Sugarcane streak Egypt virus
Basic Information
| Genus |
Mastrevirus
|
| NCBI Assembly |
GCF_000841765.1 |
| Release date |
2015/2/12 |
| Submitter |
Bigarre,L., Salah,M., Granier,M., Frutos,R., Thouvenel,J., Peterschmitt,M. |
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
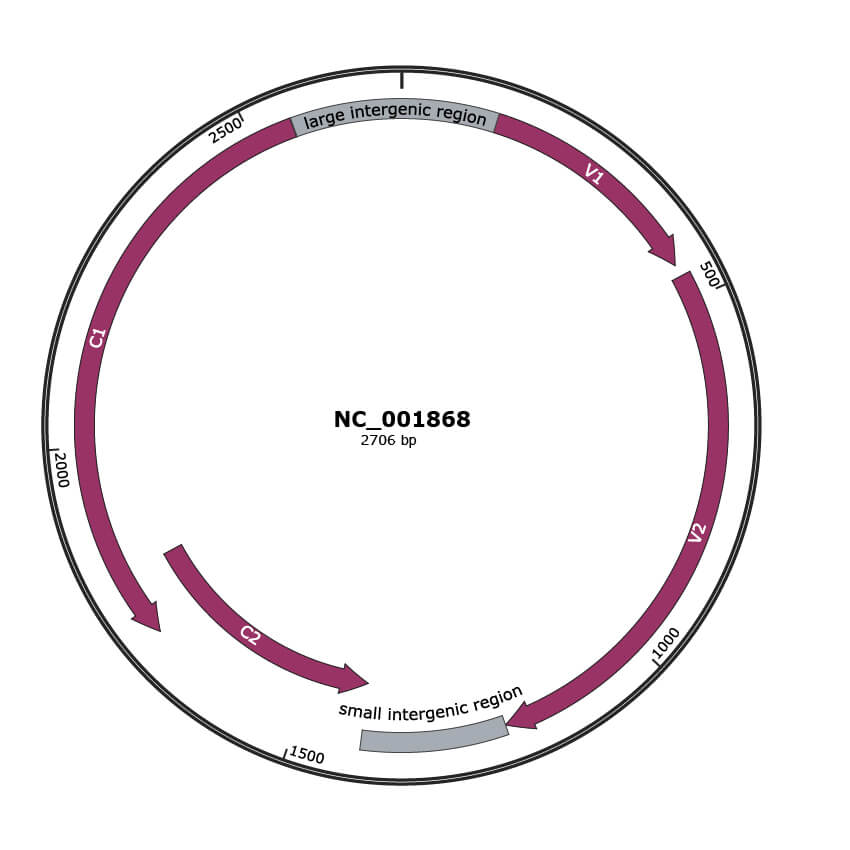
JBrowse
Genome
ACCGCGCTCTCTCATGCGAGGCCCACCAGGCCGAGCGGTCCCGCTTTGGGGCCCTATGTCTTTCGTTAAAGCCTGTATGTAGTAAGGCGCTTTGGATCGCATATAAGTTCGTGCCCAGGCTCAGTGGTGCTATGGACGGCTCTGGAGGAGCGTTGCCTGCTTTGCCTCAAAGTGTTCTGCCGCGGGTACCCTCGCCACCTCCGTCTGCCGGAGTGCTGCCGTGGAGTCGCGTCGGTGAGATAGTGATTTTCACCTTTGTTGCTTTGGTAGCTCTGTACCTGTTATGGTTGTGGGTGCTGAGAGATCTTATCTTCCTTGTTAAGGCTCGCCGCGGGATCTCAACGGAGGAGGTGAGCTTTGGTACGTCAGATCTGGTTGGTTCGCAGGCTCCAACGCCGGTCGGTGTCTCTGCTAGCTGTCCGCCGGGACCTGTGCCGTTCACGGCCTAGGTAGCCCTCAGCCACCATGCCTCTTGCCGGCAGCAAAAGGAAGAGGGCCGATGAGGTGGCCTGGTCTAAGCGTGGCACTAAGAAGAAGCCAGAGCGTACATCTGCCGCTCGGGCTGGTCCGTCTAGGCGGATTCGTCCACCCCTGCAGATAGCCACGTTTGTGGCAGCCGGTCAGTCTATGGTGTCTGTCCCTTCCGGTGGTGTTTGTGAACTGCTAGGCTCCTATGCTCGAGGCGCTGACGAGGCCAACCGTCACACCAACGAGACTGTCACGTACAAGGTTGCCTTGGACTACCACTTCGTTGCTACTGCAGCCGCCTGCAAGTATTCCAGCATTGGCACTGGCGTGGCCTGGTTGGTGTATGATGCACAGCCTACCGGAAATACCCCGACGACGAAGGACATCTTCGGCTATAGTGACTCCCTTGTGGCGTTCCCCTACACATGGAAGGTTTCAAGGGAGGTGTGTCATCGCTTCGTGGTGAAGAGGAGATGCACTTTCACGATGGAGACCGACGGTCGGATTGGGTCGGATGTTCCTCCGGCGAATACCTCATGGTCGCCTTGTAAGCGGGCGATTTACTTCCATAAGTTCTTCACCGGCCTGGGTGTGAAGACGGAGTGGAAGAATCTCACAGACGGTGGTGTGGGAGCGATTAAGAAGGGTGCGTTGTACCTGGTCATTGCCCCTGGCAATGGTCTAGAGTTTACCTGCCATGGGCAGGCCCGTCTGTACTTCAAATCAGTTGGGAATCAGTGATTCCCTACAGAATAATAAAACAAGTTTTATAATTCCATTGATATTGGACGAAGTACAATACAGAATACAATGTCTGCAGATGTGCAGACGACAACATTAAACTGGTTTTGTGTGTCGCGAGGGGGAACCCGGAGCACGCTCCCAAAACACCCAACACACACACACCCAACTGAAGATTATTGAACATGCAGCCGCCGGCCTAAGCAGGCTTGTAGAACTTCTCGCCTGCTGTCATAATGTATATGACCGCGTTTGCCTCGAAGTACTCCCGTTGTCCGGGAGTCATCACCCTCAGCCAGTCCTCATCCTCGTTGGCTAGGATTATTGATGGAATGCTGTTGGAAGCTACCTTCTTCTTCTTACCGTACTTCGGGTTGACGACGTACTCTTTCTGGCAGCCAACCAGCTGCTTCCAGCAAGGACAGAATTTGAAGGGTATATCATCTATGATGTTATAGACTGCTTCCTCATCATAGGAAGACCAGTCCACATTATTCTGCCAGTAGTTGTGGCGCCCTAGGCTTCTGGCCCAGGTTGATTTCCCTGTTCTTGTTGGCCCAAGGATGTACAGAGACTGTTTCCTGTGCCCTGGGATGTTCTGGATGCGGATTGCATCCATTCTAAGTCAGAGATTGCTTCCTCAAGGGTTAAGCAGGTAGGAGTAAGCAGCATGTAGGCTTCTGGACTAACCTGATAGATGTTGGGGTTGAGCCAATCTTCTATGGTTTCGAAGTTTACGAGGTCCGGTTCAGTGGGAGGATGAGGATTGGTGTATACTTCTGCAGTCTCAGGAAACAATCTGGAGGCTGAGTACTCAAAGTACTGGAGCTTCGTTGCCCACTCGTAGGGGAGTGCCTTCTGAAGCATTGAAAGGTACTCTTGCTTGGAGGTGGAGTGTTCGATGATATCTCTCACGATATCATCTTTTGTGGGTTTAGGTTGCCTATCCTCAGATGAAGTGGTAGCAAAGGATTTCTTGCGTGGGATGAAAGTACCTTTCTCCCACTGTTTGATCGGGTTTTTGAGCACGTATTCCTTGACCCTGTCTGCGGACTTGGCACTCTGAATGTTAGGATGGAAATCCTCAATGTCAAAGAACCTAGGGTTCGTAGTTTGTACAGGCTTGACGCTCTGAGCTAAGGCATGGATATGCCAGGATCCATCAGCATGAGCTTCCCTGCTCACGACGATGTACGCTGGATTCCAGTGACCTATGAGACTCCAGAGATGGAGCCCAACAGCTTCAGGTTCTAGATGGCACTTGGAATATGTGAGGAATGTGTTTACGTTCCTGTGCTTGAAGGAACGGCTGGCAGAGCCTGACTCTGTTGATCCTACGGTTGTCATGGCTGGGCGAGAGGTCTGATTCTGAGTCTCAACTAACTCTCCTACAGGTTTGCGAATCGAAATCCGACCTCCCGTCTTATATAGAAGGTTAGTTGGGCCGGGCCAGGATTTTTCCTGGGCCGCAATGAGAGAGCGCAAACCGATAATATT
Gene Information
|
NCBI Accession
|
NP_045942.1
|
|
Location
|
132-449 |
|
Gene Name
|
V1 |
|
Protein Name
|
putative movement protein |
|
Coding Region
|
ATGGACGGCTCTGGAGGAGCGTTGCCTGCTTTGCCTCAAAGTGTTCTGCCGCGGGTACCCTCGCCACCTCCGTCTGCCGGAGTGCTGCCGTGGAGTCGCGTCGGTGAGATAGTGATTTTCACCTTTGTTGCTTTGGTAGCTCTGTACCTGTTATGGTTGTGGGTGCTGAGAGATCTTATCTTCCTTGTTAAGGCTCGCCGCGGGATCTCAACGGAGGAGGTGAGCTTTGGTACGTCAGATCTGGTTGGTTCGCAGGCTCCAACGCCGGTCGGTGTCTCTGCTAGCTGTCCGCCGGGACCTGTGCCGTTCACGGCCTAG |
|
Protein Sequence
|
MDGSGGALPALPQSVLPRVPSPPPSAGVLPWSRVGEIVIFTFVALVALYLLWLWVLRDLIFLVKARRGISTEEVSFGTSDLVGSQAPTPVGVSASCPPGPVPFTA |
|
NCBI Accession
|
NP_045943.1
|
|
Location
|
466-1209 |
|
Gene Name
|
V2 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTCTTGCCGGCAGCAAAAGGAAGAGGGCCGATGAGGTGGCCTGGTCTAAGCGTGGCACTAAGAAGAAGCCAGAGCGTACATCTGCCGCTCGGGCTGGTCCGTCTAGGCGGATTCGTCCACCCCTGCAGATAGCCACGTTTGTGGCAGCCGGTCAGTCTATGGTGTCTGTCCCTTCCGGTGGTGTTTGTGAACTGCTAGGCTCCTATGCTCGAGGCGCTGACGAGGCCAACCGTCACACCAACGAGACTGTCACGTACAAGGTTGCCTTGGACTACCACTTCGTTGCTACTGCAGCCGCCTGCAAGTATTCCAGCATTGGCACTGGCGTGGCCTGGTTGGTGTATGATGCACAGCCTACCGGAAATACCCCGACGACGAAGGACATCTTCGGCTATAGTGACTCCCTTGTGGCGTTCCCCTACACATGGAAGGTTTCAAGGGAGGTGTGTCATCGCTTCGTGGTGAAGAGGAGATGCACTTTCACGATGGAGACCGACGGTCGGATTGGGTCGGATGTTCCTCCGGCGAATACCTCATGGTCGCCTTGTAAGCGGGCGATTTACTTCCATAAGTTCTTCACCGGCCTGGGTGTGAAGACGGAGTGGAAGAATCTCACAGACGGTGGTGTGGGAGCGATTAAGAAGGGTGCGTTGTACCTGGTCATTGCCCCTGGCAATGGTCTAGAGTTTACCTGCCATGGGCAGGCCCGTCTGTACTTCAAATCAGTTGGGAATCAGTGA |
|
Protein Sequence
|
MPLAGSKRKRADEVAWSKRGTKKKPERTSAARAGPSRRIRPPLQIATFVAAGQSMVSVPSGGVCELLGSYARGADEANRHTNETVTYKVALDYHFVATAAACKYSSIGTGVAWLVYDAQPTGNTPTTKDIFGYSDSLVAFPYTWKVSREVCHRFVVKRRCTFTMETDGRIGSDVPPANTSWSPCKRAIYFHKFFTGLGVKTEWKNLTDGGVGAIKKGALYLVIAPGNGLEFTCHGQARLYFKSVGNQ |
|
NCBI Accession
|
NP_045944.1
|
|
Location
|
1409->1816 |
|
Gene Name
|
C2 |
|
Protein Name
|
rep B |
|
Coding Region
|
CGCATCCAGAACATCCCAGGGCACAGGAAACAGTCTCTGTACATCCTTGGGCCAACAAGAACAGGGAAATCAACCTGGGCCAGAAGCCTAGGGCGCCACAACTACTGGCAGAATAATGTGGACTGGTCTTCCTATGATGAGGAAGCAGTCTATAACATCATAGATGATATACCCTTCAAATTCTGTCCTTGCTGGAAGCAGCTGGTTGGCTGCCAGAAAGAGTACGTCGTCAACCCGAAGTACGGTAAGAAGAAGAAGGTAGCTTCCAACAGCATTCCATCAATAATCCTAGCCAACGAGGATGAGGACTGGCTGAGGGTGATGACTCCCGGACAACGGGAGTACTTCGAGGCAAACGCGGTCATATACATTATGACAGCAGGCGAGAAGTTCTACAAGCCTGCTTAG |
|
Protein Sequence
|
RIQNIPGHRKQSLYILGPTRTGKSTWARSLGRHNYWQNNVDWSSYDEEAVYNIIDDIPFKFCPCWKQLVGCQKEYVVNPKYGKKKKVASNSIPSIILANEDEDWLRVMTPGQREYFEANAVIYIMTAGEKFYKPA |
|
NCBI Accession
|
NP_045945.1
|
|
Location
|
1726-2556 |
|
Gene Name
|
C1 |
|
Protein Name
|
rep A |
|
Coding Region
|
ATGACAACCGTAGGATCAACAGAGTCAGGCTCTGCCAGCCGTTCCTTCAAGCACAGGAACGTAAACACATTCCTCACATATTCCAAGTGCCATCTAGAACCTGAAGCTGTTGGGCTCCATCTCTGGAGTCTCATAGGTCACTGGAATCCAGCGTACATCGTCGTGAGCAGGGAAGCTCATGCTGATGGATCCTGGCATATCCATGCCTTAGCTCAGAGCGTCAAGCCTGTACAAACTACGAACCCTAGGTTCTTTGACATTGAGGATTTCCATCCTAACATTCAGAGTGCCAAGTCCGCAGACAGGGTCAAGGAATACGTGCTCAAAAACCCGATCAAACAGTGGGAGAAAGGTACTTTCATCCCACGCAAGAAATCCTTTGCTACCACTTCATCTGAGGATAGGCAACCTAAACCCACAAAAGATGATATCGTGAGAGATATCATCGAACACTCCACCTCCAAGCAAGAGTACCTTTCAATGCTTCAGAAGGCACTCCCCTACGAGTGGGCAACGAAGCTCCAGTACTTTGAGTACTCAGCCTCCAGATTGTTTCCTGAGACTGCAGAAGTATACACCAATCCTCATCCTCCCACTGAACCGGACCTCGTAAACTTCGAAACCATAGAAGATTGGCTCAACCCCAACATCTATCAGGTTAGTCCAGAAGCCTACATGCTGCTTACTCCTACCTGCTTAACCCTTGAGGAAGCAATCTCTGACTTAGAATGGATGCAATCCGCATCCAGAACATCCCAGGGCACAGGAAACAGTCTCTGTACATCCTTGGGCCAACAAGAACAGGGAAATCAACCTGGGCCAGAAGCCTAG |
|
Protein Sequence
|
MTTVGSTESGSASRSFKHRNVNTFLTYSKCHLEPEAVGLHLWSLIGHWNPAYIVVSREAHADGSWHIHALAQSVKPVQTTNPRFFDIEDFHPNIQSAKSADRVKEYVLKNPIKQWEKGTFIPRKKSFATTSSEDRQPKPTKDDIVRDIIEHSTSKQEYLSMLQKALPYEWATKLQYFEYSASRLFPETAEVYTNPHPPTEPDLVNFETIEDWLNPNIYQVSPEAYMLLTPTCLTLEEAISDLEWMQSASRTSQGTGNSLCTSLGQQEQGNQPGPEA |