Chilli leaf curl Sri Lanka virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_004786955.1 |
| Isolate |
Sri Lanka: Nochchiyagama |
| Release date |
2021/6/1 |
| Submitter |
Senanayake,D.M., Mandal,B., Jayasinghe,J.E., Wasala,S.K. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
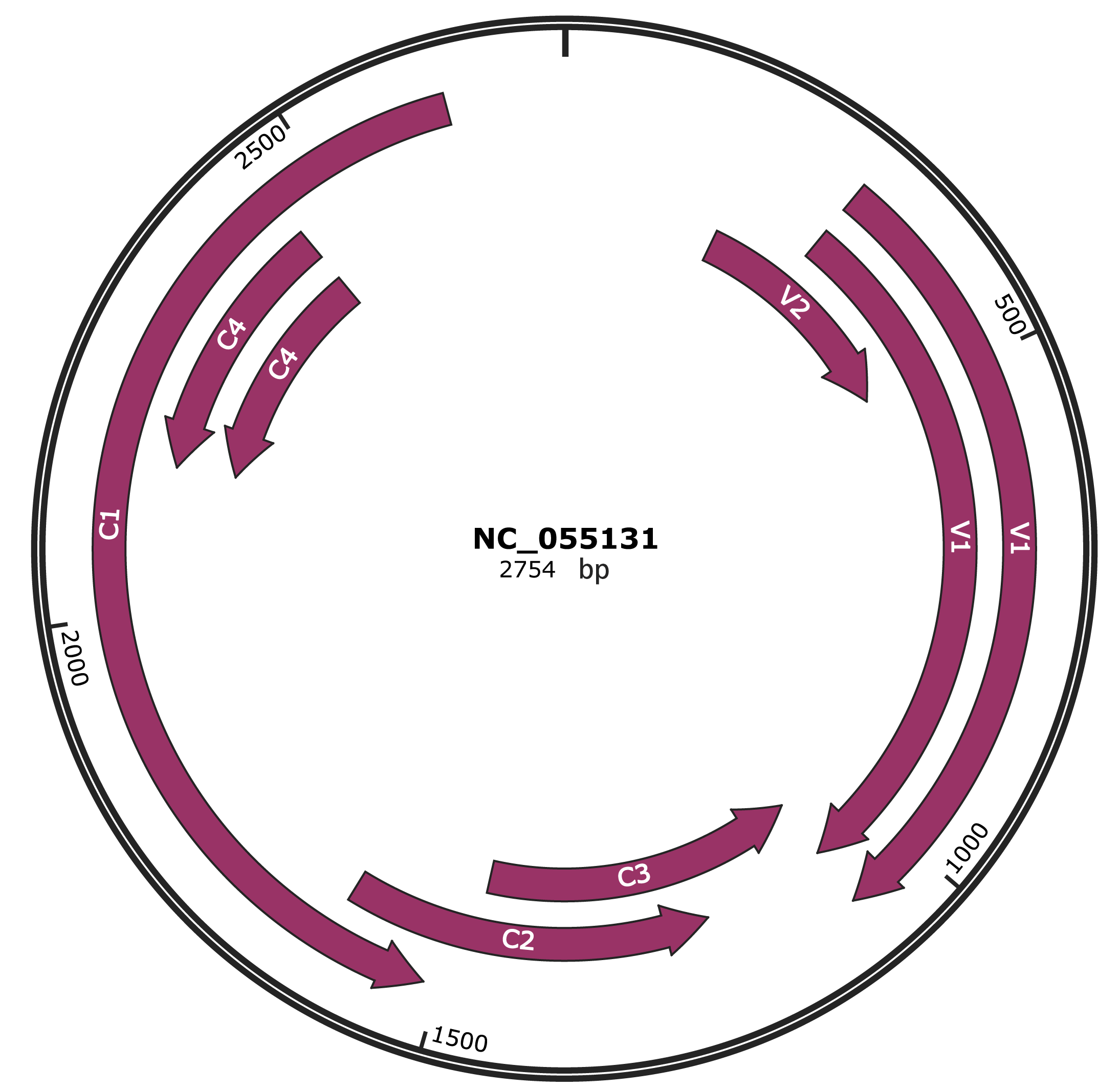
JBrowse
Genome
ACCGGATGGCCGCGCCCCTTTCTGTCGCTTTCATGGTCCCCCCGTGTGTCTTTTCCCCACCACATATGTGCCCCCGTCAAAGCTTAATTATTCATGTGGGCCCCTATATAAACTTGGTGACCAAGTTTTACATTCATTTACAATGTAGGATCCACTTGTAAATGATTTTCCTGAAACCGTACACGGGTTCAGGTGTATGCTTGCAATTAAATACTTGCAACTTGTAGAAAATACGTATTCCCCTGATTCTCTGGGATACGACTTGATACGAGAATTAATATCCGTAGTTCGTGCCAAAAATTATGTCCAAGCGTCCGGCAGATATGATCATTTCAGGACCCGCCTCGAAGTATCGTCGACTGCTGACCTCAACCAGCCCATACAGCCGACGTGCTGCTGTCCGCATTGTCCGCGCCACAAAGGGAAAGGAATGGGCCAACAGGCCCATGAATCGGAAGCCCATGTTCTACAGAATGTACAGAAGCCCTGATGTTCCCAAGGGATGTGAAGGCCCATGTAAGGTCCAGTCTTTCGAGTCTAGGCATGACGTAGTTCATATTGGTAAGGTTATGTGTATTAGTGATGTTACTAGGGGTACGGGTCTGACCCATAGGGTAGGTAAGCGTTTCTGCGTTAAGTCTGTCTATGTTCTGGGCAAGATATGGATGGATGAGAACATCAAAACCAAGAACCACACTAACAGTGTTATGTTCTTCCTTGTTCGTGATCGTCGTCCAGTTGATAAACCTCAAGATTTTGGTGATGTGTTTAACATGTTCGACAACGAGCCGAGCACTGCAACGGTCAAGAATATGCACAGGGATCGTTACCAGGTTCTCAGGAAGTGGCATGCAACCGTGACTGGTGGTCAATATGCGTCTAAGGAGCAGGCTCTCGTGAAGAAATTTGTTAGGGTTAATAATTATGTTGTGTATAACCAGCAAGAGGCTGGCAAGTATGAGAATCACAGTGAGAATGCGTTGATGTTGTATATGGCATGTACGCATGCCTCAAACCCCGTGTATGCTACTCTGAAAATACGAATCTATTTCTACGATTCGGTTACAAATTAATAAACATTGAATTTTATTATGTTTGAACTCTGTACATAGACTGTTTGCGTTAATACATTCCACAATACATGATCGACTGCCCTAATTACATTGTTGAGGCTAATTACAGCAAAATTATTGATACATTTTAACACTTGGGTCCTAAACACCCTTAAGAAATGACCAGTCTGAGGCTGTAAGGTCGTCCAGATTCGGAAGGTTAGAAAACATTTGTGTATCCCCAACGCTTTCCGAAGGTTGTGGTTGAACTGGACCCTGATAGTTATCAGGTCCGTGTTGGAGTTGAATGGCCTGCTGTCGTGGCTGAGGATCTTGAAATATAGGGGATTTGGGACCTGCAAGATACTGACGCCATTCGTTGCCTGAGCTGCAGTGATGCGTTCCCCTGTGCGTAAATCCATGGTTCCTGCAGTTGATATGGATGTAGTAGGAACAACCACAGTCAAGGTCCACCCTCTTCCTCCTGATGGACCTCTTGGCTTGCCTGTGGAGAACCTTGATTGGTACCTGAGTATAGTGGGCCTGTGAGGGTGACGAAGATTGCATTCTTGAGTGCCCAATGTTTTAGTGCGGAATGCTTTTCTTCGTCCAGGAACTCTTTATAGCTGGAGTTGGGCCCTGGATTGCAGAGGAAGATAGTGGGAATGCCACCTTTAATTTGAACTGGCTTTCCGTATTTGGTGTTGGACTGCCAGTCCCTTTGGGCCCCCATGAACTCTTTAAAGTGTTTTAAATAATGCGGATCCACATCATCAATGACGTTATACCATGCGTCATTTGAATACACTCTTGGGCTTAAGTCCAAGTGGCCACACAAATAATTGTGAGGGCCGAGGGACCTAGCCCACATTGTTTTGCCGGTCCGACTATCACCCTCAATAACAATTCCTATGGGCCTAATAGGCCGCGCAGCGGCAGTGACAACATTAACTGCAGCCCATTCTTCAAGTTCATCAGGAACTTGATCAAAAGAAGAAATAGAAAAAGGAGAAATATAAACCTCTCTTGGAGGTGCAAAAATCCTATCTAAATTAGACTTTAAATTATGATATTGAAAAATAAAATCTTTAGGGAGTTTCTCCCTTATTATTGCCAAAGCGGCATCAGCGGATCCTGAATTGAGGGCCTCTGCTGCAGCATCATTAGCTGTCTGTTGACCTCCTCTAGCAGATCTTCCATCGAGCTGAAAATCACCCCAGTCGATGTAATCACCGTCCTTCTCGATGTAGGACTTGACATCGGATGAGGACTTAGCTCCCTGGAAGTTTGGATGGAATTGGGATGAGGTGTTAGGGTGAGTGACATCGAAATGTCTGGGGTTTCTGAACTGGGCTTTACCCTTGAACTGGATGAGGGCATGGATATGCAGAGACCCATCTTGGTGTTTTTCCTGAGCAACCCGTATAAATAGTTTATCAGATGGACAGTTAATGCCCTTAATAAGTTCTAACATTTGTTCTTTGGGTATTGGGCATTTGGGGTATGTTAAAAAAATATTTTTAGCCTGAACTTGAAACGACCGTGTTTTAGGCATTTTGAATTGGACAATTGGCTCTCCAAACTCCATGTGGGAATTGGAGGCTTTGGAGGCTCATTTATACCAAGCCTCCAAATGGCAGTATGGTAATTTTTTAGAAATTTCAATCAACTTCCCGCCAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_010084340.1
|
|
Location
|
197-490 |
|
Gene Name
|
V2 |
|
Protein Name
|
V2 protein |
|
Coding Region
|
ATGCTTGCAATTAAATACTTGCAACTTGTAGAAAATACGTATTCCCCTGATTCTCTGGGATACGACTTGATACGAGAATTAATATCCGTAGTTCGTGCCAAAAATTATGTCCAAGCGTCCGGCAGATATGATCATTTCAGGACCCGCCTCGAAGTATCGTCGACTGCTGACCTCAACCAGCCCATACAGCCGACGTGCTGCTGTCCGCATTGTCCGCGCCACAAAGGGAAAGGAATGGGCCAACAGGCCCATGAATCGGAAGCCCATGTTCTACAGAATGTACAGAAGCCCTGA |
|
Protein Sequence
|
MLAIKYLQLVENTYSPDSLGYDLIRELISVVRAKNYVQASGRYDHFRTRLEVSSTADLNQPIQPTCCCPHCPRHKGKGMGQQAHESEAHVLQNVQKP |
|
NCBI Accession
|
YP_010084341.1
|
|
Location
|
303-1073 |
|
Gene Name
|
V1 |
|
Protein Name
|
V1 protein |
|
Coding Region
|
ATGTCCAAGCGTCCGGCAGATATGATCATTTCAGGACCCGCCTCGAAGTATCGTCGACTGCTGACCTCAACCAGCCCATACAGCCGACGTGCTGCTGTCCGCATTGTCCGCGCCACAAAGGGAAAGGAATGGGCCAACAGGCCCATGAATCGGAAGCCCATGTTCTACAGAATGTACAGAAGCCCTGATGTTCCCAAGGGATGTGAAGGCCCATGTAAGGTCCAGTCTTTCGAGTCTAGGCATGACGTAGTTCATATTGGTAAGGTTATGTGTATTAGTGATGTTACTAGGGGTACGGGTCTGACCCATAGGGTAGGTAAGCGTTTCTGCGTTAAGTCTGTCTATGTTCTGGGCAAGATATGGATGGATGAGAACATCAAAACCAAGAACCACACTAACAGTGTTATGTTCTTCCTTGTTCGTGATCGTCGTCCAGTTGATAAACCTCAAGATTTTGGTGATGTGTTTAACATGTTCGACAACGAGCCGAGCACTGCAACGGTCAAGAATATGCACAGGGATCGTTACCAGGTTCTCAGGAAGTGGCATGCAACCGTGACTGGTGGTCAATATGCGTCTAAGGAGCAGGCTCTCGTGAAGAAATTTGTTAGGGTTAATAATTATGTTGTGTATAACCAGCAAGAGGCTGGCAAGTATGAGAATCACAGTGAGAATGCGTTGATGTTGTATATGGCATGTACGCATGCCTCAAACCCCGTGTATGCTACTCTGAAAATACGAATCTATTTCTACGATTCGGTTACAAATTAA |
|
Protein Sequence
|
MSKRPADMIISGPASKYRRLLTSTSPYSRRAAVRIVRATKGKEWANRPMNRKPMFYRMYRSPDVPKGCEGPCKVQSFESRHDVVHIGKVMCISDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNSVMFFLVRDRRPVDKPQDFGDVFNMFDNEPSTATVKNMHRDRYQVLRKWHATVTGGQYASKEQALVKKFVRVNNYVVYNQQEAGKYENHSENALMLYMACTHASNPVYATLKIRIYFYDSVTN |
|
NCBI Accession
|
YP_010084342.1
|
|
Location
|
1070-1474 |
|
Gene Name
|
C3 |
|
Protein Name
|
C3 protein |
|
Coding Region
|
ATGGATTTACGCACAGGGGAACGCATCACTGCAGCTCAGGCAACGAATGGCGTCAGTATCTTGCAGGTCCCAAATCCCCTATATTTCAAGATCCTCAGCCACGACAGCAGGCCATTCAACTCCAACACGGACCTGATAACTATCAGGGTCCAGTTCAACCACAACCTTCGGAAAGCGTTGGGGATACACAAATGTTTTCTAACCTTCCGAATCTGGACGACCTTACAGCCTCAGACTGGTCATTTCTTAAGGGTGTTTAGGACCCAAGTGTTAAAATGTATCAATAATTTTGCTGTAATTAGCCTCAACAATGTAATTAGGGCAGTCGATCATGTATTGTGGAATGTATTAACGCAAACAGTCTATGTACAGAGTTCAAACATAATAAAATTCAATGTTTATTAA |
|
Protein Sequence
|
MDLRTGERITAAQATNGVSILQVPNPLYFKILSHDSRPFNSNTDLITIRVQFNHNLRKALGIHKCFLTFRIWTTLQPQTGHFLRVFRTQVLKCINNFAVISLNNVIRAVDHVLWNVLTQTVYVQSSNIIKFNVY |
|
NCBI Accession
|
YP_010084343.1
|
|
Location
|
1215-1619 |
|
Gene Name
|
C2 |
|
Protein Name
|
C2 protein |
|
Coding Region
|
ATGCAATCTTCGTCACCCTCACAGGCCCACTATACTCAGGTACCAATCAAGGTTCTCCACAGGCAAGCCAAGAGGTCCATCAGGAGGAAGAGGGTGGACCTTGACTGTGGTTGTTCCTACTACATCCATATCAACTGCAGGAACCATGGATTTACGCACAGGGGAACGCATCACTGCAGCTCAGGCAACGAATGGCGTCAGTATCTTGCAGGTCCCAAATCCCCTATATTTCAAGATCCTCAGCCACGACAGCAGGCCATTCAACTCCAACACGGACCTGATAACTATCAGGGTCCAGTTCAACCACAACCTTCGGAAAGCGTTGGGGATACACAAATGTTTTCTAACCTTCCGAATCTGGACGACCTTACAGCCTCAGACTGGTCATTTCTTAAGGGTGTTTAG |
|
Protein Sequence
|
MQSSSPSQAHYTQVPIKVLHRQAKRSIRRKRVDLDCGCSYYIHINCRNHGFTHRGTHHCSSGNEWRQYLAGPKSPIFQDPQPRQQAIQLQHGPDNYQGPVQPQPSESVGDTQMFSNLPNLDDLTASDWSFLKGV |
|
NCBI Accession
|
YP_010084344.1
|
|
Location
|
1516-2640 |
|
Gene Name
|
C1 |
|
Protein Name
|
Rep protein |
|
Coding Region
|
ATGGAGTTTGGAGAGCCAATTGTCCAATTCAAAATGCCTAAAACACGGTCGTTTCAAGTTCAGGCTAAAAATATTTTTTTAACATACCCCAAATGCCCAATACCCAAAGAACAAATGTTAGAACTTATTAAGGGCATTAACTGTCCATCTGATAAACTATTTATACGGGTTGCTCAGGAAAAACACCAAGATGGGTCTCTGCATATCCATGCCCTCATCCAGTTCAAGGGTAAAGCCCAGTTCAGAAACCCCAGACATTTCGATGTCACTCACCCTAACACCTCATCCCAATTCCATCCAAACTTCCAGGGAGCTAAGTCCTCATCCGATGTCAAGTCCTACATCGAGAAGGACGGTGATTACATCGACTGGGGTGATTTTCAGCTCGATGGAAGATCTGCTAGAGGAGGTCAACAGACAGCTAATGATGCTGCAGCAGAGGCCCTCAATTCAGGATCCGCTGATGCCGCTTTGGCAATAATAAGGGAGAAACTCCCTAAAGATTTTATTTTTCAATATCATAATTTAAAGTCTAATTTAGATAGGATTTTTGCACCTCCAAGAGAGGTTTATATTTCTCCTTTTTCTATTTCTTCTTTTGATCAAGTTCCTGATGAACTTGAAGAATGGGCTGCAGTTAATGTTGTCACTGCCGCTGCGCGGCCTATTAGGCCCATAGGAATTGTTATTGAGGGTGATAGTCGGACCGGCAAAACAATGTGGGCTAGGTCCCTCGGCCCTCACAATTATTTGTGTGGCCACTTGGACTTAAGCCCAAGAGTGTATTCAAATGACGCATGGTATAACGTCATTGATGATGTGGATCCGCATTATTTAAAACACTTTAAAGAGTTCATGGGGGCCCAAAGGGACTGGCAGTCCAACACCAAATACGGAAAGCCAGTTCAAATTAAAGGTGGCATTCCCACTATCTTCCTCTGCAATCCAGGGCCCAACTCCAGCTATAAAGAGTTCCTGGACGAAGAAAAGCATTCCGCACTAAAACATTGGGCACTCAAGAATGCAATCTTCGTCACCCTCACAGGCCCACTATACTCAGGTACCAATCAAGGTTCTCCACAGGCAAGCCAAGAGGTCCATCAGGAGGAAGAGGGTGGACCTTGA |
|
Protein Sequence
|
MEFGEPIVQFKMPKTRSFQVQAKNIFLTYPKCPIPKEQMLELIKGINCPSDKLFIRVAQEKHQDGSLHIHALIQFKGKAQFRNPRHFDVTHPNTSSQFHPNFQGAKSSSDVKSYIEKDGDYIDWGDFQLDGRSARGGQQTANDAAAEALNSGSADAALAIIREKLPKDFIFQYHNLKSNLDRIFAPPREVYISPFSISSFDQVPDELEEWAAVNVVTAAARPIRPIGIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPRVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEEKHSALKHWALKNAIFVTLTGPLYSGTNQGSPQASQEVHQEEEGGP |
|
NCBI Accession
|
YP_010084345.1
|
|
Location
|
2160-2450 |
|
Gene Name
|
C4 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGGTCTCTGCATATCCATGCCCTCATCCAGTTCAAGGGTAAAGCCCAGTTCAGAAACCCCAGACATTTCGATGTCACTCACCCTAACACCTCATCCCAATTCCATCCAAACTTCCAGGGAGCTAAGTCCTCATCCGATGTCAAGTCCTACATCGAGAAGGACGGTGATTACATCGACTGGGGTGATTTTCAGCTCGATGGAAGATCTGCTAGAGGAGGTCAACAGACAGCTAATGATGCTGCAGCAGAGGCCCTCAATTCAGGATCCGCTGATGCCGCTTTGGCAATAA |
|
Protein Sequence
|
MGLCISMPSSSSRVKPSSETPDISMSLTLTPHPNSIQTSRELSPHPMSSPTSRRTVITSTGVIFSSMEDLLEEVNRQLMMLQQRPSIQDPLMPLWQ |