Abutilon mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000847225.1 |
| Release date |
2015/2/12 |
| Submitter |
Frischmuth,T., Zimmat,G., Jeske,H. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
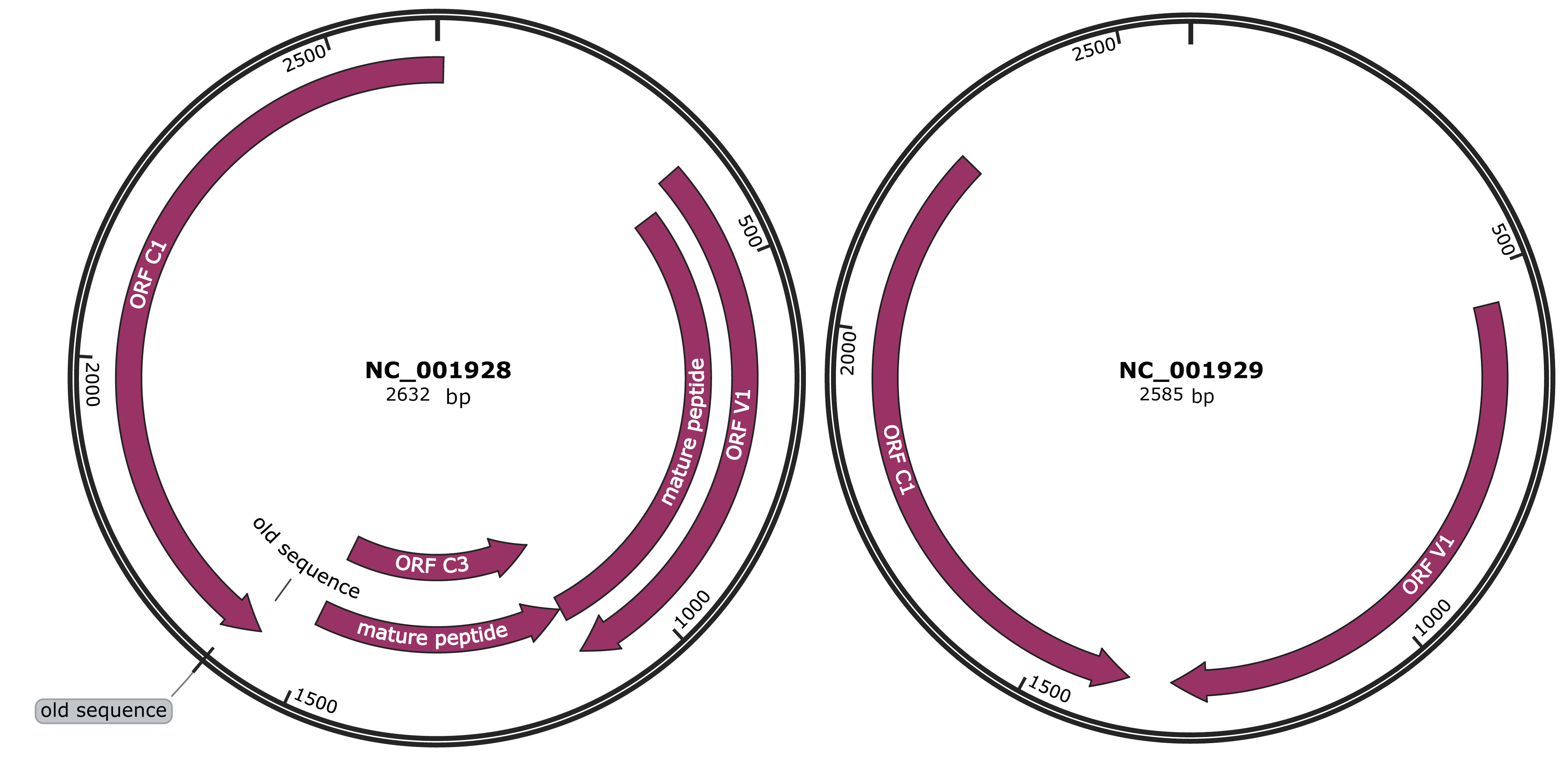
Genome
CGGTGGCATTTATGTAATAAGAAGGGGTACTCTGGATGAGTTACTCCACTTGAGGCTCCTCAAAACTTGCTCATGTAATTGGAGTATTGGAGGTCTTTATATACTAGAACTCTCATTAACGGATTTGCAACACGTGGCGGCCATCCGCTATAATATTACCGGATGGCCGCGCGACCCCCCTGGTGCCCGTACATCCCGCGCGCTTTTTCAACCTTTAATTTAGAATTAAAGGTAGTCCATGGCGCCTCGTCCAATAATAATGCGCCTGACGAGTCAATATAATTTGAACAACTTGTAGCGCTAAGTTGTTGGGTTGTCTATAAATGAAAGCCATTGGCCCACGAGCTTTAACCCAAAATGCCTAAGCGCGATCTCCCATGGCGATCGATGCCTGGAACATCAAAGACTAGTCGCAACGCTAATTATTCTCCTCGTGCTCGTATTGGGCCAAGAGTTGACAAGGCCTCTGAATGGGTGCACAGGCCCATGTACAGGAAGCCCAGGATCTACCGGACGCTGAGGACGGCCGATGTGCCCAGAGGCTGTGAAGGGCCTTGTAAGGTCCAGTCGTATGAACAGCGTCATGACATCTCACATGTTGGCAAGGTAATGTGCATCTCTGATGTGACACGTGGTAATGGCATTACCCACCGTGTGGGTAAGCGTTTCTGTGTCAAGTCTGTGTATATTTTAGGGAAGATTTGGATGGACGAGAACATCAAGCTCCAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCCGAGACCGTAGACCGTATGGCACGCCCATGGATTTCGGTCATGTGTTCAACATGTTCGACAACGAGCCCAGTACTGCCACTGTGAAGAACGATCTCCGCGATCGTTACCAGGTCCTTCACAAGTTCTATGGCAAGGTCACAGGTGGACAGTATGCCAGCAATGAACAGGCAATCGTCAAGCGTTTCTGGAAGGTCAACAATCATGTGGTCTACAATCATCAAGAGGCTGGCAAGTACGAGAATCACACGGAGAACGCTCTACTATTGTATATGGCATGTACTCATGCTTCTAACCCCGTTTATGCAACTTTGAAGATCCGAATCTATTTCTATGATTCGCTCATGAATTAATAAAATTTGAATTTTATTGAATGATTTTCCAGTACATAATTTACATACGTTCTGTTTGTCGCAAACTGAACAGCTCTAATTACATTGTTAATGGAAATCACGCCTAACTGATCTAAGTACATGTTGACTAAACGCCTAAATCTATTTAAATAAATTGACCCAGAAGCTGTCATCGAAGTCGTCCAAACTTGGAAGTTCAGGTAAGCTTTGTGGAGATGCAACGCTCTCCTCAGGTTGTGGTTGAACCGTATTTGTACATGGTATATCCTCGTTCTGGTGTATAGCGGGTCCTCTACTTTGTATATCCTGAAATACAGGGGATTTGCTATCTCCCAGATATACACGCCATTCTCCGCCTGATGTACAGTGATGAATTCCCCTGTGCGTGAATCCATGTCCTGTACAGTCTATGTGGAAGTAGATGGAGCACCCGCACTGCAGATCAATCCTCCGCCGCCTAATGGCCCTCCTCTTGGCCTGCCTGTGTGCCTTCTTGATAGAGGGGGGCTGTGAGGGTGATGAAGATCGCATTCTTGAGAGTCCAGTTGCGTAGACCTGTATTTTCCTCTTTGTCCAGGTACTCTTTATAGCTGGAACCCTCACCAGGATTGCAAAGCACGATTGCTGGGATTCCTCCTTTAATTTGAACCGGCTTGCCGTACTTGCAATTTGACTGCCAGTCTTTTTGGGCCCCCAGCAATTCTTTCCAGTGCTTTAGCTTTAGATAGTGCGGTGCGACGTCATCAATGACGTTATACTCCACTTCGTTCGAATAGACGCGACCATTGAAGTCCAGGTGTCCACTGAGATAGTTATGTGGGCCTAACGCACGTGCCCACATCGTCTTCCCTGTCCTTGAATCACCTTCGACTATGAGACTCAATGGTCTGTCTGGCCGCGCAGCGGAACCACTCCCAAAATAATCATCCGCCCACTCCTGCATCTCCTCGGGAACGGCCGTGAAAGAGGAGAGGGGAAACCGCGGAACCCATGGTTCCGGAGCCTTTGCGAATATTCTTTCGAGATTGGAGCGGATGTTATGATTCTGAAGGACATAATCTTTTGGCTGTTCTTCCTTCAAAATGTTTAAGGCAGATTGAACATCTCCTGCATTCAACGCCTTGGCATATGAATCATTAGCAGTCTGTTGGCCTCCCCTGGCAGATCTGCCGTCGATCTGGAATTCTCCCCATTCAGCTGTATCTCCGTCCTTGTCGATGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGTATGTTTGGATGGAAATGTGCTGACCTGGTTGGGGAGACCAGATCGAAGAATCTGTTATTCGTGCATTGGTATTTGCCTTCGAACTGTATGAGCACATGGAGATGAGGCTCCCCATTCTCGTGAAGCTCTCTACAGATCTTGATGAACTTCTTGTTCACTGGGGTTTCTAGGTTTTGTAATTGGGAAAGTGCCTCATCTTTAGTAAGAGAGCACTGGGGATATGTGAGGAAATAATTTTTGGCCTGTACTCTAAATTTCTTTGG
CGGTGGCGTTTTTGTAATAAGAAGGGGTACTCTGGATGAGTTACTCCACTTGAGGCTCCTCAAAACTTGCTCATGTAATTGGAGTATTGGAGGTCTTTATATACTAGAACTCTCATTAACGGATTTGCAACACGTGGCGGCCATCCGCTATAATATTACCGGATGGCCGCGCGACCCCCCCCCCTGGTGCTGCTCTCGCACTCGCTCTACCCTGGTGCTCTTCTCACACGCGCTCTCCCATTGGTGCGGGTCCTTCACGCTCCTCTTTTGGCTGGACCTTTAATTTGAATTAAAGGTGTTTACTTTCTCGTGCGACGTGCTTTATAGTTTGAATTGTTGTCGCGCGAATACTGGCTATGGACCATTGTACCTGGTCAAGGACGTGTCATAATTGGACCTTGCTTCTGAGTCTATTTGCGATTAATGGTGGACCATCTAACTATATATTTGGCCGGATAGGTACTTTTGTGGTAAAAGACTCAGCAATCCCCCACGTTTTTTCGCACCTGGCTAATCGTGTTGTTTTTTCTTATATTATCATCTGATAATGTACCCGTCTAGGAATAAACGTGGATCCTACTTTAATCAACGTCGACAGTATTCACGCAATCATGTGTGGAAACGGCCAACTGCTGCGAAGAGACATGACTGGAAGCGTCGACCTTCAAATACGAGCAAGCCCAACGACGAGCCCAAGATGTCAGCCCAACGCATACATGAGAATCAGTATGGGCCTGAGTTTGTAATGGCCCAGAACTCAGCGATCTCGTCGTTCATCAGTTATCCTGACTTGGGTAGGTCCGAGCCCAACCGAAGCAGGTCCTATATTAGGTTGAAGCAACTACGCTTCAAAGGGACGGTGAAGATTGAACAGGTACCATTGGCGATGAACATGGACGGATCTACCCCCAAAGTGGAAGGAGTGTTCTCCCTTGTCATTGTTGTGGATCGTAAACCACACCTTGGCCCGTCTGGTTGTCTGCATACATTTGACGAGCTGTTTGGTGCTAGGATACACAGTCATGGTAACCTCAGCGTAACCCCCGCGTTGAAAGATCGATATTACATTCGCCACGTTTGCAAACGTGTGCTATCTGTGGAGAAGGATACGCTGATGGTAGACGTGGAAGGATCCATTCCTCTCTCTAACCGGCGTATTAATTGTTGGGCCACGTTTAAGGACGTGGATCGTGAGTCATGTAAGGGTGTTTATGATAACATAAGTAAGAACGCCCTGTTAGTTTATTACTGCTGGATGTCGGATACGCCTGCGAAGGCATCCACTTTTGTATCGTTTGACCTTGACTATATTGGTTAAGTGAATAAATGAATTATTTAAAGTTGATCATCTTATTTGTACAAGCAAAACATACAATTATTTCAATGATTTGGCTTGAGAAGCCTGACAGTTACTATTGACACATTCTTGGACCGCTGTCCTGACTAATTCGTTCAACTGGCCCATTGACATTGTGATGTTGGGCTCCGCTCTCTGGTCACCCACAATCGAAGCAGATTCTCCGGGGTCTAGAAGGCTGGTCCCCAGCCTGTTTAGGTGTCTGTATGGATGGAGCTCGTTCTCCATTTCTGAGTCCGTATCTGGCTGGGCTGTCCCTATGGTGCTCCTGGAAGCCCATGATTCACCAGGCCTAATCTCAATTGGGCCTCGTAGTCCAATCCTGGACATGGACGCGCATCTGATGGGCTTCCTCTCCCATTTCCCATAATCCACATGGGAAAAGTCCACGTCTTTTTCGGAGAACTGTTTGGACAGTATCCTTACTGTTGGTGCCCGGAACGGAATGTCGACTGAGTGTTTCGCCGTGGACAATTTCAGTTTCCCTTTGAACTTGGCGAAGTGGGTCCGCTGATGCACGTTTGTATCGCAGACTTTGTAGTACAATTTCCATGGAATGGGGTCTTTCAGCGAGAAGAACGAAGCCGAGAAATAGTGGAGATCTATGTTGCATCTGATCGGAAAAGTCCACGACGCCTGTAAAGACTCGTTGTCCGTCATTCTCTTGTCGTGGATCTCCACAATCACCGACCCGGTGGCGTTGATCGGTACTTGTTGTCTGTATTCTATGACGCAGTGATCGATCTTCATGCAGCTACGACTGAGTCTAGCTGTCAACTGAGCCGCCGTGGACGGAAATTGCAGTATTATCTCAGTTAGGTCATGGGAAAGTTGATATTCGTCACGGTGTGACTCGATGTAGTTGAAGGCGTTCGGAGGATTTACTAACTGAGAATCCATTTGGAGAAGATCGGCCGCAGCGGAACTGGAACCGACTACTGAAGTTGAACAGTTAAGAAGATGAACAATTACTGTTGATCAAGAAGAATGTAAATAGAAAGGGCTCTTTTCTTCTTTTGAGAAAGTCAGATATCTCTGACGTATAACTGAGGAGATGGAGGAGGAGTAACTGGTGAAGAGTCGAGTTGTTTGAGAAAGAAAAGAGAGTTGAGGAAGAATTTGAGAGAGAACTGGAAATGAAGGAGTTGGTATATGAACCCAGATCTTCTGGTTGATGGTATTAAATTGGAAAGTGTTCTTCTACTTCTGAGAGAATCTATTTGTTAAA
Gene Information
|
NCBI Accession
|
NP_047218.2
|
|
Location
|
1571-2632,1-9 |
|
Gene Name
|
ORF C1 |
|
Protein Name
|
40.2 kDa |
|
Coding Region
|
ATGCCACCGCCAAAGAAATTTAGAGTACAGGCCAAAAATTATTTCCTCACATATCCCCAGTGCTCTCTTACTAAAGATGAGGCACTTTCCCAATTACAAAACCTAGAAACCCCAGTGAACAAGAAGTTCATCAAGATCTGTAGAGAGCTTCACGAGAATGGGGAGCCTCATCTCCATGTGCTCATACAGTTCGAAGGCAAATACCAATGCACGAATAACAGATTCTTCGATCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCAAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACAGCTGAATGGGGAGAATTCCAGATCGACGGCAGATCTGCCAGGGGAGGCCAACAGACTGCTAATGATTCATATGCCAAGGCGTTGAATGCAGGAGATGTTCAATCTGCCTTAAACATTTTGAAGGAAGAACAGCCAAAAGATTATGTCCTTCAGAATCATAACATCCGCTCCAATCTCGAAAGAATATTCGCAAAGGCTCCGGAACCATGGGTTCCGCGGTTTCCCCTCTCCTCTTTCACGGCCGTTCCCGAGGAGATGCAGGAGTGGGCGGATGATTATTTTGGGAGTGGTTCCGCTGCGCGGCCAGACAGACCATTGAGTCTCATAGTCGAAGGTGATTCAAGGACAGGGAAGACGATGTGGGCACGTGCGTTAGGCCCACATAACTATCTCAGTGGACACCTGGACTTCAATGGTCGCGTCTATTCGAACGAAGTGGAGTATAACGTCATTGATGACGTCGCACCGCACTATCTAAAGCTAAAGCACTGGAAAGAATTGCTGGGGGCCCAAAAAGACTGGCAGTCAAATTGCAAGTACGGCAAGCCGGTTCAAATTAAAGGAGGAATCCCAGCAATCGTGCTTTGCAATCCTGGTGAGGGTTCCAGCTATAAAGAGTACCTGGACAAAGAGGAAAATACAGGTCTACGCAACTGGACTCTCAAGAATGCGATCTTCATCACCCTCACAGCCCCCCTCTATCAAGAAGGCACACAGGCAGGCCAAGAGGAGGGCCATTAG |
|
Protein Sequence
|
MPPPKKFRVQAKNYFLTYPQCSLTKDEALSQLQNLETPVNKKFIKICRELHENGEPHLHVLIQFEGKYQCTNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTAEWGEFQIDGRSARGGQQTANDSYAKALNAGDVQSALNILKEEQPKDYVLQNHNIRSNLERIFAKAPEPWVPRFPLSSFTAVPEEMQEWADDYFGSGSAARPDRPLSLIVEGDSRTGKTMWARALGPHNYLSGHLDFNGRVYSNEVEYNVIDDVAPHYLKLKHWKELLGAQKDWQSNCKYGKPVQIKGGIPAIVLCNPGEGSSYKEYLDKEENTGLRNWTLKNAIFITLTAPLYQEGTQAGQEEGH |
|
NCBI Accession
|
NP_047215.2
|
|
Location
|
358-1113 |
|
Gene Name
|
ORF V1 |
|
Protein Name
|
28 kDa |
|
Coding Region
|
ATGCCTAAGCGCGATCTCCCATGGCGATCGATGCCTGGAACATCAAAGACTAGTCGCAACGCTAATTATTCTCCTCGTGCTCGTATTGGGCCAAGAGTTGACAAGGCCTCTGAATGGGTGCACAGGCCCATGTACAGGAAGCCCAGGATCTACCGGACGCTGAGGACGGCCGATGTGCCCAGAGGCTGTGAAGGGCCTTGTAAGGTCCAGTCGTATGAACAGCGTCATGACATCTCACATGTTGGCAAGGTAATGTGCATCTCTGATGTGACACGTGGTAATGGCATTACCCACCGTGTGGGTAAGCGTTTCTGTGTCAAGTCTGTGTATATTTTAGGGAAGATTTGGATGGACGAGAACATCAAGCTCCAGAACCACACGAACAGTGTCATGTTCTGGTTGGTCCGAGACCGTAGACCGTATGGCACGCCCATGGATTTCGGTCATGTGTTCAACATGTTCGACAACGAGCCCAGTACTGCCACTGTGAAGAACGATCTCCGCGATCGTTACCAGGTCCTTCACAAGTTCTATGGCAAGGTCACAGGTGGACAGTATGCCAGCAATGAACAGGCAATCGTCAAGCGTTTCTGGAAGGTCAACAATCATGTGGTCTACAATCATCAAGAGGCTGGCAAGTACGAGAATCACACGGAGAACGCTCTACTATTGTATATGGCATGTACTCATGCTTCTAACCCCGTTTATGCAACTTTGAAGATCCGAATCTATTTCTATGATTCGCTCATGAATTAA |
|
Protein Sequence
|
MPKRDLPWRSMPGTSKTSRNANYSPRARIGPRVDKASEWVHRPMYRKPRIYRTLRTADVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLQNHTNSVMFWLVRDRRPYGTPMDFGHVFNMFDNEPSTATVKNDLRDRYQVLHKFYGKVTGGQYASNEQAIVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSLMN |
|
NCBI Accession
|
NP_047216.1
|
|
Location
|
1110-1508 |
|
Gene Name
|
ORF C3 |
|
Protein Name
|
15.9 kDa |
|
Coding Region
|
ATGGATTCACGCACAGGGGAATTCATCACTGTACATCAGGCGGAGAATGGCGTGTATATCTGGGAGATAGCAAATCCCCTGTATTTCAGGATATACAAAGTAGAGGACCCGCTATACACCAGAACGAGGATATACCATGTACAAATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCTTACCTGAACTTCCAAGTTTGGACGACTTCGATGACAGCTTCTGGGTCAATTTATTTAAATAGATTTAGGCGTTTAGTCAACATGTACTTAGATCAGTTAGGCGTGATTTCCATTAACAATGTAATTAGAGCTGTTCAGTTTGCGACAAACAGAACGTATGTAAATTATGTACTGGAAAATCATTCAATAAAATTCAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGEFITVHQAENGVYIWEIANPLYFRIYKVEDPLYTRTRIYHVQIRFNHNLRRALHLHKAYLNFQVWTTSMTASGSIYLNRFRRLVNMYLDQLGVISINNVIRAVQFATNRTYVNYVLENHSIKFKFY |
|
NCBI Accession
|
NP_047217.2
|
|
Location
|
1255-1644 |
|
Gene Name
|
ORF C2 |
|
Protein Name
|
14.4 kDa |
|
Coding Region
|
ATGCGATCTTCATCACCCTCACAGCCCCCCTCTATCAAGAAGGCACACAGGCAGGCCAAGAGGAGGGCCATTAGGCGGCGGAGGATTGATCTGCAGTGCGGGTGCTCCATCTACTTCCACATAGACTGTACAGGACATGGATTCACGCACAGGGGAATTCATCACTGTACATCAGGCGGAGAATGGCGTGTATATCTGGGAGATAGCAAATCCCCTGTATTTCAGGATATACAAAGTAGAGGACCCGCTATACACCAGAACGAGGATATACCATGTACAAATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCTTACCTGAACTTCCAAGTTTGGACGACTTCGATGACAGCTTCTGGGTCAATTTATTTAAATAG |
|
Protein Sequence
|
MRSSSPSQPPSIKKAHRQAKRRAIRRRRIDLQCGCSIYFHIDCTGHGFTHRGIHHCTSGGEWRVYLGDSKSPVFQDIQSRGPAIHQNEDIPCTNTVQPQPEESVASPQSLPELPSLDDFDDSFWVNLFK |
|
NCBI Accession
|
NP_047219.2
|
|
Location
|
548-1318 |
|
Gene Name
|
ORF V1 |
|
Protein Name
|
29.8 kDa |
|
Coding Region
|
ATGTACCCGTCTAGGAATAAACGTGGATCCTACTTTAATCAACGTCGACAGTATTCACGCAATCATGTGTGGAAACGGCCAACTGCTGCGAAGAGACATGACTGGAAGCGTCGACCTTCAAATACGAGCAAGCCCAACGACGAGCCCAAGATGTCAGCCCAACGCATACATGAGAATCAGTATGGGCCTGAGTTTGTAATGGCCCAGAACTCAGCGATCTCGTCGTTCATCAGTTATCCTGACTTGGGTAGGTCCGAGCCCAACCGAAGCAGGTCCTATATTAGGTTGAAGCAACTACGCTTCAAAGGGACGGTGAAGATTGAACAGGTACCATTGGCGATGAACATGGACGGATCTACCCCCAAAGTGGAAGGAGTGTTCTCCCTTGTCATTGTTGTGGATCGTAAACCACACCTTGGCCCGTCTGGTTGTCTGCATACATTTGACGAGCTGTTTGGTGCTAGGATACACAGTCATGGTAACCTCAGCGTAACCCCCGCGTTGAAAGATCGATATTACATTCGCCACGTTTGCAAACGTGTGCTATCTGTGGAGAAGGATACGCTGATGGTAGACGTGGAAGGATCCATTCCTCTCTCTAACCGGCGTATTAATTGTTGGGCCACGTTTAAGGACGTGGATCGTGAGTCATGTAAGGGTGTTTATGATAACATAAGTAAGAACGCCCTGTTAGTTTATTACTGCTGGATGTCGGATACGCCTGCGAAGGCATCCACTTTTGTATCGTTTGACCTTGACTATATTGGTTAA |
|
Protein Sequence
|
MYPSRNKRGSYFNQRRQYSRNHVWKRPTAAKRHDWKRRPSNTSKPNDEPKMSAQRIHENQYGPEFVMAQNSAISSFISYPDLGRSEPNRSRSYIRLKQLRFKGTVKIEQVPLAMNMDGSTPKVEGVFSLVIVVDRKPHLGPSGCLHTFDELFGARIHSHGNLSVTPALKDRYYIRHVCKRVLSVEKDTLMVDVEGSIPLSNRRINCWATFKDVDRESCKGVYDNISKNALLVYYCWMSDTPAKASTFVSFDLDYIG |
|
NCBI Accession
|
NP_047220.2
|
|
Location
|
1376-2257 |
|
Gene Name
|
ORF C1 |
|
Protein Name
|
32.9 kDa |
|
Coding Region
|
ATGGATTCTCAGTTAGTAAATCCTCCGAACGCCTTCAACTACATCGAGTCACACCGTGACGAATATCAACTTTCCCATGACCTAACTGAGATAATACTGCAATTTCCGTCCACGGCGGCTCAGTTGACAGCTAGACTCAGTCGTAGCTGCATGAAGATCGATCACTGCGTCATAGAATACAGACAACAAGTACCGATCAACGCCACCGGGTCGGTGATTGTGGAGATCCACGACAAGAGAATGACGGACAACGAGTCTTTACAGGCGTCGTGGACTTTTCCGATCAGATGCAACATAGATCTCCACTATTTCTCGGCTTCGTTCTTCTCGCTGAAAGACCCCATTCCATGGAAATTGTACTACAAAGTCTGCGATACAAACGTGCATCAGCGGACCCACTTCGCCAAGTTCAAAGGGAAACTGAAATTGTCCACGGCGAAACACTCAGTCGACATTCCGTTCCGGGCACCAACAGTAAGGATACTGTCCAAACAGTTCTCCGAAAAAGACGTGGACTTTTCCCATGTGGATTATGGGAAATGGGAGAGGAAGCCCATCAGATGCGCGTCCATGTCCAGGATTGGACTACGAGGCCCAATTGAGATTAGGCCTGGTGAATCATGGGCTTCCAGGAGCACCATAGGGACAGCCCAGCCAGATACGGACTCAGAAATGGAGAACGAGCTCCATCCATACAGACACCTAAACAGGCTGGGGACCAGCCTTCTAGACCCCGGAGAATCTGCTTCGATTGTGGGTGACCAGAGAGCGGAGCCCAACATCACAATGTCAATGGGCCAGTTGAACGAATTAGTCAGGACAGCGGTCCAAGAATGTGTCAATAGTAACTGTCAGGCTTCTCAAGCCAAATCATTGAAATAA |
|
Protein Sequence
|
MDSQLVNPPNAFNYIESHRDEYQLSHDLTEIILQFPSTAAQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYKVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVRILSKQFSEKDVDFSHVDYGKWERKPIRCASMSRIGLRGPIEIRPGESWASRSTIGTAQPDTDSEMENELHPYRHLNRLGTSLLDPGESASIVGDQRAEPNITMSMGQLNELVRTAVQECVNSNCQASQAKSLK |