Common bean mottle virus
Basic Information
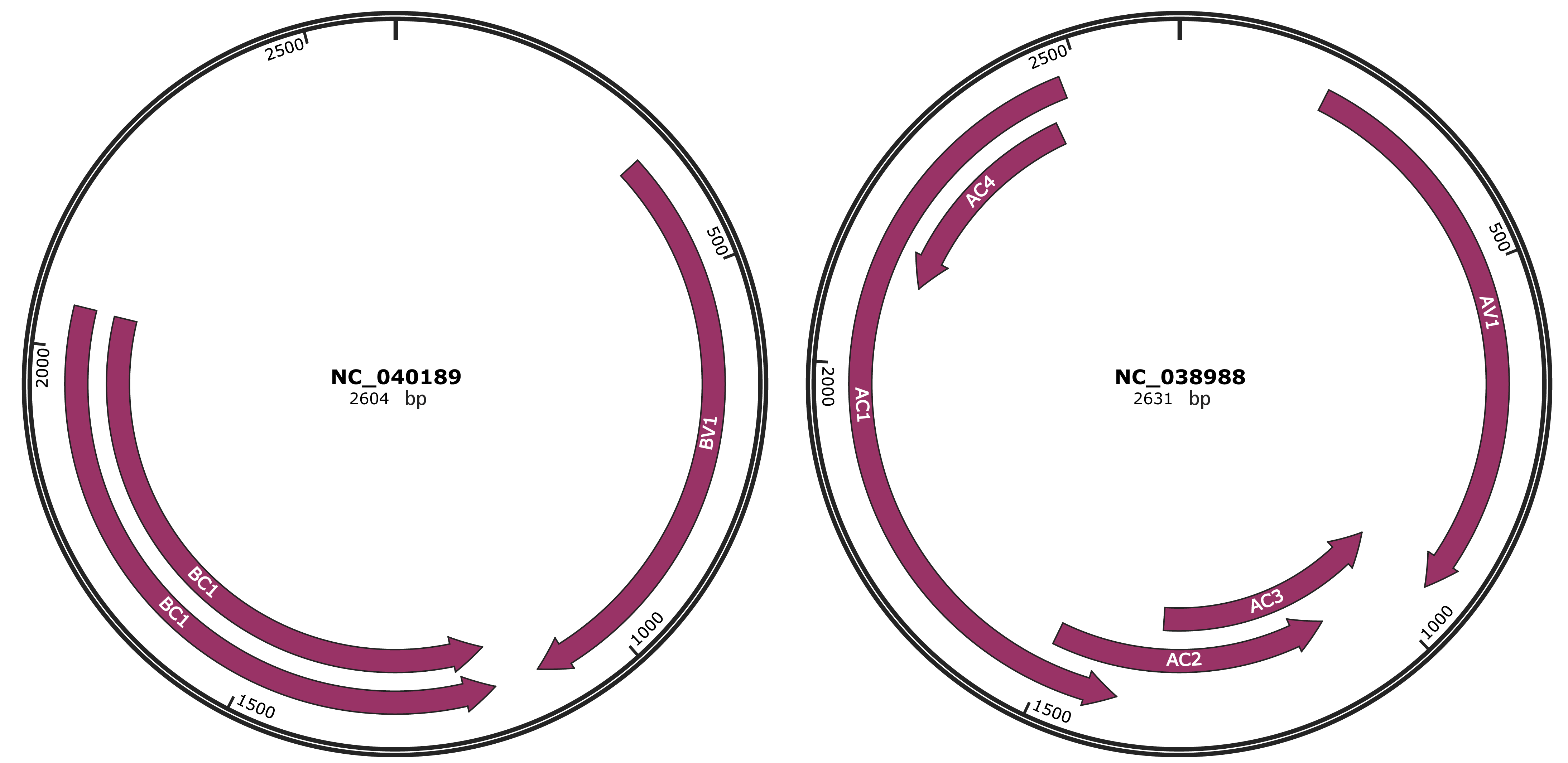
Genomic Organization
JBrowse
Genome
ACCAGATGGCCGACCGGTGTCTCTCTGGTGCCGTACGCCCACGTGACGCTTTTCATTGTCCAATCACATTTGCGGTAGGGAGTTAAAGCTTATCCACACTTTAACTTGAATTTTGAATTATTGCCGTTTGAAGGATATTGGCGCTATTATTAAAGTGCATGCGGTCTGACACATTTGCGCAATTATTATTTTGAGTGCGGTCTGACACAGTGTACGTCTATTTACACATGGACCAATCAAAATTCAAGTTGGGCGTCTATATAATACGTTTGCCGTTTATTAAAGCTATAAATGTGTCAAGGAAAAATATATCCTATATGAGTGTTTTATTGTGATTTAACTATGTATTCTTCTAAATATAAACGTGGTGTGTCTAATTATCAACGACGTGGTTATATTCGTAATCAAGTCTTGCGAAAAGCATCTTTTAAACGTTATGATGGCAAACGTCGACAAATTCATGGTGGTAAGGTTTATGATGATTCTAAAATGTTGGATCAACGGTTACATGAAAATCAATTTGGACCTGAATTTGTTATGGGTCAGAATGGTGCTATATCGACGTTTATTAGTTTCCCTCAATTGGGTAAGAATAAACCCAATCGAACTAGGTCATATATTAAATTAAAACGTTTGCGATTAAAAGGTACTGTTAAAATAGAGCGTGTTCGTAATGATATGAATATGGATGGTATTTCCTCAAAAATCGAAGGTGTATTCTCTATGGTTGTTGTGGTGGATCGTAAACCACATCTTGGTCCGTCTGGGAATCTACCAACATTTGAAGATTTATTCGGTGCAAGGATTAATAGTCATGGTAACTTAGCAATAATTCCGTCAATGGAGGACCGTTTTTATATACGACATGTTACGAAGCGAGTATTATCCGTGGATAATGACACAATGATGATCGATGTTGAAGGTTATACAAAATTGTCTAATAGGCGATATAATATGTGGTCTACGTTTAAGGATATAGACCATGAATCAAGTAATGGGGCCTATGATAATATTAGTAAAAATGCGATTTTAGTGTATTACTGTTGGATGTCGGATAATATGTCAAAGGCATCTACATTTGTATCATTTGATCTTGATTATGTGGGTTGAAAATGAATAAAATTATGTGTATTGGGATATTGTGTATAAGAAAATAAAATACGCACATTTTATTTCAATGCTTTGGGCTGATTTGGAATACAATTATTGTTTATACATTCTTGAACCGTTGTCCTAACAAGATCGCTTAATTGGGCCACTGACATTGTAATGTTTGATTGGGTTCTTTGCAACCCTGCTTGTGATGCTGAATCACCTGGGTCTATTGCGCTTGATCCTAAACGATTCAGTTGTCTGTATGGATGTATTGCGTTTTCTATTTCAGAATCCGTATCTGTATGAGTAAGCCCAATTGTGCTTTTGGCGGCCCATGACTCTCCTGGTCTCAATTCAATTGGGCCTGGTAGAGCAACTCTGGATATGGATGTGGACCTTAATGTTTTTCGTTCCCATCGACCGTAGTCCACATGCGAAAAATCAACATCTTTATGTGAAAATTGTTTGGAGTGAATTTTCACTGTTGGTGCTCGGAAGGGTATATCCACTGAATGTTTAGCCGTGGATAATTTTAATTTACCCTTAAACTTGGCAAAATGTGTTCTTTGATGTACGTTTGTGTCGCTAACTCTATAATACAGTTTCCATGGTATTGGGTCTTTTAGCGAGAAGAAGGAAGAGGAAAAGTAATGGAGATCTATGTTGCATCGTAGTGGAAATGTCCATGATGCTTGTAATGATTCATCGTCAGTCATTCTTTTGTCATGGATCTCTACAATGACTGTGCCAGTAGCGTTTATTGGTACTTGCTGCCTATATTCAATGACGCAATGGTCAATTTTCATACAGCTACGACTGAGCCTTGCTGTTAATTGTGCTGCTGTTGAAGGAAATTGAAGAATTATCTCAGTTAGATCATGAGACAGTTGATATTCATCCCTATGGGATTCTATGTAATTAAACGCATTTGGAGCATTTGCTAACTGAGAATCCATATATGGAGAATATGGCCACGCAGTGGCGTTGTCAAAAAAAAATGATGATGTTAGACGGATGAAGAGAATGAACAGTATGAATATGAATCCAGAATATGTTGCACTATAATGAAAAAGTAGTATTTCAAGGAGTAATTTGAATATGATAAAGAGAATTTGAGATCAACATTACTAAGCATATCTTGAATATGTATATGATATTCAGAATATGTTGGAATACACAGAAAAAGAAAATATGAATATGCACGATTTGAAAATGCTGGATAATGAATGTTTATGCGGTACAATATTTCTGGGTTCAGAAATAGTCAGATGATAATATATGTTTGTTTATGTTGTTTATATAGACAGTCAGATGGTGTGAGGTGTTATGAAGCGAGAGCGTTCCGAATGGCATATTTGTAATAAGAGAGTGTACACCAAATGAAAATGCGGAGATACACCAATTGAGCTCTTCAACTCCCCCCCCCTCTATTGGTGTATTGGAGTGCTATATATACTATTACTCTCAATTATTGATTTGATACACGTGGAGGCCATCTGTTATAATATT
ACCGGATGGCCGACCGGTGTCTCTTTGGCGCCGTACAACCACGTGATGCTTTATTTTGAATTAAAGTTGTTTATTTTGCATTGGCCAATCACGTTTGCACTGGCGAGTCTAGATATTCGTGTTCAGACTTAGCGACCAAGTTTATGTTGCATATAAATGTGTGCCATCTTACGTGGAGCCAGTGTCTTTAATTCAAAATGCCTAAGCGGGATGCCCCGTGGCGTTCTAATGCGGGGACCTCTAAGGTTAGCCGTAATTTGAATTACTCTCCTCGTGGAGGCCCAAAATCCAATAAGGCCAACGATTGGGTTAATAGGCCCATGTATAGAAAGCCCAGGTTTTATCGGATGTACAGGACTCCCGATGTACCTAGAGGATGTGAAGGGCCATGTAAGATCCAGTCGTTTGAACAACGCCATGATGTGTCTCACCTTGGTAAGGTTATGTGTATATCTGACGTGACACGTGGTAACGGTATTACCCATCGCGTTGGAAAACGTTTCTGTATCAAGTCTGTGTATATTTTAGGCAAGGTATGGATGGATGACAATATCAAGTTAAAGAATCACACCAACAGTGTTATGTTTTGGTTGGTTAGGGATAGGAGACCATATGGCACTCCCATGGATTTTGGTCAAGTTTTTAATATGTTTGATAATGAACCAAGTACTGCTACGGTTAAGAACGATCTTCGTGATCGTTTCCAGGTCTTGCACAAGTTTTATTCTAAGGTTACAGGTGGACAATATGCGAGTAATGAACAATCACTCGTTAAGCGATTTTGGAAGGTTAACAACCATGTGGTGTATAACCATCAGGAAGCGGCTAAGTACGAGAATCACACTGAAAATGCTCTATTATTGTATATGGCATGTACTCATGCGTCTAATCCTGTGTATGCTACATTGAAAATTCGGATCTATTTTTACGATTCGATAATGAATTAATAAAGTTTATATTTTATATCATGATCTTCAAGTACATCATTTACATAATGTTTGTCTGTTGCATATGAGACAGCTCTAATAATATTGTTAACTGAAATAACACCTAAATTGTCTAAGTAATACATGACAATAAATTTGAATCTACTTAAATAATTCTTCCCAGAAGCTGTCGTCAAAGTCGTCCAGACTTGGAAATTGAAGTAGGCTTTGTGGAGAGCCAACGCTTTCCTGAGGTTGTGGTTGGCTCGGATTTGTATTTGGAACACCTTGCTGCGTGTGTATATTGGATGTTCCACCCATACGATCTTGAAATATAGGGGATTTGGAACCTCCCAAATAAAAACGCCATTCGTTGCCTGAGCTGCAGTGATGGGTTCCCCTGTGCGTGAATCCATGATTGTTGCAGTTGATGTGAACGTAAATTGAACAGCCGCACTGCAGATCAATTCTTTTACGCCTCGTTTGTCTCTTCGCGTATCGATGGCGAGGTTTGATTGACGGAGGAGAACAGTGGTCTCTCAATTGAGACGTAGATGGCGTTTTTTTGTGCCCAGTCATTGAGTGATCTGTTCTTGTCCTCGCCGAGATACTCTTTATATGATGAATGGGGGCCAGGATTGCAAAGGAAGATAGTGGGAATTCCTCCTTTAATTTGAATTGGCTTTCCGTATTTGCAGTTTGATTGCCAATTTCTTTGGGCCCCCATGAACTCTTTAAAGTGTTTGAGATAATGCGGATCTACGTCGTCGATGACGTTATACCAAGCATCATTGGAGTATATGCGTGGATTGAGATCGATATGACCACATAAATAATTATGAGGGCCCAGACTTCGGGCCCATAATGTTTTGCCTGTTCTTGATGATCCTTCAATAATAATTGAAATAGGTCTCAATGGCCGCGCAGCGGCATCGACAACATTATGACTAACCCAGTCTTTCATGACTTGAGGAACATTATCAAACGTTGATGATTGATATGGAGGAACCCATTGTTCCGGGGCCTTTGCGAAGATTCGTTGGAGATTATTATGTATGTTATGATGTTGAAGGAGATAATCTTTGGGTTGTTCCTCTTTAATGATCTTTAATGCTTCGTCTATGGATTCTGCATTTAAGGCCTTTGCATATGAATCATTAGCAGATTGCTTACCTCCTCTAGCTGATCTGCCGTCTATTTGAAACTCTCCCCATTCGAGTGTATCCCCGTCTTTGTCGATGTAGGATTTGACGTCTGAGCTAGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGTTGACCTGGTTGTGGATACCAGGTCGAAGAATCTATTATTCGCGCATTGGTATTTACCTTCGAATTGGATGAGAACATGCAGATGTGGTTGCCCATCTTCATGCAATTCGCTGCAGATCTTGATGTATTTTTTGTTGACAGGTGTGGATAATTGTTGTAATTGTGATAATGCCTCTTCTTTAGAAAGAGAACATTTTGGATATGTGAGGAAGTAGTTCTTTGCATTTAAACGAAAGCGTTTCTGGAGTGGCATTGTTGTAATAAGAGGGTGTACACCAAATGAAAATGCGGAGATACACCAATTGAGCTCTTCAACTCCCCCCCCCTTCTATTGGTGTATTGGTGTTCTATATATAGTATAATTCTAATTATTGCTTTTTGCTACGTGGAGGCCATCCGTTATAATATT
Gene Information
|
NCBI Accession
|
YP_009547938.1
|
|
Location
|
343-1110 |
|
Gene Name
|
BV1 |
|
Protein Name
|
NSP |
|
Coding Region
|
ATGTATTCTTCTAAATATAAACGTGGTGTGTCTAATTATCAACGACGTGGTTATATTCGTAATCAAGTCTTGCGAAAAGCATCTTTTAAACGTTATGATGGCAAACGTCGACAAATTCATGGTGGTAAGGTTTATGATGATTCTAAAATGTTGGATCAACGGTTACATGAAAATCAATTTGGACCTGAATTTGTTATGGGTCAGAATGGTGCTATATCGACGTTTATTAGTTTCCCTCAATTGGGTAAGAATAAACCCAATCGAACTAGGTCATATATTAAATTAAAACGTTTGCGATTAAAAGGTACTGTTAAAATAGAGCGTGTTCGTAATGATATGAATATGGATGGTATTTCCTCAAAAATCGAAGGTGTATTCTCTATGGTTGTTGTGGTGGATCGTAAACCACATCTTGGTCCGTCTGGGAATCTACCAACATTTGAAGATTTATTCGGTGCAAGGATTAATAGTCATGGTAACTTAGCAATAATTCCGTCAATGGAGGACCGTTTTTATATACGACATGTTACGAAGCGAGTATTATCCGTGGATAATGACACAATGATGATCGATGTTGAAGGTTATACAAAATTGTCTAATAGGCGATATAATATGTGGTCTACGTTTAAGGATATAGACCATGAATCAAGTAATGGGGCCTATGATAATATTAGTAAAAATGCGATTTTAGTGTATTACTGTTGGATGTCGGATAATATGTCAAAGGCATCTACATTTGTATCATTTGATCTTGATTATGTGGGTTGA |
|
Protein Sequence
|
MYSSKYKRGVSNYQRRGYIRNQVLRKASFKRYDGKRRQIHGGKVYDDSKMLDQRLHENQFGPEFVMGQNGAISTFISFPQLGKNKPNRTRSYIKLKRLRLKGTVKIERVRNDMNMDGISSKIEGVFSMVVVVDRKPHLGPSGNLPTFEDLFGARINSHGNLAIIPSMEDRFYIRHVTKRVLSVDNDTMMIDVEGYTKLSNRRYNMWSTFKDIDHESSNGAYDNISKNAILVYYCWMSDNMSKASTFVSFDLDYVG |
|
NCBI Accession
|
YP_009547939.1
|
|
Location
|
1170-2051 |
|
Gene Name
|
BC1 |
|
Protein Name
|
MP |
|
Coding Region
|
ATGGATTCTCAGTTAGCAAATGCTCCAAATGCGTTTAATTACATAGAATCCCATAGGGATGAATATCAACTGTCTCATGATCTAACTGAGATAATTCTTCAATTTCCTTCAACAGCAGCACAATTAACAGCAAGGCTCAGTCGTAGCTGTATGAAAATTGACCATTGCGTCATTGAATATAGGCAGCAAGTACCAATAAACGCTACTGGCACAGTCATTGTAGAGATCCATGACAAAAGAATGACTGACGATGAATCATTACAAGCATCATGGACATTTCCACTACGATGCAACATAGATCTCCATTACTTTTCCTCTTCCTTCTTCTCGCTAAAAGACCCAATACCATGGAAACTGTATTATAGAGTTAGCGACACAAACGTACATCAAAGAACACATTTTGCCAAGTTTAAGGGTAAATTAAAATTATCCACGGCTAAACATTCAGTGGATATACCCTTCCGAGCACCAACAGTGAAAATTCACTCCAAACAATTTTCACATAAAGATGTTGATTTTTCGCATGTGGACTACGGTCGATGGGAACGAAAAACATTAAGGTCCACATCCATATCCAGAGTTGCTCTACCAGGCCCAATTGAATTGAGACCAGGAGAGTCATGGGCCGCCAAAAGCACAATTGGGCTTACTCATACAGATACGGATTCTGAAATAGAAAACGCAATACATCCATACAGACAACTGAATCGTTTAGGATCAAGCGCAATAGACCCAGGTGATTCAGCATCACAAGCAGGGTTGCAAAGAACCCAATCAAACATTACAATGTCAGTGGCCCAATTAAGCGATCTTGTTAGGACAACGGTTCAAGAATGTATAAACAATAATTGTATTCCAAATCAGCCCAAAGCATTGAAATAA |
|
Protein Sequence
|
MDSQLANAPNAFNYIESHRDEYQLSHDLTEIILQFPSTAAQLTARLSRSCMKIDHCVIEYRQQVPINATGTVIVEIHDKRMTDDESLQASWTFPLRCNIDLHYFSSSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKIHSKQFSHKDVDFSHVDYGRWERKTLRSTSISRVALPGPIELRPGESWAAKSTIGLTHTDTDSEIENAIHPYRQLNRLGSSAIDPGDSASQAGLQRTQSNITMSVAQLSDLVRTTVQECINNNCIPNQPKALK |
|
NCBI Accession
|
YP_009508412.1
|
|
Location
|
198-947 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGGGATGCCCCGTGGCGTTCTAATGCGGGGACCTCTAAGGTTAGCCGTAATTTGAATTACTCTCCTCGTGGAGGCCCAAAATCCAATAAGGCCAACGATTGGGTTAATAGGCCCATGTATAGAAAGCCCAGGTTTTATCGGATGTACAGGACTCCCGATGTACCTAGAGGATGTGAAGGGCCATGTAAGATCCAGTCGTTTGAACAACGCCATGATGTGTCTCACCTTGGTAAGGTTATGTGTATATCTGACGTGACACGTGGTAACGGTATTACCCATCGCGTTGGAAAACGTTTCTGTATCAAGTCTGTGTATATTTTAGGCAAGGTATGGATGGATGACAATATCAAGTTAAAGAATCACACCAACAGTGTTATGTTTTGGTTGGTTAGGGATAGGAGACCATATGGCACTCCCATGGATTTTGGTCAAGTTTTTAATATGTTTGATAATGAACCAAGTACTGCTACGGTTAAGAACGATCTTCGTGATCGTTTCCAGGTCTTGCACAAGTTTTATTCTAAGGTTACAGGTGGACAATATGCGAGTAATGAACAATCACTCGTTAAGCGATTTTGGAAGGTTAACAACCATGTGGTGTATAACCATCAGGAAGCGGCTAAGTACGAGAATCACACTGAAAATGCTCTATTATTGTATATGGCATGTACTCATGCGTCTAATCCTGTGTATGCTACATTGAAAATTCGGATCTATTTTTACGATTCGATAATGAATTAA |
|
Protein Sequence
|
MPKRDAPWRSNAGTSKVSRNLNYSPRGGPKSNKANDWVNRPMYRKPRFYRMYRTPDVPRGCEGPCKIQSFEQRHDVSHLGKVMCISDVTRGNGITHRVGKRFCIKSVYILGKVWMDDNIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVLHKFYSKVTGGQYASNEQSLVKRFWKVNNHVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
|
NCBI Accession
|
YP_009508413.1
|
|
Location
|
944-1342 |
|
Gene Name
|
AC3 |
|
Protein Name
|
REn |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAGGCAACGAATGGCGTTTTTATTTGGGAGGTTCCAAATCCCCTATATTTCAAGATCGTATGGGTGGAACATCCAATATACACACGCAGCAAGGTGTTCCAAATACAAATCCGAGCCAACCACAACCTCAGGAAAGCGTTGGCTCTCCACAAAGCCTACTTCAATTTCCAAGTCTGGACGACTTTGACGACAGCTTCTGGGAAGAATTATTTAAGTAGATTCAAATTTATTGTCATGTATTACTTAGACAATTTAGGTGTTATTTCAGTTAACAATATTATTAGAGCTGTCTCATATGCAACAGACAAACATTATGTAAATGATGTACTTGAAGATCATGATATAAAATATAAACTTTATTAA |
|
Protein Sequence
|
MDSRTGEPITAAQATNGVFIWEVPNPLYFKIVWVEHPIYTRSKVFQIQIRANHNLRKALALHKAYFNFQVWTTLTTASGKNYLSRFKFIVMYYLDNLGVISVNNIIRAVSYATDKHYVNDVLEDHDIKYKLY |
|
NCBI Accession
|
YP_009508414.1
|
|
Location
|
1089-1505 |
|
Gene Name
|
AC2 |
|
Protein Name
|
TrAP |
|
Coding Region
|
ATGACTGGGCACAAAAAAACGCCATCTACGTCTCAATTGAGAGACCACTGTTCTCCTCCGTCAATCAAACCTCGCCATCGATACGCGAAGAGACAAACGAGGCGTAAAAGAATTGATCTGCAGTGCGGCTGTTCAATTTACGTTCACATCAACTGCAACAATCATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAGGCAACGAATGGCGTTTTTATTTGGGAGGTTCCAAATCCCCTATATTTCAAGATCGTATGGGTGGAACATCCAATATACACACGCAGCAAGGTGTTCCAAATACAAATCCGAGCCAACCACAACCTCAGGAAAGCGTTGGCTCTCCACAAAGCCTACTTCAATTTCCAAGTCTGGACGACTTTGACGACAGCTTCTGGGAAGAATTATTTAAGTAG |
|
Protein Sequence
|
MTGHKKTPSTSQLRDHCSPPSIKPRHRYAKRQTRRKRIDLQCGCSIYVHINCNNHGFTHRGTHHCSSGNEWRFYLGGSKSPIFQDRMGGTSNIHTQQGVPNTNPSQPQPQESVGSPQSLLQFPSLDDFDDSFWEELFK |
|
NCBI Accession
|
YP_009508415.1
|
|
Location
|
1399-2475 |
|
Gene Name
|
AC1 |
|
Protein Name
|
Rep |
|
Coding Region
|
ATGCCACTCCAGAAACGCTTTCGTTTAAATGCAAAGAACTACTTCCTCACATATCCAAAATGTTCTCTTTCTAAAGAAGAGGCATTATCACAATTACAACAATTATCCACACCTGTCAACAAAAAATACATCAAGATCTGCAGCGAATTGCATGAAGATGGGCAACCACATCTGCATGTTCTCATCCAATTCGAAGGTAAATACCAATGCGCGAATAATAGATTCTTCGACCTGGTATCCACAACCAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCTAGCTCAGACGTCAAATCCTACATCGACAAAGACGGGGATACACTCGAATGGGGAGAGTTTCAAATAGACGGCAGATCAGCTAGAGGAGGTAAGCAATCTGCTAATGATTCATATGCAAAGGCCTTAAATGCAGAATCCATAGACGAAGCATTAAAGATCATTAAAGAGGAACAACCCAAAGATTATCTCCTTCAACATCATAACATACATAATAATCTCCAACGAATCTTCGCAAAGGCCCCGGAACAATGGGTTCCTCCATATCAATCATCAACGTTTGATAATGTTCCTCAAGTCATGAAAGACTGGGTTAGTCATAATGTTGTCGATGCCGCTGCGCGGCCATTGAGACCTATTTCAATTATTATTGAAGGATCATCAAGAACAGGCAAAACATTATGGGCCCGAAGTCTGGGCCCTCATAATTATTTATGTGGTCATATCGATCTCAATCCACGCATATACTCCAATGATGCTTGGTATAACGTCATCGACGACGTAGATCCGCATTATCTCAAACACTTTAAAGAGTTCATGGGGGCCCAAAGAAATTGGCAATCAAACTGCAAATACGGAAAGCCAATTCAAATTAAAGGAGGAATTCCCACTATCTTCCTTTGCAATCCTGGCCCCCATTCATCATATAAAGAGTATCTCGGCGAGGACAAGAACAGATCACTCAATGACTGGGCACAAAAAAACGCCATCTACGTCTCAATTGAGAGACCACTGTTCTCCTCCGTCAATCAAACCTCGCCATCGATACGCGAAGAGACAAACGAGGCGTAA |
|
Protein Sequence
|
MPLQKRFRLNAKNYFLTYPKCSLSKEEALSQLQQLSTPVNKKYIKICSELHEDGQPHLHVLIQFEGKYQCANNRFFDLVSTTRSTHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGKQSANDSYAKALNAESIDEALKIIKEEQPKDYLLQHHNIHNNLQRIFAKAPEQWVPPYQSSTFDNVPQVMKDWVSHNVVDAAARPLRPISIIIEGSSRTGKTLWARSLGPHNYLCGHIDLNPRIYSNDAWYNVIDDVDPHYLKHFKEFMGAQRNWQSNCKYGKPIQIKGGIPTIFLCNPGPHSSYKEYLGEDKNRSLNDWAQKNAIYVSIERPLFSSVNQTSPSIREETNEA |
|
NCBI Accession
|
YP_009508416.1
|
|
Location
|
2121-2447 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGCAAAGAACTACTTCCTCACATATCCAAAATGTTCTCTTTCTAAAGAAGAGGCATTATCACAATTACAACAATTATCCACACCTGTCAACAAAAAATACATCAAGATCTGCAGCGAATTGCATGAAGATGGGCAACCACATCTGCATGTTCTCATCCAATTCGAAGGTAAATACCAATGCGCGAATAATAGATTCTTCGACCTGGTATCCACAACCAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCTAGCTCAGACGTCAAATCCTACATCGACAAAGACGGGGATACACTCGAATGGGGAGAGTTTCAAATAG |
|
Protein Sequence
|
MQRTTSSHIQNVLFLKKRHYHNYNNYPHLSTKNTSRSAANCMKMGNHICMFSSNSKVNTNARIIDSSTWYPQPGQHISIRTFRELNLAQTSNPTSTKTGIHSNGESFK |