Common bean severe mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002366145.2 |
| Isolate |
Cuba |
| Release date |
2018/12/27 |
| Submitter |
Chang-Sidorchuk,L., Gonzalez-Alvarez,H., Navas-Castillo,J., Fiallo-Olive,E., Martinez-Zubiaur,Y. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
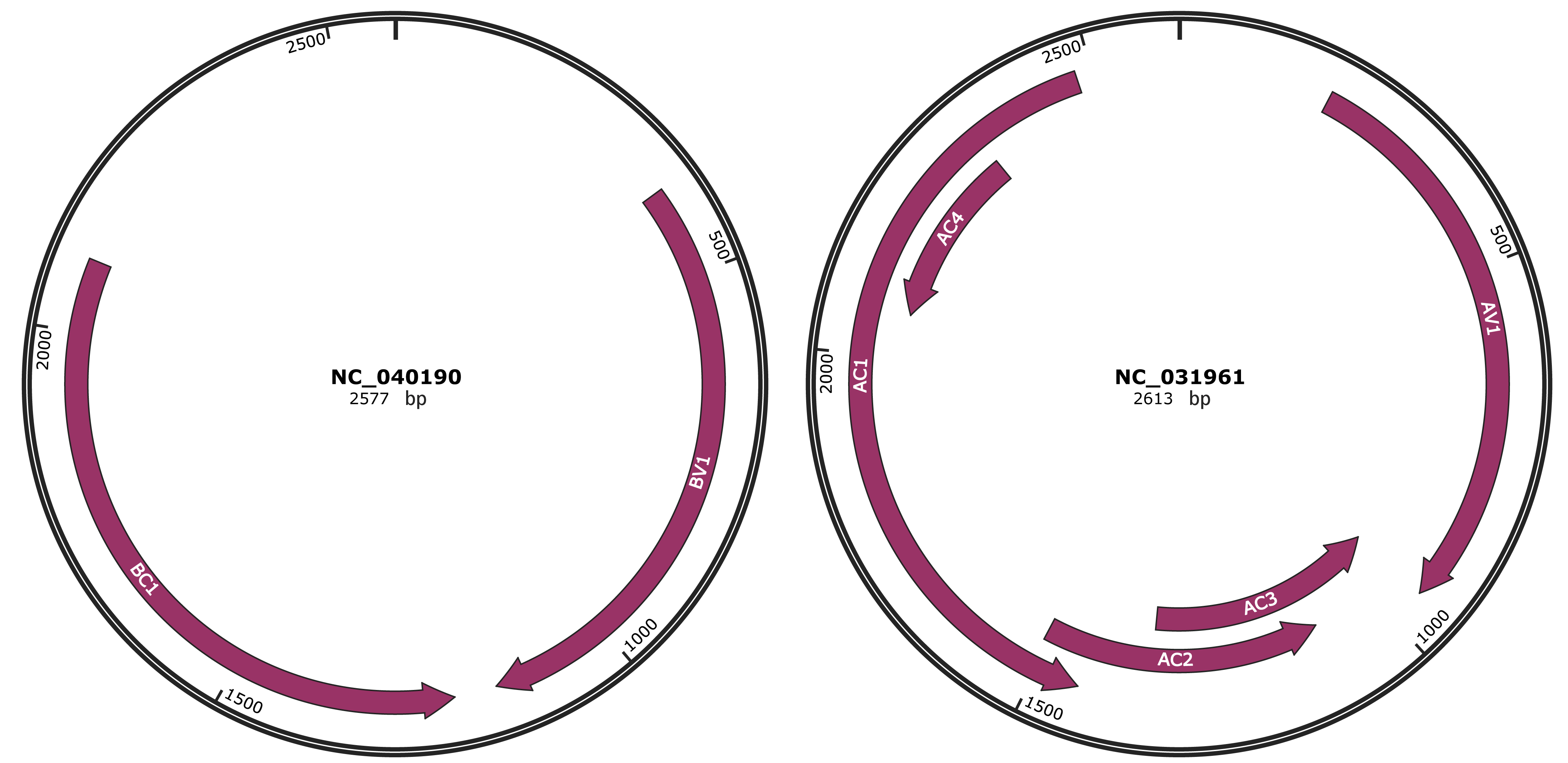
JBrowse
Genome
ACCGGATGGCCGACCGGGGTTCGTGGTGTATCCTCTCGCACTCCCACGTGGTGGCTCCCACTCTCTGACGCATTCCCACTTGGTGCGCAAATCGATAAATGTGTTATGACGTGGACATGGTATCTACCGTTCAAATTCTCTTATCGGTCTACTGAATTTGAATTTTGAATTGCTAGTGCGTCTTTTTATGTCTCTTTGCACGTTTTTTTTAGGAGTCTTGGTCAATTGTCTAACGGTAATGTTGTCTGACACATTGTCCTATGATAAAACGTGGCCCAATTAAATATTGTCTGTGGAGGTAAGTTAAATGATATGTTTAATGTTTTTGTATATATAATGAGTGACCAAGATTCGAATATTTAATTGTGCAGAAAGACGCTTTAACATGTATCCAAGAAAATATAGGCGCGGTTCATTTTATTCACATCGACGCTCAAATAATGTGTTTAAGCGATCCACCTATGTTAAAGGAAAGGATGTTAAAGATGGTAAGCGTCGATTAAATTATGGCAGCAATGTTCATGATGATTCCAAAATGTCATCTAAACGTATACATGAGAATCAGTATGGGCCTGATTTTGTGTTAGCCCATAATGCTGCCATCTCTACGTTCATTAGTTATCCTCATTTGGGTAAGACGGAACCCAATCGATCCAGGTCATATATTAAGTTGAAACGTTTACGTTTCAAAGGCACGGTGAAATTTGAACGTGTTCATGCTGATGTGAATATGGATGGTTTATGTCCCAAAATAGACGGAGTATTTTCTCTTGTTATTGTTATGGACCGCAAACCTCATCTCAGTGCGTCTGGGGTTTTGCATACCTTTGATGAACTATTCGGTGCAAGAATACATAGTCATGGTAACCTGTGCATAACCCCAGCTTTGAAAGACCGCTTCTATATTCGTCATGTATTAAAGCGAGTTGTATCTGTGGAGAAGGACACTGCAATGATTGACCTTGATGGATCGATTGGGTTATCTACTCGTCGTTTTAATTGTTGGGCTACATTTAAAGACCTTGATCATGATTCATCTAATGGGGTGTATGATAATATAAGTAAAAACGCTATCTTAGTTTATTATTGTTGGATGTCGGATGCCATGTCTAAAGCATCCACATTTGTATCGTTCGATCTTGATTATGTTGGCTGAACGGCTATATACTGAATATCCAATTTTGAACATGTTATACAATAATAAACATAATTTATTTCAATGTTTTTGGTTGAGAAGGAGTACAATTATTGTTAATACATTCTTGAACGGTAGTTCTGACTAACTCGCTTAATTGGGCAACTGACATTGTAATGTTTGATTGGGCCCTCTGCGCACCTATTATTGAAGCCGATTCACCCGGGTCGAAAACGCTTGTTCCTAAGCGATGGAGTTCTTTATATGGATGTGTTGCATTTTCCATGTCTGACTCTGAGTCTGTATGTGTCAATCCAATTGTGCTTCTGGAGGCCCATGACTCTCCGGGTTTCAATTCAATTGGGCCTGGTAGTCCAAATCTGGACATTGATGTGGACCTAATTGGTCGTCTCTCCCATTTACCATAGTCCACATGCGAAAAGTCGACATCTTTATGTGAGAACTGTTTTGACAGAATTTTCACCGTTGGTGCCCGGAATGGGATATCTACTGAATGTTTCGCTGTGGACAATTTCAGTTTTCCTTTGAACTTGGCAAAATGAGTCCTTTGATGAACATTGGTATCAGAAACCCTGTAGTATAGTTTCCATGGAATGGGGTCTTTTAAGGAAAAGAATGATGACGAAAAATAGTGGAGATCTATGTTGCATCTGATGGGAAATGTCCATGATGCTTGTAATGACTCGTTGTCTGTCATTCGTTTGTCATGAATCTCCACTATTACTGATCCCGTCGCGTTAATTGGTACTTGTTGTCTATATTCTATGACGCAATGGTCAATTTTCATACAACTCCGACTAAGTCTTGCCGTTAATTGCGACGCCGTGGAAGGAAATTGCAGAACTATCTCAGTTAGATCATGAGACAGTTGATATTCATCTCTATGAGATTCTATATAGTTGAACGCGTTAGGTGGATTTGCTAACTGAGAATCCATATATGAAAATGAGGCCGCGCAGCGGAAGTGGCCGCCAATTATATACCTGTTATGACAATTGAACAGTCCGATTAAGATGAAGACAATAACATGAACGGGTTATTTTCTATTCCGTGCAGTTTCATCTAATTTGAACATGAACAAACTGGGTAATTCGAACTGATAATGATTATGAACTACTTACTGGAAATGCACGGACGATGTTGTTGAAGTAAGACGATGAACTGGGTTGATGTTGAACAAGGGTTCTTATGAATATGTGTGTTATGAATATGTGTGTTAATGTTTATCATTTATATAGACGCGTTCATATATACTCTTCATCTAGTTGAGAGAGTTTCTAGTGGCATTTCTGTAATAAGAAGGGTGTACACCGATTGAGGCTCTCAACTCTTACTCATGTTATTGGTGTATTGGTGCCAATATATAGTATACCTTCTATTCTATAGATTTTTGACACGTGGAGGCCATCCGTTATAATATT
ACCGGATGGCCGACCGGGGTTCGTGGTGTATCCCTTTTCGTACTGGTCCACGTATGCTTTATTTTGAATTAAAGATATTTATTTTGCGTTGTCCAATCAAAATTACACTGGCGCGTCTAGATATGTGTGTCTAAACTTGCTGACCAAGTTCTTTTCTATAAATCGACCTCGTGTCCGTGGAGCCAGTGTCTTTAATTCAAAATGCCTAAGCGGGATGCCCCGTGGCGTTATACTGCGGGGACCTCAAAGGTTAGTCGCAATGCTAATTATTCACCTGGTGGAGGCCCAAAATCCAACAGGACCAATGCTTGGGTAAACAGGCCCATGTACAGGAAGCCCAGGATATATCGTATGTATAGATCCCCCGATGTTCCGAAAGGCTGTGAAGGGCCCTGTAAAATCCAGTCTTTTGAACAGAGACATGATGTTTCTCATGTTGGTAAGGTTATGTGTATATCCGACGTGACTCGTGGTAATGGTATTACCCATCGTGTTGGTAAACGATTCTGTGTTAAGTCTGTTTACATTTTAGGGAAAGTATGGATGGACGACAACATCAAGTTGAAGAACCACACCAACAGTGTCATGTTTTGGTTAGTCAGGGATAGACGACCATATGGCACCCCTATGGATTTTGGCCAAGTTTTTAATATGTTCGATAATGAGCCTAGTACAGCTACTGTTAAGAACGACCTCCGTGATCGTTTCCAAGTCATGCACAAATTTTATGCCAAGGTTACAGGTGGACAATATGCCAGCAACGAGCAATCTTTGGTCAAGCGTTTTTGGAAGGTGAATAATTATGTCGTCTACAACCATCAGGAAGCTGCTAAATATGAGAACCATACTGAGAATGCTCTATTATTGTATATGGCATGTACTCATGCTTCTAATCCTGTGTATGCTACTCTAAAAATTCGGATCTATTTTTATGATTCGATAATGAATTAATAAAATTTGAATTTTATTTCATGATATTCAAGTACATCGTTGACATAACTTCTGTTCGTTGCAAAAGAGACAGCTTTAATTACATTGTTAACTGAAATAACACCTAAATTGTCTAAGTAATACATTACAAGAAACTTGAATCTATTTAAATAAATCTGCCCAGAAGCTGTCGTCAATGTCGTCCAAACTTGGAAATTGAAGTAGGCTTTGTGGAGAGCCAACGCTTTCCTCAGGTTGTGGTTGGCTCGGACTTGTATGTGGAACACCGTCGTGTGTGTGAAGAGTGGTTTCTCTACTCTGGTTATCTTGAAATAGAGGGGATTTGGAACCTCCCAAATATAAACGCCACTCGTCGCCTGAGCTGCAGTGATGGGTTCCCCTGTGCGTGAATCCATTGTTTCTGCAGTTAATGTGAATGTAAATAGAACAGCCGCACTGCAGATCAATCCTTCTTCGTCTTATTTGTTTTTTCGCGTATCTATGGCGAGGTTTAATTTTCGGTGGTGAAGAGAGGTTCTTCAATGGAGACGAAGATGGCGTTCTTCTGTGCCCAGTCATTGAGTGATGTGTTTTTGTCCTCACTGAGAAACTCCTTATATGATGAATGGGGGCCTGGATTGCAAAGGAAGATAGTGGGAATTCCACCTTTAATTTGAATTGGCTTTCCGTATTTGCAGTTTGATTGCCAATCCCTCTGGGCCCCCATGAACTCTTTAAAGTGTTTTAAATAATGGGGATCAACATCATCAATGACGTTATACCATGCATTATTGGAGTAAATTTTTGAATTTAGATCGATATGACCACATAAGTAGTTGTGAGGCCCGAGACTACGGGCCCATAATGTTTTGCCTGTTCTTGATGATCCTTCAATAATAATTGATATAGGTCTAATTGGCCGCGCAGCGGAATCGGCAATATTCTGACTAACCCATTCTGACATTATATCTGGAACATTATTGAATGTGGACAACTGGAATGGAGGAACCCATGGTTCCGGGGGTTTTTGAAATATTTTGGATATGTTTGTGACTAAATTATGATATTGTAAGACAAAATGTTGTGGTTGATGCTCTTTGATTATCTGTAGAGCTTCGTCTGCAGATTCTGCATTTAACGCCCTTGCATATGAATCGTTAGCCGATTGTTGACCTCCTCTAGCAGATCTGCCGTCGATTTGAAACTCTCCCCATTCAAGTGTATCTCCGTCTTTATCGATGTAGGACTTGACGTCGGAGCTCGACTTAGCTCCCTGAATGTTTGGATGGAAATGTGCTGACCTGGATGTGGAAACCAGGTCGAAGAATCTGTTATTCGTGCATTGGTATTTTCCTTCGAATTGGATGAGCACGTGAAGATGAGGTTCCCCATTTTCATGGAGTTCCCTGCATATCTTGATGAACTTCTTGTTTACTGGAGTGGTTATCGAACGTAACTGGTCAAGAGCTTCTTCTTTCGTGAGAGAGCACTTTGGATAAGTGATGAAGAAGTTCTTGGCATTTAAGCGAAAGCGTTTCTGCAGTGGCATATTTGTAATAAGAAGGGTGTACACCGATTGAGGCTCTCAACTCTTACTCATGTTATTGGTGTATTGGTGCCAATATATAGTATACCTTCTATTCTATAGATTTTTGACACGTGGAGGCCATCCGTTATAATATT
Gene Information
|
NCBI Accession
|
YP_009547940.1
|
|
Location
|
386-1156 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTATCCAAGAAAATATAGGCGCGGTTCATTTTATTCACATCGACGCTCAAATAATGTGTTTAAGCGATCCACCTATGTTAAAGGAAAGGATGTTAAAGATGGTAAGCGTCGATTAAATTATGGCAGCAATGTTCATGATGATTCCAAAATGTCATCTAAACGTATACATGAGAATCAGTATGGGCCTGATTTTGTGTTAGCCCATAATGCTGCCATCTCTACGTTCATTAGTTATCCTCATTTGGGTAAGACGGAACCCAATCGATCCAGGTCATATATTAAGTTGAAACGTTTACGTTTCAAAGGCACGGTGAAATTTGAACGTGTTCATGCTGATGTGAATATGGATGGTTTATGTCCCAAAATAGACGGAGTATTTTCTCTTGTTATTGTTATGGACCGCAAACCTCATCTCAGTGCGTCTGGGGTTTTGCATACCTTTGATGAACTATTCGGTGCAAGAATACATAGTCATGGTAACCTGTGCATAACCCCAGCTTTGAAAGACCGCTTCTATATTCGTCATGTATTAAAGCGAGTTGTATCTGTGGAGAAGGACACTGCAATGATTGACCTTGATGGATCGATTGGGTTATCTACTCGTCGTTTTAATTGTTGGGCTACATTTAAAGACCTTGATCATGATTCATCTAATGGGGTGTATGATAATATAAGTAAAAACGCTATCTTAGTTTATTATTGTTGGATGTCGGATGCCATGTCTAAAGCATCCACATTTGTATCGTTCGATCTTGATTATGTTGGCTGA |
|
Protein Sequence
|
MYPRKYRRGSFYSHRRSNNVFKRSTYVKGKDVKDGKRRLNYGSNVHDDSKMSSKRIHENQYGPDFVLAHNAAISTFISYPHLGKTEPNRSRSYIKLKRLRFKGTVKFERVHADVNMDGLCPKIDGVFSLVIVMDRKPHLSASGVLHTFDELFGARIHSHGNLCITPALKDRFYIRHVLKRVVSVEKDTAMIDLDGSIGLSTRRFNCWATFKDLDHDSSNGVYDNISKNAILVYYCWMSDAMSKASTFVSFDLDYVG |
|
NCBI Accession
|
YP_009547941.1
|
|
Location
|
1212-2093 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGATTCTCAGTTAGCAAATCCACCTAACGCGTTCAACTATATAGAATCTCATAGAGATGAATATCAACTGTCTCATGATCTAACTGAGATAGTTCTGCAATTTCCTTCCACGGCGTCGCAATTAACGGCAAGACTTAGTCGGAGTTGTATGAAAATTGACCATTGCGTCATAGAATATAGACAACAAGTACCAATTAACGCGACGGGATCAGTAATAGTGGAGATTCATGACAAACGAATGACAGACAACGAGTCATTACAAGCATCATGGACATTTCCCATCAGATGCAACATAGATCTCCACTATTTTTCGTCATCATTCTTTTCCTTAAAAGACCCCATTCCATGGAAACTATACTACAGGGTTTCTGATACCAATGTTCATCAAAGGACTCATTTTGCCAAGTTCAAAGGAAAACTGAAATTGTCCACAGCGAAACATTCAGTAGATATCCCATTCCGGGCACCAACGGTGAAAATTCTGTCAAAACAGTTCTCACATAAAGATGTCGACTTTTCGCATGTGGACTATGGTAAATGGGAGAGACGACCAATTAGGTCCACATCAATGTCCAGATTTGGACTACCAGGCCCAATTGAATTGAAACCCGGAGAGTCATGGGCCTCCAGAAGCACAATTGGATTGACACATACAGACTCAGAGTCAGACATGGAAAATGCAACACATCCATATAAAGAACTCCATCGCTTAGGAACAAGCGTTTTCGACCCGGGTGAATCGGCTTCAATAATAGGTGCGCAGAGGGCCCAATCAAACATTACAATGTCAGTTGCCCAATTAAGCGAGTTAGTCAGAACTACCGTTCAAGAATGTATTAACAATAATTGTACTCCTTCTCAACCAAAAACATTGAAATAA |
|
Protein Sequence
|
MDSQLANPPNAFNYIESHRDEYQLSHDLTEIVLQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFSHKDVDFSHVDYGKWERRPIRSTSMSRFGLPGPIELKPGESWASRSTIGLTHTDSESDMENATHPYKELHRLGTSVFDPGESASIIGAQRAQSNITMSVAQLSELVRTTVQECINNNCTPSQPKTLK |
|
NCBI Accession
|
YP_009325421.1
|
|
Location
|
202-951 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGGGATGCCCCGTGGCGTTATACTGCGGGGACCTCAAAGGTTAGTCGCAATGCTAATTATTCACCTGGTGGAGGCCCAAAATCCAACAGGACCAATGCTTGGGTAAACAGGCCCATGTACAGGAAGCCCAGGATATATCGTATGTATAGATCCCCCGATGTTCCGAAAGGCTGTGAAGGGCCCTGTAAAATCCAGTCTTTTGAACAGAGACATGATGTTTCTCATGTTGGTAAGGTTATGTGTATATCCGACGTGACTCGTGGTAATGGTATTACCCATCGTGTTGGTAAACGATTCTGTGTTAAGTCTGTTTACATTTTAGGGAAAGTATGGATGGACGACAACATCAAGTTGAAGAACCACACCAACAGTGTCATGTTTTGGTTAGTCAGGGATAGACGACCATATGGCACCCCTATGGATTTTGGCCAAGTTTTTAATATGTTCGATAATGAGCCTAGTACAGCTACTGTTAAGAACGACCTCCGTGATCGTTTCCAAGTCATGCACAAATTTTATGCCAAGGTTACAGGTGGACAATATGCCAGCAACGAGCAATCTTTGGTCAAGCGTTTTTGGAAGGTGAATAATTATGTCGTCTACAACCATCAGGAAGCTGCTAAATATGAGAACCATACTGAGAATGCTCTATTATTGTATATGGCATGTACTCATGCTTCTAATCCTGTGTATGCTACTCTAAAAATTCGGATCTATTTTTATGATTCGATAATGAATTAA |
|
Protein Sequence
|
MPKRDAPWRYTAGTSKVSRNANYSPGGGPKSNRTNAWVNRPMYRKPRIYRMYRSPDVPKGCEGPCKIQSFEQRHDVSHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKVWMDDNIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYAKVTGGQYASNEQSLVKRFWKVNNYVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
|
NCBI Accession
|
YP_009325422.1
|
|
Location
|
948-1346 |
|
Gene Name
|
AC3 |
|
Protein Name
|
REn |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAGGCGACGAGTGGCGTTTATATTTGGGAGGTTCCAAATCCCCTCTATTTCAAGATAACCAGAGTAGAGAAACCACTCTTCACACACACGACGGTGTTCCACATACAAGTCCGAGCCAACCACAACCTGAGGAAAGCGTTGGCTCTCCACAAAGCCTACTTCAATTTCCAAGTTTGGACGACATTGACGACAGCTTCTGGGCAGATTTATTTAAATAGATTCAAGTTTCTTGTAATGTATTACTTAGACAATTTAGGTGTTATTTCAGTTAACAATGTAATTAAAGCTGTCTCTTTTGCAACGAACAGAAGTTATGTCAACGATGTACTTGAATATCATGAAATAAAATTCAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGEPITAAQATSGVYIWEVPNPLYFKITRVEKPLFTHTTVFHIQVRANHNLRKALALHKAYFNFQVWTTLTTASGQIYLNRFKFLVMYYLDNLGVISVNNVIKAVSFATNRSYVNDVLEYHEIKFKFY |
|
NCBI Accession
|
YP_009325423.1
|
|
Location
|
1093-1509 |
|
Gene Name
|
AC2 |
|
Protein Name
|
TrAP |
|
Coding Region
|
ATGACTGGGCACAGAAGAACGCCATCTTCGTCTCCATTGAAGAACCTCTCTTCACCACCGAAAATTAAACCTCGCCATAGATACGCGAAAAAACAAATAAGACGAAGAAGGATTGATCTGCAGTGCGGCTGTTCTATTTACATTCACATTAACTGCAGAAACAATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAGGCGACGAGTGGCGTTTATATTTGGGAGGTTCCAAATCCCCTCTATTTCAAGATAACCAGAGTAGAGAAACCACTCTTCACACACACGACGGTGTTCCACATACAAGTCCGAGCCAACCACAACCTGAGGAAAGCGTTGGCTCTCCACAAAGCCTACTTCAATTTCCAAGTTTGGACGACATTGACGACAGCTTCTGGGCAGATTTATTTAAATAG |
|
Protein Sequence
|
MTGHRRTPSSSPLKNLSSPPKIKPRHRYAKKQIRRRRIDLQCGCSIYIHINCRNNGFTHRGTHHCSSGDEWRLYLGGSKSPLFQDNQSRETTLHTHDGVPHTSPSQPQPEESVGSPQSLLQFPSLDDIDDSFWADLFK |
|
NCBI Accession
|
YP_009325424.1
|
|
Location
|
1442-2479 |
|
Gene Name
|
AC1 |
|
Protein Name
|
Rep |
|
Coding Region
|
ATGCCACTGCAGAAACGCTTTCGCTTAAATGCCAAGAACTTCTTCATCACTTATCCAAAGTGCTCTCTCACGAAAGAAGAAGCTCTTGACCAGTTACGTTCGATAACCACTCCAGTAAACAAGAAGTTCATCAAGATATGCAGGGAACTCCATGAAAATGGGGAACCTCATCTTCACGTGCTCATCCAATTCGAAGGAAAATACCAATGCACGAATAACAGATTCTTCGACCTGGTTTCCACATCCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAGTCGAGCTCCGACGTCAAGTCCTACATCGATAAAGACGGAGATACACTTGAATGGGGAGAGTTTCAAATCGACGGCAGATCTGCTAGAGGAGGTCAACAATCGGCTAACGATTCATATGCAAGGGCGTTAAATGCAGAATCTGCAGACGAAGCTCTACAGATAATCAAAGAGCATCAACCACAACATTTTGTCTTACAATATCATAATTTAGTCACAAACATATCCAAAATATTTCAAAAACCCCCGGAACCATGGGTTCCTCCATTCCAGTTGTCCACATTCAATAATGTTCCAGATATAATGTCAGAATGGGTTAGTCAGAATATTGCCGATTCCGCTGCGCGGCCAATTAGACCTATATCAATTATTATTGAAGGATCATCAAGAACAGGCAAAACATTATGGGCCCGTAGTCTCGGGCCTCACAACTACTTATGTGGTCATATCGATCTAAATTCAAAAATTTACTCCAATAATGCATGGTATAACGTCATTGATGATGTTGATCCCCATTATTTAAAACACTTTAAAGAGTTCATGGGGGCCCAGAGGGATTGGCAATCAAACTGCAAATACGGAAAGCCAATTCAAATTAAAGGTGGAATTCCCACTATCTTCCTTTGCAATCCAGGCCCCCATTCATCATATAAGGAGTTTCTCAGTGAGGACAAAAACACATCACTCAATGACTGGGCACAGAAGAACGCCATCTTCGTCTCCATTGAAGAACCTCTCTTCACCACCGAAAATTAA |
|
Protein Sequence
|
MPLQKRFRLNAKNFFITYPKCSLTKEEALDQLRSITTPVNKKFIKICRELHENGEPHLHVLIQFEGKYQCTNNRFFDLVSTSRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGQQSANDSYARALNAESADEALQIIKEHQPQHFVLQYHNLVTNISKIFQKPPEPWVPPFQLSTFNNVPDIMSEWVSQNIADSAARPIRPISIIIEGSSRTGKTLWARSLGPHNYLCGHIDLNSKIYSNNAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNCKYGKPIQIKGGIPTIFLCNPGPHSSYKEFLSEDKNTSLNDWAQKNAIFVSIEEPLFTTEN |
|
NCBI Accession
|
YP_009325425.1
|
|
Location
|
2065-2328 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGAAAATGGGGAACCTCATCTTCACGTGCTCATCCAATTCGAAGGAAAATACCAATGCACGAATAACAGATTCTTCGACCTGGTTTCCACATCCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAGTCGAGCTCCGACGTCAAGTCCTACATCGATAAAGACGGAGATACACTTGAATGGGGAGAGTTTCAAATCGACGGCAGATCTGCTAGAGGAGGTCAACAATCGGCTAACGATTCATATGCAAGGGCGTTAA |
|
Protein Sequence
|
MKMGNLIFTCSSNSKENTNARITDSSTWFPHPGQHISIQTFRELSRAPTSSPTSIKTEIHLNGESFKSTADLLEEVNNRLTIHMQGR |