Abutilon mosaic Brazil virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000895175.1 |
| Isolate |
Brazil |
| Release date |
2015/2/22 |
| Submitter |
Wyant,P.S., Strohmeier,S., Schafer,B., Krenz,B., Assuncao,I.P., Lima,G.S., Jeske,H., Schaefer,B., Lima,G.S.A. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
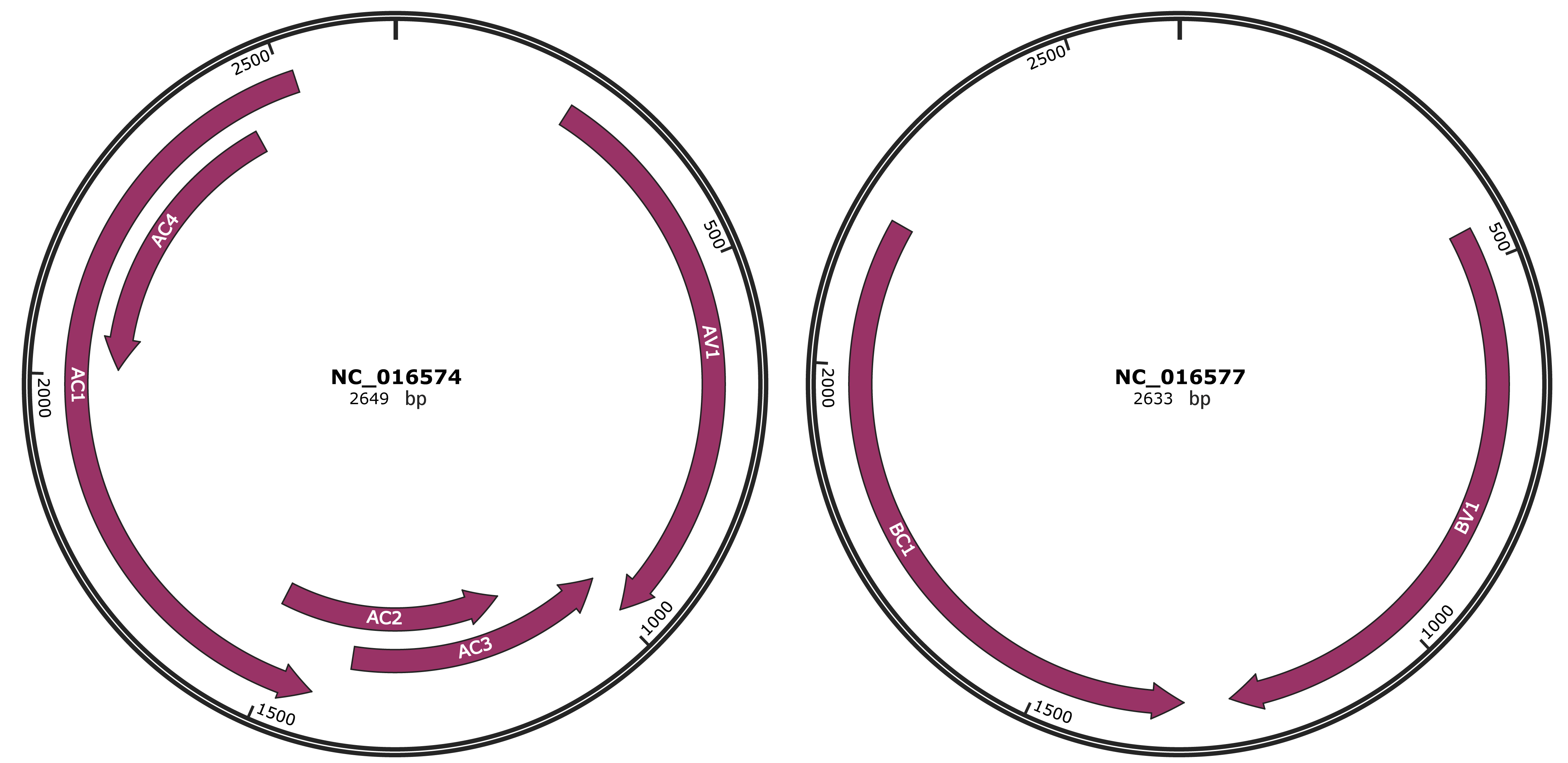
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTCCCCCCCCCACGTGGCGCTCTCGTATCCGCGCGATCTCCTTTCGCTTCCCCCCCCGCGCGCGTCTATCTCCTTTAATTTGAATTAAAGGAATTAACTTTCGTTCCGACCAATGATAATGCGCCTGACTAGCTTAGATAACTGTGAAAGACTTGGTCCCTAAGTTGTTGATTAACGGCTATAAATTAAAGGAAGACCGGGTAGGGTCTTCAATTCAAGATGCCTAAGCGGGATGCCCCGTGGCGCCTGATGGCGGGAACTTCCAAGGTTGGCCGTTTATCCAACACCGCTCCTCGTGGAGGTTCTGGGCCTAGGTCCAACAAGGCCAATGAGTGGGTCAACAGACCCATGTACAGGAAGCCCAGGATATACCGGGCCTTCAGAACTCCAGATGTCCCTCGAGGGTGTGAAGGGCCATGCAAGGTCCAGTCCTATGAACAGCGACATGATATCTCTCATGTCGGTAAGGTTATGTGTATATCTGATGTCACCCGAGGTAATGGTATTACTCACCGTGTCGGTAAGCGTTTCTGCGTTAAGTCTGTGTATATTTTAGGGAAGATATGGATGGACGAGAATATCAAGCTCAAGAACCACACGAACAGTGTTATGTTCTGGTTGGTCAGGGACCGTAGACCGTATGGCACACCAATGGACTTTGGCCAGGTCTTCAACATGTTTGACAACGAGCCCAGCACTGCTACGGTTAAGAACGATCTACGCGATCGTTATCAGGTCATGCACAAGTTCTATGCCAAGGTCACTGGCGGTCAGTATGCCAGCAATGAACAGGCTCTGGTCAAGAGGTTCTGGAAGGTCAACAATCATGTGGTGTATAATCACCAGGAGGCTGGGAAGTACGAGAATCACACGGAGAACGCACTCCTATTGTACATGGCATGTACTCATGCCTCTAACCCTGTGTATGCAACGCTTAAGATTCGGATCTACTTTTACGATTCGATCATGAATTAATAAAATTTGAATTTTATTACGTGGTTTTCAAGTACATAGCTGACATAAGATTTGTCTGTTGCGAAACGCACAGCTCTGATTACATTGTTAAGCGTAATTACTCCTAATCGGTCTAAGTAAAGCATGACTAAGTGTCTAAACCTAGTCAAATAAGTTGACCCAGAAGCTGTCAGAGAAGTCGTCCAGACTTGGAAGTTCAGGAATGCCTTGTGGAGACCCAATGCTCTCCTGAGGTTGTGGTTGAACCTTATCTGGATGTGGTACACTCTTGTCCGAGTGTACGGTGGATCCTCTACCCTGATTATCTTGAAATACAGGGGATTTGTTATCTCCCAGATATAGACGCCATTCTCTGCCTGACGTGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGGCCCGTGCAGTTGAGATGCTGGTAAATGGAGCAGCCGCAGTCCAGATCAATTCGTCGTCGCCTGATTGCTCTCTTCTTCGCAATCCTGTGTCGTGGTTTGATAGAGGGGGGAGTTGAGGAAGATGAATTTAGCATTGTTGATTGTCCAGGCTTTAAGTGATGAGTTTTCCTGCTTCTCCAGGAAATCTTTATAGCTGGCCCCCTCTCCAGGATTGCATAGCACGATTGATGGGATACCCCCTTTAATTTGAACAGGCTTGCCGTACTTGCAATTGGACTGCCAATCTTTTTGAGCACCAATCAATTCCTTCCAGTGCTTTAGCTTTAGGTATTGCGGGCTGACATCATCGATGACGTTATACTCAACTTGATTTGAGTAGACCCGGGAATTGAAATCTAAATGGCCACTCAAGTAATTATGTGGGCCTAATGCTCTAGCCCACATCGTCTTACCAGTTCGAGAATCACCTTCAACTATTATACTTATGGGCCTAACAGGCCGCGCAGCGGAACTTCTTCCAAAATAATCATCCGCCCACTCTTGCATCTCTTCAGGAACGTTAGTGAACGATGAGAGGGGAAACGGAGGAGCCCATGGTTCCGGAGCCCTCTTAAAGATCAATTCCAGGTTGGAGCGGATGTTATGGTGTTGGACGATGAAGGTCTTTGGATCTCCGGCTCTGATAATTTCAAGAGCCTCTGAAACACCTCCTGCATTGACGGCGTTGTGGAAGACATCGTCCTTGTTGGCCTTGGTACCCCCAGACACCTTGTATTGTCCGGATTCACAATAGTCACCATCTTTGGTGATGTAGTTCCTGACGGCAACGGTGTCTTTGGCAGCTTGCACGTTCGGGTGAAAACTGGCTGACCGTCTGGGGTGAGTAAGGTCGAAAAATCTTGCATCCCTGATGTTGGACTTTCCTGATAATTGTATGAGACAGTGTAGATGGGGGTGTCCATCGGAGTGTTCCTCACGTGCGACTCTGATATAGGTAGGTTGGACGACTGTCCATGAAAGGGCTTGAAGCATTTGAAGAGCTTCATCTTTGGGTATGTCGCAACGGGGATATGTGAGGAATATGTTTCTGGCTTGTAATCTAAAAGAATGGGAAAGTCGGGGCATTTTTGTAAATTTCTGTTAGTGGCTCCAGGGGAGCTCTCAACTTCTGTGCTATTTGCTGGAGTCTTGGAGCCTCATTTATACTAGAAGTCTCTAATGCTCCTAGGGGGCACGTGGCGGCCATCCGTATAATATT
ACCTGAGGGCCGCCCCCCGGAGACCCCCCTGACGTGGCGCAATCTGATCCACTCCATCATGTTATCTTGGAGGCTGTTTACCGGGTGACCGGATCCCCCCCTCCCTTTTTACCGGTTTCCCAGGTTACCCCCCTGCCCCCATACCAAATGACCAATATACCCTCGTCTTTATTAAAAGACGCGCCCACTCCGCAATTCTGACGTGGCTCGCTTGTGTCCCTTGGATTAAATTAGATGTGGTCCCATCCTTTAATTGTCAGATGAATTATTGAATTGCGGGCCTCTGTACACTTTAATTTGAAACTTGAATTATTGGTTTGCGTGCCTCTTTTTGACCAGTCAATAATATGTATGTGGTGTACAGAGGGTGTTACGTGGAGCAATAATGTGCTTATGTATTATTGATATAACTATTTTCTGTATATTGAACGTCTTATTTAAGTTCCCTCGTGATGTCCCATGTGTGTATGCCTAGTTTGAACATGTATTCTACAAAGAGTAGACGGGGATCGTCTGCATATCGGGGAACTTATTCTCGTAAACCTTTTATTAGACGTTCCTATGGTTCATCACGCACACATGCTAGACGTCGTGTTAGTAATCCTAACAGGTCAAGTGACGATAGCAAGATGTCACATTTTAGGATTCATGAAAATCAATATGGCCCAGAGTTTGTAATGCTTCATAACACGGCGATATCTACGTTTATTACGTATCCCACCCTTGGTAAGACTGAGCCTTGTCGTACTAGGTCATACATTAAACTGAGACGTTTGCGATATAAGGGAACTGTTAAGATTGAACGTGTTCACACGGATGTGAACATGAACGGGTTAATCCCCAAGATTGAAGGTGTGTTTTCCTTGGTGGTTGTTGTTGATCGCAAACCTCATCTTAGCCCATCTGGGAGCCTGTATACATTTGATGAGCTATTTGGTGCAAGGATCCATAGCCATGGTAACTTGGCCATTACTTCAGCTCTGAGAGATCGGTTTTACATACGTCATGTCCTGAAACGTGTATTATCTGTTGAGAAGGATACGACCATGATTGATCTCGAAGCAACCACATTATTGTCCACCAGGCGTTACAACTGTTGGGCTACTTTTAATGACCTTGATCGAGAATCATGTAATGGTGTTTATGCAAACATTAGCAAGAACGCCTTATTGGTTTATTATTGTTGGATGTCTGATACTGTGTCTAAGGCATCTACTTTTGTATCATTTGATCTGGATTACGTTGGATAAGCAACAATAATAATATGTGTTAACACTGTAATGCATTTGAGACAATTATTCGATAATTGTTTATTTCAATGACTTTGGTTCTGATGGTGTACAATTTGTGTTAATACATTCATGTACGGTAGACCTAACAATCTCGTTCAATTCCGCTAACGAAATTGAAATGTTGGAGCGTGTTCTCTCTGCTCCTGTAACCGATGCTGACTCCCCTGGATCTAATACTGTTGAACCTAGTCTGTGTAAATGTCTATATGGGTGGATCTCGTTTTGTAGCTGCGAGTCCCCTGATGAGTTCGTGAGCCCAATAGTGCTTCTAGAAGCCCATGATTCTCCAGGCTTTATTTCTATTGGGACTTGCAGCCCAAATCTTGACGTCGAAGCTGTTCTTATGAGCTTCCGCTCCCAAGCTCCGTATCCAACGTGTGAGAAATCTATATCCTTTTCTGTGAACTGCTTCGACAGTATCTTCACAGTTGGTGCCCTAAACGGAATATCTACAGAGTGTTTAGCTGTTGACAGTTTCAGCTTTCCTTTGAACTTGGCGAAATGCGTCCTTTGATGAACGTTCGTGTCCATCACTCTGTAGTATAACTTCCATGGAATTGGATCTTTTAGGGAGAAGAACGACGACGAGAAGTAGTGTAGGTCTATGTTGCATCTGATTGGGAAGGTCCAAGATGCCTGTAGAGATTCATTGTCCGTCATCCTCTTGTCGTGAATCTCCATTATGACTGAGCCTGTGGCGTTAATTGGCACTTGCTGCCTGTATTCGATGACGCAATGATCTATCTTCATACAGCTCCGACTCAGTTTAGCACTAATTTGCGACGCCGTTGAAGGAAATTGCAGAACAATTTCTGTTAGGTCATGCGATAGCTGGTATTCATCACGCTGAGATTCAACATAATTAAAAGCGCTTGGAGGAGCAACCAACTGAGAACTCATATTAAATATCCTGGCCGCGCAGCGGAATTGTTTAGCTGATTTGAACAGGCGAAGCAAATAGGAATCGTTGTTTATGTGATGAAGCAATAGCCAAGATGAAGAAGAAACCTGGGCTGATATTTTGCAGATGCTATGAATCTGATGAAGATGCGAATGGAATATGAGCGTAGAGGATAGAGGTCGATATATGAAGATAATTCTGGGTTGAGTATTTGCTGTGCTACCTGTTTATGTGAATTTTGTTCTTGAAAAATTCAAGAGATGATGATGAATATAAAGGAAACCCAGATGGTGTCTCTAGATGAGCGTCTCCAATTCCCCCCCTTGAAACTGGGCGTATTATATTGGAGATTGGGGACAATATATACTAGAAGATATATGGTTAGTATGTGGTCCCTACACTACCGGATGACCTAGAGCGGCCCTCAGTATACTAATATT
Gene Information
|
NCBI Accession
|
YP_004958224.1
|
|
Location
|
239-994 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGGGATGCCCCGTGGCGCCTGATGGCGGGAACTTCCAAGGTTGGCCGTTTATCCAACACCGCTCCTCGTGGAGGTTCTGGGCCTAGGTCCAACAAGGCCAATGAGTGGGTCAACAGACCCATGTACAGGAAGCCCAGGATATACCGGGCCTTCAGAACTCCAGATGTCCCTCGAGGGTGTGAAGGGCCATGCAAGGTCCAGTCCTATGAACAGCGACATGATATCTCTCATGTCGGTAAGGTTATGTGTATATCTGATGTCACCCGAGGTAATGGTATTACTCACCGTGTCGGTAAGCGTTTCTGCGTTAAGTCTGTGTATATTTTAGGGAAGATATGGATGGACGAGAATATCAAGCTCAAGAACCACACGAACAGTGTTATGTTCTGGTTGGTCAGGGACCGTAGACCGTATGGCACACCAATGGACTTTGGCCAGGTCTTCAACATGTTTGACAACGAGCCCAGCACTGCTACGGTTAAGAACGATCTACGCGATCGTTATCAGGTCATGCACAAGTTCTATGCCAAGGTCACTGGCGGTCAGTATGCCAGCAATGAACAGGCTCTGGTCAAGAGGTTCTGGAAGGTCAACAATCATGTGGTGTATAATCACCAGGAGGCTGGGAAGTACGAGAATCACACGGAGAACGCACTCCTATTGTACATGGCATGTACTCATGCCTCTAACCCTGTGTATGCAACGCTTAAGATTCGGATCTACTTTTACGATTCGATCATGAATTAA |
|
Protein Sequence
|
MPKRDAPWRLMAGTSKVGRLSNTAPRGGSGPRSNKANEWVNRPMYRKPRIYRAFRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHKFYAKVTGGQYASNEQALVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
|
NCBI Accession
|
YP_004958225.1
|
|
Location
|
991-1389 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCACGTCAGGCAGAGAATGGCGTCTATATCTGGGAGATAACAAATCCCCTGTATTTCAAGATAATCAGGGTAGAGGATCCACCGTACACTCGGACAAGAGTGTACCACATCCAGATAAGGTTCAACCACAACCTCAGGAGAGCATTGGGTCTCCACAAGGCATTCCTGAACTTCCAAGTCTGGACGACTTCTCTGACAGCTTCTGGGTCAACTTATTTGACTAGGTTTAGACACTTAGTCATGCTTTACTTAGACCGATTAGGAGTAATTACGCTTAACAATGTAATCAGAGCTGTGCGTTTCGCAACAGACAAATCTTATGTCAGCTATGTACTTGAAAACCACGTAATAAAATTCAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGELITARQAENGVYIWEITNPLYFKIIRVEDPPYTRTRVYHIQIRFNHNLRRALGLHKAFLNFQVWTTSLTASGSTYLTRFRHLVMLYLDRLGVITLNNVIRAVRFATDKSYVSYVLENHVIKFKFY |
|
NCBI Accession
|
YP_004958226.1
|
|
Location
|
1136-1525 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcriptional regulator |
|
Coding Region
|
ATGCTAAATTCATCTTCCTCAACTCCCCCCTCTATCAAACCACGACACAGGATTGCGAAGAAGAGAGCAATCAGGCGACGACGAATTGATCTGGACTGCGGCTGCTCCATTTACCAGCATCTCAACTGCACGGGCCATGGATTCACGCACAGGGGAACTCATCACTGCACGTCAGGCAGAGAATGGCGTCTATATCTGGGAGATAACAAATCCCCTGTATTTCAAGATAATCAGGGTAGAGGATCCACCGTACACTCGGACAAGAGTGTACCACATCCAGATAAGGTTCAACCACAACCTCAGGAGAGCATTGGGTCTCCACAAGGCATTCCTGAACTTCCAAGTCTGGACGACTTCTCTGACAGCTTCTGGGTCAACTTATTTGACTAG |
|
Protein Sequence
|
MLNSSSSTPPSIKPRHRIAKKRAIRRRRIDLDCGCSIYQHLNCTGHGFTHRGTHHCTSGREWRLYLGDNKSPVFQDNQGRGSTVHSDKSVPHPDKVQPQPQESIGSPQGIPELPSLDDFSDSFWVNLFD |
|
NCBI Accession
|
YP_004958227.1
|
|
Location
|
1437-2516 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGCCCCGACTTTCCCATTCTTTTAGATTACAAGCCAGAAACATATTCCTCACATATCCCCGTTGCGACATACCCAAAGATGAAGCTCTTCAAATGCTTCAAGCCCTTTCATGGACAGTCGTCCAACCTACCTATATCAGAGTCGCACGTGAGGAACACTCCGATGGACACCCCCATCTACACTGTCTCATACAATTATCAGGAAAGTCCAACATCAGGGATGCAAGATTTTTCGACCTTACTCACCCCAGACGGTCAGCCAGTTTTCACCCGAACGTGCAAGCTGCCAAAGACACCGTTGCCGTCAGGAACTACATCACCAAAGATGGTGACTATTGTGAATCCGGACAATACAAGGTGTCTGGGGGTACCAAGGCCAACAAGGACGATGTCTTCCACAACGCCGTCAATGCAGGAGGTGTTTCAGAGGCTCTTGAAATTATCAGAGCCGGAGATCCAAAGACCTTCATCGTCCAACACCATAACATCCGCTCCAACCTGGAATTGATCTTTAAGAGGGCTCCGGAACCATGGGCTCCTCCGTTTCCCCTCTCATCGTTCACTAACGTTCCTGAAGAGATGCAAGAGTGGGCGGATGATTATTTTGGAAGAAGTTCCGCTGCGCGGCCTGTTAGGCCCATAAGTATAATAGTTGAAGGTGATTCTCGAACTGGTAAGACGATGTGGGCTAGAGCATTAGGCCCACATAATTACTTGAGTGGCCATTTAGATTTCAATTCCCGGGTCTACTCAAATCAAGTTGAGTATAACGTCATCGATGATGTCAGCCCGCAATACCTAAAGCTAAAGCACTGGAAGGAATTGATTGGTGCTCAAAAAGATTGGCAGTCCAATTGCAAGTACGGCAAGCCTGTTCAAATTAAAGGGGGTATCCCATCAATCGTGCTATGCAATCCTGGAGAGGGGGCCAGCTATAAAGATTTCCTGGAGAAGCAGGAAAACTCATCACTTAAAGCCTGGACAATCAACAATGCTAAATTCATCTTCCTCAACTCCCCCCTCTATCAAACCACGACACAGGATTGCGAAGAAGAGAGCAATCAGGCGACGACGAATTGA |
|
Protein Sequence
|
MPRLSHSFRLQARNIFLTYPRCDIPKDEALQMLQALSWTVVQPTYIRVAREEHSDGHPHLHCLIQLSGKSNIRDARFFDLTHPRRSASFHPNVQAAKDTVAVRNYITKDGDYCESGQYKVSGGTKANKDDVFHNAVNAGGVSEALEIIRAGDPKTFIVQHHNIRSNLELIFKRAPEPWAPPFPLSSFTNVPEEMQEWADDYFGRSSAARPVRPISIIVEGDSRTGKTMWARALGPHNYLSGHLDFNSRVYSNQVEYNVIDDVSPQYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLEKQENSSLKAWTINNAKFIFLNSPLYQTTTQDCEEESNQATTN |
|
NCBI Accession
|
YP_004958228.1
|
|
Location
|
2009-2437 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGAAGCTCTTCAAATGCTTCAAGCCCTTTCATGGACAGTCGTCCAACCTACCTATATCAGAGTCGCACGTGAGGAACACTCCGATGGACACCCCCATCTACACTGTCTCATACAATTATCAGGAAAGTCCAACATCAGGGATGCAAGATTTTTCGACCTTACTCACCCCAGACGGTCAGCCAGTTTTCACCCGAACGTGCAAGCTGCCAAAGACACCGTTGCCGTCAGGAACTACATCACCAAAGATGGTGACTATTGTGAATCCGGACAATACAAGGTGTCTGGGGGTACCAAGGCCAACAAGGACGATGTCTTCCACAACGCCGTCAATGCAGGAGGTGTTTCAGAGGCTCTTGAAATTATCAGAGCCGGAGATCCAAAGACCTTCATCGTCCAACACCATAACATCCGCTCCAACCTGGAATTGA |
|
Protein Sequence
|
MKLFKCFKPFHGQSSNLPISESHVRNTPMDTPIYTVSYNYQESPTSGMQDFSTLLTPDGQPVFTRTCKLPKTPLPSGTTSPKMVTIVNPDNTRCLGVPRPTRTMSSTTPSMQEVFQRLLKLSEPEIQRPSSSNTITSAPTWN |
|
NCBI Accession
|
YP_004958237.1
|
|
Location
|
453-1250 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTCCCATGTGTGTATGCCTAGTTTGAACATGTATTCTACAAAGAGTAGACGGGGATCGTCTGCATATCGGGGAACTTATTCTCGTAAACCTTTTATTAGACGTTCCTATGGTTCATCACGCACACATGCTAGACGTCGTGTTAGTAATCCTAACAGGTCAAGTGACGATAGCAAGATGTCACATTTTAGGATTCATGAAAATCAATATGGCCCAGAGTTTGTAATGCTTCATAACACGGCGATATCTACGTTTATTACGTATCCCACCCTTGGTAAGACTGAGCCTTGTCGTACTAGGTCATACATTAAACTGAGACGTTTGCGATATAAGGGAACTGTTAAGATTGAACGTGTTCACACGGATGTGAACATGAACGGGTTAATCCCCAAGATTGAAGGTGTGTTTTCCTTGGTGGTTGTTGTTGATCGCAAACCTCATCTTAGCCCATCTGGGAGCCTGTATACATTTGATGAGCTATTTGGTGCAAGGATCCATAGCCATGGTAACTTGGCCATTACTTCAGCTCTGAGAGATCGGTTTTACATACGTCATGTCCTGAAACGTGTATTATCTGTTGAGAAGGATACGACCATGATTGATCTCGAAGCAACCACATTATTGTCCACCAGGCGTTACAACTGTTGGGCTACTTTTAATGACCTTGATCGAGAATCATGTAATGGTGTTTATGCAAACATTAGCAAGAACGCCTTATTGGTTTATTATTGTTGGATGTCTGATACTGTGTCTAAGGCATCTACTTTTGTATCATTTGATCTGGATTACGTTGGATAA |
|
Protein Sequence
|
MSHVCMPSLNMYSTKSRRGSSAYRGTYSRKPFIRRSYGSSRTHARRRVSNPNRSSDDSKMSHFRIHENQYGPEFVMLHNTAISTFITYPTLGKTEPCRTRSYIKLRRLRYKGTVKIERVHTDVNMNGLIPKIEGVFSLVVVVDRKPHLSPSGSLYTFDELFGARIHSHGNLAITSALRDRFYIRHVLKRVLSVEKDTTMIDLEATTLLSTRRYNCWATFNDLDRESCNGVYANISKNALLVYYCWMSDTVSKASTFVSFDLDYVG |
|
NCBI Accession
|
YP_004958238.1
|
|
Location
|
1311-2192 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGAGTTCTCAGTTGGTTGCTCCTCCAAGCGCTTTTAATTATGTTGAATCTCAGCGTGATGAATACCAGCTATCGCATGACCTAACAGAAATTGTTCTGCAATTTCCTTCAACGGCGTCGCAAATTAGTGCTAAACTGAGTCGGAGCTGTATGAAGATAGATCATTGCGTCATCGAATACAGGCAGCAAGTGCCAATTAACGCCACAGGCTCAGTCATAATGGAGATTCACGACAAGAGGATGACGGACAATGAATCTCTACAGGCATCTTGGACCTTCCCAATCAGATGCAACATAGACCTACACTACTTCTCGTCGTCGTTCTTCTCCCTAAAAGATCCAATTCCATGGAAGTTATACTACAGAGTGATGGACACGAACGTTCATCAAAGGACGCATTTCGCCAAGTTCAAAGGAAAGCTGAAACTGTCAACAGCTAAACACTCTGTAGATATTCCGTTTAGGGCACCAACTGTGAAGATACTGTCGAAGCAGTTCACAGAAAAGGATATAGATTTCTCACACGTTGGATACGGAGCTTGGGAGCGGAAGCTCATAAGAACAGCTTCGACGTCAAGATTTGGGCTGCAAGTCCCAATAGAAATAAAGCCTGGAGAATCATGGGCTTCTAGAAGCACTATTGGGCTCACGAACTCATCAGGGGACTCGCAGCTACAAAACGAGATCCACCCATATAGACATTTACACAGACTAGGTTCAACAGTATTAGATCCAGGGGAGTCAGCATCGGTTACAGGAGCAGAGAGAACACGCTCCAACATTTCAATTTCGTTAGCGGAATTGAACGAGATTGTTAGGTCTACCGTACATGAATGTATTAACACAAATTGTACACCATCAGAACCAAAGTCATTGAAATAA |
|
Protein Sequence
|
MSSQLVAPPSAFNYVESQRDEYQLSHDLTEIVLQFPSTASQISAKLSRSCMKIDHCVIEYRQQVPINATGSVIMEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVMDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTEKDIDFSHVGYGAWERKLIRTASTSRFGLQVPIEIKPGESWASRSTIGLTNSSGDSQLQNEIHPYRHLHRLGSTVLDPGESASVTGAERTRSNISISLAELNEIVRSTVHECINTNCTPSEPKSLK |