Clerodendron golden mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000875165.1 |
| Isolate |
Viet Nam: Sonla |
| Release date |
2015/2/13 |
| Submitter |
Ha,C., Coombs,S., Revill,P., Harding,R., Vu,M., Dale,J., Ha,C.V., Revill,P.A., Harding,R.M., Vu,M.T., Dale,J.L. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
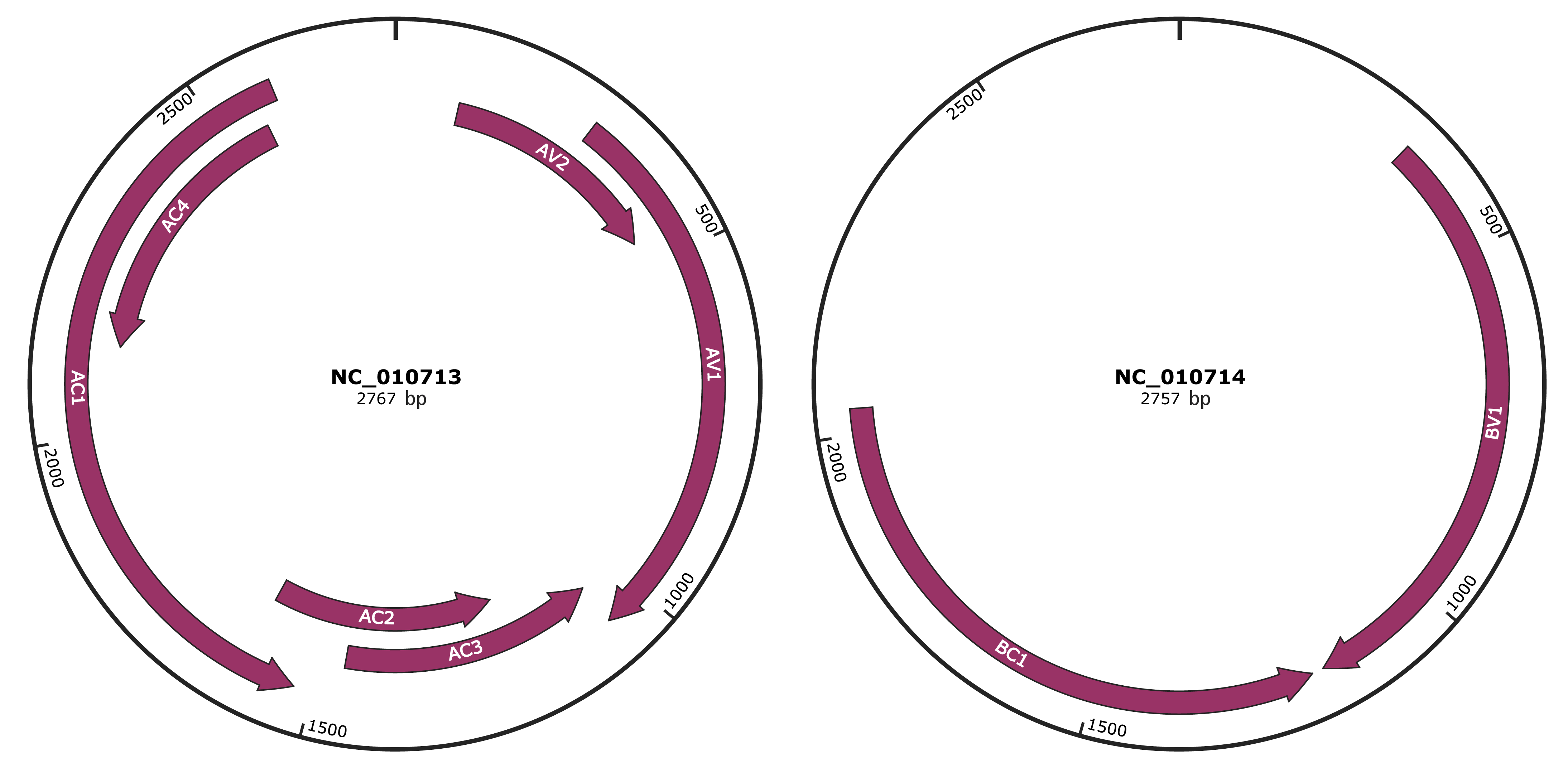
JBrowse
Genome
ACCGGGTGGCCGCGGGGTCTCTTTAAAGTGGGTCCCACCTATTAAAACAACCAATCCGCATAGCTCCTCTGAGCTTGTTAGTCAAAAGGTGGCCTATAAATGTTGACCAGTCATACTGGATTGTCAGACATGTGGGATCCATTGGTGAATGATTTTCCTGAGACCGTACATGGTCTTAGGTGTATGCTAGCTGTCAAATACCTGAAATACGTTGAAAGTACGTATTCCCCTGATACACTCGGATACGATCTAATCCGTGATCTGATACTTGTTGTCCGTGCCAAAAATTATGGCGAAGCGAGCCGGAGATATAATCATTTCCACACCCGCCTCCAAGGTTCGACGGAGGCTGAACTTCGACAGCCCGTATCAGAACCGTGTGCCTGTCCTCACTGCCCGAGGCACACGAAAACAGTTATGGGCCAATCGGCCCATGTACAGGAAGCCCAGGATATTTAAATTATATAGAGGCCTTGATGTGCCTCGTGGATGTGAAGGCCCATGTAAAGTCCAGTCATTTGAGCAACGCCATGATGTGGCCCATGTAGGGAAGGTCATATGTATATCTGATGTTACACGTGGGAATGGTATTACTCATCGCGTTGGTAAACGTTTTTGTATTAAGTCCGTATATGTTTTGGGCAAGGTCTGGATGGATGAAAACATCAAGGTCAAGAATCACACGAATAGTGTAATGTTTTTTGTTGTACGTGATCGAAGGCCGTATGGTACCCCTCAAGAATTTGGCCAAGTATTTAATACTTATGACAACGAGCCAAGTACTGCTACTGTGAAGAATGATCTCAGAGATAGATTTCAAGTGATCAGGAAGTTCTATGCAACTGTGACAGGTGGTCAGTATGCCAGTAGAGAACAGACATTAGTCAGGAGATTCATTAGAGTTAATAATTATGTTGTGTATAATCATCAGGAGGCTGCTAAGTACGAGAATCATACAGAGAATGCATTGTTGTTGTATATGGCATGTACACATGCCTCAAATCCTGTGTATGCTACGTTAAAAATACGAATCTATTTTTATGATTCGGTAACAAATTAATAATATTTGAAATTCACCGAATGGTGGTCGATTACATCCAAAGTACCAGCTATTACATCATACAAAACATGTCTTACAGTCCTAATTACATTGTTAATTGAAATAACCCCTAAACTATCTAAGTACTTCATACATTCATTTTTAAAGACTCTTAAAAATCTCCCAGTCGGTGGATTCAAACGTGTGTAGATCCGAAAGGATAGGAAGCATTTGTGAAGTCCCAGTGCTCTCCGTAGGTTGTGGTTGAATTGTATCTGGATGGTGATGATGTCGTGTGGTCGGAACATTGGCCTGTCGAGGTGGCTGATGATTTTGAAATATAGGGGATTTGGAACCTCCCAGATAAAAACGCCACTCTCCGCTTGAGTTGCAGTGATGATTTCCCCGGTGCGTGAATCCATGGTTGTGGCAATTGATTGATAAGAAATATGAGCAGCCGCACTCCAAATCTATCCTTCGTCGTCTACTACGTTTCTTGGCAATCTTGTGTTGGACCTTGATTGGTACTTGAATAGAGAGGCTCTGTGAGTGTGACGAACTCTGCATTTTTCAAAGCCCAAGTCTTTAGTGCGGATTGCTTTTCTTCATTTAAAAATTGAATATAGCTGGCACCGGGCCCTGGATTGCAGAGAAAGATAGTGGGAATCCCACCTTTAATTTGAACTGGCTTTCCGTATTTTGTATTGCTTTGCCAGTCTCTTTGGGCCCCCATGAATTCCTTAAAGTGCTTTAAATAGTGGGGGTCGACATCATCAATGACGTTATACCATGCGTCATTACTGTAAACCTTGGGACTCAAGTCTAGGTGACCACATAAATAATTATGTGGTCCAAGTGATCTGGCCCACATTGTTTTCCCTGTTCGACTATCGCCCTCAAGAACAATTGATTTAGGTCTTAATGGCCGCGCAGCGGCACTCATCACATTTTCTGAAACCCAGAGTTCAAGTTCTTCTGGAACTTGATTAAAAGAAGATGAAAGAAATGGGGACCTATAAATAGGCACCTCTTGTACAAATATCCTATCTAAATTTGAATTTAAATTGTGAAATTGTAAAATAAAATCCTTAGGGGCTAATTCTTTAATGACCTTAAGAGCTTCGTGCTTACTGCCAGTGTTAAGCGCCTGGGCGTAAGCATCATTAGCTGTCTGTGGACCTCCTCGTGCAGATCTCCCGTCGATCTGGAATTCTCCCCATTCCAGTGTGTCCCCGTCCTTATCCATATAGGACTTGACGTCGGAACTCGATTTTGCCCCTTGAATGTTAGGATGGAAGTGGGCTGATCTTGTTGGGGATACCAGATCGAAGAATCGTTGATTCTTGCATTGGAATTTGCCCTCGAATTGCATAAGAACGTGGAGATGAGGGCTCCCATCTTCGTGGAGTTCTCTGCAAATCTTGATGAATTTTTTATTGGTTGGTGTAACAATTGCCAGAAGTCTGGCAAGAGTTTCTTCTTTTGTGAGTGAGCATTGTGGATAAGTGAGAAAATAATTTTTGGCATTTATTCTGAATTTTGTTGGAGGAGGCATGTTGACTTGGTCAACTGGTGTCTCGCAAACTGGGTGATATATATTGGTGTCTGGGGTCCTATAAATACTTAGACACCTAATGGCACATTCGTAAATATCTTACCCACTTTTGAATTTGAATTTCAAATTTGAATTTAATTTCGGCTCCAAAAAGCGGCCACCCGTATAATATT
ACCGGGTGGCCGCGGGGTCTCTTTATATAGTATGTGTCATGTGTGGGTCCCATGTCACGTGATTTTGTACCTTTCTGTCCCCCAGCTAGCCGACAAAGTGGGACCCACTCACGTGATTAGCACTTGCCTTGTACCTTCCTTCTGTGTACGTTCTGGTCAAAAAGACTAGTATACCCCTGTTGGTGAAAGTACTATATTGCCCCTGGATATTATTGTGTAAGGTTCTGACACGTGTTATGTTATTAAACTCGCATTTACCTAATGCGAGTCTTGCATCGGTCGTCTGAGACTTCCAATAAATATGYACCCCTCACATTGTTATGATTTGTGTATACAATGTCTCCGACATCTGTTGACCGTGTAGGTAGCTGGTACCGACGGGCAAATACTCCGATGTATACCAGACGGAGATATTCATCCGTGCCTGTGTATACACCTAGGTTTACTAGGTATAATTTCAACAAGCCAAGAGCACGCATTCTTGGCGTGCCCTTTTCTCAACGGAGGCGTGATCGGGTCCGAACAAGTCTGTTCTCCAAGAATGTCGACAAGGTGCCTATGAGGGTCCAGACAATTGAGGAGGTCCAGAGTGGTACCCAATATGTTCTGACCAACAATAGTTCCAAGGTGTCGTACATAACATATCCCAGCATATCTCGTAGTGCATTCAGTAGTCGTACATACGACTACATCAAGGTGCTGTCCATAAGTGCCTCTGGCTCCGTGGTCGTGAAGCGAGTTGGTTCGACGTCGGAGGCTGCTTCCACTTGCATCAACGGTATATTTACAACCGTCCTGGTGTGTGACAAGAGGCCGTCTGAATATTCCTCTAGTGAACCAATAATTCCTTATGGGGAATTATTTGGACTTGAGCAGGGATCATGTTCCACTCTTCGCGTACGTGAAAATCATAGGGATAGGTTCCGGGTGATTCAACAGAGGAAGTGTATTGTTAATACGTCCCTCTCGACCTATGTATTTAAATTTGAGTACAAAGCCCACTTGAGGGCCTATCCTTACTGGGTTAGATTTAGAGATAGCCCTAGTCTTGAGGCTACTGGTAGGTATGGAAACATCACAAAAAATGCCCTTGTATTGTATTACGTGTGGTTGTGTGATAGTGCTGCAACTGCTGAGGTGCATGCCAAATATGATACATTGTATTTGGGATAAATAAAATTTAATTTTATTAAATAGGCTTTGCATTTGAAGTTACACTGTTTGATGAGATACAGAGTTCTACGGTTTTTTTGATGATGTTTATTACATCATCATTTACATTTGAGTTTCCTGCGCTAAATACATTATTATTAACTTGTGAAGCCGATGGGCCTGGGTCCAGTGATGCTGGGTCCAATCTGTTAAGCGTCCTGTATGGATAGTCTGCAATAGAAGGCCCATCAATTGAACTTGCTGAGGCCCATGTCTCTCCTGGGCCTATAGTGGGCCTATTGAAACGGGCTGATGCAGATCGTAAGCCCGCAACTGGGTGTCTCGCGAATTGGGCCTGGGCCTGCCCAACTGTCCAGAAATCAATATGTGTGTTGTTATATGCCTTGGACAGAATGTCAATTCTCGGAGATCGGAATTGAATGTCTGATGATTGCTTCGCCGATGACATCCTGAGCTTGCCCTGAATCCTGCAGAAATGGACTCCATTGATGACATTCGTGTTGTCGACCCTGTACATCACTCTCCATGGATTTGGATCCTTTGGAGAAAAATACGAGGACGAGTAGTAGTGTATGTTGCAGTTGCAACCAATTGGAATTGTAAACTCCGCCTGTTTGGAGTCCCCATCTCCTAGTCTCGTATCATGCATTTCAATAATCACATGACCAGTGGCATTAATGGGAACCTGGTTCCTATACTCGAGTATGACATGGTCAATTCTGAGGCAACGACCACGGAGTCTTGATAATTGCTGATCGAGTGTGGAAGGAAACAGAAGAGTGACGTCGGTGAGATCGTTAGATAGTTGGTATTCAGTACGATCGGAGGTCGTATATGCTAGAGTTGAATTGTGTGTTTCCATTGAAACACAGTTTGTAAATGAAGAGCTCTACACATGGTGGTATTTTAAAACCAAAATGGCACGGGTCCCATCAACCTTTGTCAGATGAAGAAACGTCCACTGGAAGGAACTATAACATTCACTAATTCATTTATTTTCCCCCGGCCGCGCAGCGGCATTTGTCCTAAAATATTAACTCAGAAAACATGTGTGAACAGTTAAGTCCGACAACATAGACGATGTAATCGTCTGTAGATTCCATAATCCGAGGAATCCTCCGTTGATGCATTTAAATGGCAATTAATAATTAATTATTATACATAATTAAGTGTTGGTCGGTAATTAGAGTTATCACCAAACCCTAACCTCGGTTAGTTGCTCTGAATATTTAGAAAATATTAAGAAACCAAAGCCCATGGATCCTAAATGTCCGTAAATAATTATTAAAACTAAGTAATTGCAATTACGTGGGATTATGAAATTCCAATAAACAAACAGAACAATTAAACATGTAAATTTGTAGAGAGAAGGCAGAGCCTTGTTCAGAGGTCTAGAGAGAGGAAGAGGCATGTTGACTTGGTCAACTGGTGTCTCGCAAACTGGGTGATAAGTATTGGTGTCTGGGGTCCTATAAATACTTAGACACCTAATGGCACAATTGTAAATACCTTTCCTACTTTTTGAATTTGAATTTGAATTTTGAATTAAATTTTGCCTCCAAAAGCGGCCACCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_001911128.1
|
|
Location
|
100-459 |
|
Gene Name
|
AV2 |
|
Protein Name
|
AV2 protein |
|
Coding Region
|
ATGTTGACCAGTCATACTGGATTGTCAGACATGTGGGATCCATTGGTGAATGATTTTCCTGAGACCGTACATGGTCTTAGGTGTATGCTAGCTGTCAAATACCTGAAATACGTTGAAAGTACGTATTCCCCTGATACACTCGGATACGATCTAATCCGTGATCTGATACTTGTTGTCCGTGCCAAAAATTATGGCGAAGCGAGCCGGAGATATAATCATTTCCACACCCGCCTCCAAGGTTCGACGGAGGCTGAACTTCGACAGCCCGTATCAGAACCGTGTGCCTGTCCTCACTGCCCGAGGCACACGAAAACAGTTATGGGCCAATCGGCCCATGTACAGGAAGCCCAGGATATTTAA |
|
Protein Sequence
|
MLTSHTGLSDMWDPLVNDFPETVHGLRCMLAVKYLKYVESTYSPDTLGYDLIRDLILVVRAKNYGEASRRYNHFHTRLQGSTEAELRQPVSEPCACPHCPRHTKTVMGQSAHVQEAQDI |
|
NCBI Accession
|
YP_001911129.1
|
|
Location
|
290-1060 |
|
Gene Name
|
AV1 |
|
Protein Name
|
CP protein |
|
Coding Region
|
ATGGCGAAGCGAGCCGGAGATATAATCATTTCCACACCCGCCTCCAAGGTTCGACGGAGGCTGAACTTCGACAGCCCGTATCAGAACCGTGTGCCTGTCCTCACTGCCCGAGGCACACGAAAACAGTTATGGGCCAATCGGCCCATGTACAGGAAGCCCAGGATATTTAAATTATATAGAGGCCTTGATGTGCCTCGTGGATGTGAAGGCCCATGTAAAGTCCAGTCATTTGAGCAACGCCATGATGTGGCCCATGTAGGGAAGGTCATATGTATATCTGATGTTACACGTGGGAATGGTATTACTCATCGCGTTGGTAAACGTTTTTGTATTAAGTCCGTATATGTTTTGGGCAAGGTCTGGATGGATGAAAACATCAAGGTCAAGAATCACACGAATAGTGTAATGTTTTTTGTTGTACGTGATCGAAGGCCGTATGGTACCCCTCAAGAATTTGGCCAAGTATTTAATACTTATGACAACGAGCCAAGTACTGCTACTGTGAAGAATGATCTCAGAGATAGATTTCAAGTGATCAGGAAGTTCTATGCAACTGTGACAGGTGGTCAGTATGCCAGTAGAGAACAGACATTAGTCAGGAGATTCATTAGAGTTAATAATTATGTTGTGTATAATCATCAGGAGGCTGCTAAGTACGAGAATCATACAGAGAATGCATTGTTGTTGTATATGGCATGTACACATGCCTCAAATCCTGTGTATGCTACGTTAAAAATACGAATCTATTTTTATGATTCGGTAACAAATTAA |
|
Protein Sequence
|
MAKRAGDIIISTPASKVRRRLNFDSPYQNRVPVLTARGTRKQLWANRPMYRKPRIFKLYRGLDVPRGCEGPCKVQSFEQRHDVAHVGKVICISDVTRGNGITHRVGKRFCIKSVYVLGKVWMDENIKVKNHTNSVMFFVVRDRRPYGTPQEFGQVFNTYDNEPSTATVKNDLRDRFQVIRKFYATVTGGQYASREQTLVRRFIRVNNYVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSVTN |
|
NCBI Accession
|
YP_001911130.1
|
|
Location
|
1057-1461 |
|
Gene Name
|
AC3 |
|
Protein Name
|
REn protein |
|
Coding Region
|
ATGGATTCACGCACCGGGGAAATCATCACTGCAACTCAAGCGGAGAGTGGCGTTTTTATCTGGGAGGTTCCAAATCCCCTATATTTCAAAATCATCAGCCACCTCGACAGGCCAATGTTCCGACCACACGACATCATCACCATCCAGATACAATTCAACCACAACCTACGGAGAGCACTGGGACTTCACAAATGCTTCCTATCCTTTCGGATCTACACACGTTTGAATCCACCGACTGGGAGATTTTTAAGAGTCTTTAAAAATGAATGTATGAAGTACTTAGATAGTTTAGGGGTTATTTCAATTAACAATGTAATTAGGACTGTAAGACATGTTTTGTATGATGTAATAGCTGGTACTTTGGATGTAATCGACCACCATTCGGTGAATTTCAAATATTATTAA |
|
Protein Sequence
|
MDSRTGEIITATQAESGVFIWEVPNPLYFKIISHLDRPMFRPHDIITIQIQFNHNLRRALGLHKCFLSFRIYTRLNPPTGRFLRVFKNECMKYLDSLGVISINNVIRTVRHVLYDVIAGTLDVIDHHSVNFKYY |
|
NCBI Accession
|
YP_001911131.1
|
|
Location
|
1202-1606 |
|
Gene Name
|
AC2 |
|
Protein Name
|
TrAP protein |
|
Coding Region
|
ATGCAGAGTTCGTCACACTCACAGAGCCTCTCTATTCAAGTACCAATCAAGGTCCAACACAAGATTGCCAAGAAACGTAGTAGACGACGAAGGATAGATTTGGAGTGCGGCTGCTCATATTTCTTATCAATCAATTGCCACAACCATGGATTCACGCACCGGGGAAATCATCACTGCAACTCAAGCGGAGAGTGGCGTTTTTATCTGGGAGGTTCCAAATCCCCTATATTTCAAAATCATCAGCCACCTCGACAGGCCAATGTTCCGACCACACGACATCATCACCATCCAGATACAATTCAACCACAACCTACGGAGAGCACTGGGACTTCACAAATGCTTCCTATCCTTTCGGATCTACACACGTTTGAATCCACCGACTGGGAGATTTTTAAGAGTCTTTAA |
|
Protein Sequence
|
MQSSSHSQSLSIQVPIKVQHKIAKKRSRRRRIDLECGCSYFLSINCHNHGFTHRGNHHCNSSGEWRFYLGGSKSPIFQNHQPPRQANVPTTRHHHHPDTIQPQPTESTGTSQMLPILSDLHTFESTDWEIFKSL |
|
NCBI Accession
|
YP_001911132.1
|
|
Location
|
1527-2594 |
|
Gene Name
|
AC1 |
|
Protein Name
|
rep protein |
|
Coding Region
|
ATGCCTCCTCCAACAAAATTCAGAATAAATGCCAAAAATTATTTTCTCACTTATCCACAATGCTCACTCACAAAAGAAGAAACTCTTGCCAGACTTCTGGCAATTGTTACACCAACCAATAAAAAATTCATCAAGATTTGCAGAGAACTCCACGAAGATGGGAGCCCTCATCTCCACGTTCTTATGCAATTCGAGGGCAAATTCCAATGCAAGAATCAACGATTCTTCGATCTGGTATCCCCAACAAGATCAGCCCACTTCCATCCTAACATTCAAGGGGCAAAATCGAGTTCCGACGTCAAGTCCTATATGGATAAGGACGGGGACACACTGGAATGGGGAGAATTCCAGATCGACGGGAGATCTGCACGAGGAGGTCCACAGACAGCTAATGATGCTTACGCCCAGGCGCTTAACACTGGCAGTAAGCACGAAGCTCTTAAGGTCATTAAAGAATTAGCCCCTAAGGATTTTATTTTACAATTTCACAATTTAAATTCAAATTTAGATAGGATATTTGTACAAGAGGTGCCTATTTATAGGTCCCCATTTCTTTCATCTTCTTTTAATCAAGTTCCAGAAGAACTTGAACTCTGGGTTTCAGAAAATGTGATGAGTGCCGCTGCGCGGCCATTAAGACCTAAATCAATTGTTCTTGAGGGCGATAGTCGAACAGGGAAAACAATGTGGGCCAGATCACTTGGACCACATAATTATTTATGTGGTCACCTAGACTTGAGTCCCAAGGTTTACAGTAATGACGCATGGTATAACGTCATTGATGATGTCGACCCCCACTATTTAAAGCACTTTAAGGAATTCATGGGGGCCCAAAGAGACTGGCAAAGCAATACAAAATACGGAAAGCCAGTTCAAATTAAAGGTGGGATTCCCACTATCTTTCTCTGCAATCCAGGGCCCGGTGCCAGCTATATTCAATTTTTAAATGAAGAAAAGCAATCCGCACTAAAGACTTGGGCTTTGAAAAATGCAGAGTTCGTCACACTCACAGAGCCTCTCTATTCAAGTACCAATCAAGGTCCAACACAAGATTGCCAAGAAACGTAG |
|
Protein Sequence
|
MPPPTKFRINAKNYFLTYPQCSLTKEETLARLLAIVTPTNKKFIKICRELHEDGSPHLHVLMQFEGKFQCKNQRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYMDKDGDTLEWGEFQIDGRSARGGPQTANDAYAQALNTGSKHEALKVIKELAPKDFILQFHNLNSNLDRIFVQEVPIYRSPFLSSSFNQVPEELELWVSENVMSAAARPLRPKSIVLEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPGASYIQFLNEEKQSALKTWALKNAEFVTLTEPLYSSTNQGPTQDCQET |
|
NCBI Accession
|
YP_001911133.1
|
|
Location
|
2135-2566 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGCCAAAAATTATTTTCTCACTTATCCACAATGCTCACTCACAAAAGAAGAAACTCTTGCCAGACTTCTGGCAATTGTTACACCAACCAATAAAAAATTCATCAAGATTTGCAGAGAACTCCACGAAGATGGGAGCCCTCATCTCCACGTTCTTATGCAATTCGAGGGCAAATTCCAATGCAAGAATCAACGATTCTTCGATCTGGTATCCCCAACAAGATCAGCCCACTTCCATCCTAACATTCAAGGGGCAAAATCGAGTTCCGACGTCAAGTCCTATATGGATAAGGACGGGGACACACTGGAATGGGGAGAATTCCAGATCGACGGGAGATCTGCACGAGGAGGTCCACAGACAGCTAATGATGCTTACGCCCAGGCGCTTAACACTGGCAGTAAGCACGAAGCTCTTAAGGTCATTAAAGAATTAG |
|
Protein Sequence
|
MPKIIFSLIHNAHSQKKKLLPDFWQLLHQPIKNSSRFAENSTKMGALISTFLCNSRANSNARINDSSIWYPQQDQPTSILTFKGQNRVPTSSPIWIRTGTHWNGENSRSTGDLHEEVHRQLMMLTPRRLTLAVSTKLLRSLKN |
|
NCBI Accession
|
YP_001911134.1
|
|
Location
|
337-1173 |
|
Gene Name
|
BV1 |
|
Protein Name
|
NSP protein |
|
Coding Region
|
ATGTCTCCGACATCTGTTGACCGTGTAGGTAGCTGGTACCGACGGGCAAATACTCCGATGTATACCAGACGGAGATATTCATCCGTGCCTGTGTATACACCTAGGTTTACTAGGTATAATTTCAACAAGCCAAGAGCACGCATTCTTGGCGTGCCCTTTTCTCAACGGAGGCGTGATCGGGTCCGAACAAGTCTGTTCTCCAAGAATGTCGACAAGGTGCCTATGAGGGTCCAGACAATTGAGGAGGTCCAGAGTGGTACCCAATATGTTCTGACCAACAATAGTTCCAAGGTGTCGTACATAACATATCCCAGCATATCTCGTAGTGCATTCAGTAGTCGTACATACGACTACATCAAGGTGCTGTCCATAAGTGCCTCTGGCTCCGTGGTCGTGAAGCGAGTTGGTTCGACGTCGGAGGCTGCTTCCACTTGCATCAACGGTATATTTACAACCGTCCTGGTGTGTGACAAGAGGCCGTCTGAATATTCCTCTAGTGAACCAATAATTCCTTATGGGGAATTATTTGGACTTGAGCAGGGATCATGTTCCACTCTTCGCGTACGTGAAAATCATAGGGATAGGTTCCGGGTGATTCAACAGAGGAAGTGTATTGTTAATACGTCCCTCTCGACCTATGTATTTAAATTTGAGTACAAAGCCCACTTGAGGGCCTATCCTTACTGGGTTAGATTTAGAGATAGCCCTAGTCTTGAGGCTACTGGTAGGTATGGAAACATCACAAAAAATGCCCTTGTATTGTATTACGTGTGGTTGTGTGATAGTGCTGCAACTGCTGAGGTGCATGCCAAATATGATACATTGTATTTGGGATAA |
|
Protein Sequence
|
MSPTSVDRVGSWYRRANTPMYTRRRYSSVPVYTPRFTRYNFNKPRARILGVPFSQRRRDRVRTSLFSKNVDKVPMRVQTIEEVQSGTQYVLTNNSSKVSYITYPSISRSAFSSRTYDYIKVLSISASGSVVVKRVGSTSEAASTCINGIFTTVLVCDKRPSEYSSSEPIIPYGELFGLEQGSCSTLRVRENHRDRFRVIQQRKCIVNTSLSTYVFKFEYKAHLRAYPYWVRFRDSPSLEATGRYGNITKNALVLYYVWLCDSAATAEVHAKYDTLYLG |
|
NCBI Accession
|
YP_001911135.1
|
|
Location
|
1190-2035 |
|
Gene Name
|
BC1 |
|
Protein Name
|
MP protein |
|
Coding Region
|
ATGGAAACACACAATTCAACTCTAGCATATACGACCTCCGATCGTACTGAATACCAACTATCTAACGATCTCACCGACGTCACTCTTCTGTTTCCTTCCACACTCGATCAGCAATTATCAAGACTCCGTGGTCGTTGCCTCAGAATTGACCATGTCATACTCGAGTATAGGAACCAGGTTCCCATTAATGCCACTGGTCATGTGATTATTGAAATGCATGATACGAGACTAGGAGATGGGGACTCCAAACAGGCGGAGTTTACAATTCCAATTGGTTGCAACTGCAACATACACTACTACTCGTCCTCGTATTTTTCTCCAAAGGATCCAAATCCATGGAGAGTGATGTACAGGGTCGACAACACGAATGTCATCAATGGAGTCCATTTCTGCAGGATTCAGGGCAAGCTCAGGATGTCATCGGCGAAGCAATCATCAGACATTCAATTCCGATCTCCGAGAATTGACATTCTGTCCAAGGCATATAACAACACACATATTGATTTCTGGACAGTTGGGCAGGCCCAGGCCCAATTCGCGAGACACCCAGTTGCGGGCTTACGATCTGCATCAGCCCGTTTCAATAGGCCCACTATAGGCCCAGGAGAGACATGGGCCTCAGCAAGTTCAATTGATGGGCCTTCTATTGCAGACTATCCATACAGGACGCTTAACAGATTGGACCCAGCATCACTGGACCCAGGCCCATCGGCTTCACAAGTTAATAATAATGTATTTAGCGCAGGAAACTCAAATGTAAATGATGATGTAATAAACATCATCAAAAAAACCGTAGAACTCTGTATCTCATCAAACAGTGTAACTTCAAATGCAAAGCCTATTTAA |
|
Protein Sequence
|
METHNSTLAYTTSDRTEYQLSNDLTDVTLLFPSTLDQQLSRLRGRCLRIDHVILEYRNQVPINATGHVIIEMHDTRLGDGDSKQAEFTIPIGCNCNIHYYSSSYFSPKDPNPWRVMYRVDNTNVINGVHFCRIQGKLRMSSAKQSSDIQFRSPRIDILSKAYNNTHIDFWTVGQAQAQFARHPVAGLRSASARFNRPTIGPGETWASASSIDGPSIADYPYRTLNRLDPASLDPGPSASQVNNNVFSAGNSNVNDDVINIIKKTVELCISSNSVTSNAKPI |