Panicum streak virus
Basic Information
| Genus |
Mastrevirus
|
| NCBI Assembly |
GCF_000839585.1 |
| Release date |
2015/2/12 |
| Submitter |
Schnippenkoetter,W.H., Martin,D.P., Hughes,F.L., Fyvie,M., Willment,J.A., James,D., von Wechmar,M.B., Rybicki,E.P. |
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
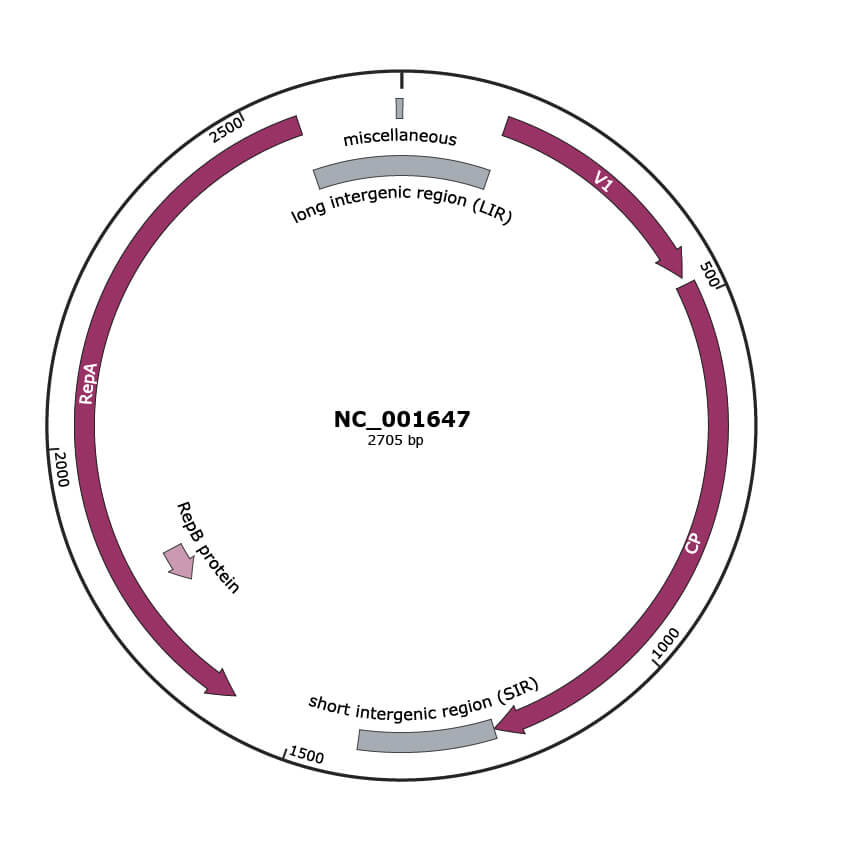
JBrowse
Genome
ACCGCTCACACCCCATGCGAGCCACGGCCCTGTGTGGCGAGCGGTCCCCGGATGTTCTTACCCCGGTGCGATTTCTTTAGCTGCGTGTTCTTTAGCAGCTGCCCCCACTGTCCTATAAGTTGCTCCCCGGTGCGATTCCGCATCATGGATGCTAGCAGCACCACTCCTTTTCCTTTCCCTCAGCCGCCTCGGGTACCCTCTGCAGCTCCGGTCGCCGGAGCGCTGCCGTGGAGTCGCGTCGGTGAGATAGTTATCTTTACCTTTGTTTCAGTGCTAGGCCTTTACCTGCTTTGGCTTTGGGTGCTCAAAGATTGTATCTTACTTCTGAAGGCTCAGCGAGGTAGATCCACGGAGGAGCTGATCTTTGGTCCTGGTGAGAGGCCAGCCGTCGCTTCTGCCGACGGTTCTCGCTCCGTTCCAGATCCGTCTCCGTCCTGTCCGCCGGGACCTAGACCTTTCGTGGTCTAGAGCACTCAGCATGTCCGGAGCTTTGAAGCGCAAGCGTTCGGATGAGGTTGCCTGGAGTCGAAGGAAGCCCGTCAAGAAGCAAGACACCGGGTTCCCCCTCCCCCGGGCTGGCCCCTCTGTCAGGAGAGGACTCCCTGCCCTTCAGATCCAGACGCTTACGGCGGCTGGTGACACTATGATCACGGTGCCGTCCGGCGGCATCTGCAGTCTGATTGGCACGTATGCCCGGGGCTCTGATGAAGGTAACCGCCACACCAACGAGACTCTGACGTACAAGGTTGCGCTGGACTACCACTTCGTTGCTACTGCTGCGGCCTGCAAGTACTCCAGCATTGGAGTGGGTGTCATGTGGTTGGTGTATGATGCGCAGCCGACCGGCAATTCACCGGAGGTGAAGGACATCTTCCCTCACTCCGATACGCTCTCAGCGTTCCCGTACACTTGGAAGGTTGGCAGGGAGGTCTGCCATCGCTTCGTTGTTAAACGGCGCTGGTGCTTCACCATGGAGACTAACGGCCGGATCGGTTCAGATGTGCCTCCGGCCAATACCGCTTGGCCGCCTTGCAAGAAGGACATCTACTTCCACAAGTTCTGCACGGGACTCGGCGTGAAGACGGAGTGGAAGAACGTTACAGACGGGAAGGTCGGCGCTATTAAGAAGGGCGCCTTGTACATTGTCATTGCGCCTGGAAACGGGCTTGAGTTTACGGTTCACGGCCAGTGCCGTCTGTACTTTAAGTCAGTTGGTAATCAGTGATTACCACATCAATTAATAAAACAAGTTTTATTCAAAGAGCGAAGCTCATACATTACATAGTCAGCAGATATGCTGACAGAAAACACACACATAGTGCAGCCTCGGGCTAAAGACCGAGTCTCAAACGACCCAACTTAAAAACAAATCAAAACAAGCATGATATTATTAAATATGCAGCCGCCGGCTTAAGCAGGAGTGAACCACTTCTCTCCTGCCTGCATTACGTAGATTTCGCAGTTTGCGTAGAAGTAGTCATACTGCGCCGGAGTCATGTCCTTCAGCCAGTCCTCATCCTCGTTGGCGAGGATGATAGTTGGTATGCTCTTTGAGGCCACCTTCCGTCTCTTCCCGTACTTCGGGTTCACTATGTAGTCTTTTTGACAGCCGACGAGCTGCTTCCAGCACGGACAGAACTTGAAGGGAATGTCGTCCACGACATTGTACGCAGCTTCTTCATCGTATGAAGACCAGTCGATGTTATTCTGCCAGTAGTTGTGCCGTCCGAGGCTTCTGGCCCAGGATGTTTTACCTGTCCGTGTTGGGCCGACGATGTAGAGGCTTCGCTTTCTTGCTCCTGGAATAATCTGGTTGTTTCAGACAACCATTCTAAGTCAGCTTTGGCTTGCTCTAGGCTTAAGCAGCTAGGTTCAAGGAGCATGTATGCTTTAGGACTGACCTGGTAGATGTTAGGCTCAAGCCAGTCCTGGAGTGTTTCGTTGCAGAGGAGGTCAGGGTCAGTGGCAGGATGAGGATTGCTGTAAGGCTCTGCAATGTCCGGGAACAGGCGACTAGCTGAGTACTCAAAGTATGACAGTTTTGTGGCCCAGTCGTAAGGCAGTGAAGTCTGCACTAGTGAAAGGTACTCTGCTCTGCTAGTGGCATGTGTCATGATCTCCTTCATGACCTCATCCTTAGAAGGCTTCTTCTCAGAGTTTTCCTTACCTGGAGGAACGAAGCTCTTCTTCCTTGGTATGTAAGTACCTTTCTCCCACTTGTCCTTGGGATCCTTCAGTATGTACTCACGTACCTTGTCAGTGCTCTTGGCGCTCTGTATATTCGGATGATACCGATCTATGTCAAAGTACCTCTCGTCACGAGTAGTGACAGGCTTGATGCACTGGAGAAGAGCATGGCAGTGCCATGTTCCGTCTTGGTGAGTCTCTCTCACTACCAGGATGTATGCTGGCTCAAAGTCCTTAGTGAGCCTGAAGAGATGCTCACCGATGAACTCAGGTTCTAGTGGACACTTGCTGTATGTGAGGAAGGTGTTCGCGTTCCGGTGCCTGAAGGACCGGACGCTGTGCCTGCCATCTGAGGTGATAGACAGAGAGGTCGACATTAGCGCAGGAGGTTGGGCAATCTCAGGCTCTCCTCAGCTCTATCCCTAGACAGCTGCGAAATAATCCGCCCACCCCCCGTGCCTTTTATAGCTGCTTGGTGGGCTGGGCCGGCCGGCATGGGGTGTGAGCAGCATAATATT
Gene Information
|
NCBI Accession
|
NP_042588.1
|
|
Location
|
145-468 |
|
Gene Name
|
V1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGATGCTAGCAGCACCACTCCTTTTCCTTTCCCTCAGCCGCCTCGGGTACCCTCTGCAGCTCCGGTCGCCGGAGCGCTGCCGTGGAGTCGCGTCGGTGAGATAGTTATCTTTACCTTTGTTTCAGTGCTAGGCCTTTACCTGCTTTGGCTTTGGGTGCTCAAAGATTGTATCTTACTTCTGAAGGCTCAGCGAGGTAGATCCACGGAGGAGCTGATCTTTGGTCCTGGTGAGAGGCCAGCCGTCGCTTCTGCCGACGGTTCTCGCTCCGTTCCAGATCCGTCTCCGTCCTGTCCGCCGGGACCTAGACCTTTCGTGGTCTAG |
|
Protein Sequence
|
MDASSTTPFPFPQPPRVPSAAPVAGALPWSRVGEIVIFTFVSVLGLYLLWLWVLKDCILLLKAQRGRSTEELIFGPGERPAVASADGSRSVPDPSPSCPPGPRPFVV |
|
NCBI Accession
|
NP_042589.1
|
|
Location
|
479-1225 |
|
Gene Name
|
CP |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCCGGAGCTTTGAAGCGCAAGCGTTCGGATGAGGTTGCCTGGAGTCGAAGGAAGCCCGTCAAGAAGCAAGACACCGGGTTCCCCCTCCCCCGGGCTGGCCCCTCTGTCAGGAGAGGACTCCCTGCCCTTCAGATCCAGACGCTTACGGCGGCTGGTGACACTATGATCACGGTGCCGTCCGGCGGCATCTGCAGTCTGATTGGCACGTATGCCCGGGGCTCTGATGAAGGTAACCGCCACACCAACGAGACTCTGACGTACAAGGTTGCGCTGGACTACCACTTCGTTGCTACTGCTGCGGCCTGCAAGTACTCCAGCATTGGAGTGGGTGTCATGTGGTTGGTGTATGATGCGCAGCCGACCGGCAATTCACCGGAGGTGAAGGACATCTTCCCTCACTCCGATACGCTCTCAGCGTTCCCGTACACTTGGAAGGTTGGCAGGGAGGTCTGCCATCGCTTCGTTGTTAAACGGCGCTGGTGCTTCACCATGGAGACTAACGGCCGGATCGGTTCAGATGTGCCTCCGGCCAATACCGCTTGGCCGCCTTGCAAGAAGGACATCTACTTCCACAAGTTCTGCACGGGACTCGGCGTGAAGACGGAGTGGAAGAACGTTACAGACGGGAAGGTCGGCGCTATTAAGAAGGGCGCCTTGTACATTGTCATTGCGCCTGGAAACGGGCTTGAGTTTACGGTTCACGGCCAGTGCCGTCTGTACTTTAAGTCAGTTGGTAATCAGTGA |
|
Protein Sequence
|
MSGALKRKRSDEVAWSRRKPVKKQDTGFPLPRAGPSVRRGLPALQIQTLTAAGDTMITVPSGGICSLIGTYARGSDEGNRHTNETLTYKVALDYHFVATAAACKYSSIGVGVMWLVYDAQPTGNSPEVKDIFPHSDTLSAFPYTWKVGREVCHRFVVKRRWCFTMETNGRIGSDVPPANTAWPPCKKDIYFHKFCTGLGVKTEWKNVTDGKVGAIKKGALYIVIAPGNGLEFTVHGQCRLYFKSVGNQ |
|
NCBI Accession
|
NP_042590.1
|
|
Location
|
1590-2564 |
|
Gene Name
|
RepA |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGTCGACCTCTCTGTCTATCACCTCAGATGGCAGGCACAGCGTCCGGTCCTTCAGGCACCGGAACGCGAACACCTTCCTCACATACAGCAAGTGTCCACTAGAACCTGAGTTCATCGGTGAGCATCTCTTCAGGCTCACTAAGGACTTTGAGCCAGCATACATCCTGGTAGTGAGAGAGACTCACCAAGACGGAACATGGCACTGCCATGCTCTTCTCCAGTGCATCAAGCCTGTCACTACTCGTGACGAGAGGTACTTTGACATAGATCGGTATCATCCGAATATACAGAGCGCCAAGAGCACTGACAAGGTACGTGAGTACATACTGAAGGATCCCAAGGACAAGTGGGAGAAAGGTACTTACATACCAAGGAAGAAGAGCTTCGTTCCTCCAGGTAAGGAAAACTCTGAGAAGAAGCCTTCTAAGGATGAGGTCATGAAGGAGATCATGACACATGCCACTAGCAGAGCAGAGTACCTTTCACTAGTGCAGACTTCACTGCCTTACGACTGGGCCACAAAACTGTCATACTTTGAGTACTCAGCTAGTCGCCTGTTCCCGGACATTGCAGAGCCTTACAGCAATCCTCATCCTGCCACTGACCCTGACCTCCTCTGCAACGAAACACTCCAGGACTGGCTTGAGCCTAACATCTACCAGGTCAGTCCTAAAGCATACATGCTCCTTGAACCTAGCTGCTTAAGCCTAGAGCAAGCCAAAGCTGACTTAGAATGGTTGTCTGAAACAACCAGATTATTCCAGGAGCAAGAAAGCGAAGCCTCTACATCGTCGGCCCAACACGGACAGGTAAAACATCCTGGGCCAGAAGCCTCGGACGGCACAACTACTGGCAGAATAACATCGACTGGTCTTCATACGATGAAGAAGCTGCGTACAATGTCGTGGACGACATTCCCTTCAAGTTCTGTCCGTGCTGGAAGCAGCTCGTCGGCTGTCAAAAAGACTACATAG |
|
Protein Sequence
|
MSTSLSITSDGRHSVRSFRHRNANTFLTYSKCPLEPEFIGEHLFRLTKDFEPAYILVVRETHQDGTWHCHALLQCIKPVTTRDERYFDIDRYHPNIQSAKSTDKVREYILKDPKDKWEKGTYIPRKKSFVPPGKENSEKKPSKDEVMKEIMTHATSRAEYLSLVQTSLPYDWATKLSYFEYSASRLFPDIAEPYSNPHPATDPDLLCNETLQDWLEPNIYQVSPKAYMLLEPSCLSLEQAKADLEWLSETTRLFQEQESEASTSSAQHGQVKHPGPEASDGTTTGRITSTGLHTMKKLRTMSWTTFPSSSVRAGSSSSAVKKTT |