Tomato geminivirus 1
Basic Information
Genomic Organization
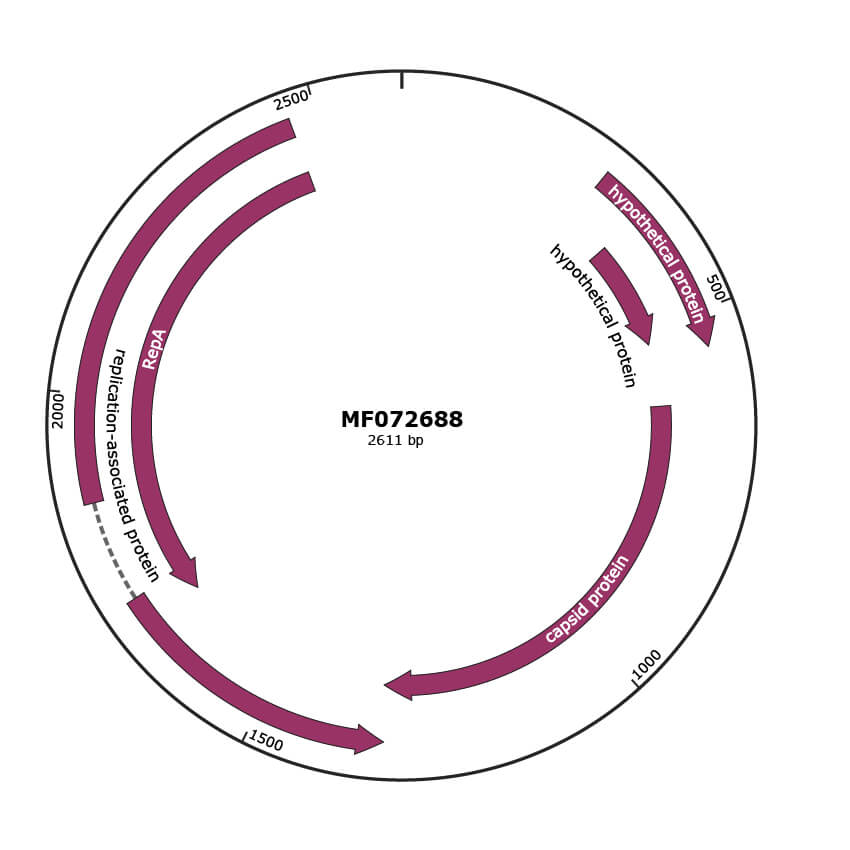
JBrowse
Genome
ACGGATGTGGCCCCAGTTGCGAGCGCTTTAGCGCGAGCCTTTAATAAAGTGATAAAGTGAAACGCTACTTTTGACGTGGCACAATGTGAGCCGTAAAACGTGCAGAAAAAAAATAAAAAAAGCCGACAAGCAAATAACGTGGGCCCCACTAAATAAAGACATCGGAAAAAGGTAACATACTATATTATTCTTGCCTTCGTCCCTAAGTTTTGACTGGTCAAAACTTGCGGCGTACTCTATACGCTTCTTATTTGGTATATAAAGTGGTGTATTTTATACGCATTATGGAGTGGTCTTTTAACGCAGTGGTGTACATTATTGTGTACATTTGTACGCTATTCGTTACGCTCGTTAATGGATATTCCGTTATACGAAGTGAACGACTATCCCGGCGTCTACAATCAATTTCTACAGACTTGCGCCAATCGTCTAATTTCTTGGCAATTATCGAAGGTTCAATTGGAGCTCGACGTGAAAGGAATTTCAATCGACCGGAAGGAGCAGCTTCTGAAACTCCAGTAGTTCCTCGAGGAGTTCAAGAAGTTTAATCGGGTTATATCTTATCAACGCAATCATCTAGTGAAGTGTTGTTTGTATTCTACTTTCATTGCCAAATTTAGGTATGGCGGAGCGGAAGAGGAAGATGGAATGGTCGAAAGCGAATCGGAAGAGGAGTCGTACGACTCTGCCGAGGAATTCTAGGGTGTATGCTAGAAAACGACCTATATTGCGAGGTCCTAAATTGACTAGCAGGGATAAGGTTTATACGTATACGAAATACGAGACACTTACTACAGCGGGTGCGGTTTATCATCTCAATAGTTTTAGTCAGGGTTTAGCTAATAATCAACGTGCGACTTCCGTTGATATTGTTCATAATGTTCAGCTTAGGTTTTCTGTTGAGTTACCTACTGGTGCTATGGTTTTTTGTCGTCGTTACAAGATGTCATGGGCTGTTGTTCAAGATATGATGCCGGGAGATAGTATGCCAGCGGTCAGCGATATTTTTAGTATGACTTCTCCTCCTATTGAAGGTTTGGAGTATATTGCTGATGATAATCATCGCAGATTTCAAGTTAAAAAATTTGGAATTTTGTACTTGGAATCTGGTGGTGCTGACTACTCTGTTAATACTGGAAAGCAGACGTACAACGTACAAGATGCTTTGAAAAGGGTCTTCGTGAAGTGCAATACACGCGGTGTGTATGATAGTAACAGCTCTGCTGGTTCTATCAGTGCTATGAATTCTGGGGCTTTGTATTTTGTTGTAAATCCCACTTTCGCTGGGTATTTGGGTTTCAACATTACTGTGTATCATAATTCACCTGTTTAATACAGGTTTTTATTAATAAAGAAGTATTCTACATTTTGTTGTGACCATTCATAGATATCGCTATTCTGTATAGCTGTTTCGTATGATTGATCAGAATTACATAGGATAATAGATGGTATTCCTCCCTTTATTCTACATTTTTTCTTATATTTTTCGTTTACTGTGAAATCCTTTTGTGCTCCTAGGATTTCTTTTTTACATGGTAAAAACTGGAAAGGAATATCATCGAATACATTATATAACGCCGTGTTGTCATAGTTTGACCAGTCGACTCCTCCGCAGTAGTAATTATGTTTTCCCAAGCTTCTTGCCCATGCTGTTTTTCCACATCTCGTTGGACCTTCAATTATTGCGGTGGTGGGTCGGTCTGGTACCAGTTCTGGTTCCTATAAACAAAATATGAAGGTGACTCAGCTTGGTTTTCCCATGCTTCACGAATTTCCATTTTCGTTGTTTCTGATGCCCAGACCAAGTCTGAAAAATCAGCAGTAGGATTGATGTGAAGATAGGTATCGAAGCTTACGCAGTAGAGGTTTTGATCTGCCCAGTGTTGTAAGGACTCTGGAATGCCAATAAAATTTGTCCATCTGGGTTGATAACTCTCAGGGGGTGTGGGCCATTGTTTATCAGCCATGTATTCGAGGTTTCTATAGTTGTTGGCATACGTGTAGGGCTGTTCGGCCAGTACTCTGGTGAGGAAGTCAGACTTGGATGTGGATTCTGAGAGAATTCTTGTCCAGATAGCGTCTCTATTCTTCTTCGGACTTCTTCGGGAAGCTCTAAGAATACCTCTCTCCTCAAAGGTACCCCCCTTGGAAATGTAGTCCGCAACATCTGCATCCCTTCTTGGGATCTGGATGTTTGGATGATAAATTCCCGATCCGTTAGGGTCGGTGATGTCGAAGAACCTCTGGTTCTGCGTCTGAAACCTCTTCTCAGTCTGTACCAGACAGTGGATGTGTGGCTCTCCATCTTGATGGTTTTCCGTACAAGCTCTAACGTATGTGACGTTATAATCTTTTAGTAATTGAAAAAAGTAATCGATAATGAAAATTGGAATTAGAGGACACTTTGGATAGGTTAGAAAAAAGGATTTGCCCTGGATTTTAAAGGAAGAGGGTTGGCGAGGCATAGCTGCTGGCGCTACAGTGCTTTCTATTGTTTATTGTATTACAAGGATGGTGATCAGTTGATCAGTTATATACTAAATTAAATGGGCCGAATAGTGTTGGGCCGATTTATTGGGCTTCGTCAACTGGGGCACATCCTTTTAATATT
Gene Information
|
NCBI Accession
|
ASU08499.1
|
|
Location
|
285-548 |
|
Protein Name
|
hypothetical protein |
|
Coding Region
|
ATGGAGTGGTCTTTTAACGCAGTGGTGTACATTATTGTGTACATTTGTACGCTATTCGTTACGCTCGTTAATGGATATTCCGTTATACGAAGTGAACGACTATCCCGGCGTCTACAATCAATTTCTACAGACTTGCGCCAATCGTCTAATTTCTTGGCAATTATCGAAGGTTCAATTGGAGCTCGACGTGAAAGGAATTTCAATCGACCGGAAGGAGCAGCTTCTGAAACTCCAGTAGTTCCTCGAGGAGTTCAAGAAGTTTAA |
|
Protein Sequence
|
MEWSFNAVVYIIVYICTLFVTLVNGYSVIRSERLSRRLQSISTDLRQSSNFLAIIEGSIGARRERNFNRPEGAASETPVVPRGVQEV |
|
NCBI Accession
|
ASU08500.1
|
|
Location
|
355-522 |
|
Protein Name
|
hypothetical protein |
|
Coding Region
|
ATGGATATTCCGTTATACGAAGTGAACGACTATCCCGGCGTCTACAATCAATTTCTACAGACTTGCGCCAATCGTCTAATTTCTTGGCAATTATCGAAGGTTCAATTGGAGCTCGACGTGAAAGGAATTTCAATCGACCGGAAGGAGCAGCTTCTGAAACTCCAGTAG |
|
Protein Sequence
|
MDIPLYEVNDYPGVYNQFLQTCANRLISWQLSKVQLELDVKGISIDRKEQLLKLQ |
|
NCBI Accession
|
ASU08496.1
|
|
Location
|
623-1333 |
|
Protein Name
|
capsid protein |
|
Coding Region
|
ATGGCGGAGCGGAAGAGGAAGATGGAATGGTCGAAAGCGAATCGGAAGAGGAGTCGTACGACTCTGCCGAGGAATTCTAGGGTGTATGCTAGAAAACGACCTATATTGCGAGGTCCTAAATTGACTAGCAGGGATAAGGTTTATACGTATACGAAATACGAGACACTTACTACAGCGGGTGCGGTTTATCATCTCAATAGTTTTAGTCAGGGTTTAGCTAATAATCAACGTGCGACTTCCGTTGATATTGTTCATAATGTTCAGCTTAGGTTTTCTGTTGAGTTACCTACTGGTGCTATGGTTTTTTGTCGTCGTTACAAGATGTCATGGGCTGTTGTTCAAGATATGATGCCGGGAGATAGTATGCCAGCGGTCAGCGATATTTTTAGTATGACTTCTCCTCCTATTGAAGGTTTGGAGTATATTGCTGATGATAATCATCGCAGATTTCAAGTTAAAAAATTTGGAATTTTGTACTTGGAATCTGGTGGTGCTGACTACTCTGTTAATACTGGAAAGCAGACGTACAACGTACAAGATGCTTTGAAAAGGGTCTTCGTGAAGTGCAATACACGCGGTGTGTATGATAGTAACAGCTCTGCTGGTTCTATCAGTGCTATGAATTCTGGGGCTTTGTATTTTGTTGTAAATCCCACTTTCGCTGGGTATTTGGGTTTCAACATTACTGTGTATCATAATTCACCTGTTTAA |
|
Protein Sequence
|
MAERKRKMEWSKANRKRSRTTLPRNSRVYARKRPILRGPKLTSRDKVYTYTKYETLTTAGAVYHLNSFSQGLANNQRATSVDIVHNVQLRFSVELPTGAMVFCRRYKMSWAVVQDMMPGDSMPAVSDIFSMTSPPIEGLEYIADDNHRRFQVKKFGILYLESGGADYSVNTGKQTYNVQDALKRVFVKCNTRGVYDSNSSAGSISAMNSGALYFVVNPTFAGYLGFNITVYHNSPV |
|
NCBI Accession
|
ASU08498.1
|
|
Location
|
NA |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCTCGCCAACCCTCTTCCTTTAAAATCCAGGGCAAATCCTTTTTTCTAACCTATCCAAAGTGTCCTCTAATTCCAATTTTCATTATCGATTACTTTTTTCAATTACTAAAAGATTATAACGTCACATACGTTAGAGCTTGTACGGAAAACCATCAAGATGGAGAGCCACACATCCACTGTCTGGTACAGACTGAGAAGAGGTTTCAGACGCAGAACCAGAGGTTCTTCGACATCACCGACCCTAACGGATCGGGAATTTATCATCCAAACATCCAGATCCCAAGAAGGGATGCAGATGTTGCGGACTACATTTCCAAGGGGGGTACCTTTGAGGAGAGAGGTATTCTTAGAGCTTCCCGAAGAAGTCCGAAGAAGAATAGAGACGCTATCTGGACAAGAATTCTCTCAGAATCCACATCCAAGTCTGACTTCCTCACCAGAGTACTGGCCGAACAGCCCTACACGTATGCCAACAACTATAGAAACCTCGAATACATGGCTGATAAACAATGGCCCACACCCCCTGAGAGTTATCAACCCAGATGGACAAATTTTATTGGCATTCCAGAGTCCTTACAACACTGGGCAGATCAAAACCTCTACTGCGAACCAGAACTGGTACCAGACCGACCCACCACCGCAATAATTGAAGGTCCAACGAGATGTGGAAAAACAGCATGGGCAAGAAGCTTGGGAAAACATAATTACTACTGCGGAGGAGTCGACTGGTCAAACTATGACAACACGGCGTTATATAATGTATTCGATGATATTCCTTTCCAGTTTTTACCATGTAAAAAAGAAATCCTAGGAGCACAAAAGGATTTCACAGTAAACGAAAAATATAAGAAAAAATGTAGAATAAAGGGAGGAATACCATCTATTATCCTATGTAATTCTGATCAATCATACGAAACAGCTATACAGAATAGCGATATCTATGAATGGTCACAACAAAATGTAGAATACTTCTTTATTAATAAAAACCTGTATTAA |
|
Protein Sequence
|
MPRQPSSFKIQGKSFFLTYPKCPLIPIFIIDYFFQLLKDYNVTYVRACTENHQDGEPHIHCLVQTEKRFQTQNQRFFDITDPNGSGIYHPNIQIPRRDADVADYISKGGTFEERGILRASRRSPKKNRDAIWTRILSESTSKSDFLTRVLAEQPYTYANNYRNLEYMADKQWPTPPESYQPRWTNFIGIPESLQHWADQNLYCEPELVPDRPTTAIIEGPTRCGKTAWARSLGKHNYYCGGVDWSNYDNTALYNVFDDIPFQFLPCKKEILGAQKDFTVNEKYKKKCRIKGGIPSIILCNSDQSYETAIQNSDIYEWSQQNVEYFFINKNLY |
|
NCBI Accession
|
ASU08497.1
|
|
Location
|
1680-2465 |
|
Protein Name
|
RepA |
|
Coding Region
|
ATGCCTCGCCAACCCTCTTCCTTTAAAATCCAGGGCAAATCCTTTTTTCTAACCTATCCAAAGTGTCCTCTAATTCCAATTTTCATTATCGATTACTTTTTTCAATTACTAAAAGATTATAACGTCACATACGTTAGAGCTTGTACGGAAAACCATCAAGATGGAGAGCCACACATCCACTGTCTGGTACAGACTGAGAAGAGGTTTCAGACGCAGAACCAGAGGTTCTTCGACATCACCGACCCTAACGGATCGGGAATTTATCATCCAAACATCCAGATCCCAAGAAGGGATGCAGATGTTGCGGACTACATTTCCAAGGGGGGTACCTTTGAGGAGAGAGGTATTCTTAGAGCTTCCCGAAGAAGTCCGAAGAAGAATAGAGACGCTATCTGGACAAGAATTCTCTCAGAATCCACATCCAAGTCTGACTTCCTCACCAGAGTACTGGCCGAACAGCCCTACACGTATGCCAACAACTATAGAAACCTCGAATACATGGCTGATAAACAATGGCCCACACCCCCTGAGAGTTATCAACCCAGATGGACAAATTTTATTGGCATTCCAGAGTCCTTACAACACTGGGCAGATCAAAACCTCTACTGCGTAAGCTTCGATACCTATCTTCACATCAATCCTACTGCTGATTTTTCAGACTTGGTCTGGGCATCAGAAACAACGAAAATGGAAATTCGTGAAGCATGGGAAAACCAAGCTGAGTCACCTTCATATTTTGTTTATAGGAACCAGAACTGGTACCAGACCGACCCACCACCGCAATAA |
|
Protein Sequence
|
MPRQPSSFKIQGKSFFLTYPKCPLIPIFIIDYFFQLLKDYNVTYVRACTENHQDGEPHIHCLVQTEKRFQTQNQRFFDITDPNGSGIYHPNIQIPRRDADVADYISKGGTFEERGILRASRRSPKKNRDAIWTRILSESTSKSDFLTRVLAEQPYTYANNYRNLEYMADKQWPTPPESYQPRWTNFIGIPESLQHWADQNLYCVSFDTYLHINPTADFSDLVWASETTKMEIREAWENQAESPSYFVYRNQNWYQTDPPPQ |