTTTTCCCATGTGGACTACGGCAAGGTCGAGAGGAAGCTGGTGAAGTGCGAGTCCTCCAGTCGACTGGGCCTGCACTCGGCAATAGAATTAAGGCCTGGTGAATCATGGGCCACGCGTAGCTGTATTGGGCCTGATACCATGGAGACAGAATCCGAGGTGCACAACAGGAACCACCCGTATCGTGAACTCAACAGACTCAGCACAAGTATGCTGGATCCAGGGGACTCCGCCTCAATGATCGGTGCTTCCCGGGCTGAGTCCAACATAACACTTACTAGAGCCCAGTTGCAGGAACTAGTCAGTAGCACGGTCGAACATTGTATTAATCGTAATTGTACGCCCCATCAGGCGAAACCATTATAA |
|
Protein Sequence
|
MESQLAQAPSSFNYIESHRDEYRLTHDLTEIVLQFPSTAEQWGATVRRRCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASYTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVSDTNVHQGTHFAKFKGKLKMSTAKHSVDVIFRSPTVKILSKQFTGKDIDFSHVDYGKVERKLVKCESSSRLGLHSAIELRPGESWATRSCIGPDTMETESEVHNRNHPYRELNRLSTSMLDPGDSASMIGASRAESNITLTRAQLQELVSSTVEHCINRNCTPHQAKPL |