Chilli leaf curl Bhavanisagar virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_004786875.1 |
| Isolate |
India: Tamil Nadu |
| Release date |
2021/6/1 |
| Submitter |
Parvathy,K., Angappan,K., Malathi,V.G., Richa,S., Jyothsna,P., Jeevalatha,A., Nirmal Kumar,R. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
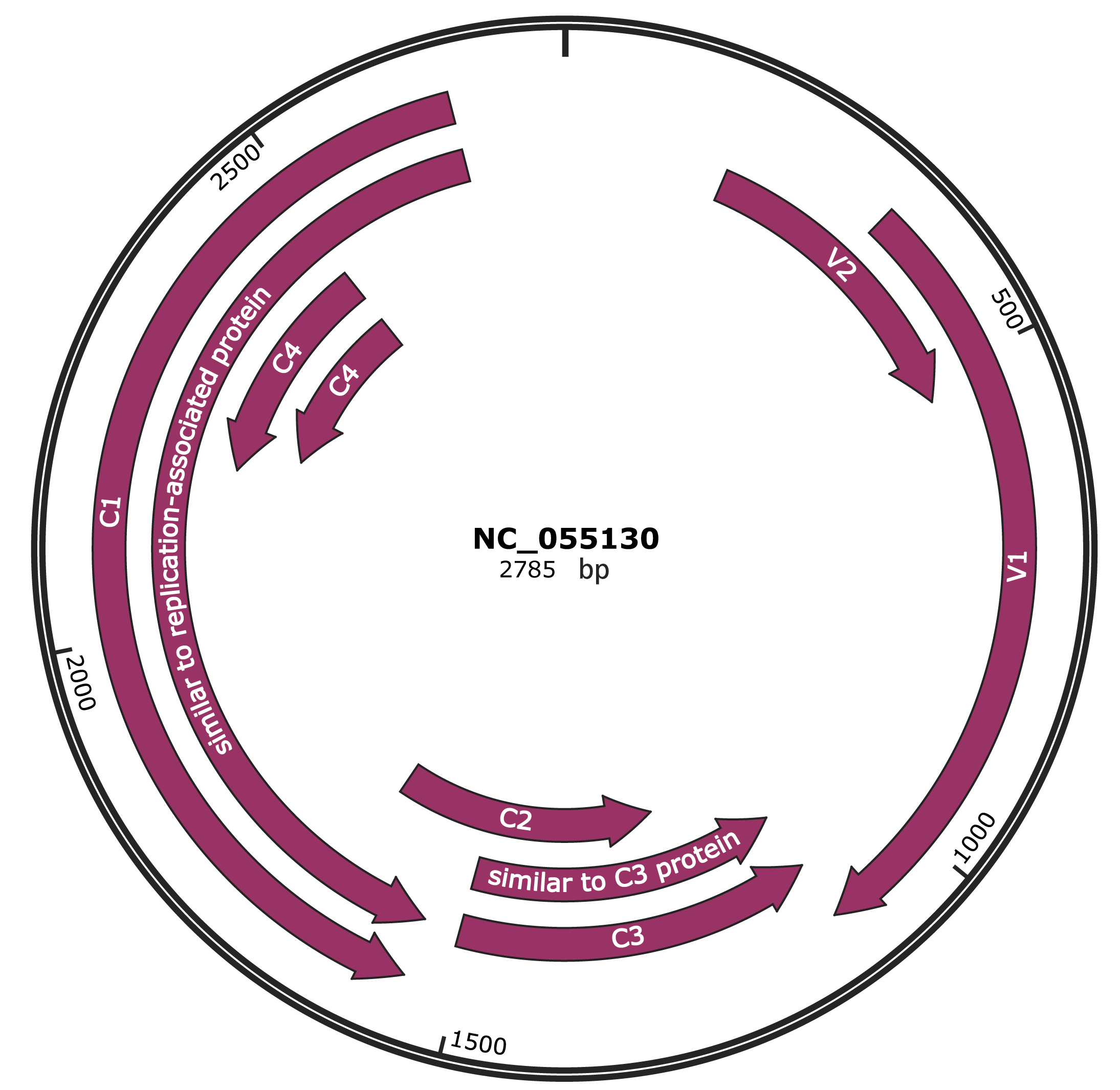
JBrowse
Genome
ACCGGATGGCCGCGTACCCTCCAGTCGCTTTCATGGACCCCACGTGTGTCTTATCCCCTTTGTCTTTTCTGCGGGCCCCACCACATTCACATGTTAGCCAATCATATTTCAGCCTCAAAGCTTAATTATTTATGTGGGCCCCTATATATACTTGGTCCCCAAGTTTAACAGTCATTTACCATGTGGGACCCACTAGTAAATGATTTTCCTGAAACGGTGCATGGGTTTAGGTGTATGCTTGCTATAAAATACCTGCACCTAGTAGAAAATACGTATTCCCCTGATTCATTGGGATACGACCTGATACGTGAATTAATTTCCGTAGTTAGGGCTAAAAATTATGTCCAAGCGACCAGCAGATATGATCATTTCCGGGCCCGTCTCGAAGTATCGTCGATTGCTGACCTCAACCAGCCCATACAGCAAGCGTGCTGCTGTCCGCATTGTCCGCGCCACAAAGGGAAAGGAATGGGCCAACAGGCCCATGAATCGGAAGCCCATGTTCTACAGAATGTACAGAAGCCCTGATGTTCCGAGGGGCTGTGAAGGCCCATGTAAGGTCCAGTCATTTGAGTCGAGACACGATGTAGTCCATATAGGGAAGGTCATGTGTATCAGCGATGTTACCAGGGGTACAGGTCTGACCCATAGAGTAGGTAAACGTTTCTGCGTTAAGTCCGTTTATGTTCTGGGCAAGATATGGATGGACGAAAACATTAAAACCAAAAATCACACTAACAGTGTTATGTTCTTCCTCGTTCGTGATCGTCGTCCGGTAGATAAGCCGCAAGATTTTGGGGATGTATTTAACATGTTCGACAACGAGCCGAGCACGGCGACTGTGAAGAATGTGCATAGGGATCGTTATCAGGTTCTCCGGAAGTGGCATGCAACCGTCACTGGTGGACAGTATGCGTCAAAGGAACAGGCGTTAGTGAAGAAGTTTGTTAGGGTTAATAATTATGTTGTGTATAACCAGCAAGAGGCTGGCAAGTATGAGAATCATAGTGAGAATGCTCTGATGTTGTATATGGCATGTACGCATGCCTCTAACCCCGTGTATGCGACATTGAAAATACGCATCTATTTCTACGATTCAGTGACAAATTAATAAATATTGTATTTTATTATGTTTGAACTCTGTACATACACTGTTTTTGTCAACACATTCCATAATACATGATCAATAGCTCGAATTACATTATTTAGGCTAATTACAGCAAAATTATTAAGACACTGCATTACTTGGGTCCTAAATACCCTTAAGAAATGACCAGTCTGAGGCTGTAAGGTCGTCCAGATTCGGAAGGTTAGAAAACATTTGTGTATCCCCAACGCTTTCCGAAGGTTGTGGTTGAACTGGACCCTTACAGTTATCATGTCCTTGTTGTAGTTGAGGGTCGTCTGTGGTGGCTGAGGATTGTGAAATACACGGGATTTGGGACCTGCCACATCCGGACGCCATTCGTTGCCTGAGCTGCATTGATGCGTTCCCCTGTGCGTAAATCCATAATTCCTGCAATTTATATTCATGTAGTATGAACAACCACACTCAAGGTCGACTCTCTTCCGCCTGATGCTCCTCTTGTATTGCCTGTGGAGAACCTTGATGGGTACCGGAGTAGAGTGGGCCTGTGAGGGTGACGAAGATTGCATTCTTGAGTGCCCAATTCTTTAATGCAGAATGCTTTTCTTCGTCCAGGTACTCTTTATAGCTGGAGTTGGGCCCTGGATTGCAGAGGAAGATAGTGGGAATGCCACCTTTAATTTGAACTGGCTTTCCGTATTTGGTGTTGCTTTGCCAGTCTTTTTGGGCCCCCCATGAATTCCTTAAAGTGCTTTAAGTAATGGGGGTCTACGTCATCAATGACGTTATACCATGCGTCATTGGAATAAATCTTTGGGCTTAAGTCCAAATGTCCACATAAATAGTTATGTGGACCCAAGGACCTGGCCCATATTGTCTTCCCCGTACGACTATCACCCTCAACAACTACACTTACGGGCCTTATCGGCCGCGCAGCGGCCCCCCACAACATTATCTGCAGCCCATTCTTCAAGTTCATCGGAACTTGATCAAAAGAAGAAAGAGAAAAAGGAGAAACATAACCTCTCGTGGAGGTGCAAAAATCCTATCTAAGTTGGATTTTAAATTATGATATTTAAAAATAAAATCATGGGGGAGTTTCTCCCTTATTATTGCCAGAGCGGCATCAGCGGAGCCTGAATTTAGGGCCTCTGCTGCAGCATCATTAGCTGTCTGTTGACCTCCTCTAGCAGATCTTCCATCGACCTGAAAGTCACCCCAGTCGATGTAATCACCGTCCTTCTCGATGTAGGACTTGACATCTGATGAGGACTTAGCTCCCTGGAAGTTTGGATGGAATTGGGATGAGGTGTTAGGGTGAGTGACATCGAAATGTCTGGGGTTTCTGAACTGGGCTTTACCCTTGAACTGGATGAGGGCATGGACATGCAGAGACCCATCTTGATGTTTTTCCTGCGCAACTCTTATAAATAATTTATCAGATGGACAGTTAATGCCCTTGATGAGTTCTAACATTTGTTCTTTGGGTATGGGGCATTTTGGGTATGTTAGAAAAATATTTTTGGCTTTAACCTGAAACGACGTCGGACGTGTCATTCTGTATTGGGTGCTCTCAAAACTCTGTGGCAATTGGGGGCTTTGGGGGCTCTTATATATGAAGCCCCCAAATGGCATTACGGTAAATTGGAGGAAATTGCCAATCAATTTCCCGCCAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_010084337.1
|
|
Location
|
181-528 |
|
Gene Name
|
V2 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGTGGGACCCACTAGTAAATGATTTTCCTGAAACGGTGCATGGGTTTAGGTGTATGCTTGCTATAAAATACCTGCACCTAGTAGAAAATACGTATTCCCCTGATTCATTGGGATACGACCTGATACGTGAATTAATTTCCGTAGTTAGGGCTAAAAATTATGTCCAAGCGACCAGCAGATATGATCATTTCCGGGCCCGTCTCGAAGTATCGTCGATTGCTGACCTCAACCAGCCCATACAGCAAGCGTGCTGCTGTCCGCATTGTCCGCGCCACAAAGGGAAAGGAATGGGCCAACAGGCCCATGAATCGGAAGCCCATGTTCTACAGAATGTACAGAAGCCCTGA |
|
Protein Sequence
|
MWDPLVNDFPETVHGFRCMLAIKYLHLVENTYSPDSLGYDLIRELISVVRAKNYVQATSRYDHFRARLEVSSIADLNQPIQQACCCPHCPRHKGKGMGQQAHESEAHVLQNVQKP |
|
NCBI Accession
|
YP_010084338.1
|
|
Location
|
341-1111 |
|
Gene Name
|
V1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCCAAGCGACCAGCAGATATGATCATTTCCGGGCCCGTCTCGAAGTATCGTCGATTGCTGACCTCAACCAGCCCATACAGCAAGCGTGCTGCTGTCCGCATTGTCCGCGCCACAAAGGGAAAGGAATGGGCCAACAGGCCCATGAATCGGAAGCCCATGTTCTACAGAATGTACAGAAGCCCTGATGTTCCGAGGGGCTGTGAAGGCCCATGTAAGGTCCAGTCATTTGAGTCGAGACACGATGTAGTCCATATAGGGAAGGTCATGTGTATCAGCGATGTTACCAGGGGTACAGGTCTGACCCATAGAGTAGGTAAACGTTTCTGCGTTAAGTCCGTTTATGTTCTGGGCAAGATATGGATGGACGAAAACATTAAAACCAAAAATCACACTAACAGTGTTATGTTCTTCCTCGTTCGTGATCGTCGTCCGGTAGATAAGCCGCAAGATTTTGGGGATGTATTTAACATGTTCGACAACGAGCCGAGCACGGCGACTGTGAAGAATGTGCATAGGGATCGTTATCAGGTTCTCCGGAAGTGGCATGCAACCGTCACTGGTGGACAGTATGCGTCAAAGGAACAGGCGTTAGTGAAGAAGTTTGTTAGGGTTAATAATTATGTTGTGTATAACCAGCAAGAGGCTGGCAAGTATGAGAATCATAGTGAGAATGCTCTGATGTTGTATATGGCATGTACGCATGCCTCTAACCCCGTGTATGCGACATTGAAAATACGCATCTATTTCTACGATTCAGTGACAAATTAA |
|
Protein Sequence
|
MSKRPADMIISGPVSKYRRLLTSTSPYSKRAAVRIVRATKGKEWANRPMNRKPMFYRMYRSPDVPRGCEGPCKVQSFESRHDVVHIGKVMCISDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNSVMFFLVRDRRPVDKPQDFGDVFNMFDNEPSTATVKNVHRDRYQVLRKWHATVTGGQYASKEQALVKKFVRVNNYVVYNQQEAGKYENHSENALMLYMACTHASNPVYATLKIRIYFYDSVTN |
|
NCBI Accession
|
YP_010084339.1
|
|
Location
|
2230-2487 |
|
Gene Name
|
C4 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGGTCTCTGCATGTCCATGCCCTCATCCAGTTCAAGGGTAAAGCCCAGTTCAGAAACCCCAGACATTTCGATGTCACTCACCCTAACACCTCATCCCAATTCCATCCAAACTTCCAGGGAGCTAAGTCCTCATCAGATGTCAAGTCCTACATCGAGAAGGACGGTGATTACATCGACTGGGGTGACTTTCAGGTCGATGGAAGATCTGCTAGAGGAGGTCAACAGACAGCTAATGATGCTGCAGCAGAGGCCCTAA |
|
Protein Sequence
|
MGLCMSMPSSSSRVKPSSETPDISMSLTLTPHPNSIQTSRELSPHQMSSPTSRRTVITSTGVTFRSMEDLLEEVNRQLMMLQQRP |