Clerodendrum golden mosaic Jiangsu virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002986365.1 |
| Isolate |
China:Jiangsu province |
| Release date |
2018/8/26 |
| Submitter |
Li,J., Zhou,X., Zhou,X.P. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
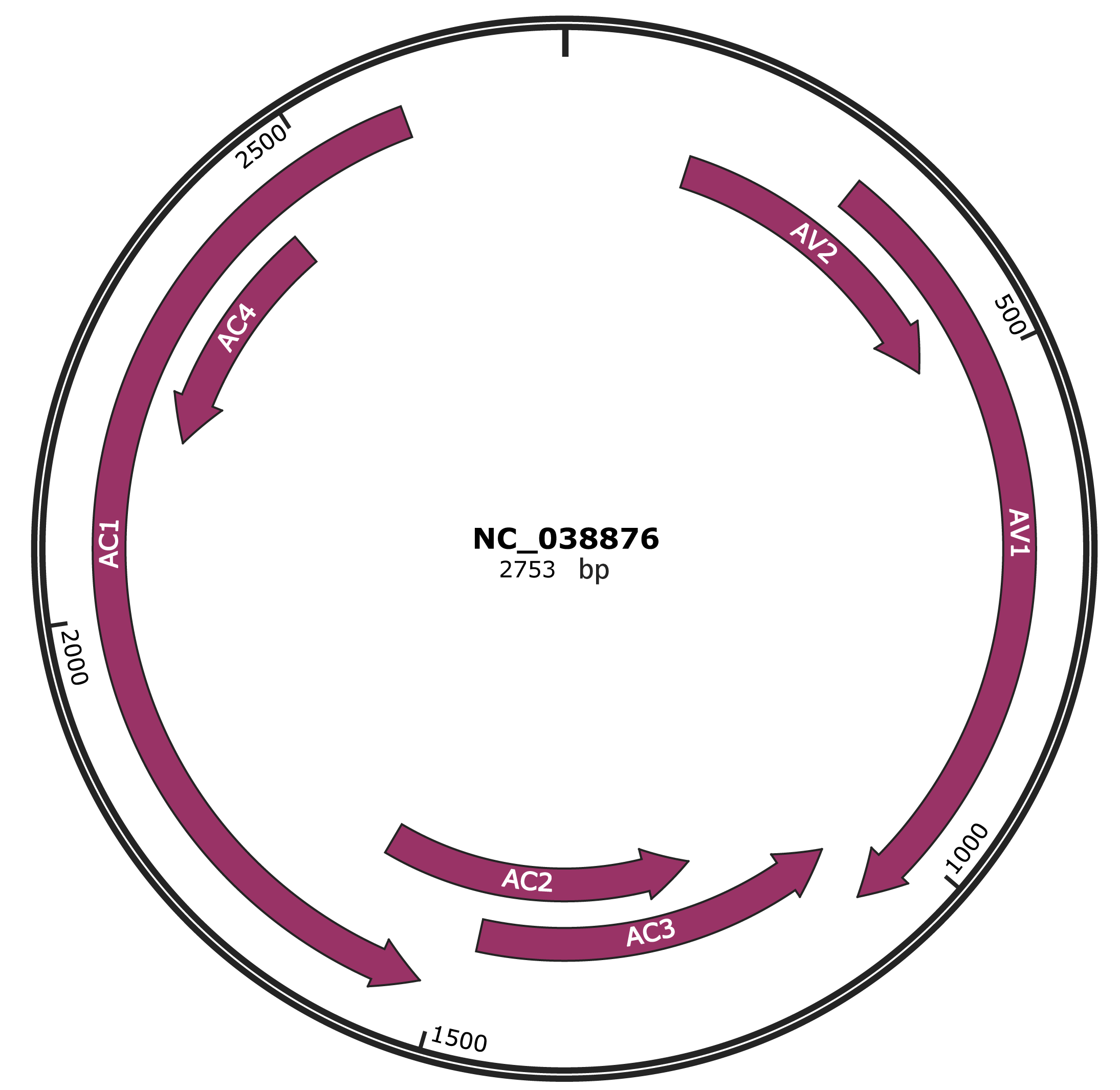
JBrowse
Genome
ACCGGAAGGCCCGCGCCCCCCTTTTTTGTGGGCCCCGCGCACGTTCTTTTTGTCGTCCAATAGAATTGGGCCCTCAAAGCTTAGTTAAGTAATTTTGTCCTATTAATACGTGGTCTTCCTCTTTCCACGTATTAAGATGTGGGACCCACTCTTGAATGAGTTTCCCGAAACCGTACACGGTTTTAGGTGTATGCTCGCGATAAAATACTTGCAGCTCGTAGAAAATACGTATTCTCCGGATACGTTGGGGTACGATCTTATACGCGATCTTATACTTGTGATTCGTGCGAAGAATTATGTCGAAGCGTCCAGCAGATATAGTCATTTCCACGCCCGCCTCCAAGGTGCGTCGCCGTCTGAATTTCGACAGCCCTTATTCCAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACAAACAGAAGGAGATCATGGGCTCAGCGGCCCATGTACCGGAAGCCCAAACTGTACAGAATGTACAGAAGCCCTGATGTTCCAAAGGGATGTGAAGGCCCATGTAAGGTTCAATCATTTGAACAGCGACATGATATAGCCCATACTGGGAAGGTTATTTGTATTTCCGATGTTACTAGGGGAGGTGGTATTACCCATAGGGTTGGTAAGAGATTTTGTGTTAAGTCCGTTTATGTCTTAGGTAAAGTGTGGATGGATGAAAATATTAAGGTTAAAAACCACACAAATACAGTTATGTTTTTTGTAGTTAGGGATCGACGTCCGTATGGTACTCCACAAGATTTTGGGCAGGTGTTTAATATGTATGATAATGAGCCCAGTACTGCTACCGTGAAGAACGATATGAGGGATCGTTTCCAAGTATTGAGGAAGTTTTCGTCGACTGTTACTGGTGGTCAATATGCGTCCAAGGAACAAGCTTTAGTGAGGAAGTTTATGAAGATAAATAATCATGTTACGTACAATCATCAGGAAGCCGCTAAGTATGAGAATCATACGGAGAATGCTGTTTTATTGTATATGGCATGTACTCATGCCTCTAATCCCGTGTATGCTACTTTGAAAATTCGGATCTATTTCTACGATTCGACAATGAATTAATAAAATATAAATTTTATATCATGTGCTTCAATTACATCAATTGTTCCCTCTATTACATTGGTTAATACATGGGTAAATGCCCTAATACAATTATTGATACTAATCACTCCTAATCTATCTAAATACTTAATTACTTGGGTTTTAAATACCCTTAAGAAATGCGATGTCTGAGGATGTAAAGCTGTGTAGATCTTCAAGTTGAGAAAACACTTGTGAATCCCCAACTCCTTCCTTAGGTTGTGGTTGAATCGGACTTGAATTTGTATGATGTCGTGGTTCATGTTGAACGGTCTCTTGTGGTGGTTTAGGATCTTGAAATAGAGGGGATTGTCTATAACCCATGTATGTACGCCATTCGTCGCTTGAGCTGCAGTGATGTACTCCCCTGTGCGTGAATCCATGGTGTTCGCAGTCCACTGATTTGTATATGGAACACCCGCAAGCTAGGTCAATTCTCTTCCTGCGAATTGGTCTCTTGGCCTGCTTGTGAATCACTTTGATTGGAGTATAATGGCTCCGTGAGGGTGACGAATGTTGCATTTTTTACTGCCCAGTCTCTTAAAGCTCTATTTTTCTCTTCATCCAAGAATTCTTTATATGATGAGTTTGGTCCTGGATTGCAGAGGAAGATAGTGGGAATACCACCTTTAATTTGAATTGGTTTCCCGTACTTTGTGTTTGACTGCCAGTCCCTCTGGGCTCCCATGAATTCCTTAAAGTGCTTTAGATAGTGGGGATCAACGTCATCAATGACGTTGTACCACGCGTCATTTGAATATACCTTGGGGCTCAAGTCTAGGTGTCCACACAAATAATTGTGTGGACCCAGAGACCTGGCCCACATAGTCTTGCCAGTACGACTATCCCCCTTTATCACAATACTATTCGGTCTCCATGGCCGCGCAGCGGCATTCCTAACATTCTCGGACACCCACTCCTCAAGTTCCTCAGGAACTTGGTTAAATGAAGAAGAAAGAAAAGGAGAAATATAAACCTCCAAGGGAGGTGCAAAAATCCTATCTAAATTACTATTTAAATTATGAAATTGAAAAATATAATCTTTTGGGAGTTTTTCCCTTATTATAGCCATGGCAGCCTCTTTGGAACCTGCGTTTAATGCTTCCGCACATGCGTCGTTAGCATTCTGGCAGCCTCCTCTAGCACTTCTGCCGTCGACTTGAAATTCTCCCCATTCGAGTGTATCTCCATCCTTGTCGATATAGGACTTGATGTCGGAGCTGGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTGGTTGGGGATACCAGGTCGAAGAATCTGTTATTTGTGCAGTTGTATTTTCCCTCGAATTGCACAAGCACATGGAGATGAGGGCTCCCATCTTCGTGTAATTCTTTGCAGATTTTAATGAATTTTTTATTTGTGGGAGTTTTTAGGTTTTGTAATTGGGAAAGTGCTTCCTCTTTGGTGAGAGAGCAGTGTGGATATGTTAGAAAATAGTTTTTGGCTTTAATAGAAAATCTACCTGCACGAGGCATTTTGGAATTGGGGGGCACTCAAAGTCTGAGGAATCGGGGGAACTGGGGGGCAATATATAGTGCCCCCCAAATGGCATAATGGTAATTTGGTAAAGATACTTTCTTTAATTCAAAATTCAAAATTCGAATAGTAGGCGGGCCTTCCTTCTAATATT
Gene Information
|
NCBI Accession
|
YP_009508113.1
|
|
Location
|
137-487 |
|
Gene Name
|
AV2 |
|
Protein Name
|
AV2 protein |
|
Coding Region
|
ATGTGGGACCCACTCTTGAATGAGTTTCCCGAAACCGTACACGGTTTTAGGTGTATGCTCGCGATAAAATACTTGCAGCTCGTAGAAAATACGTATTCTCCGGATACGTTGGGGTACGATCTTATACGCGATCTTATACTTGTGATTCGTGCGAAGAATTATGTCGAAGCGTCCAGCAGATATAGTCATTTCCACGCCCGCCTCCAAGGTGCGTCGCCGTCTGAATTTCGACAGCCCTTATTCCAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACAAACAGAAGGAGATCATGGGCTCAGCGGCCCATGTACCGGAAGCCCAAACTGTACAGAATGTACAGAAGCCCTGA |
|
Protein Sequence
|
MWDPLLNEFPETVHGFRCMLAIKYLQLVENTYSPDTLGYDLIRDLILVIRAKNYVEASSRYSHFHARLQGASPSEFRQPLFQPCCCPHCPRHKQKEIMGSAAHVPEAQTVQNVQKP |
|
NCBI Accession
|
YP_009508114.1
|
|
Location
|
297-1070 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGTCCAGCAGATATAGTCATTTCCACGCCCGCCTCCAAGGTGCGTCGCCGTCTGAATTTCGACAGCCCTTATTCCAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACAAACAGAAGGAGATCATGGGCTCAGCGGCCCATGTACCGGAAGCCCAAACTGTACAGAATGTACAGAAGCCCTGATGTTCCAAAGGGATGTGAAGGCCCATGTAAGGTTCAATCATTTGAACAGCGACATGATATAGCCCATACTGGGAAGGTTATTTGTATTTCCGATGTTACTAGGGGAGGTGGTATTACCCATAGGGTTGGTAAGAGATTTTGTGTTAAGTCCGTTTATGTCTTAGGTAAAGTGTGGATGGATGAAAATATTAAGGTTAAAAACCACACAAATACAGTTATGTTTTTTGTAGTTAGGGATCGACGTCCGTATGGTACTCCACAAGATTTTGGGCAGGTGTTTAATATGTATGATAATGAGCCCAGTACTGCTACCGTGAAGAACGATATGAGGGATCGTTTCCAAGTATTGAGGAAGTTTTCGTCGACTGTTACTGGTGGTCAATATGCGTCCAAGGAACAAGCTTTAGTGAGGAAGTTTATGAAGATAAATAATCATGTTACGTACAATCATCAGGAAGCCGCTAAGTATGAGAATCATACGGAGAATGCTGTTTTATTGTATATGGCATGTACTCATGCCTCTAATCCCGTGTATGCTACTTTGAAAATTCGGATCTATTTCTACGATTCGACAATGAATTAA |
|
Protein Sequence
|
MSKRPADIVISTPASKVRRRLNFDSPYSSRAAAPTVLVTNRRRSWAQRPMYRKPKLYRMYRSPDVPKGCEGPCKVQSFEQRHDIAHTGKVICISDVTRGGGITHRVGKRFCVKSVYVLGKVWMDENIKVKNHTNTVMFFVVRDRRPYGTPQDFGQVFNMYDNEPSTATVKNDMRDRFQVLRKFSSTVTGGQYASKEQALVRKFMKINNHVTYNHQEAAKYENHTENAVLLYMACTHASNPVYATLKIRIYFYDSTMN |
|
NCBI Accession
|
YP_009508115.1
|
|
Location
|
1067-1471 |
|
Gene Name
|
AC3 |
|
Protein Name
|
AC3 protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAGTACATCACTGCAGCTCAAGCGACGAATGGCGTACATACATGGGTTATAGACAATCCCCTCTATTTCAAGATCCTAAACCACCACAAGAGACCGTTCAACATGAACCACGACATCATACAAATTCAAGTCCGATTCAACCACAACCTAAGGAAGGAGTTGGGGATTCACAAGTGTTTTCTCAACTTGAAGATCTACACAGCTTTACATCCTCAGACATCGCATTTCTTAAGGGTATTTAAAACCCAAGTAATTAAGTATTTAGATAGATTAGGAGTGATTAGTATCAATAATTGTATTAGGGCATTTACCCATGTATTAACCAATGTAATAGAGGGAACAATTGATGTAATTGAAGCACATGATATAAAATTTATATTTTATTAA |
|
Protein Sequence
|
MDSRTGEYITAAQATNGVHTWVIDNPLYFKILNHHKRPFNMNHDIIQIQVRFNHNLRKELGIHKCFLNLKIYTALHPQTSHFLRVFKTQVIKYLDRLGVISINNCIRAFTHVLTNVIEGTIDVIEAHDIKFIFY |
|
NCBI Accession
|
YP_009508116.1
|
|
Location
|
1212-1610 |
|
Gene Name
|
AC2 |
|
Protein Name
|
AC2 protein |
|
Coding Region
|
ATGCAACATTCGTCACCCTCACGGAGCCATTATACTCCAATCAAAGTGATTCACAAGCAGGCCAAGAGACCAATTCGCAGGAAGAGAATTGACCTAGCTTGCGGGTGTTCCATATACAAATCAGTGGACTGCGAACACCATGGATTCACGCACAGGGGAGTACATCACTGCAGCTCAAGCGACGAATGGCGTACATACATGGGTTATAGACAATCCCCTCTATTTCAAGATCCTAAACCACCACAAGAGACCGTTCAACATGAACCACGACATCATACAAATTCAAGTCCGATTCAACCACAACCTAAGGAAGGAGTTGGGGATTCACAAGTGTTTTCTCAACTTGAAGATCTACACAGCTTTACATCCTCAGACATCGCATTTCTTAAGGGTATTTAA |
|
Protein Sequence
|
MQHSSPSRSHYTPIKVIHKQAKRPIRRKRIDLACGCSIYKSVDCEHHGFTHRGVHHCSSSDEWRTYMGYRQSPLFQDPKPPQETVQHEPRHHTNSSPIQPQPKEGVGDSQVFSQLEDLHSFTSSDIAFLKGI |
|
NCBI Accession
|
YP_009508117.1
|
|
Location
|
1519-2598 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication protein |
|
Coding Region
|
ATGCCTCGTGCAGGTAGATTTTCTATTAAAGCCAAAAACTATTTTCTAACATATCCACACTGCTCTCTCACCAAAGAGGAAGCACTTTCCCAATTACAAAACCTAAAAACTCCCACAAATAAAAAATTCATTAAAATCTGCAAAGAATTACACGAAGATGGGAGCCCTCATCTCCATGTGCTTGTGCAATTCGAGGGAAAATACAACTGCACAAATAACAGATTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACATCAAGTCCTATATCGACAAGGATGGAGATACACTCGAATGGGGAGAATTTCAAGTCGACGGCAGAAGTGCTAGAGGAGGCTGCCAGAATGCTAACGACGCATGTGCGGAAGCATTAAACGCAGGTTCCAAAGAGGCTGCCATGGCTATAATAAGGGAAAAACTCCCAAAAGATTATATTTTTCAATTTCATAATTTAAATAGTAATTTAGATAGGATTTTTGCACCTCCCTTGGAGGTTTATATTTCTCCTTTTCTTTCTTCTTCATTTAACCAAGTTCCTGAGGAACTTGAGGAGTGGGTGTCCGAGAATGTTAGGAATGCCGCTGCGCGGCCATGGAGACCGAATAGTATTGTGATAAAGGGGGATAGTCGTACTGGCAAGACTATGTGGGCCAGGTCTCTGGGTCCACACAATTATTTGTGTGGACACCTAGACTTGAGCCCCAAGGTATATTCAAATGACGCGTGGTACAACGTCATTGATGACGTTGATCCCCACTATCTAAAGCACTTTAAGGAATTCATGGGAGCCCAGAGGGACTGGCAGTCAAACACAAAGTACGGGAAACCAATTCAAATTAAAGGTGGTATTCCCACTATCTTCCTCTGCAATCCAGGACCAAACTCATCATATAAAGAATTCTTGGATGAAGAGAAAAATAGAGCTTTAAGAGACTGGGCAGTAAAAAATGCAACATTCGTCACCCTCACGGAGCCATTATACTCCAATCAAAGTGATTCACAAGCAGGCCAAGAGACCAATTCGCAGGAAGAGAATTGA |
|
Protein Sequence
|
MPRAGRFSIKAKNYFLTYPHCSLTKEEALSQLQNLKTPTNKKFIKICKELHEDGSPHLHVLVQFEGKYNCTNNRFFDLVSPTRSAHFHPNIQGAKSSSDIKSYIDKDGDTLEWGEFQVDGRSARGGCQNANDACAEALNAGSKEAAMAIIREKLPKDYIFQFHNLNSNLDRIFAPPLEVYISPFLSSSFNQVPEELEEWVSENVRNAAARPWRPNSIVIKGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPNSSYKEFLDEEKNRALRDWAVKNATFVTLTEPLYSNQSDSQAGQETNSQEEN |
|
NCBI Accession
|
YP_009508118.1
|
|
Location
|
2184-2441 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGAGCCCTCATCTCCATGTGCTTGTGCAATTCGAGGGAAAATACAACTGCACAAATAACAGATTCTTCGACCTGGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACATCAAGTCCTATATCGACAAGGATGGAGATACACTCGAATGGGGAGAATTTCAAGTCGACGGCAGAAGTGCTAGAGGAGGCTGCCAGAATGCTAACGACGCATGTGCGGAAGCATTAA |
|
Protein Sequence
|
MGALISMCLCNSRENTTAQITDSSTWYPQPGQHISIRTFRELNPAPTSSPISTRMEIHSNGENFKSTAEVLEEAARMLTTHVRKH |