Chilli leaf curl India virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002986345.1 |
| Isolate |
India:North India |
| Release date |
2018/8/26 |
| Submitter |
Kumar,Y., Walia,Y., Bhardwaj,P., Negi,A., Hallan,V., Zaidi,A.A. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
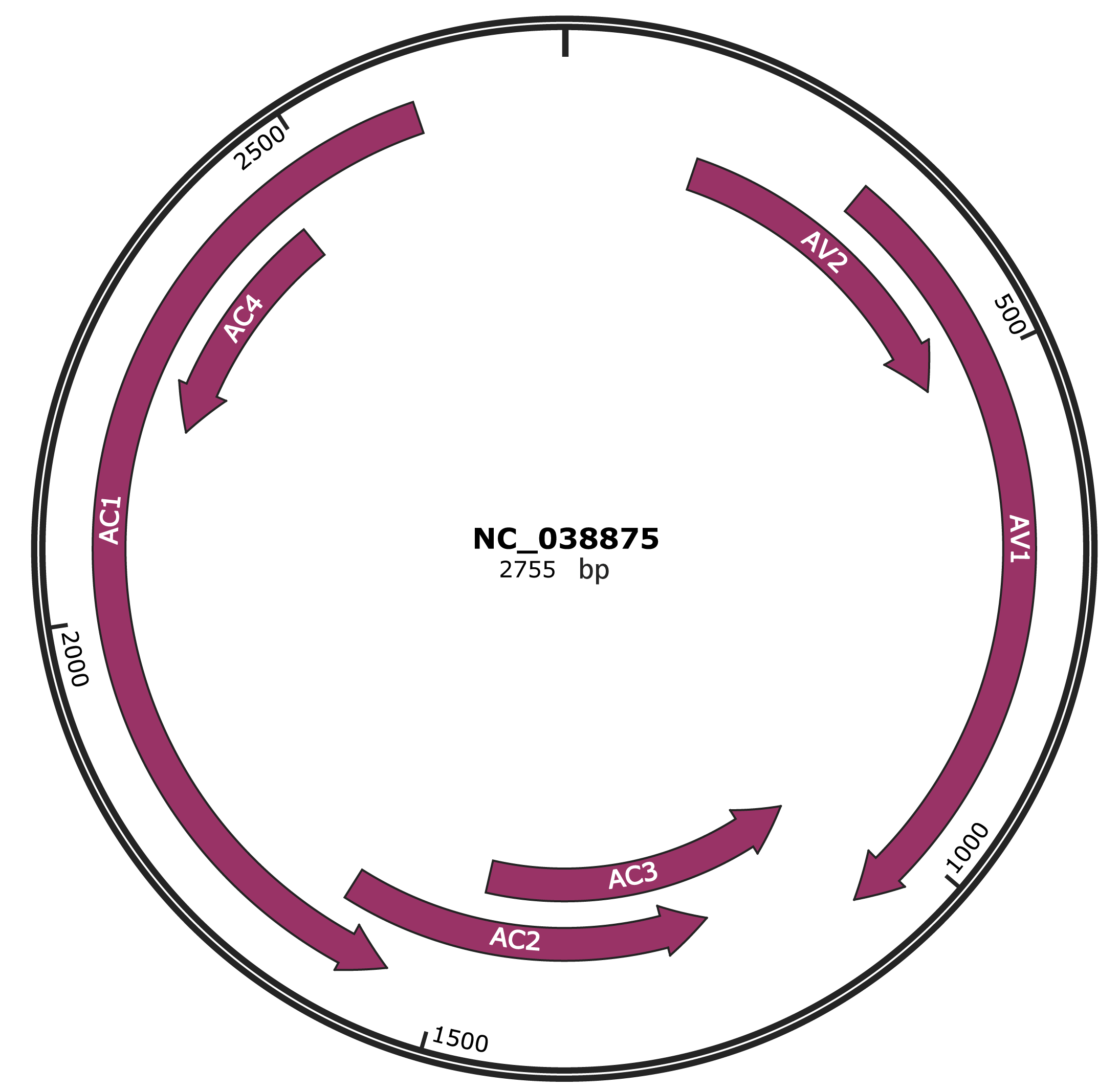
JBrowse
Genome
ACCGGATGGCCGCGATTTTTTTTGTGGCCCCCACAACGCGCTAACTGACAATGACATGTGGACCAATGAGAATCGTCCCTCATGGTCTCATTGTTTTGTGGTCCCCCCTATAAATTAGTCCCCAAATATTGGTCTTTATCCACAATGTGGGACCCTTTAGTAAACGAGTTTCCCGAAACCGTTCACGGTTTTAGGTGTATGCTAGCAGTTAAATACCTGCGGTTAGTAGAAAATACGTATTCCCCAGATACTCTGGGCTACGATTTAATTAGGGATTTGATTTCAGTTATTAGGGCTAGAAATTATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCCTCGAAGGTACGCCGCCGTCTGAACTTCGACAGCCCATATGCGAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACAAAGGCAAGAGCATGGGCGAACAGGCCCATGAACCGAAAGCCCAAGATGTACAGGGTGTACAGAAGCCCAGATGTTCCGAGGGGATGTGAAGGCCCGTGTAAGGTCCAGTCATTTGAGTCCAGACATGATATCCAGCACATTGGTAAAGTAATGTGTGTTAGTGATGTTACTCGTGGTATTGGGCTGACTCACCGGGTTGGCAAGAGGTTCTGTGTGAAGTCCGTTTATGTTTTGGGCAAGATCTGGATGGACGAGAACATCAAGACTAAGAATCATACGAATAGTGTTATGTTTTTCCTTGTTAGAGATCGTAGGCCTGTTGATAAGCCTCAAGATTTTGGTGAGGTTTTTAACATGTTTGATAATGAGCCCAGCACGGCGACTGTGAAGAATGTTCATCGTGATAGGTATCAGGTGCTGAGAAAGTGGCATGCAACTGTCACCGGTGGTCAATATGCATCCAAGGAGCAGGCTCTCGTGAAGAAGTTTATTAGGGTTAATAATTATGTTGTGTATAACCAGCAAGAGGCTGGCAAGTATGAGAATCATACTGAGAATGCGTTGATGTTGTATATGGCGTGTACCCACGCCTCTAACCCTGTGTATGCTACATTGAAGATACGGATCTACTTCTATGATTCAGTATCGAATTAATAAAGATTAAATTTTATTGAATATGATTGTTCTACATATACAACATGATGTAATACATTCCATAATACATGATCAACTGCTCTAACTACATTGTTAATACTGATAACTCCTAAATTATCTAAATACTTAATAACTTGGGTCTTAAAGACCCTTAAGAAACGACCAGTCGGAGGCTGTGAGGTCATCCAGATTCGGAAGGCTATGAAACATTTGTGAATCCCCAACGCTTTCCTCAGGTTGTGGTTGAACTGGACTTGGACGGTTATGATGTCTTTGTTCATCAGGAATGGCCTGTTGTGGTGCTCTGTTATCTTGAAATACAGGGGATTTGGAACCTCCCAGGTATACACGCCATTCTCTGCTTGAGCTGCAGTGATGGGTTCCTCTGTGCGTGAATCCATATTTGTGGCAGTCGATGTGTACGTAGTATGAGCACCCACAGTTTAGATCAACCCTCTTACGCCGGATGGCTCTACGCTTAGCAGCTCTGTGTTGGACCTTGATTGGTACCTGAGTATAGTGGCTCTTCGAGGGTGATGAAGGTTGCATTATGTATTGCCCACGACCTCAGTGCTGAGTTCTTTTCCTCATCGAGGAATTCTTTATAGCTGGAATTGGGCCCAGGATTGCAGAGGAAGATAGTGGGAATGCCCCCTTTAATTTGAACTGGCTTCCCGTACTTGGTGTTGCTTTGCCAGTCCCTTTGGGCCCCCATGAACTCTTTAAAGTGCTTTAGGTAGTGGGGATCTACGTCATCAATGACGTTGTACCAGGCATCATTTGAATATATCTTGGGACTCAGATCTAAATGGCCGCATAAATAATTGTGTGGTCCCAAAGACCTGGCCCACATTGTCTTGCCTGTACGACTATCACCCTCAATGACGATACTTTTAGGTCTCAATGGCCGCGCAGCGGGACCCATCACATTTTCAGAGGCCCATTCCTCTATGGCCTCTGGAACCTGATCGAACGAAGAAGAAAGAAATGGGGGAACATAAACCTCCACTGGAGGTGTAAAAATCCTATCTAAATTAGTTTTTAAATTATGATATTGAAAAATAAAATCTTTCGGGAGTTTCTCCCTAATAATTGCTAGAGCTGCTTCAGCTGAACCTGCATTTAGGGCCTCTGCTGCAGCATCATTAGCTGTCTGTTGACCTCCTCGAGCAGATCGTCCATCGACCTGAAACTGACCCCAGTCGATGTAATCACCGTCCTTCTCGATATAGGACTTGACATCGGAGCTGGACTTTGCTCCCTGGAAGTTTGGGTGGAATTGGGTTGATGTATTAGGGTGAGTGACATCGAAATGTCTGGGGTTTCTGAATTGGGATTTACCTTTGAATTGGATGAGGGCATGGATATGCAGAGACCCATCTTGGTGTTTTTCCTGTGACACTCTGATAAATAATTTATCAGAAGGACAAGAAACGTTTTTTAGGAGTTCGAGCATTTGCTCTTTGGGTATTGGGCATTTTGGATAAGTAAGGAAGATATTTTTGGCTTTAACTTGGAACTGATGAGCACGAGGCATAATGAATTGGGTGCTCTCTAAAACTCTGTGGAATGGGGATCTTTGGGTGCCTATTTATATCGAGCTCCCAAATGGCATTATCGTAATTTGGGGAAATAATTCAAAATCCCCACGCTCCAAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_009508107.1
|
|
Location
|
145-510 |
|
Gene Name
|
AV2 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGTGGGACCCTTTAGTAAACGAGTTTCCCGAAACCGTTCACGGTTTTAGGTGTATGCTAGCAGTTAAATACCTGCGGTTAGTAGAAAATACGTATTCCCCAGATACTCTGGGCTACGATTTAATTAGGGATTTGATTTCAGTTATTAGGGCTAGAAATTATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCCTCGAAGGTACGCCGCCGTCTGAACTTCGACAGCCCATATGCGAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACAAAGGCAAGAGCATGGGCGAACAGGCCCATGAACCGAAAGCCCAAGATGTACAGGGTGTACAGAAGCCCAGATGTTCCGAGGGGATGTGA |
|
Protein Sequence
|
MWDPLVNEFPETVHGFRCMLAVKYLRLVENTYSPDTLGYDLIRDLISVIRARNYVEATSRYNHFHARLEGTPPSELRQPICEPCCCPHCPRHKGKSMGEQAHEPKAQDVQGVQKPRCSEGM |
|
NCBI Accession
|
YP_009508108.1
|
|
Location
|
305-1075 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCCTCGAAGGTACGCCGCCGTCTGAACTTCGACAGCCCATATGCGAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACAAAGGCAAGAGCATGGGCGAACAGGCCCATGAACCGAAAGCCCAAGATGTACAGGGTGTACAGAAGCCCAGATGTTCCGAGGGGATGTGAAGGCCCGTGTAAGGTCCAGTCATTTGAGTCCAGACATGATATCCAGCACATTGGTAAAGTAATGTGTGTTAGTGATGTTACTCGTGGTATTGGGCTGACTCACCGGGTTGGCAAGAGGTTCTGTGTGAAGTCCGTTTATGTTTTGGGCAAGATCTGGATGGACGAGAACATCAAGACTAAGAATCATACGAATAGTGTTATGTTTTTCCTTGTTAGAGATCGTAGGCCTGTTGATAAGCCTCAAGATTTTGGTGAGGTTTTTAACATGTTTGATAATGAGCCCAGCACGGCGACTGTGAAGAATGTTCATCGTGATAGGTATCAGGTGCTGAGAAAGTGGCATGCAACTGTCACCGGTGGTCAATATGCATCCAAGGAGCAGGCTCTCGTGAAGAAGTTTATTAGGGTTAATAATTATGTTGTGTATAACCAGCAAGAGGCTGGCAAGTATGAGAATCATACTGAGAATGCGTTGATGTTGTATATGGCGTGTACCCACGCCTCTAACCCTGTGTATGCTACATTGAAGATACGGATCTACTTCTATGATTCAGTATCGAATTAA |
|
Protein Sequence
|
MSKRPADIIISTPASKVRRRLNFDSPYASRAAAPIVRVTKARAWANRPMNRKPKMYRVYRSPDVPRGCEGPCKVQSFESRHDIQHIGKVMCVSDVTRGIGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNSVMFFLVRDRRPVDKPQDFGEVFNMFDNEPSTATVKNVHRDRYQVLRKWHATVTGGQYASKEQALVKKFIRVNNYVVYNQQEAGKYENHTENALMLYMACTHASNPVYATLKIRIYFYDSVSN |
|
NCBI Accession
|
YP_009508109.1
|
|
Location
|
1072-1476 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGAGGAACCCATCACTGCAGCTCAAGCAGAGAATGGCGTGTATACCTGGGAGGTTCCAAATCCCCTGTATTTCAAGATAACAGAGCACCACAACAGGCCATTCCTGATGAACAAAGACATCATAACCGTCCAAGTCCAGTTCAACCACAACCTGAGGAAAGCGTTGGGGATTCACAAATGTTTCATAGCCTTCCGAATCTGGATGACCTCACAGCCTCCGACTGGTCGTTTCTTAAGGGTCTTTAAGACCCAAGTTATTAAGTATTTAGATAATTTAGGAGTTATCAGTATTAACAATGTAGTTAGAGCAGTTGATCATGTATTATGGAATGTATTACATCATGTTGTATATGTAGAACAATCATATTCAATAAAATTTAATCTTTATTAA |
|
Protein Sequence
|
MDSRTEEPITAAQAENGVYTWEVPNPLYFKITEHHNRPFLMNKDIITVQVQFNHNLRKALGIHKCFIAFRIWMTSQPPTGRFLRVFKTQVIKYLDNLGVISINNVVRAVDHVLWNVLHHVVYVEQSYSIKFNLY |
|
NCBI Accession
|
YP_009508110.1
|
|
Location
|
1217-1624 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCAACCTTCATCACCCTCGAAGAGCCACTATACTCAGGTACCAATCAAGGTCCAACACAGAGCTGCTAAGCGTAGAGCCATCCGGCGTAAGAGGGTTGATCTAAACTGTGGGTGCTCATACTACGTACACATCGACTGCCACAAATATGGATTCACGCACAGAGGAACCCATCACTGCAGCTCAAGCAGAGAATGGCGTGTATACCTGGGAGGTTCCAAATCCCCTGTATTTCAAGATAACAGAGCACCACAACAGGCCATTCCTGATGAACAAAGACATCATAACCGTCCAAGTCCAGTTCAACCACAACCTGAGGAAAGCGTTGGGGATTCACAAATGTTTCATAGCCTTCCGAATCTGGATGACCTCACAGCCTCCGACTGGTCGTTTCTTAAGGGTCTTTAA |
|
Protein Sequence
|
MQPSSPSKSHYTQVPIKVQHRAAKRRAIRRKRVDLNCGCSYYVHIDCHKYGFTHRGTHHCSSSREWRVYLGGSKSPVFQDNRAPQQAIPDEQRHHNRPSPVQPQPEESVGDSQMFHSLPNLDDLTASDWSFLKGL |
|
NCBI Accession
|
YP_009508111.1
|
|
Location
|
1554-2612 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication initiator protein |
|
Coding Region
|
ATGCCTCGTGCTCATCAGTTCCAAGTTAAAGCCAAAAATATCTTCCTTACTTATCCAAAATGCCCAATACCCAAAGAGCAAATGCTCGAACTCCTAAAAAACGTTTCTTGTCCTTCTGATAAATTATTTATCAGAGTGTCACAGGAAAAACACCAAGATGGGTCTCTGCATATCCATGCCCTCATCCAATTCAAAGGTAAATCCCAATTCAGAAACCCCAGACATTTCGATGTCACTCACCCTAATACATCAACCCAATTCCACCCAAACTTCCAGGGAGCAAAGTCCAGCTCCGATGTCAAGTCCTATATCGAGAAGGACGGTGATTACATCGACTGGGGTCAGTTTCAGGTCGATGGACGATCTGCTCGAGGAGGTCAACAGACAGCTAATGATGCTGCAGCAGAGGCCCTAAATGCAGGTTCAGCTGAAGCAGCTCTAGCAATTATTAGGGAGAAACTCCCGAAAGATTTTATTTTTCAATATCATAATTTAAAAACTAATTTAGATAGGATTTTTACACCTCCAGTGGAGGTTTATGTTCCCCCATTTCTTTCTTCTTCGTTCGATCAGGTTCCAGAGGCCATAGAGGAATGGGCCTCTGAAAATGTGATGGGTCCCGCTGCGCGGCCATTGAGACCTAAAAGTATCGTCATTGAGGGTGATAGTCGTACAGGCAAGACAATGTGGGCCAGGTCTTTGGGACCACACAATTATTTATGCGGCCATTTAGATCTGAGTCCCAAGATATATTCAAATGATGCCTGGTACAACGTCATTGATGACGTAGATCCCCACTACCTAAAGCACTTTAAAGAGTTCATGGGGGCCCAAAGGGACTGGCAAAGCAACACCAAGTACGGGAAGCCAGTTCAAATTAAAGGGGGCATTCCCACTATCTTCCTCTGCAATCCTGGGCCCAATTCCAGCTATAAAGAATTCCTCGATGAGGAAAAGAACTCAGCACTGAGGTCGTGGGCAATACATAATGCAACCTTCATCACCCTCGAAGAGCCACTATACTCAGGTACCAATCAAGGTCCAACACAGAGCTGCTAA |
|
Protein Sequence
|
MPRAHQFQVKAKNIFLTYPKCPIPKEQMLELLKNVSCPSDKLFIRVSQEKHQDGSLHIHALIQFKGKSQFRNPRHFDVTHPNTSTQFHPNFQGAKSSSDVKSYIEKDGDYIDWGQFQVDGRSARGGQQTANDAAAEALNAGSAEAALAIIREKLPKDFIFQYHNLKTNLDRIFTPPVEVYVPPFLSSSFDQVPEAIEEWASENVMGPAARPLRPKSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKIYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEEKNSALRSWAIHNATFITLEEPLYSGTNQGPTQSC |
|
NCBI Accession
|
YP_009508112.1
|
|
Location
|
2198-2455 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGTCTCTGCATATCCATGCCCTCATCCAATTCAAAGGTAAATCCCAATTCAGAAACCCCAGACATTTCGATGTCACTCACCCTAATACATCAACCCAATTCCACCCAAACTTCCAGGGAGCAAAGTCCAGCTCCGATGTCAAGTCCTATATCGAGAAGGACGGTGATTACATCGACTGGGGTCAGTTTCAGGTCGATGGACGATCTGCTCGAGGAGGTCAACAGACAGCTAATGATGCTGCAGCAGAGGCCCTAA |
|
Protein Sequence
|
MGLCISMPSSNSKVNPNSETPDISMSLTLIHQPNSTQTSREQSPAPMSSPISRRTVITSTGVSFRSMDDLLEEVNRQLMMLQQRP |