Chino del tomate virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000838385.1 |
| Release date |
2015/2/12 |
| Submitter |
Jiang,H., Hou,Y.-M., Guzman,P., Gilbertson,R.L. |
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
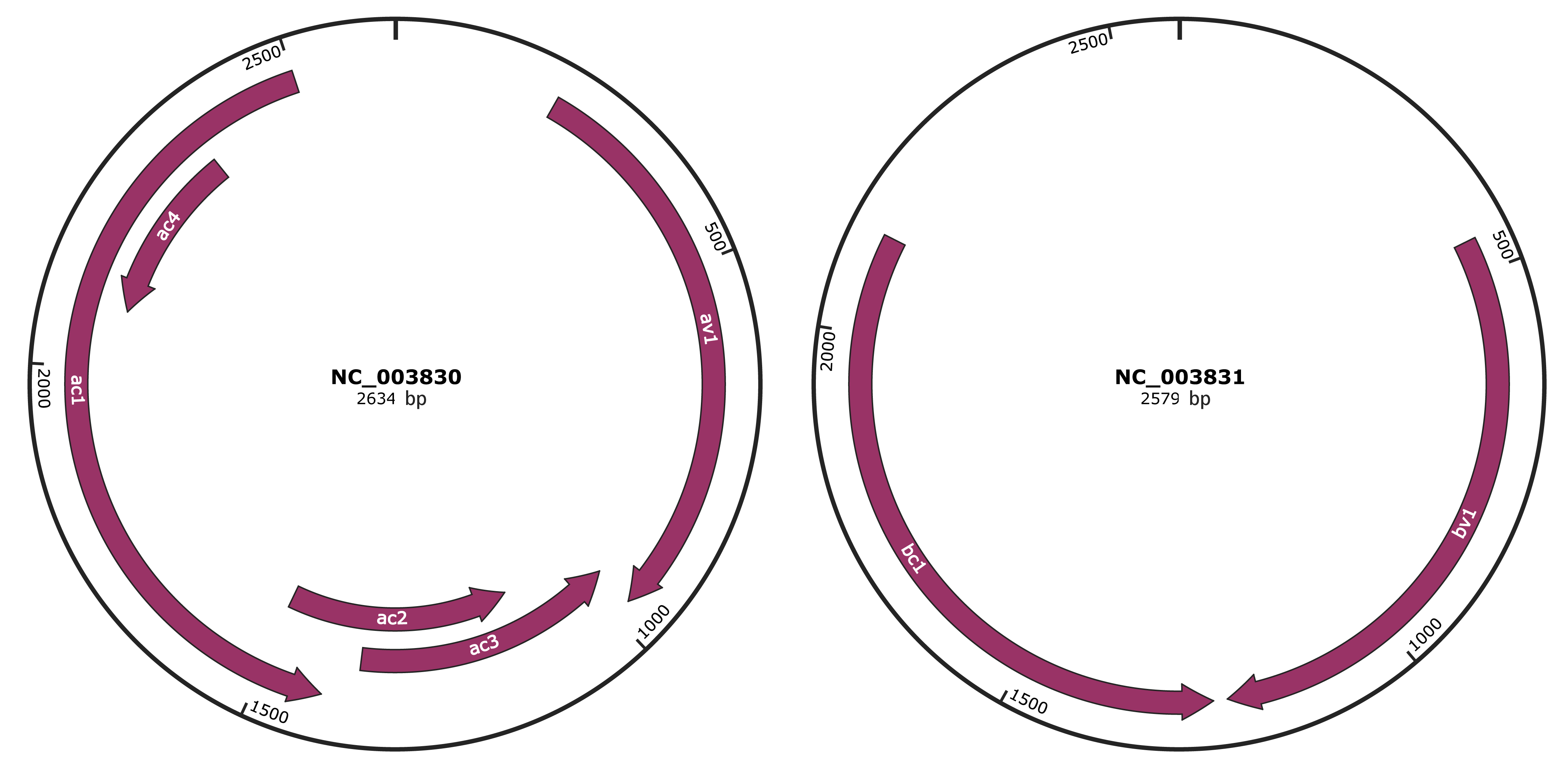
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTCCCCCCTTGTACGTGGACGGTCACGATTGTCTCTTTCCGCCCGCACGCTCCTCTTTAATTTGAATTAAAGCTCTCCGCTTTCGTCTCGTCCAATCATGTAACGCCTGACGAGCTTAGATATTTTTAACTACTTGGGCTCGAAGTAGTTATCGTTATAAATTAAAGAGGCTTTTGGCCCACTGAATTCAATTCAAAATGCCTAAGCGCGATCTACCCTGGCGCTCGATCGCGGGAACTTCGAAGGTGAGCCGCAATGCCAATTATTCCCCTCGTGGAGGAAGTGGGCCTCGAATTAACAAGGCCGCTGAATGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGGACGCTGAGAACGCCTGACGTTCCAAGAGGATGTGAAGGCCCATGTAAGGTCCAGTCCTATGAACAGCGCCACGATATTTCACATACAGGTAAGGTTATGTGCATATCCGACGTGACACGTGGTAATGGTATCACTCACCGTGTGGGTAAGCGTTTCTGTGTTAAGTCTGTGTACATTCTCGGTAAGATCTGGATGGATGAGAACATCAAGCTGAAGAACCACACGAATAGTGTTATGTTCTGGTTGGTCAGGGATCGTAGACCGTATGGCACTCCCATGGATTTCGGTCAAGTGTTCAACATGTTTGACAACGAGCCCAGCACTGCTACGGTGAAGAACGATCTACGCGATCGATTCCAGGTCATGCACAAATTCTATGGGAAGGTGACAGGTGGACAGTATGCCAGCAACGAGCAGGCGATAGTCAAGCGCTTCTGGAAGGTCAACAATCATGTGGTCTACAATCATCAAGAGGCTGGCAAGTACGAGAATCATACGGAGAACGCTTTGTTATTGTACATGGCATGTACGCATGCCTCTAACCCTGTATATGCAACGCTTAAGATCCGGATCTACTTCTATGATTCGATCATGAATTAATAAAGTTTGAATTTTATTGAATGATTTTCCAGTACATAACTAACATACGACCTGTCTGTTGCGAAACGAACAGCTCTGATTACATTGTTAATGGAAATAACGCCTAACTGATCTAAATACATATTAACTAAATGTCTAAACCTAGCTAAATAGGTCGACCCAGAAGCTATCATCGATGTCGTCCAGACTTGGAAGTTCAGGTAGGCTTTGTGGAGATGCAACGCTCTCCTCAGGTTGTGGTTGAACCGTATCTGAACGTGGTAAACCCTGGTTCTCGTATACGGTAGATCCTCCACTTTGTACATCTTGAAATAGAGGGGATTTTCTATCTCCCAGATATACACGCCATTCTCCGCCTGAGGTACAGTGATGAATTCCCCTGTGCGTGAATCCATGCCCCGTGCAGCCTATGTGGAAGTATATGGAGCACCCGCACCGTAAATCAATCCGCCTCCTCCTGATGGCCCTTTTCTTGGCTTGCCTGTGCGCTGTCTTGATAGAGGGCGGATGTGAGGGTGATGAAGATCGCATTCTTTATGGTCCAATTTCTCAGTGATGCGTTTTCCTCTTTGTTGAGGAAATCTTTATAGCTGGCACCCTCACCAGGATTGCAAAGCACGATTGCTGGGATCCCTCCTTTAATTTGAACTGGCTTACCGTACTTGCAATTGGATTGCCAGTCCTTCTGGGCCCCCAGAAGTTCCTTCCAGTGCTTTAACTTTAGATAGTGCGGTGCGACGTCATCAATGACGTTATACTCCACTTCGTTCGAGTAGACCTTTGGGTTGAAGTCCAGATGACCACTTAGGTAATTATGTGGGCCTAATGCCCTAGCCCACATCGTCTTCCCTGTCCTCGAATCACCTTCCACGATGATACTAATAGGTCTTTCCGGCCGCGCAGCGGAACCTCTTCCAAAATAATCATCCGCCCACTCTTGCATCTCGTCTGGAACGTTAGTGAACGAAGAGAGTTGAAACGGAGGAACCCACCGTTCCGGAGCCTTTGCGAATATTCTCTCTAGGTTGGAGCGGATGTTATGATTATGCAGGACAAAATCTTTTGGCTGCTCTTCCTTTAAAACCGCCATGGCAGATTGAACAGATCCTGCATTCAACGCCTTGGCATATGAGTCGTTAGCAGATTGCTGACCTCCTCTAGCTGATCTGCCGTCGATCTGGAATTCTCCCCACTCAACTGTATCTCCGTCCTTGTCGATGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGTATGTTCGGATGGAAATGTGCTGACCGGGTTGGGGAGACCAGATCGAAGAATCTGTTATTCGTGCACTGGTACTTCCCTTCGAATTGGATGAGAACGTGGAGATGAGGCTCCCCATTCTCATGTAACTCTCTGCAAATCTTGATGTATTTCTTGTTAACTGGCGTTTTTAGGGTTTGTAATTGGGAAAGTGCTTCTTCTTTGCTAAGAGAGCACTGGGGATATGTGAGGAAATAGTTTTTGGCTGAGACTTTGAAACGTTTAACCGATGGCATTTTTGTAATAAGATGGGTGTACTCCGATTGAGCTCTCAAACTTCTGTGCTATGTTTTGGGGTAAAGGGGACAATATATACTAGAACTCTTAGTAGCACTTTAGCGACACGTGGCGGCCATCCGATATAATATT
ACCGGATGGCCGCGCCGGGGGACGTTCCCTCAACGTGTTGTCTCTCTATTGGCTCTCTCTCGCCAGCTGTTGCGCATTAACCCCGCCCCCTCCTCCCTCTGGTGGCCCTCTCAACGTGGCGTCTCTGTAATGGTCCTTTTCCCGCTACAATGGGCCCTTTTGTCAGTGAGTATTTATCTATCTCTTTAATTCAAATTAAAGGTAATTACTTTCATGTCTCGCGACCAGATTTGAATTTGAGACTATGTGTGTTGTCTTTTGAATATGGCCCATTGTACTACATGATGGACGTGGCTGATTTGAGACCGCGCTGCTGAGTTAAGTTAAGTCTTATTGTGAACTAGCTTTTCTATATATTGGGCCATGTTGATCTATTATATTCGATGTGACTCAGCAGTCTACCACGCTTAGTTGTTAATTAAACGTTTATTTTTGATAAAGTGGTATCATTTGATAATGTATCCTTTTAGGTCTAAGCGTGGTGCCTCATTTGTTGCACGTCGTTCTTATTCACGTAATAATTTGTTTAAGCGATCAACCATCTCCAAACGAGATGATGGGAGACGTCGATCTGTTAATGCAACTAAACCCAATGACGAGCCCAAGATGATAGCCCAACGCATGCACGAGAATCAGTTTGGGCCAGATTTTGTAATGGCCCATAATGCAGCCTTGGCAACTTTCATCAGCTTCCCTTGTTTGGGTAAGACTCAACCGAACCGAAGCAGGTCGTATATCAAGTTGAAACGGCTGCGTTTCAAAGGTACGGTGAAGATCGAACGTGTCATGTCTGATATGAACATGGATGGTTCTACTTCCAAGGTCGAAGGAGTTTTCTCACTCGTTGTCGTTGTGGATCGAAAACCCCATCTGGGTGCGTCCGGCAGTCTACATACGTTTGATGAACTATTTGGCGCTAGGATCCACAGCCATGGAAACCTCAGCATAACCCCTTCTTTGAAAGACCGGTTTTACATAAGACACGTGTTCAAACGTGTATTGTCTGTGGAGAAGGATAGTATGATGGTTGATGTTGAAGGGTCCACAGCTCTCTCTAACAGGCGTTTCAATTGTTGGTCCACGTTTAAGGATTTGGATCGTGATTCATGTAACGGCGTTTATGGTAACATCAGCAAGAACGCCCTGTTAGTCTACTATTGTTGGATGTCAGATACTATGTCTAGGGCGTCAAGCTTTGTATCGTTTGATCTCGATTATATTGGATGATTAATAAAAAATAAGAATTTATTGCAACGTTTTGGGCTGAGAAGCCTTATAATTACTATTAATACATTCTTGGACCGTAGTCCTTACTAGTTCGTTTAATTGGCCCATGGACATTGTTATGTTTGATTCCGCTCTCCGGGCTCCCACTATTGAAGCAGACTCTCCAGGGTCTAAAATGTTGGTCCCTAGCCTACTTAGATGTCTGTATGGGTGCAGCTCGTTCTCGACCTCTGAGTCCGCATCTGATTGACCCGTTCCCAATGCACTCCTGGAAGCCCAAGACTCACCAGGCTTTATTTCAATTGGGCCTCGGAGCCCAAGTCTTGACATGGATGCACATCTGATGGGCTTCCTTTCCCATCTTCCGTAGTCGACGTGGGAAAAGTCGACATCTTTGTCTGTGAACTGTTTGGATAGGATTTTGACCGTCGGTGCCCTGAACGGAATATCCACTGAATGTTTCGCCGTCGACAATTTCAGTTTCCCTTTGAATTTCGCGAAGTGAGTCCTCTGATGAACATTCGTATCGCAAACTCTGTAATAGAGTTTCCATGGAATTGGGTCTTTGAGCGAAAAGAAGGATGCTGAGAAGTAGTGGAGATCTATGTTGCATCTGATCGGAAAAGTCCATGACGCCTGTAGCGATTCATTTTCCGTCATTCTCTTGTCGTGTATCTCCACAATTACCGTCCCGGTGGCGTTAATCGGAACCTGCTGCCTGTATTCTATGACGCAATGGTCGATCTTCATACAACTCCGACTGAGTCTTGCTGTGAATTGTGACGCCGTTGACGGAAATTGCAGAACGATCTCAGTCAGATCATGTGAAAGCTGATATTCGTCCCTGTGGGACTCTATGTAATTGAAAGCGTTAGGAGGAAATGCTAGCTGAGATTCCATTAGAAAATTAAAGGCCGCGCAGCGGAACCGAAGACTGAAGTTGAACTGTTGATGAACAAATGAAATTTTGTTTGGGAAAACACTCGATGAAGAACTGTTGAAGAAGAATAAGATTTTCTGGGTTTTCCAGAAATTAAGTCAAGAACTAAAGAATATTTGTTTATTCTTTTAAATATGTGTATTGTTTTTGAGAAAGAGGAGAAATCTGGTAAAGATTTCGATTTTTATTATGATTAGATCTGATGTTCTTTATATAGAAAACCCCATTCTTTGTTTTGAGAGCTTTCGGGAGAAGTTATAGACGCATAACCGATGGCATTTTTGTAATAAGAGGGGTGTACTCCGATTGAGCTCTCAAACTTCTGTGCTATGTTTTGGGGTAAAGGGGACAATATATACTAGAAGTCTCTATCGTTGATTAGCGACACGTGGCGGCCATCCGATATAATATT
Gene Information
|
NCBI Accession
|
NP_620745.1
|
|
Location
|
218-973 |
|
Gene Name
|
av1 |
|
Protein Name
|
AV1 protein |
|
Coding Region
|
ATGCCTAAGCGCGATCTACCCTGGCGCTCGATCGCGGGAACTTCGAAGGTGAGCCGCAATGCCAATTATTCCCCTCGTGGAGGAAGTGGGCCTCGAATTAACAAGGCCGCTGAATGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGGACGCTGAGAACGCCTGACGTTCCAAGAGGATGTGAAGGCCCATGTAAGGTCCAGTCCTATGAACAGCGCCACGATATTTCACATACAGGTAAGGTTATGTGCATATCCGACGTGACACGTGGTAATGGTATCACTCACCGTGTGGGTAAGCGTTTCTGTGTTAAGTCTGTGTACATTCTCGGTAAGATCTGGATGGATGAGAACATCAAGCTGAAGAACCACACGAATAGTGTTATGTTCTGGTTGGTCAGGGATCGTAGACCGTATGGCACTCCCATGGATTTCGGTCAAGTGTTCAACATGTTTGACAACGAGCCCAGCACTGCTACGGTGAAGAACGATCTACGCGATCGATTCCAGGTCATGCACAAATTCTATGGGAAGGTGACAGGTGGACAGTATGCCAGCAACGAGCAGGCGATAGTCAAGCGCTTCTGGAAGGTCAACAATCATGTGGTCTACAATCATCAAGAGGCTGGCAAGTACGAGAATCATACGGAGAACGCTTTGTTATTGTACATGGCATGTACGCATGCCTCTAACCCTGTATATGCAACGCTTAAGATCCGGATCTACTTCTATGATTCGATCATGAATTAA |
|
Protein Sequence
|
MPKRDLPWRSIAGTSKVSRNANYSPRGGSGPRINKAAEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSYEQRHDISHTGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYGKVTGGQYASNEQAIVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
|
NCBI Accession
|
NP_620746.1
|
|
Location
|
970-1368 |
|
Gene Name
|
ac3 |
|
Protein Name
|
AC3 protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAATTCATCACTGTACCTCAGGCGGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATGTACAAAGTGGAGGATCTACCGTATACGAGAACCAGGGTTTACCACGTTCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGATGATAGCTTCTGGGTCGACCTATTTAGCTAGGTTTAGACATTTAGTTAATATGTATTTAGATCAGTTAGGCGTTATTTCCATTAACAATGTAATCAGAGCTGTTCGTTTCGCAACAGACAGGTCGTATGTTAGTTATGTACTGGAAAATCATTCAATAAAATTCAAACTTTATTAA |
|
Protein Sequence
|
MDSRTGEFITVPQAENGVYIWEIENPLYFKMYKVEDLPYTRTRVYHVQIRFNHNLRRALHLHKAYLNFQVWTTSMIASGSTYLARFRHLVNMYLDQLGVISINNVIRAVRFATDRSYVSYVLENHSIKFKLY |
|
NCBI Accession
|
NP_620747.1
|
|
Location
|
1115-1504 |
|
Gene Name
|
ac2 |
|
Protein Name
|
AC2 protein |
|
Coding Region
|
ATGCGATCTTCATCACCCTCACATCCGCCCTCTATCAAGACAGCGCACAGGCAAGCCAAGAAAAGGGCCATCAGGAGGAGGCGGATTGATTTACGGTGCGGGTGCTCCATATACTTCCACATAGGCTGCACGGGGCATGGATTCACGCACAGGGGAATTCATCACTGTACCTCAGGCGGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATGTACAAAGTGGAGGATCTACCGTATACGAGAACCAGGGTTTACCACGTTCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGATGATAGCTTCTGGGTCGACCTATTTAGCTAG |
|
Protein Sequence
|
MRSSSPSHPPSIKTAHRQAKKRAIRRRRIDLRCGCSIYFHIGCTGHGFTHRGIHHCTSGGEWRVYLGDRKSPLFQDVQSGGSTVYENQGLPRSDTVQPQPEESVASPQSLPELPSLDDIDDSFWVDLFS |
|
NCBI Accession
|
NP_620748.1
|
|
Location
|
1416-2501 |
|
Gene Name
|
ac1 |
|
Protein Name
|
AC1 protein |
|
Coding Region
|
ATGCCATCGGTTAAACGTTTCAAAGTCTCAGCCAAAAACTATTTCCTCACATATCCCCAGTGCTCTCTTAGCAAAGAAGAAGCACTTTCCCAATTACAAACCCTAAAAACGCCAGTTAACAAGAAATACATCAAGATTTGCAGAGAGTTACATGAGAATGGGGAGCCTCATCTCCACGTTCTCATCCAATTCGAAGGGAAGTACCAGTGCACGAATAACAGATTCTTCGATCTGGTCTCCCCAACCCGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACAGTTGAGTGGGGAGAATTCCAGATCGACGGCAGATCAGCTAGAGGAGGTCAGCAATCTGCTAACGACTCATATGCCAAGGCGTTGAATGCAGGATCTGTTCAATCTGCCATGGCGGTTTTAAAGGAAGAGCAGCCAAAAGATTTTGTCCTGCATAATCATAACATCCGCTCCAACCTAGAGAGAATATTCGCAAAGGCTCCGGAACGGTGGGTTCCTCCGTTTCAACTCTCTTCGTTCACTAACGTTCCAGACGAGATGCAAGAGTGGGCGGATGATTATTTTGGAAGAGGTTCCGCTGCGCGGCCGGAAAGACCTATTAGTATCATCGTGGAAGGTGATTCGAGGACAGGGAAGACGATGTGGGCTAGGGCATTAGGCCCACATAATTACCTAAGTGGTCATCTGGACTTCAACCCAAAGGTCTACTCGAACGAAGTGGAGTATAACGTCATTGATGACGTCGCACCGCACTATCTAAAGTTAAAGCACTGGAAGGAACTTCTGGGGGCCCAGAAGGACTGGCAATCCAATTGCAAGTACGGTAAGCCAGTTCAAATTAAAGGAGGGATCCCAGCAATCGTGCTTTGCAATCCTGGTGAGGGTGCCAGCTATAAAGATTTCCTCAACAAAGAGGAAAACGCATCACTGAGAAATTGGACCATAAAGAATGCGATCTTCATCACCCTCACATCCGCCCTCTATCAAGACAGCGCACAGGCAAGCCAAGAAAAGGGCCATCAGGAGGAGGCGGATTGA |
|
Protein Sequence
|
MPSVKRFKVSAKNYFLTYPQCSLSKEEALSQLQTLKTPVNKKYIKICRELHENGEPHLHVLIQFEGKYQCTNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTVEWGEFQIDGRSARGGQQSANDSYAKALNAGSVQSAMAVLKEEQPKDFVLHNHNIRSNLERIFAKAPERWVPPFQLSSFTNVPDEMQEWADDYFGRGSAARPERPISIIVEGDSRTGKTMWARALGPHNYLSGHLDFNPKVYSNEVEYNVIDDVAPHYLKLKHWKELLGAQKDWQSNCKYGKPVQIKGGIPAIVLCNPGEGASYKDFLNKEENASLRNWTIKNAIFITLTSALYQDSAQASQEKGHQEEAD |
|
NCBI Accession
|
NP_620749.1
|
|
Location
|
2087-2350 |
|
Gene Name
|
ac4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGAGAATGGGGAGCCTCATCTCCACGTTCTCATCCAATTCGAAGGGAAGTACCAGTGCACGAATAACAGATTCTTCGATCTGGTCTCCCCAACCCGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACAGTTGAGTGGGGAGAATTCCAGATCGACGGCAGATCAGCTAGAGGAGGTCAGCAATCTGCTAACGACTCATATGCCAAGGCGTTGA |
|
Protein Sequence
|
MRMGSLISTFSSNSKGSTSARITDSSIWSPQPGQHISIRTYRELNPAPTSSPTSTRTEIQLSGENSRSTADQLEEVSNLLTTHMPRR |
|
NCBI Accession
|
NP_620750.1
|
|
Location
|
457-1227 |
|
Gene Name
|
bv1 |
|
Protein Name
|
BV1 protein |
|
Coding Region
|
ATGTATCCTTTTAGGTCTAAGCGTGGTGCCTCATTTGTTGCACGTCGTTCTTATTCACGTAATAATTTGTTTAAGCGATCAACCATCTCCAAACGAGATGATGGGAGACGTCGATCTGTTAATGCAACTAAACCCAATGACGAGCCCAAGATGATAGCCCAACGCATGCACGAGAATCAGTTTGGGCCAGATTTTGTAATGGCCCATAATGCAGCCTTGGCAACTTTCATCAGCTTCCCTTGTTTGGGTAAGACTCAACCGAACCGAAGCAGGTCGTATATCAAGTTGAAACGGCTGCGTTTCAAAGGTACGGTGAAGATCGAACGTGTCATGTCTGATATGAACATGGATGGTTCTACTTCCAAGGTCGAAGGAGTTTTCTCACTCGTTGTCGTTGTGGATCGAAAACCCCATCTGGGTGCGTCCGGCAGTCTACATACGTTTGATGAACTATTTGGCGCTAGGATCCACAGCCATGGAAACCTCAGCATAACCCCTTCTTTGAAAGACCGGTTTTACATAAGACACGTGTTCAAACGTGTATTGTCTGTGGAGAAGGATAGTATGATGGTTGATGTTGAAGGGTCCACAGCTCTCTCTAACAGGCGTTTCAATTGTTGGTCCACGTTTAAGGATTTGGATCGTGATTCATGTAACGGCGTTTATGGTAACATCAGCAAGAACGCCCTGTTAGTCTACTATTGTTGGATGTCAGATACTATGTCTAGGGCGTCAAGCTTTGTATCGTTTGATCTCGATTATATTGGATGA |
|
Protein Sequence
|
MYPFRSKRGASFVARRSYSRNNLFKRSTISKRDDGRRRSVNATKPNDEPKMIAQRMHENQFGPDFVMAHNAALATFISFPCLGKTQPNRSRSYIKLKRLRFKGTVKIERVMSDMNMDGSTSKVEGVFSLVVVVDRKPHLGASGSLHTFDELFGARIHSHGNLSITPSLKDRFYIRHVFKRVLSVEKDSMMVDVEGSTALSNRRFNCWSTFKDLDRDSCNGVYGNISKNALLVYYCWMSDTMSRASSFVSFDLDYIG |
|
NCBI Accession
|
NP_620751.1
|
|
Location
|
1246-2127 |
|
Gene Name
|
bc1 |
|
Protein Name
|
BC1 protein |
|
Coding Region
|
ATGGAATCTCAGCTAGCATTTCCTCCTAACGCTTTCAATTACATAGAGTCCCACAGGGACGAATATCAGCTTTCACATGATCTGACTGAGATCGTTCTGCAATTTCCGTCAACGGCGTCACAATTCACAGCAAGACTCAGTCGGAGTTGTATGAAGATCGACCATTGCGTCATAGAATACAGGCAGCAGGTTCCGATTAACGCCACCGGGACGGTAATTGTGGAGATACACGACAAGAGAATGACGGAAAATGAATCGCTACAGGCGTCATGGACTTTTCCGATCAGATGCAACATAGATCTCCACTACTTCTCAGCATCCTTCTTTTCGCTCAAAGACCCAATTCCATGGAAACTCTATTACAGAGTTTGCGATACGAATGTTCATCAGAGGACTCACTTCGCGAAATTCAAAGGGAAACTGAAATTGTCGACGGCGAAACATTCAGTGGATATTCCGTTCAGGGCACCGACGGTCAAAATCCTATCCAAACAGTTCACAGACAAAGATGTCGACTTTTCCCACGTCGACTACGGAAGATGGGAAAGGAAGCCCATCAGATGTGCATCCATGTCAAGACTTGGGCTCCGAGGCCCAATTGAAATAAAGCCTGGTGAGTCTTGGGCTTCCAGGAGTGCATTGGGAACGGGTCAATCAGATGCGGACTCAGAGGTCGAGAACGAGCTGCACCCATACAGACATCTAAGTAGGCTAGGGACCAACATTTTAGACCCTGGAGAGTCTGCTTCAATAGTGGGAGCCCGGAGAGCGGAATCAAACATAACAATGTCCATGGGCCAATTAAACGAACTAGTAAGGACTACGGTCCAAGAATGTATTAATAGTAATTATAAGGCTTCTCAGCCCAAAACGTTGCAATAA |
|
Protein Sequence
|
MESQLAFPPNAFNYIESHRDEYQLSHDLTEIVLQFPSTASQFTARLSRSCMKIDHCVIEYRQQVPINATGTVIVEIHDKRMTENESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGRWERKPIRCASMSRLGLRGPIEIKPGESWASRSALGTGQSDADSEVENELHPYRHLSRLGTNILDPGESASIVGARRAESNITMSMGQLNELVRTTVQECINSNYKASQPKTLQ |