Chino del tomate Amazonas virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002821945.1 |
| Isolate |
Brazil |
| Release date |
2018/8/25 |
| Submitter |
Fonseca,M.E.N., Boiteux,L.S., Fernandes,N.A.N., Costa,A.F. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
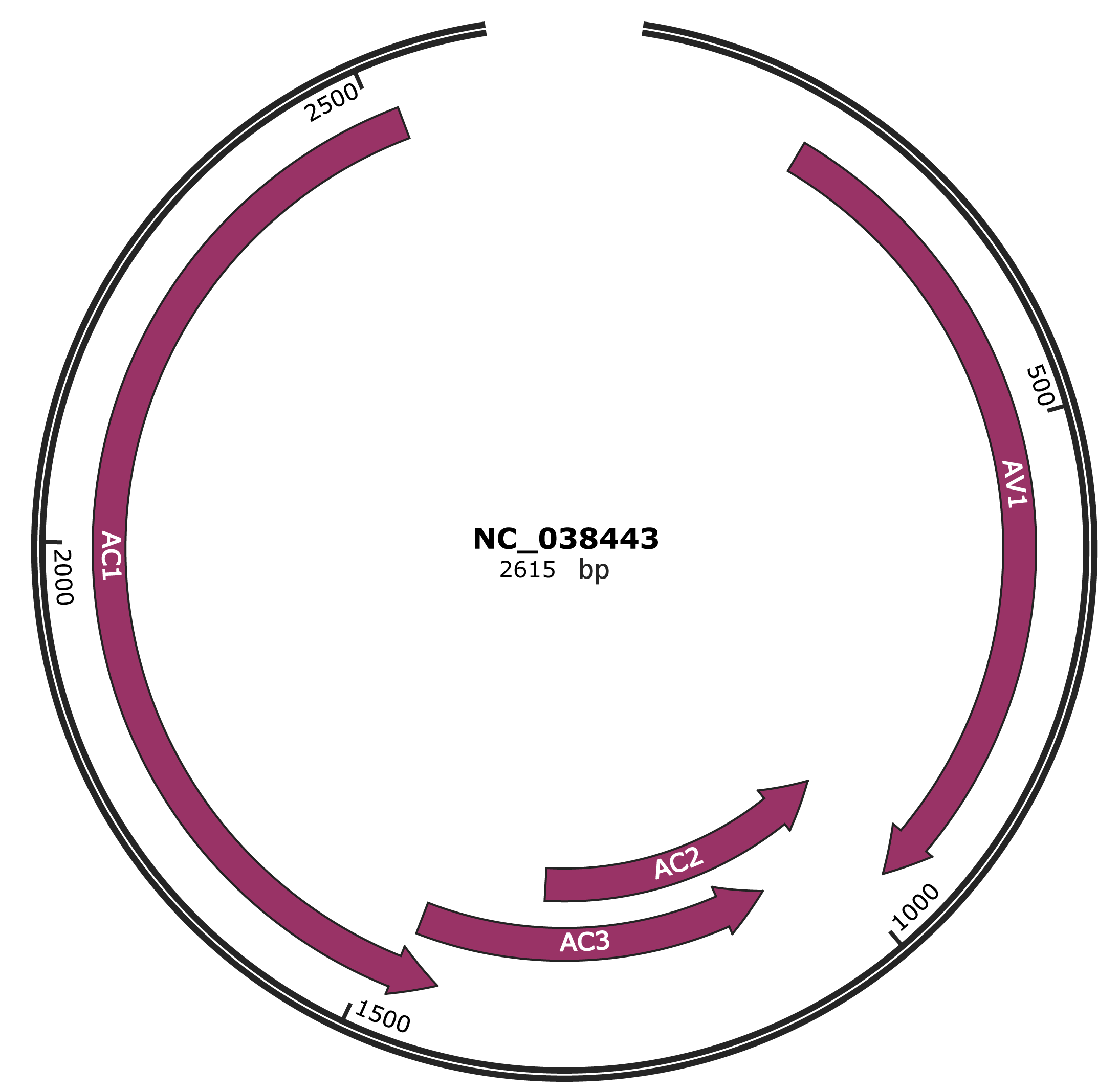
JBrowse
Genome
ACCGGATGGCCGCGCTTTTTTTGTCCTGGCCTTTAATTTCGAATTAAAGGTGGTCCTTCGCACTTTCGTCCAATTATATCGCGCCTGATGTGTCTAGATATTTTAAACAACTTGGGAGCCAAGTTGTGATGTCGATATAAAGGAAAGGACCACTGGGCCACATGCTTCATGTCGAAATGCCGAAGCGCGATCTCCCATGGCGCTCGATGGCGGGAACCTCTAAGGTCAGCCGCAATGTCAACTCCTCGCCTCGTGCAGGTATCGGCCCAAAACTCAACAAGGCCTCTGAATGGGTCAACAGGCCCATGTATAGGAAGCCCAGGATCTATCGCACGCTCAGATCTCCCGATGTGCCTAGAGGGTGTGAAGGGCCGTGTAAGGTCCAGTCCTTATGAACCAGGCGCCACGAACATATCACATGTCGGCAAGGTAATGTGTATTTCTGACGTGACACGTGGTAATGGCATTACCCACCGTGTGGGTAAGCGTTTTTGTGTTAAGTCTGTGTACATTCTAGGTAAGATATGGATGGATGAGAACATCAAGCTGAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTTAGAGACCGTAGACCGTATGGAACGCCCATGGATTTTGGACAAGTGTTCAACATGTTCGACAACGAACCTAGCACTGCCACGATCAAGAACGATCTCCGTGATCGTTACCAGGTCATGCACAGGTTCTATGGGAAGGTGACAGGTGGACAGTATGCGAGCAACGAGCAGGCTATTGTCAGGCGATTCTGGAAGGTCAACAATCATGTGGTCTACAATCATCAGGAGGCTGGAAAGTATGAGAATCACACAGAGAATGCTTTGTTACTGTACATGGCATGCACTCATGCCTCAAACCCTGTATATGCTACTCTGAAGATCCGGATCTATTTTTATGATTCGGGTTTCAAATTAATAAAATTTGAATTTTATTTAATGATTCTCTAGTACAGAAGTTACATAACGTTTGTCTGTTGCGAATTGAACAGCTCTAATTACATTATTAATGGAAATAACACCTAACTGGTCTAAGTACAACATAACTAAATGCCTAAATTTATTTAAATATGTCGTCCCAGAAGCTGTCACTGATGTCGTCCAGACTTGGAAATTCAGGATGGCTTTGTGTAGATTCAACTCCTTCCTGAGGTTGTGATTGAACCGTATTTGTATGTGATACACCCTGGAGTTCGTGTACATGGGTGTCTCTACGTTGTATATCTTGAAATATAGGGGATTTGTTATCTCCCAGATATACACGCCATTCTCTGCCTGATGTGCAGTGATGAGTTCCTCTGTGCGTGAATCCATGCCCAGTGCAGCCTATGTGGAGGTAGATGGAGCAACCGCACTCTAGATCAATGCGCCTCCTCCTGATGGCCCTCTTCTTGGCTTGCCTGTGTGCTCTCTTTATTGAGGGGGGAGCTGAGGGTGATGAAGAGCGCATTCTTGAGGGTCCAGTTCCTGAGTGATGCGTTTTCCTCTTTGTTGAGGAAATCTTGATAGCTGGAACCCTGACCCTGGATTGCAAAGCACGATTGATGGGATTCCTCCTTGAATTTGAACTGGCTTGCCGTACTTGCAATTTGACTGCCAGTCTTTTTGTGACCCAATCAATTCTTTCCAGTGCTTTAGCTTTAGATAGTGCGGTGCGACGGCAGCAATGACGGTATACTCCACTTGATTTGAATAGACCGTACCATTGAAATCCAGATGTCCACTCAGATAGGTATGTGGGCCTAACGCACGAGCCCACATTGTCTTTCCTGTTCTTGAATTCACCCTCGATGATGATACTAATCGGTCTCTCCGGCCGCGCAGCGGCACCTCTCCCGAAATAATTATCTGCCCACTCTTGCATCTCTTCTGGAACGTTAGTGAATGAGGAGAGGGGAAACGGAGGAATCCATGGTTCCGGAGCCTTAGCAAAAATCCTTTCTGCATTTGCTTTGAGATTATGATAATTTGCAAAAAAGTCTCTGGGTTGTTCCTCTCTGAATATATTGAGGGCCTGGGTTGCATCGCCTGCATTGAGAGCCTTGGCATAAGAGTCGTTGGCAGATTGGCAACCTCCTCTAGCTGATCGTCCATCGATCTGGAAAACTCCATGATCAATGAAGTCTCCGTCTTTCTCCATATAGGCTTTGACGTCTGAGCTTGCTTCTTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGATCTGGTTGGGGATACCAAGTCGAAGAATCTGTTGTTGGTGCATTGGTATTTCCCTTCGAATTGGATAAGCACATGGAGATGAGGCTCCCCATTCTCGTGAAGCTCTCTTGCAACACGAATGAATAATTTGTTAGTTGGGGTTTGAAGGTTGATGAATTGGGAAAGTGCATCGTCTTTGGTGAGAGAGCAATGAGGATAAGTAAGGAAATAGTTTTTGGAAGAGATTTTGAAACGCTTGGGTGGTGGCATTTTGGTAATATAGGCTTGTCCCCCCAGTTGGAGCTCTCTGAAAACTGTGACATGAATTGGGGTAATGGGGTACATTATATAGTAGAAGTCTCAATAGAACTTCGTATCTGAATCCGCACACGTGGCGGCCATCCGTTATAATATT
Gene Information
|
NCBI Accession
|
YP_009506396.1
|
|
Location
|
169-969 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAATGCCGAAGCGCGATCTCCCATGGCGCTCGATGGCGGGAACCTCTAAGGTCAGCCGCAATGTCAACTCCTCGCCTCGTGCAGGTATCGGCCCAAAACTCAACAAGGCCTCTGAATGGGTCAACAGGCCCATGTATAGGAAGCCCAGGATCTATCGCACGCTCAGATCTCCCGATGTGCCTAGAGGGTGTGAAGGGCCGTGTAAGGTCCAGTCCTTATGAACCAGGCGCCACGAACATATCACATGTCGGCAAGGTAATGTGTATTTCTGACGTGACACGTGGTAATGGCATTACCCACCGTGTGGGTAAGCGTTTTTGTGTTAAGTCTGTGTACATTCTAGGTAAGATATGGATGGATGAGAACATCAAGCTGAAGAACCACACGAACAGTGTCATGTTCTGGTTGGTTAGAGACCGTAGACCGTATGGAACGCCCATGGATTTTGGACAAGTGTTCAACATGTTCGACAACGAACCTAGCACTGCCACGATCAAGAACGATCTCCGTGATCGTTACCAGGTCATGCACAGGTTCTATGGGAAGGTGACAGGTGGACAGTATGCGAGCAACGAGCAGGCTATTGTCAGGCGATTCTGGAAGGTCAACAATCATGTGGTCTACAATCATCAGGAGGCTGGAAAGTATGAGAATCACACAGAGAATGCTTTGTTACTGTACATGGCATGCACTCATGCCTCAAACCCTGTATATGCTACTCTGAAGATCCGGATCTATTTTTATGATTCGGGTTTCAAATTAATAAAATTTGAATTTTATTTAATGATTCTCTAG |
|
Protein Sequence
|
MSKCRSAISHGARWREPLRSAAMSTPRLVQVSAQNSTRPLNGSTGPCIGSPGSIARSDLPMCLEGVKGRVRSSPYEPGATNISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATIKNDLRDRYQVMHRFYGKVTGGQYASNEQAIVRRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSGFKLIKFEFYLMIL |
|
NCBI Accession
|
YP_009506397.1
|
|
Location
|
955-1332 |
|
Gene Name
|
AC2 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGAGGAACTCATCACTGCACATCAGGCAGAGAATGGCGTGTATATCTGGGAGATAACAAATCCCCTATATTTCAAGATATACAACGTAGAGACACCCATGTACACGAACTCCAGGGTGTATCACATACAAATACGGTTCAATCACAACCTCAGGAAGGAGTTGAATCTACACAAAGCCATCCTGAATTTCCAAGTCTGGACGACATCAGTGACAGCTTCTGGGACGACATATTTAAATAAATTTAGGCATTTAGTTATGTTGTACTTAGACCAGTTAGGTGTTATTTCCATTAATAATGTAATTAGAGCTGTTCAATTCGCAACAGACAAACGTTATGTAACTTCTGTACTAGAGAATCATTAA |
|
Protein Sequence
|
MDSRTEELITAHQAENGVYIWEITNPLYFKIYNVETPMYTNSRVYHIQIRFNHNLRKELNLHKAILNFQVWTTSVTASGTTYLNKFRHLVMLYLDQLGVISINNVIRAVQFATDKRYVTSVLENH |
|
NCBI Accession
|
YP_009506398.1
|
|
Location
|
1079-1468 |
|
Gene Name
|
AC3 |
|
Protein Name
|
transactivator protein |
|
Coding Region
|
ATGCGCTCTTCATCACCCTCAGCTCCCCCCTCAATAAAGAGAGCACACAGGCAAGCCAAGAAGAGGGCCATCAGGAGGAGGCGCATTGATCTAGAGTGCGGTTGCTCCATCTACCTCCACATAGGCTGCACTGGGCATGGATTCACGCACAGAGGAACTCATCACTGCACATCAGGCAGAGAATGGCGTGTATATCTGGGAGATAACAAATCCCCTATATTTCAAGATATACAACGTAGAGACACCCATGTACACGAACTCCAGGGTGTATCACATACAAATACGGTTCAATCACAACCTCAGGAAGGAGTTGAATCTACACAAAGCCATCCTGAATTTCCAAGTCTGGACGACATCAGTGACAGCTTCTGGGACGACATATTTAAATAA |
|
Protein Sequence
|
MRSSSPSAPPSIKRAHRQAKKRAIRRRRIDLECGCSIYLHIGCTGHGFTHRGTHHCTSGREWRVYLGDNKSPIFQDIQRRDTHVHELQGVSHTNTVQSQPQEGVESTQSHPEFPSLDDISDSFWDDIFK |
|
NCBI Accession
|
YP_009506399.1
|
|
Location
|
1432-2523 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGTCACAGTTTTCAGAGAGCTCCAACTGGGGGGACAAGCCTATATTACCAAAATGCCACCACCCAAGCGTTTCAAAATCTCTTCCAAAAACTATTTCCTTACTTATCCTCATTGCTCTCTCACCAAAGACGATGCACTTTCCCAATTCATCAACCTTCAAACCCCAACTAACAAATTATTCATTCGTGTTGCAAGAGAGCTTCACGAGAATGGGGAGCCTCATCTCCATGTGCTTATCCAATTCGAAGGGAAATACCAATGCACCAACAACAGATTCTTCGACTTGGTATCCCCAACCAGATCAGCACATTTCCATCCGAACATTCAGGGAGCTAAAGAAGCAAGCTCAGACGTCAAAGCCTATATGGAGAAAGACGGAGACTTCATTGATCATGGAGTTTTCCAGATCGATGGACGATCAGCTAGAGGAGGTTGCCAATCTGCCAACGACTCTTATGCCAAGGCTCTCAATGCAGGCGATGCAACCCAGGCCCTCAATATATTCAGAGAGGAACAACCCAGAGACTTTTTTGCAAATTATCATAATCTCAAAGCAAATGCAGAAAGGATTTTTGCTAAGGCTCCGGAACCATGGATTCCTCCGTTTCCCCTCTCCTCATTCACTAACGTTCCAGAAGAGATGCAAGAGTGGGCAGATAATTATTTCGGGAGAGGTGCCGCTGCGCGGCCGGAGAGACCGATTAGTATCATCATCGAGGGTGAATTCAAGAACAGGAAAGACAATGTGGGCTCGTGCGTTAGGCCCACATACCTATCTGAGTGGACATCTGGATTTCAATGGTACGGTCTATTCAAATCAAGTGGAGTATACCGTCATTGCTGCCGTCGCACCGCACTATCTAAAGCTAAAGCACTGGAAAGAATTGATTGGGTCACAAAAAGACTGGCAGTCAAATTGCAAGTACGGCAAGCCAGTTCAAATTCAAGGAGGAATCCCATCAATCGTGCTTTGCAATCCAGGGTCAGGGTTCCAGCTATCAAGATTTCCTCAACAAAGAGGAAAACGCATCACTCAGGAACTGGACCCTCAAGAATGCGCTCTTCATCACCCTCAGCTCCCCCCTCAATAA |
|
Protein Sequence
|
MSQFSESSNWGDKPILPKCHHPSVSKSLPKTISLLILIALSPKTMHFPNSSTFKPQLTNYSFVLQESFTRMGSLISMCLSNSKGNTNAPTTDSSTWYPQPDQHISIRTFRELKKQAQTSKPIWRKTETSLIMEFSRSMDDQLEEVANLPTTLMPRLSMQAMQPRPSIYSERNNPETFLQIIIISKQMQKGFLLRLRNHGFLRFPSPHSLTFQKRCKSGQIIISGEVPLRGRRDRLVSSSRVNSRTGKTMWARALGPHTYLSGHLDFNGTVYSNQVEYTVIAAVAPHYLKLKHWKELIGSQKDWQSNCKYGKPVQIQGGIPSIVLCNPGSGFQLSRFPQQRGKRITQELDPQECALHHPQLPPQ |