Clerodendrum golden mosaic China virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000882255.1 |
| Isolate |
China |
| Release date |
2015/2/22 |
| Submitter |
Yang,C.X., Wu,Z.J., Xie,L.H. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
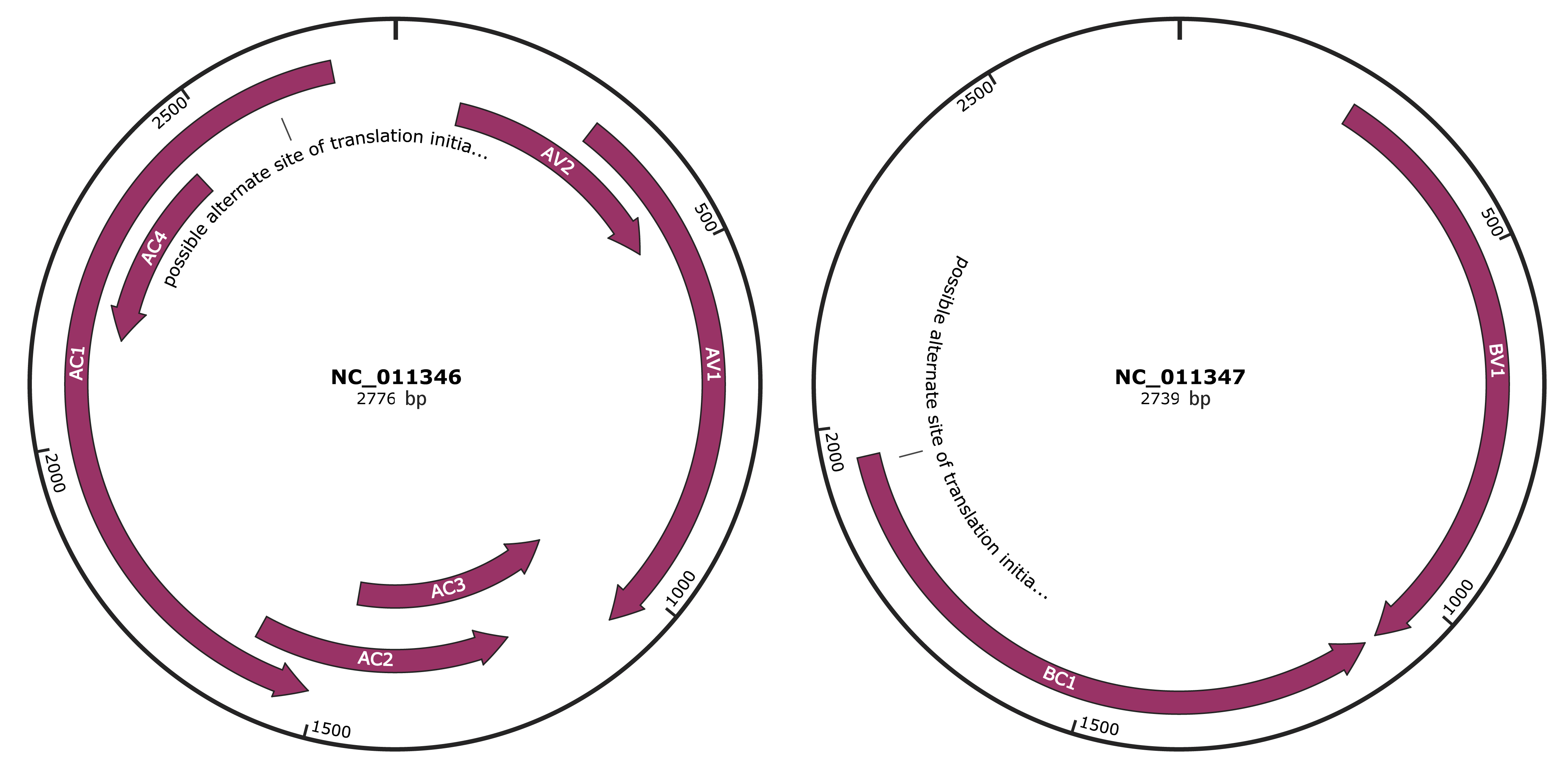
JBrowse
Genome
ACCGGGTGGCCGCGCCCTTTCTTTAAAAAGTGGACCCCACATGAAAAAGCAGCCAATCAGAAGAGCTGCTCCGATCCTAATAGTCAAAAGTTGGCCTATAAATGTTGACTAGTCATACAAGCTTGTCAGACATGTGGGATCCATTGGTTAATGAATTCCCTGAGACTGTACATGGTCTCAGGTGTATGCTAGCTGTGAAATACTTGAAATACGTAGAGAATACATATTCGCCGGATACACTCGGATACGATTTAATTCGTGATCTGATACTTGTTATTCGTGCCAAAAATTATGTCGAAGCGTCCCGGAGATATAATCATTTCCACGCCCGCCTCCAAAGTTCGACGGAGGTTGAACTTCGACAGCCCGTATCAGAGCCGTGTGCCTGTCCTCACTGCCCGAGGCACGCGAAAGCAGCTATGGGCCAACAGGCCCATGTACCGGAAGCCCAGATTATATCGTCTGTTCAGGAGCCCTGATGTTCCTAGAGGCTGTGAAGGCCCATGTAAGGTCCAATCATTCGAGCAGAGGCATGACATAGCCCACACTGGGAAGGTCATTTGTATTTCCGATGTGACACGTGGGAATGGTATCACCCATCGTGTGGGCAAACGTTTTTGTGTTAAGTCCGTTTATGTCTTGGGGAAGGTGTGGATGGATGAGAACATCAAGACTAAGAATCACACCAATACTGTTATGTTCTATGTCGTTAGAGATAGGCGTCCCTTTGGTACTCCGATGGATTTTGGTCAAGTGTTTAATATGTATGACAACGAGCCAAGCACAGCGACTGTCAAGAACGATCTTAGGGATCGGTATCAGGTTTTACGGAAGTTCTACTCGACCGTGACCGGTGGTCAGTATGCAAGTAAGGAGCAGGCGCTTGTGAAGAAATTTATGAGGGTTAATAATCATGTGGTTTATAACCACCAAGAGGCCGCTAAGTATGAGAATCATACGGAGAATGCTTTGTTGTTGTATATGGCATGTACACATGCATCTAATCCCGTGTATGCTACGTTGAAAATACGTATCTATTTCTACGACTCTGTATCAAATTAATAAACATTGAATTTTATTGAGTGTTTTTCGATTACATCCAAAGTACCTGCAATTACATTATTTAGTACATGCGTGACTGTTCTAATTACATTGTTGATCGAAATAACACCTAAATTATTCAAGTACTTGCAACATTCATTCTTAAAGACCCTTAAAAATCTCCCAGTCGGCGGAGTCAAACGTGTCCAGATTCGAAAGGAGAGGAAACATTTGTGAAGTCCCAGTGCTTTCCTCAGGTTGTGGTTGAATTGTATCTGGACGGTGATAATGTCGTGGTTCATGTTGAACGGCCTCGAGTCGTGTTCCGTTATTTTGAAATATAGGGGATTTGGTACCTCCCAAATAAAAACGCCGTTCTCCGCCTGAGTTGCAGTGATGATTTCCCCTGTGCGTGAATCCATGATTGTGGCAGTCGATTGATAGATAATATGAGCAACCGCAATCGAGGTCAACCCTCCGTCGTCGTGTTGGCCTCCTCTTGGAAATCTTGTGTTGGACCTTGATTGGGACTTGAGAAGAGTGGCTCTGTGAGGGAGACGAATTCTGCATTCTTTAATGCCCAATTCTTGAGGGCTGTTTGTTTTTCCTCGTTTAAAAACTCGATGTAGCTGGAGCCTGGACCTGGATTGCAGAGAAAGATAGTGGGAATCCCACCTTTAATTTGAACTGGCTTTCCGTATTTTGTGTTGCTTTGCCAGTCCCTTTGGGCCCCCATGAATTCTTTAAAGTGCTTCAGATAATGCGGATCAACGTCATCAATGACGTTGTACCACGCGTCGTTGCTGTAAACCTTGGGACTCAAGTCTAGGTGACCACATAAATAATTGTGTGGTCCAAGAGATCTGGCCCACACTGTCTTCCCTGTACGACTAACGCCCTCGATAACAATTGATTTAGGTCTCAATGGCCGCGCAGCGGCACTCTTCACATTTTCTGAAACCCATGCCTCGAGTTCCTCGGGAACTCGATTGAAAGAAGAAGATAGAAATGGCGACGTATAAACAGGCACCTCTGGTGCGAAGATCCTATCTAAATTTGAACTTAAATTATGAAACTGTAAAATAAAATCTTTTGGGGCTAATTCCCTAATTACCCTAAGAGCATCCTGCTTACTTCCCGTGTTAAGCGCCTGGGCGTAAGCATCGTTTGCTGATTGTTGACCGCCCCTTGCAGAACGTCCGTCGATCTGAAACTGCCCCCATTCCAGTGTGTCCCCGTCCTTATCAATATATGACTTGACGTCGGAGCTGGATTTAGCTCCCTGTATGTTCGGATGGAAATGTGTTGATCTGGTTGGGGAGACCAGGTCGAACAATCTGTTATTTGTGCAGACGTATTTGCCTTCGAACTGTATAAGCACATGGAGATGAGGGCTTCCATCTTCGTGCAGTTCTCTACAGACCTTAATATATTTCTTATTGACTTGAGTATTTATGCTACGAAGTTGTGAAAGTGCTTCGTCTTTGGTGACGGAGCAATGGGGATAAGTGAGGAAATAATTTTTGGCAGAAATTCTAAAACGACGTGGGGGAGCCATTAAAATTGTCGTTTTGGTATCGGTGACAAAAAACTCTGTGGAATGAATTGGTGACTGGTGTACAATATATACCTTGTCACCATATGGCATATTCGTAATTATCTCTACAACTTTTGAATTTGAATTTGAATTTTGAATTAAATTTCGGCTCCAAAAGCGGCCACCCGTACTAATATT
ACCGGGTGGCCGCGCCCTCCCCTCTTATAGTGGGCCCCCATATGCCACGTGGATTGACTGGTCAAAAAGACATAAAAGCCCCTGTCCCCTGTCGGTGAAATTACCATGAAGCCCTTTAATTTTGAACGAGTTAGTAGTCGACACGTGGCAGTAGAAGTCGTTTATTTTAAAATGCGAGTCTTGTCCTGCACATCTGAAAATATTAATAAAACCCTTCGCCGCCGGGAAACTATCCCTGAACAAAATGCCTGCTCTATCAAATGAGCGTTCCGGCGGATGGTACCGTCTGAGCAATTATCCGACGTCTGCCCGGCGGCGACCTGCCTCCGGTCCCGTTTATTCACCTAGGTTGGGTAGATATATTTCTGGCAAGCCAAGGTCACGTAACCCTGGTATGTCCTATTCCCAACGGAGGCATGGTCGTGTTCGGACTACTCTGTTTAATAGAAATTCCGACAGAGTCCCCATGAAGATTCAGACGATCGAGGAGGTTCAGACTGGTCCCCAGTACGTGATCACCAACAATACCTCGAAGGTGTCATATATAACATACCCTAGCATCTCCCGCAGTGCATTTTGTAGTCGTGTAAACGACTATATCAAGGTCCTTTCCGTGAGTGCCTCTGGCTCCGTTGTTGTGAAGCAGGTCGGCTCGACGCCGGGTGCATCTTCCACTTGCATCAACGGCATATTCACTACCGTCCTTGTGCGTGACATGAGGCCATCTGAATTTTCATCTAGTGATCCCATTGTCCCTTATGGAGAGTTATTTGGGCTCGAGCAAGGATCATGTTCCAATCTACGTGTCCGTGACAATCATGCGGACAGGTTTCGTGTGCTTTGGCAGAAGAAGTCTATTGTTAATACCTCTCTATCGACTTATGTTTTTAAGTTTGACTATAGAGTTCTCATGAGACATTATCCCTTTTGGGTTAGATTCAAAGACATTCCTAGTCTTGAGGCTAGTGGTAGGTATGGAAATATATCGAAAAACGCCCTGGTATTGTACTATGTATGGCTGTGCGATAGCCCTGTAACCGCAGAGGTTCATGTGAAATATGATACAAAGTATTTGGGTTGAATAAAATAAAAATTTTATTAAACAGGCTTTGCATTTGTTGTTACATTATTCGAAGCGATACAAAGTTCGACCGTTTTTTTGATGATGTTTATGACATCATCGTTTACATTTGAGTTCCCTGCACTAATAACATTATTAGTAACTTGTGATGCTGATGGGCCCGGATCTAGTGATGCTGGGTCCAGTCTGTTGAGAGCCCTGTATGGGTAATCCGCAATCGAAGGCCCATCAATTGAGCTTGCAGAGGCCCATGTCTCTCCTGGGCCGATAGTGGGCCGTTGAAATCGGGCAGATGCAGATCGCAGGCCCATGACTGGGTGTCTTGAGAATTGGGCCTGGGCCTGTCCAACAGTCCAGAAATCTATGTGTGTGTTGTTGTAGGCCTTCGAAAGAATATCTATTCTTGGGGACCGGAATTGGATGTCAGAAGATTGTTTTGCCGATGACATCCTGAGCTTGCCCTGGATCCTGCAGAAATGGACCCCATTGATGACATTTGAATTGTCTACCCTGTACATGACCCTCCATGGATTAGGATCCTTTGGAGAAAAATACGAGGACGAGTAGTAGTGAATGTTGCAGTTGCATCCAATCGGAATTGTAAATTCCGCCTGTTTTGAGTCCCCTTCACCCAATCTGGTGTCGTGCATTTCAATGACCACATGTCCGGTCGCGTTTATTGGAACTTGGTTTCTATACTCCAGTATTACGTGATCTATTCGTAGACAACGACCACGGAGTCTTGATAATTGTTGGTCGAGTGTTGAAGGGAACAGCAGAGTCACGTCTGTGAGGTCGTTGGATAGTTGGTATTCAGTTCTATCGGAGGTCGTATAGGCAAGTGTTGAGGTGTGTGTTTCCATTGAACTTACCATGCACTGAACCTATTGATCTGTTGACGTTTGTGGTTTTTAAAAACCATAAACGGTCCGGGTCCCACATATCATTGTCAGAGTACGAAACTTCCAACCGAAGGAACTATCACATACTAACTATTCATTTAATCTTCAAAGGCCGCGCAGCGGCACTTACAATAAATTGTAATATCCAGTTGATTAAAATCGTGTGGAAACCCTATAAATCATTTACTGACAGACATTCTAATCGTCTGTAGATTCCAATTAATGTCTGTAGATTCCATGTCGTTCAACTGAACAGTGGCAGGACATAGAAATAATTAATTTGTTAATTATATATGCTGAACTTAATTAATTTGTTTGAAGATCTCTGAAACGACTATAATTACCAAAGTCCGTGGAACCTAAGTCCCATACAATAAACAAATTAATTAGTAATAATAGCCCTTCTGTAATCCTAATTACCAAAGTCCGTGGATCCTAAAATCCCATAAAATAGAAAATTGAAAAATTTATTATATGAATTTTATTCTGACGTCCGTGGATCCTAAATTACAGCAAATAAATAAATTGTTAAATAGTCGGCAGAGCAGTTGCAAAGAAATTTCTAGAGAGAGAAATATTGTGTGCCCGGGCAATCCATTTGGTGACAACAAACTCTGTGGAATGAATTGGTGACTGGTGTACAATATATACCTTGTCACCATATGGCATATTCGTAATTATCTCTACAACTTTTGAATTTGAATTTGAATTTTGAATTAAATTTCGGCTCCAAAAGCGGCCACCCGTACTAATATT
Gene Information
|
NCBI Accession
|
YP_002268194.1
|
|
Location
|
102-479 |
|
Gene Name
|
AV2 |
|
Protein Name
|
AV2 protein |
|
Coding Region
|
ATGTTGACTAGTCATACAAGCTTGTCAGACATGTGGGATCCATTGGTTAATGAATTCCCTGAGACTGTACATGGTCTCAGGTGTATGCTAGCTGTGAAATACTTGAAATACGTAGAGAATACATATTCGCCGGATACACTCGGATACGATTTAATTCGTGATCTGATACTTGTTATTCGTGCCAAAAATTATGTCGAAGCGTCCCGGAGATATAATCATTTCCACGCCCGCCTCCAAAGTTCGACGGAGGTTGAACTTCGACAGCCCGTATCAGAGCCGTGTGCCTGTCCTCACTGCCCGAGGCACGCGAAAGCAGCTATGGGCCAACAGGCCCATGTACCGGAAGCCCAGATTATATCGTCTGTTCAGGAGCCCTGA |
|
Protein Sequence
|
MLTSHTSLSDMWDPLVNEFPETVHGLRCMLAVKYLKYVENTYSPDTLGYDLIRDLILVIRAKNYVEASRRYNHFHARLQSSTEVELRQPVSEPCACPHCPRHAKAAMGQQAHVPEAQIISSVQEP |
|
NCBI Accession
|
YP_002268195.1
|
|
Location
|
292-1062 |
|
Gene Name
|
AV1 |
|
Protein Name
|
AV1 protein |
|
Coding Region
|
ATGTCGAAGCGTCCCGGAGATATAATCATTTCCACGCCCGCCTCCAAAGTTCGACGGAGGTTGAACTTCGACAGCCCGTATCAGAGCCGTGTGCCTGTCCTCACTGCCCGAGGCACGCGAAAGCAGCTATGGGCCAACAGGCCCATGTACCGGAAGCCCAGATTATATCGTCTGTTCAGGAGCCCTGATGTTCCTAGAGGCTGTGAAGGCCCATGTAAGGTCCAATCATTCGAGCAGAGGCATGACATAGCCCACACTGGGAAGGTCATTTGTATTTCCGATGTGACACGTGGGAATGGTATCACCCATCGTGTGGGCAAACGTTTTTGTGTTAAGTCCGTTTATGTCTTGGGGAAGGTGTGGATGGATGAGAACATCAAGACTAAGAATCACACCAATACTGTTATGTTCTATGTCGTTAGAGATAGGCGTCCCTTTGGTACTCCGATGGATTTTGGTCAAGTGTTTAATATGTATGACAACGAGCCAAGCACAGCGACTGTCAAGAACGATCTTAGGGATCGGTATCAGGTTTTACGGAAGTTCTACTCGACCGTGACCGGTGGTCAGTATGCAAGTAAGGAGCAGGCGCTTGTGAAGAAATTTATGAGGGTTAATAATCATGTGGTTTATAACCACCAAGAGGCCGCTAAGTATGAGAATCATACGGAGAATGCTTTGTTGTTGTATATGGCATGTACACATGCATCTAATCCCGTGTATGCTACGTTGAAAATACGTATCTATTTCTACGACTCTGTATCAAATTAA |
|
Protein Sequence
|
MSKRPGDIIISTPASKVRRRLNFDSPYQSRVPVLTARGTRKQLWANRPMYRKPRLYRLFRSPDVPRGCEGPCKVQSFEQRHDIAHTGKVICISDVTRGNGITHRVGKRFCVKSVYVLGKVWMDENIKTKNHTNTVMFYVVRDRRPFGTPMDFGQVFNMYDNEPSTATVKNDLRDRYQVLRKFYSTVTGGQYASKEQALVKKFMRVNNHVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSVSN |
|
NCBI Accession
|
YP_002268196.1
|
|
Location
|
1059-1463 |
|
Gene Name
|
AC3 |
|
Protein Name
|
AC3 protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAAATCATCACTGCAACTCAGGCGGAGAACGGCGTTTTTATTTGGGAGGTACCAAATCCCCTATATTTCAAAATAACGGAACACGACTCGAGGCCGTTCAACATGAACCACGACATTATCACCGTCCAGATACAATTCAACCACAACCTGAGGAAAGCACTGGGACTTCACAAATGTTTCCTCTCCTTTCGAATCTGGACACGTTTGACTCCGCCGACTGGGAGATTTTTAAGGGTCTTTAAGAATGAATGTTGCAAGTACTTGAATAATTTAGGTGTTATTTCGATCAACAATGTAATTAGAACAGTCACGCATGTACTAAATAATGTAATTGCAGGTACTTTGGATGTAATCGAAAAACACTCAATAAAATTCAATGTTTATTAA |
|
Protein Sequence
|
MDSRTGEIITATQAENGVFIWEVPNPLYFKITEHDSRPFNMNHDIITVQIQFNHNLRKALGLHKCFLSFRIWTRLTPPTGRFLRVFKNECCKYLNNLGVISINNVIRTVTHVLNNVIAGTLDVIEKHSIKFNVY |
|
NCBI Accession
|
YP_002268197.1
|
|
Location
|
1204-1611 |
|
Gene Name
|
AC2 |
|
Protein Name
|
AC2 protein |
|
Coding Region
|
ATGCAGAATTCGTCTCCCTCACAGAGCCACTCTTCTCAAGTCCCAATCAAGGTCCAACACAAGATTTCCAAGAGGAGGCCAACACGACGACGGAGGGTTGACCTCGATTGCGGTTGCTCATATTATCTATCAATCGACTGCCACAATCATGGATTCACGCACAGGGGAAATCATCACTGCAACTCAGGCGGAGAACGGCGTTTTTATTTGGGAGGTACCAAATCCCCTATATTTCAAAATAACGGAACACGACTCGAGGCCGTTCAACATGAACCACGACATTATCACCGTCCAGATACAATTCAACCACAACCTGAGGAAAGCACTGGGACTTCACAAATGTTTCCTCTCCTTTCGAATCTGGACACGTTTGACTCCGCCGACTGGGAGATTTTTAAGGGTCTTTAA |
|
Protein Sequence
|
MQNSSPSQSHSSQVPIKVQHKISKRRPTRRRRVDLDCGCSYYLSIDCHNHGFTHRGNHHCNSGGERRFYLGGTKSPIFQNNGTRLEAVQHEPRHYHRPDTIQPQPEESTGTSQMFPLLSNLDTFDSADWEIFKGL |
|
NCBI Accession
|
YP_002268198.1
|
|
Location
|
1511-2689 |
|
Gene Name
|
AC1 |
|
Protein Name
|
AC1 protein |
|
Coding Region
|
ATGCCATATGGTGACAAGGTATATATTGTACACCAGTCACCAATTCATTCCACAGAGTTTTTTGTCACCGATACCAAAACGACAATTTTAATGGCTCCCCCACGTCGTTTTAGAATTTCTGCCAAAAATTATTTCCTCACTTATCCCCATTGCTCCGTCACCAAAGACGAAGCACTTTCACAACTTCGTAGCATAAATACTCAAGTCAATAAGAAATATATTAAGGTCTGTAGAGAACTGCACGAAGATGGAAGCCCTCATCTCCATGTGCTTATACAGTTCGAAGGCAAATACGTCTGCACAAATAACAGATTGTTCGACCTGGTCTCCCCAACCAGATCAACACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCATATATTGATAAGGACGGGGACACACTGGAATGGGGGCAGTTTCAGATCGACGGACGTTCTGCAAGGGGCGGTCAACAATCAGCAAACGATGCTTACGCCCAGGCGCTTAACACGGGAAGTAAGCAGGATGCTCTTAGGGTAATTAGGGAATTAGCCCCAAAAGATTTTATTTTACAGTTTCATAATTTAAGTTCAAATTTAGATAGGATCTTCGCACCAGAGGTGCCTGTTTATACGTCGCCATTTCTATCTTCTTCTTTCAATCGAGTTCCCGAGGAACTCGAGGCATGGGTTTCAGAAAATGTGAAGAGTGCCGCTGCGCGGCCATTGAGACCTAAATCAATTGTTATCGAGGGCGTTAGTCGTACAGGGAAGACAGTGTGGGCCAGATCTCTTGGACCACACAATTATTTATGTGGTCACCTAGACTTGAGTCCCAAGGTTTACAGCAACGACGCGTGGTACAACGTCATTGATGACGTTGATCCGCATTATCTGAAGCACTTTAAAGAATTCATGGGGGCCCAAAGGGACTGGCAAAGCAACACAAAATACGGAAAGCCAGTTCAAATTAAAGGTGGGATTCCCACTATCTTTCTCTGCAATCCAGGTCCAGGCTCCAGCTACATCGAGTTTTTAAACGAGGAAAAACAAACAGCCCTCAAGAATTGGGCATTAAAGAATGCAGAATTCGTCTCCCTCACAGAGCCACTCTTCTCAAGTCCCAATCAAGGTCCAACACAAGATTTCCAAGAGGAGGCCAACACGACGACGGAGGGTTGA |
|
Protein Sequence
|
MPYGDKVYIVHQSPIHSTEFFVTDTKTTILMAPPRRFRISAKNYFLTYPHCSVTKDEALSQLRSINTQVNKKYIKVCRELHEDGSPHLHVLIQFEGKYVCTNNRLFDLVSPTRSTHFHPNIQGAKSSSDVKSYIDKDGDTLEWGQFQIDGRSARGGQQSANDAYAQALNTGSKQDALRVIRELAPKDFILQFHNLSSNLDRIFAPEVPVYTSPFLSSSFNRVPEELEAWVSENVKSAAARPLRPKSIVIEGVSRTGKTVWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPGSSYIEFLNEEKQTALKNWALKNAEFVSLTEPLFSSPNQGPTQDFQEEANTTTEG |
|
NCBI Accession
|
YP_002268199.1
|
|
Location
|
2152-2442 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGAAGCCCTCATCTCCATGTGCTTATACAGTTCGAAGGCAAATACGTCTGCACAAATAACAGATTGTTCGACCTGGTCTCCCCAACCAGATCAACACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCATATATTGATAAGGACGGGGACACACTGGAATGGGGGCAGTTTCAGATCGACGGACGTTCTGCAAGGGGCGGTCAACAATCAGCAAACGATGCTTACGCCCAGGCGCTTAACACGGGAAGTAAGCAGGATGCTCTTAGGGTAA |
|
Protein Sequence
|
MEALISMCLYSSKANTSAQITDCSTWSPQPDQHISIRTYRELNPAPTSSHILIRTGTHWNGGSFRSTDVLQGAVNNQQTMLTPRRLTREVSRMLLG |
|
NCBI Accession
|
YP_002268200.1
|
|
Location
|
245-1081 |
|
Gene Name
|
BV1 |
|
Protein Name
|
BV1 protein |
|
Coding Region
|
ATGCCTGCTCTATCAAATGAGCGTTCCGGCGGATGGTACCGTCTGAGCAATTATCCGACGTCTGCCCGGCGGCGACCTGCCTCCGGTCCCGTTTATTCACCTAGGTTGGGTAGATATATTTCTGGCAAGCCAAGGTCACGTAACCCTGGTATGTCCTATTCCCAACGGAGGCATGGTCGTGTTCGGACTACTCTGTTTAATAGAAATTCCGACAGAGTCCCCATGAAGATTCAGACGATCGAGGAGGTTCAGACTGGTCCCCAGTACGTGATCACCAACAATACCTCGAAGGTGTCATATATAACATACCCTAGCATCTCCCGCAGTGCATTTTGTAGTCGTGTAAACGACTATATCAAGGTCCTTTCCGTGAGTGCCTCTGGCTCCGTTGTTGTGAAGCAGGTCGGCTCGACGCCGGGTGCATCTTCCACTTGCATCAACGGCATATTCACTACCGTCCTTGTGCGTGACATGAGGCCATCTGAATTTTCATCTAGTGATCCCATTGTCCCTTATGGAGAGTTATTTGGGCTCGAGCAAGGATCATGTTCCAATCTACGTGTCCGTGACAATCATGCGGACAGGTTTCGTGTGCTTTGGCAGAAGAAGTCTATTGTTAATACCTCTCTATCGACTTATGTTTTTAAGTTTGACTATAGAGTTCTCATGAGACATTATCCCTTTTGGGTTAGATTCAAAGACATTCCTAGTCTTGAGGCTAGTGGTAGGTATGGAAATATATCGAAAAACGCCCTGGTATTGTACTATGTATGGCTGTGCGATAGCCCTGTAACCGCAGAGGTTCATGTGAAATATGATACAAAGTATTTGGGTTGA |
|
Protein Sequence
|
MPALSNERSGGWYRLSNYPTSARRRPASGPVYSPRLGRYISGKPRSRNPGMSYSQRRHGRVRTTLFNRNSDRVPMKIQTIEEVQTGPQYVITNNTSKVSYITYPSISRSAFCSRVNDYIKVLSVSASGSVVVKQVGSTPGASSTCINGIFTTVLVRDMRPSEFSSSDPIVPYGELFGLEQGSCSNLRVRDNHADRFRVLWQKKSIVNTSLSTYVFKFDYRVLMRHYPFWVRFKDIPSLEASGRYGNISKNALVLYYVWLCDSPVTAEVHVKYDTKYLG |
|
NCBI Accession
|
YP_002268201.1
|
|
Location
|
1099-1956 |
|
Gene Name
|
BC1 |
|
Protein Name
|
BC1 protein |
|
Coding Region
|
ATGGTAAGTTCAATGGAAACACACACCTCAACACTTGCCTATACGACCTCCGATAGAACTGAATACCAACTATCCAACGACCTCACAGACGTGACTCTGCTGTTCCCTTCAACACTCGACCAACAATTATCAAGACTCCGTGGTCGTTGTCTACGAATAGATCACGTAATACTGGAGTATAGAAACCAAGTTCCAATAAACGCGACCGGACATGTGGTCATTGAAATGCACGACACCAGATTGGGTGAAGGGGACTCAAAACAGGCGGAATTTACAATTCCGATTGGATGCAACTGCAACATTCACTACTACTCGTCCTCGTATTTTTCTCCAAAGGATCCTAATCCATGGAGGGTCATGTACAGGGTAGACAATTCAAATGTCATCAATGGGGTCCATTTCTGCAGGATCCAGGGCAAGCTCAGGATGTCATCGGCAAAACAATCTTCTGACATCCAATTCCGGTCCCCAAGAATAGATATTCTTTCGAAGGCCTACAACAACACACACATAGATTTCTGGACTGTTGGACAGGCCCAGGCCCAATTCTCAAGACACCCAGTCATGGGCCTGCGATCTGCATCTGCCCGATTTCAACGGCCCACTATCGGCCCAGGAGAGACATGGGCCTCTGCAAGCTCAATTGATGGGCCTTCGATTGCGGATTACCCATACAGGGCTCTCAACAGACTGGACCCAGCATCACTAGATCCGGGCCCATCAGCATCACAAGTTACTAATAATGTTATTAGTGCAGGGAACTCAAATGTAAACGATGATGTCATAAACATCATCAAAAAAACGGTCGAACTTTGTATCGCTTCGAATAATGTAACAACAAATGCAAAGCCTGTTTAA |
|
Protein Sequence
|
MVSSMETHTSTLAYTTSDRTEYQLSNDLTDVTLLFPSTLDQQLSRLRGRCLRIDHVILEYRNQVPINATGHVVIEMHDTRLGEGDSKQAEFTIPIGCNCNIHYYSSSYFSPKDPNPWRVMYRVDNSNVINGVHFCRIQGKLRMSSAKQSSDIQFRSPRIDILSKAYNNTHIDFWTVGQAQAQFSRHPVMGLRSASARFQRPTIGPGETWASASSIDGPSIADYPYRALNRLDPASLDPGPSASQVTNNVISAGNSNVNDDVINIIKKTVELCIASNNVTTNAKPV |