Cnidoscolus mosaic leaf deformation virus
Basic Information
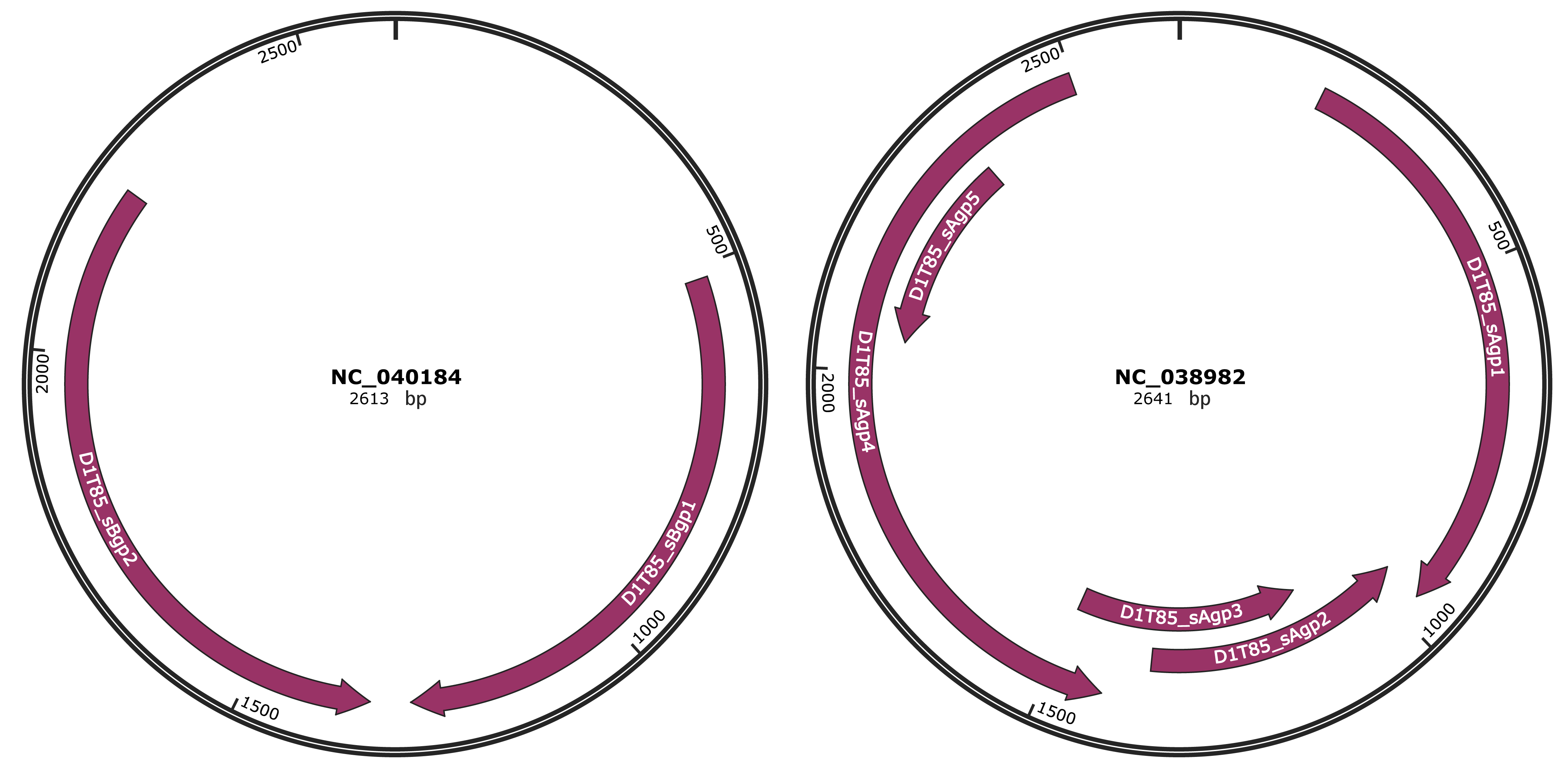
Genomic Organization
JBrowse
Genome
ACCGGATGGCCGCGCCCCCTCCCCGTACGACCCGCGCCTCGACCCGCGCTTTACCCGACCCGTAGCGCATTGTCGGCCACTACGTTGTTGTGTCATTGTCAATGTGGGGCCGTGTCAGAAACATATACGACGACTGGCCAATCAGAAGTATAACTGATAGTCTGAATATTTAACTTCTTGGGTGACGAGTATATAAAGAACGATAATGATTATCTTGTGTGGCCAGTCTTTAATTTGAAATTCACATGTGAGGATACTTTTGGCGCTGATTGACGTGTTTTATTAAACACAATAAGATGCAATTGATGTGGTGAATTTCAACGGCGAATTATTGGTTTACGTGTCTCATTTGTAGCCAAATTTATATTGGATATTTGTTCGTGCAATAATTGTGGATATGTGAACTGGACCAATAACATTCGCCATGTGTATCTATTACATTCTATTAAGAATATGGTGAACTATATATATTTGTTTAGGTGACATACGAACATGTGTATTAGCACAACAGGATAATGTATGTTAGTAGAAATAAACGTGGTTGGACGTCCAATTATCGTCGGAATACGTCGCGAAGGACGACATTTAAGCGCATCTACTATGCGCCACGCGTCGATGGGAAACGTCGAAGTAGTAAGACCAACAAGGTTCAAGAAGAAGGCAAAATTTCGAATCAGGTGATGCACGAGAATCAATATGGGCCTGACTTCGTTTTGATGCATAATACCGCTATATCGACGTACATAACTTATCCTTCACTGAGTAAAACTCAACCGTGTCGTTCAAGAGCATATATTAAGCTTCATCGTCTAAGTTTCAAAGGGACGGTTAGGATTGAAACTGCCCAAGCAGACGTGAACATGACTAGTTCAAATCCAAAGATCGAAGGAGTATTCACATTAGTTATTGTCGTCGATCGCAAACCGCATATTAATTCAACTGGGAGTCTTCACACATTTGATGAACTATTCGGTGCAAGGATTAATAGTCATGGGAATTTGTCCATAAATTCTTCTCTGAAGGAACGATTTTATATACGACATGTGTTTAAGCGTGTACTATCAACTGAGAATGATAGTGTGATGGTGGATATAGAAGGAACGACATCGTTTTCTAATAAGCGTTTTAACTGCTGGGCAAGTTTTAGGGACGTAGATCATGATTCATGTAATGGCGTATATGCGAACATAAGTAAAAACGCCTTATTAGTTTATTATTGCTGGATGTCTGACACGGCATCTCAAGCATCGTCATTTGTGTCATTTGATCTAGATTATGTTGGTTAATACACTGAATAATTTACAATGCGCGCTTTATTATTTATTCGATAAATAATATTTTACTTCAACGATTTGGGCTCAGATGGAGTACAGTTCAGGTTAATGCACTCTTGGACTGTGGATCGAACGATATCGTTAATTTGGGCTAATGACAAAGTGATGTTGGATTGTGCCCTCTGGGCCCCAATAATTGATGCCGAGTCGCCTGGATCTAATATTGTAGAGCCCAATTTGTTTAGTTGCTTATATGGATGTAGTTCGTTTCCCACCTCCGAGTCAGGATATGAATTGTTTGGGCCTAAAGAACTCCTTGAAGCCCATGACTCACCGGGCTTAATTTCGATTGGGCCGTTTAGGCCTATTGTGGAGGTGGAAACGTTCCTGATTAATTTTCTTTCCCAATTCCCATAAGCCACATGGGAAAAGTCGACGTCTTTGTCTGTGAATTGTTTCGACAAGATCTTCACCGTTGGTGCCTTGAAAGGGATATCCACTGAGTGTTTAGCCGTCGACAGTTTCAATTTTCCCTTGAATTTGGCGAAATGTGTTCTTTGATGAACATTAGTGTCAGAGACTTTGTAATATAACTTCCAAGGAATTGGGTCTTTAAGAGAGAAGAATGACGACGAGAAATAATGCAGATCAATGTTGCATCGAATTGGAAATGTCCACGAGGCTTGTAATGATTCGTTGTCATTCATTCGCTTGTCGTGAATTTCCACTATGACCGAGCCAGTGGCGTTGATTGGCACTTGTTGCCGGTATTCGATAACACAGTGATCTATTTTCATGCAGCTCCGGCTGAGTCTTGCAGTAATTTGAGACGCTGTAGATGGAAATTGCAACACAATTTCTGTTAGGTCGTGAGACAGCTGATACTCATCTCGTTGGGATTCGATATAATTAAAAGCGTTAGGAGGAATTACTAATTGAGATTCCATAATTTATGAAAAATAGGCCGCGCAGCGGAATGGAATCACCCAAGTTAACAACTAAAGACGAATGGCAATAATTGAAACAGTGTGAGTGGAAGAGGATAAACTGATAATAAATAATGTGAACAAGAGATAGGCAAACTTGGTTTGGGATAATTGTTTCATATAACTGGATCTATTTATAGACTACTAATAATGGATAGGATTGACAGGAATGTTGTATTGAGGTATCGAAACGACGTGGTTTGATGGCATTTATGTAATAAGAAGGTTGGACACCGATTGGGGTCTCTTCAAACTTCCTCTAGCAATTGGGGTCTGGGGTCTTACTTATACTAGAAGCCCCAATAGAACTTCAAATCTCCATCGCACACGTGGCGGCCATCCGCTATAATATT
ACCGGATGGCCGCGCCCCCCCGCCTCTCTCGCTACGGCCCGGCCCATTCGTAGCGCATTGTCGCATTCGTTGTGGTCCCAAATGGATAAGGACCAATTATGAGTGTTACTGAAAGTCTAGATATTTAAGCAACTTGGTCGCTAAGTTGATATAAAGCGACAAGCGTGATGTAACCCGTCCGCTTTATTTCAGAATGCCTAAGCGGGACGCCCCATGGCGATTAATGGCGGGAACGTCCAAAGTTAGCCGCGGTGTCAGTTCATCCCCACGTGGTGGCATGGCGTTAATGAGTCCGATCGTGCGTAAGTTCAACAAGACCGCGGCTTGGGTTAATAGGCCCATGTACAAGAAGCCCAGAATATACAAGGTGCTCAGGACACCTGATGTGCCGTATGGCTGTGAGGGGCCTTGTAAGGTCCAGTCATACGAGTCCCGCCATGATGTATCGCATTCGGGTAAGGTAATTTGTATATCCGATGTGACACGGGGTAGTGGTATCACTCACCGTGTTGGTAAGCGTTTCTGCATAAAGTCTGTGTACATACTGGGGAAAATCTGGATGGATGATAACATCAAGCTTAAGAACCACACGAATAGTGTTATGTTCTGGTTGGTTAGGGACAGAAGACCGAACGGTACACCTATGGATTTCGGACATCTATTCAACATGTTCGATAACGAGCCGAGCACTGCTACGATTAAGAACGATCTTCGTGATCGTTTTCAAGTTATGCATAGGTTCTATGCCAAGGTGACAGGTGGTCAGTATGCCAGCAATGAACAGGCGTTAGTGAAGAGATTTTGGAAGGTCAACAATCACGTTGTGTATAACAACCAAGAAGCCGCTAGATACGAGAATCATACGGAGAACGCCCTCCTATTGTATATGGCGTGTACTCATGCATCGAATCCTGTATATGCAACCCTAAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAATAAAGTTTATATTTTATTGAATGATTCTCGAGTACATGATTTACATACACCCTATCTGTTGCGAAACGAACAGCTCTAATTACAAGATTAATGGAGATAACTCCGACCTGATCTAAATACATATTGACTAAGTATGTAAATCTACTTAAATAAGTCCTCCCAGAAGCTGTCAGAGATGTCGTCCAGACTTGGAAGTTGAGGAAGCATTTGTGGAGATCCAATGCTTTCCTCAGGTTGTGGTTGAACCTGATCTGGACGTGGTACACCCTCGTGTTGGTGTACATTAGATCCTCCACGTTGATGATCTTGAAATAAAGGGGATTTGGAACTTCCCAGATAAACACGCCATTCTGTGCCTGAGGTGCAGTGATGGATTCCCCTGTGCGTGTATCCATGACCGTAGCAATCGATGTGTTGATATATGGTACAGCCGCACACCAGATCGATTCGACGTCGTCTAATCGCCCTCTTCTTGGCGGCTCTGTGTCTCGGTTTGATAGAGGGCGGAGTTGAGGAAGACGAATTTTGCATTATGGAGAGTCCAATTTTTGAGTGCGGCGTTTTCCTCTTTCTCGAGGAAATCTTTATAGCTGGACCCTTCGCCTGGATTGCACAGCACGATTGAAGGAACTCCACCTTTAATTTGAACTGGCTTTCCGTATTTGCAATTTGACTGCCAGTCCCTTTGGGCCCCAAGGAGTTCCTTCCAGTGCTTCATTTTTAGATATTGGGGAGTGATATCATCAATGACGTTATAATCAACGTCGTTACAATAAACTCGTGGATTAAAGTCTAAATGACCGCTAAGATAATTGTGAGACCCTAAGGCACGAGCCCACAATGTCTTCCCCGTTCGACTATGACCCTCGATAATCAAACTAATAGGTCTCACAGGCCGCGCAGCGGCAACTCTCCCAAAATAATCATCGGCCCACTCTTGCATCTCCTCTGGTACGTTAGTGAATGAGGAGAGTTGAAACGGAGGAACAAACGGTTCTGGAGCCTTTTGAAAAATACGTTCTAAATTGGAACGGATATTGTGGTGTTGAAGGACGAAGTCTTTGGGTTGTTCCTCCTTTAATATATTGAGGGCCTCCAAGATTGATCCTGAATTGAGGACCTTGGCATACGTGTCGTTGGCAGATTGCTTACCTCCTCTAGCAGATCTGCCGTCGATTTGGAAAACTCCATGATCAATGAAGTCTCCGTCTTTCTCCACATAGGTTTTAACGTCTGAGGAGCTCTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTAGTTGAGGAGACGAGATCGAAGAACCTGTTGTTCTTGCAGTTGTATTTTCCCTCGAATTGAATGAGCACATGGAGGTGAGGTTGCCCATCTTCGTGTAATTCTCTTGACACACGAATGAATTTTTTATTTGTTGGGGTTTCCAGACCTAGCAATTGGGAAAGTGCCTCTTCTTTGGATAAGGAACATTTGGGATAAGTTAGGAAAAAATTCTTACTATTTACTCTAAAACGACGTGGTTCTGATGGCATTTTTGTAATAAGAAGGTTGGACACCGATTGGGGTCTCTTCAAACTTGCTCTGGCAATTGGGGTCTGGGGTCTTACTTATACTAGAACCCCCAATAGAACTTCCAATCTCCATCGCACACGTGGCGGCCATCCGCTATAATATT
Gene Information
|
NCBI Accession
|
YP_009547928.1
|
|
Location
|
516-1286 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTATGTTAGTAGAAATAAACGTGGTTGGACGTCCAATTATCGTCGGAATACGTCGCGAAGGACGACATTTAAGCGCATCTACTATGCGCCACGCGTCGATGGGAAACGTCGAAGTAGTAAGACCAACAAGGTTCAAGAAGAAGGCAAAATTTCGAATCAGGTGATGCACGAGAATCAATATGGGCCTGACTTCGTTTTGATGCATAATACCGCTATATCGACGTACATAACTTATCCTTCACTGAGTAAAACTCAACCGTGTCGTTCAAGAGCATATATTAAGCTTCATCGTCTAAGTTTCAAAGGGACGGTTAGGATTGAAACTGCCCAAGCAGACGTGAACATGACTAGTTCAAATCCAAAGATCGAAGGAGTATTCACATTAGTTATTGTCGTCGATCGCAAACCGCATATTAATTCAACTGGGAGTCTTCACACATTTGATGAACTATTCGGTGCAAGGATTAATAGTCATGGGAATTTGTCCATAAATTCTTCTCTGAAGGAACGATTTTATATACGACATGTGTTTAAGCGTGTACTATCAACTGAGAATGATAGTGTGATGGTGGATATAGAAGGAACGACATCGTTTTCTAATAAGCGTTTTAACTGCTGGGCAAGTTTTAGGGACGTAGATCATGATTCATGTAATGGCGTATATGCGAACATAAGTAAAAACGCCTTATTAGTTTATTATTGCTGGATGTCTGACACGGCATCTCAAGCATCGTCATTTGTGTCATTTGATCTAGATTATGTTGGTTAA |
|
Protein Sequence
|
MYVSRNKRGWTSNYRRNTSRRTTFKRIYYAPRVDGKRRSSKTNKVQEEGKISNQVMHENQYGPDFVLMHNTAISTYITYPSLSKTQPCRSRAYIKLHRLSFKGTVRIETAQADVNMTSSNPKIEGVFTLVIVVDRKPHINSTGSLHTFDELFGARINSHGNLSINSSLKERFYIRHVFKRVLSTENDSVMVDIEGTTSFSNKRFNCWASFRDVDHDSCNGVYANISKNALLVYYCWMSDTASQASSFVSFDLDYVG |
|
NCBI Accession
|
YP_009547929.1
|
|
Location
|
1340-2221 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGAATCTCAATTAGTAATTCCTCCTAACGCTTTTAATTATATCGAATCCCAACGAGATGAGTATCAGCTGTCTCACGACCTAACAGAAATTGTGTTGCAATTTCCATCTACAGCGTCTCAAATTACTGCAAGACTCAGCCGGAGCTGCATGAAAATAGATCACTGTGTTATCGAATACCGGCAACAAGTGCCAATCAACGCCACTGGCTCGGTCATAGTGGAAATTCACGACAAGCGAATGAATGACAACGAATCATTACAAGCCTCGTGGACATTTCCAATTCGATGCAACATTGATCTGCATTATTTCTCGTCGTCATTCTTCTCTCTTAAAGACCCAATTCCTTGGAAGTTATATTACAAAGTCTCTGACACTAATGTTCATCAAAGAACACATTTCGCCAAATTCAAGGGAAAATTGAAACTGTCGACGGCTAAACACTCAGTGGATATCCCTTTCAAGGCACCAACGGTGAAGATCTTGTCGAAACAATTCACAGACAAAGACGTCGACTTTTCCCATGTGGCTTATGGGAATTGGGAAAGAAAATTAATCAGGAACGTTTCCACCTCCACAATAGGCCTAAACGGCCCAATCGAAATTAAGCCCGGTGAGTCATGGGCTTCAAGGAGTTCTTTAGGCCCAAACAATTCATATCCTGACTCGGAGGTGGGAAACGAACTACATCCATATAAGCAACTAAACAAATTGGGCTCTACAATATTAGATCCAGGCGACTCGGCATCAATTATTGGGGCCCAGAGGGCACAATCCAACATCACTTTGTCATTAGCCCAAATTAACGATATCGTTCGATCCACAGTCCAAGAGTGCATTAACCTGAACTGTACTCCATCTGAGCCCAAATCGTTGAAGTAA |
|
Protein Sequence
|
MESQLVIPPNAFNYIESQRDEYQLSHDLTEIVLQFPSTASQITARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMNDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYKVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFKAPTVKILSKQFTDKDVDFSHVAYGNWERKLIRNVSTSTIGLNGPIEIKPGESWASRSSLGPNNSYPDSEVGNELHPYKQLNKLGSTILDPGDSASIIGAQRAQSNITLSLAQINDIVRSTVQECINLNCTPSEPKSLK |
|
NCBI Accession
|
YP_009508389.1
|
|
Location
|
194-967 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGGGACGCCCCATGGCGATTAATGGCGGGAACGTCCAAAGTTAGCCGCGGTGTCAGTTCATCCCCACGTGGTGGCATGGCGTTAATGAGTCCGATCGTGCGTAAGTTCAACAAGACCGCGGCTTGGGTTAATAGGCCCATGTACAAGAAGCCCAGAATATACAAGGTGCTCAGGACACCTGATGTGCCGTATGGCTGTGAGGGGCCTTGTAAGGTCCAGTCATACGAGTCCCGCCATGATGTATCGCATTCGGGTAAGGTAATTTGTATATCCGATGTGACACGGGGTAGTGGTATCACTCACCGTGTTGGTAAGCGTTTCTGCATAAAGTCTGTGTACATACTGGGGAAAATCTGGATGGATGATAACATCAAGCTTAAGAACCACACGAATAGTGTTATGTTCTGGTTGGTTAGGGACAGAAGACCGAACGGTACACCTATGGATTTCGGACATCTATTCAACATGTTCGATAACGAGCCGAGCACTGCTACGATTAAGAACGATCTTCGTGATCGTTTTCAAGTTATGCATAGGTTCTATGCCAAGGTGACAGGTGGTCAGTATGCCAGCAATGAACAGGCGTTAGTGAAGAGATTTTGGAAGGTCAACAATCACGTTGTGTATAACAACCAAGAAGCCGCTAGATACGAGAATCATACGGAGAACGCCCTCCTATTGTATATGGCGTGTACTCATGCATCGAATCCTGTATATGCAACCCTAAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAA |
|
Protein Sequence
|
MPKRDAPWRLMAGTSKVSRGVSSSPRGGMALMSPIVRKFNKTAAWVNRPMYKKPRIYKVLRTPDVPYGCEGPCKVQSYESRHDVSHSGKVICISDVTRGSGITHRVGKRFCIKSVYILGKIWMDDNIKLKNHTNSVMFWLVRDRRPNGTPMDFGHLFNMFDNEPSTATIKNDLRDRFQVMHRFYAKVTGGQYASNEQALVKRFWKVNNHVVYNNQEAARYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_009508390.1
|
|
Location
|
964-1362 |
|
Protein Name
|
replication-enhancer protein |
|
Coding Region
|
ATGGATACACGCACAGGGGAATCCATCACTGCACCTCAGGCACAGAATGGCGTGTTTATCTGGGAAGTTCCAAATCCCCTTTATTTCAAGATCATCAACGTGGAGGATCTAATGTACACCAACACGAGGGTGTACCACGTCCAGATCAGGTTCAACCACAACCTGAGGAAAGCATTGGATCTCCACAAATGCTTCCTCAACTTCCAAGTCTGGACGACATCTCTGACAGCTTCTGGGAGGACTTATTTAAGTAGATTTACATACTTAGTCAATATGTATTTAGATCAGGTCGGAGTTATCTCCATTAATCTTGTAATTAGAGCTGTTCGTTTCGCAACAGATAGGGTGTATGTAAATCATGTACTCGAGAATCATTCAATAAAATATAAACTTTATTAA |
|
Protein Sequence
|
MDTRTGESITAPQAQNGVFIWEVPNPLYFKIINVEDLMYTNTRVYHVQIRFNHNLRKALDLHKCFLNFQVWTTSLTASGRTYLSRFTYLVNMYLDQVGVISINLVIRAVRFATDRVYVNHVLENHSIKYKLY |
|
NCBI Accession
|
YP_009508391.1
|
|
Location
|
1109-1498 |
|
Protein Name
|
transactivating protein |
|
Coding Region
|
ATGCAAAATTCGTCTTCCTCAACTCCGCCCTCTATCAAACCGAGACACAGAGCCGCCAAGAAGAGGGCGATTAGACGACGTCGAATCGATCTGGTGTGCGGCTGTACCATATATCAACACATCGATTGCTACGGTCATGGATACACGCACAGGGGAATCCATCACTGCACCTCAGGCACAGAATGGCGTGTTTATCTGGGAAGTTCCAAATCCCCTTTATTTCAAGATCATCAACGTGGAGGATCTAATGTACACCAACACGAGGGTGTACCACGTCCAGATCAGGTTCAACCACAACCTGAGGAAAGCATTGGATCTCCACAAATGCTTCCTCAACTTCCAAGTCTGGACGACATCTCTGACAGCTTCTGGGAGGACTTATTTAAGTAG |
|
Protein Sequence
|
MQNSSSSTPPSIKPRHRAAKKRAIRRRRIDLVCGCTIYQHIDCYGHGYTHRGIHHCTSGTEWRVYLGSSKSPLFQDHQRGGSNVHQHEGVPRPDQVQPQPEESIGSPQMLPQLPSLDDISDSFWEDLFK |
|
NCBI Accession
|
YP_009508392.1
|
|
Location
|
1425-2498 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCATCAGAACCACGTCGTTTTAGAGTAAATAGTAAGAATTTTTTCCTAACTTATCCCAAATGTTCCTTATCCAAAGAAGAGGCACTTTCCCAATTGCTAGGTCTGGAAACCCCAACAAATAAAAAATTCATTCGTGTGTCAAGAGAATTACACGAAGATGGGCAACCTCACCTCCATGTGCTCATTCAATTCGAGGGAAAATACAACTGCAAGAACAACAGGTTCTTCGATCTCGTCTCCTCAACTAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAGAGCTCCTCAGACGTTAAAACCTATGTGGAGAAAGACGGAGACTTCATTGATCATGGAGTTTTCCAAATCGACGGCAGATCTGCTAGAGGAGGTAAGCAATCTGCCAACGACACGTATGCCAAGGTCCTCAATTCAGGATCAATCTTGGAGGCCCTCAATATATTAAAGGAGGAACAACCCAAAGACTTCGTCCTTCAACACCACAATATCCGTTCCAATTTAGAACGTATTTTTCAAAAGGCTCCAGAACCGTTTGTTCCTCCGTTTCAACTCTCCTCATTCACTAACGTACCAGAGGAGATGCAAGAGTGGGCCGATGATTATTTTGGGAGAGTTGCCGCTGCGCGGCCTGTGAGACCTATTAGTTTGATTATCGAGGGTCATAGTCGAACGGGGAAGACATTGTGGGCTCGTGCCTTAGGGTCTCACAATTATCTTAGCGGTCATTTAGACTTTAATCCACGAGTTTATTGTAACGACGTTGATTATAACGTCATTGATGATATCACTCCCCAATATCTAAAAATGAAGCACTGGAAGGAACTCCTTGGGGCCCAAAGGGACTGGCAGTCAAATTGCAAATACGGAAAGCCAGTTCAAATTAAAGGTGGAGTTCCTTCAATCGTGCTGTGCAATCCAGGCGAAGGGTCCAGCTATAAAGATTTCCTCGAGAAAGAGGAAAACGCCGCACTCAAAAATTGGACTCTCCATAATGCAAAATTCGTCTTCCTCAACTCCGCCCTCTATCAAACCGAGACACAGAGCCGCCAAGAAGAGGGCGATTAG |
|
Protein Sequence
|
MPSEPRRFRVNSKNFFLTYPKCSLSKEEALSQLLGLETPTNKKFIRVSRELHEDGQPHLHVLIQFEGKYNCKNNRFFDLVSSTRSAHFHPNIQGAKSSSDVKTYVEKDGDFIDHGVFQIDGRSARGGKQSANDTYAKVLNSGSILEALNILKEEQPKDFVLQHHNIRSNLERIFQKAPEPFVPPFQLSSFTNVPEEMQEWADDYFGRVAAARPVRPISLIIEGHSRTGKTLWARALGSHNYLSGHLDFNPRVYCNDVDYNVIDDITPQYLKMKHWKELLGAQRDWQSNCKYGKPVQIKGGVPSIVLCNPGEGSSYKDFLEKEENAALKNWTLHNAKFVFLNSALYQTETQSRQEEGD |
|
NCBI Accession
|
YP_009508393.1
|
|
Location
|
2045-2338 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGCAACCTCACCTCCATGTGCTCATTCAATTCGAGGGAAAATACAACTGCAAGAACAACAGGTTCTTCGATCTCGTCTCCTCAACTAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAGAGCTCCTCAGACGTTAAAACCTATGTGGAGAAAGACGGAGACTTCATTGATCATGGAGTTTTCCAAATCGACGGCAGATCTGCTAGAGGAGGTAAGCAATCTGCCAACGACACGTATGCCAAGGTCCTCAATTCAGGATCAATCTTGGAGGCCCTCAATATATTAA |
|
Protein Sequence
|
MGNLTSMCSFNSRENTTARTTGSSISSPQLGQHISIRTFRELRAPQTLKPMWRKTETSLIMEFSKSTADLLEEVSNLPTTRMPRSSIQDQSWRPSIY |