Miscanthus streak virus
Basic Information
| Genus |
Mastrevirus
|
| NCBI Assembly |
GCF_000839945.1 |
| Release date |
2015/2/12 |
| Submitter |
Chatani,M., Matsumoto,Y., Mizuta,H., Ikegami,M., Boulton,M.I., Davies,J.W. |
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
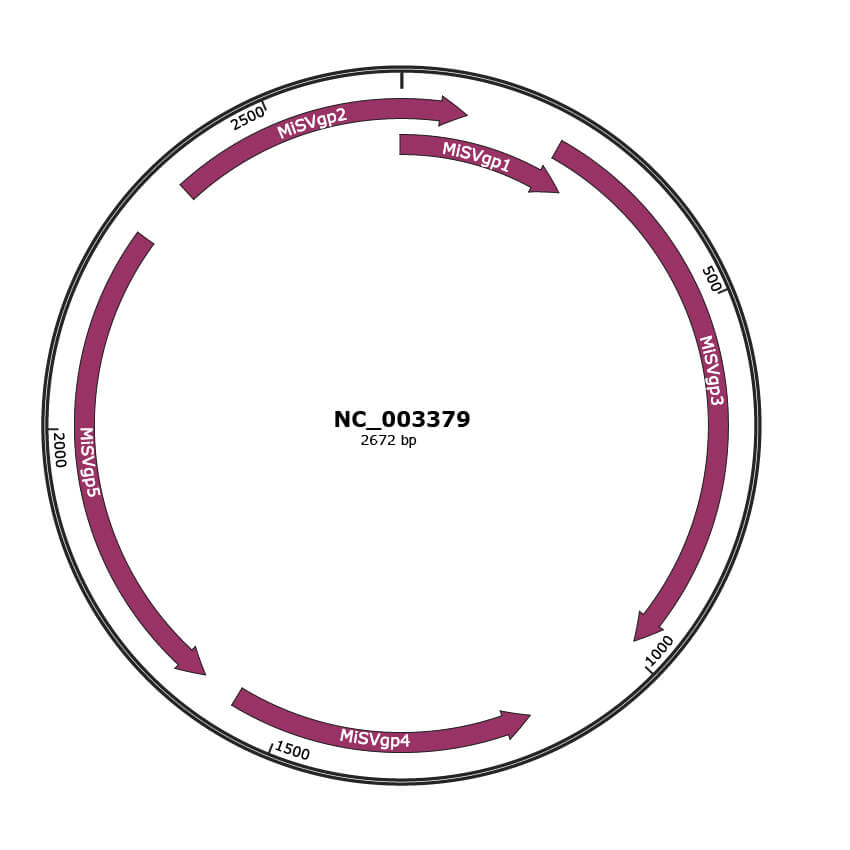
JBrowse
Genome
GGATCCCTATGGTAGCCGTCCTAGCCATCCTGATGATGGTGCACTGCATGGTATACTTGTGGCATTTATTGCGGTGCTTTGCCTCATAGGTTGCCTTTGGGCAGCATACCGACTGTTCCTTAAGGAGTGCCTTACTGATTGCAGTCAGCACACTTCATCAGGCGTCGTCGCGGGTCCTCGTCCGGCTGCAACAGGTCCTACTGCTGTTGTTGTACATAATGGTGCAGAAGCGCAAAGATCTTCGGCGTTCTGATGCCGGTTCTGCCGTTCGGGCCAAACTGCATAAGGCCTCGACTGGGAAGGCCTTCCCTGTAGGGAAGCGGGCTCCTCTGCAGATACGGTCCTATGCATGGGAGACGCCTGCCACGGCGACCACCCCTTCCGGACCTATCAGTATTACTGACGGTACCATCTTCATGTGTAACACCATTGACCCTGGGACTGGAGACGATCAGAGATCGCGGCATACCACGATGCTCTATAAGATGTCATTGAACGTGGTGCTCTGGCCTGGTGCGACTACGGCCCAAATAGTTGGGCCTTTCCGCGTGAACTTCTGGCTTGTGTATGATGCTGCCCCGACTGGAGTTGTCCCGAAGCTGACGGACATCTTTGACGTGGCCTATCCGAAGTGGGGAAACACTTGGCAGGTTTCCCGCTCTAATGTGCATAGGTTCATAGTTAAGCGTAAATGGAAGGTGGACTACCAGTCCTCTGGCGTCCCTGTTGGCAAGAGACAGAGCAGCGGTGTTGAATACGCCCCTGTTAATAATGTGGTGGAGTGCAACAAGTTCTTCGAGAAGCTGCGTGTGAAGACCGAATGGGCGAACACCTCTACCGGTGCAATTGGGGACGTGAAGAAGGGTGCGTTGTACCTGTGTGCCAATACCCGGCAGATGCCTGCTGGTGACTCAGTCACCACGAGTTGTACCACCATGATGCAAGGGTCTACCCGATTGTACTTCAAAGTGCTGGGGAACCAGTAATAATAAAAACTTATTTATTATATATTGCAAACCTGTGGATTACATGATAATGTGAGCGCATTATGCGCGACAACAAACTCAAGAAATTACATAAATTTGGGGGGTAGGGGCAAAGCAGGCGGCTATGGGCGCGCCCGCGGGCAACACACTTAAAAAAAACACAACAATAGATTCACTCTTCGGCCGGCAGGACGTAGAACTTCTGTCCTTCGTACATGTAATGTACGTGGGCGTTCGCGTGCAGGTACTCCACTTGTGCAGGTTTCATGTCCTTGATCCAGTCTTCGTCGTCATTGGTTAGAATGATGGACGGGATTCCCCCAGGGATTTTCTTCTTCTTACCGTACTTGGGATTCACTATGTAGTCACGCTGTGCTCCCACCAGCGCCTTCCACTGCGGCAAGAACTTGAAAGGCACATCGTCGATGACGTTGTAGATTGCATCTTTGTCATAGTGTGTGAAGTCTACGGTTGAGTTGTAGTAGTTGTGCCTCCCGATGTTTCTGGCCCAAGTGGTCTTTCCAGTTCGGCTTGGGCCGCAGATGTATATGCTTCGTGGTCTCCGCGGCCCGTTAGGCTGTATTCAAACCACTGTTGGTTTGTAAGTATTCAAGAAATTTGAAAGAGTGAAGCTTAATCGGTAGTTACCTGGTTCCATTCCTGGTCTATGATGTCAACGAGCTCCGGCGGACAGACGATCTGCTCATTTGGGAACGGTGACTGATATACCGGAGGTGGTTCGGTAAACAAGGCTGCTGCACTGTATTCAAACTGCTGGAGTCTGATGGCCCAGTCAAATGGGAATTCTTTACGGACCATGGACAGGTATTCATTCCTATTGGTGGAGGAGGCTATTATCATAGCCATCCTTTGATCACGGGTAGGCTTCTCGGGTTTCTTGATCCTGAGTTGGAGTTCACCCATTTCATCAGAGTCACCGTTGGTTTTGGATATGTATCCGAAAACCTTTTCAGCATCTCTGACGGGCTGAATGTTTGGGTGGAAACCCTGAACATCAAAGAACTTGGGGTTCCTTGTGCATAGTTTGGTGTTTAGCTGTATAAGGACATGGAGATGCGGGTCCCCGTCCTTATGGAACTCTTGGGATACCTTAATGTATCCTGGAATTTTCTCGGTCAGGCGAGAGAACAATTCCTTCATCAGCTCGGATGGTGTTAGGTTGCAGTGTGGATAGGTAAGGAAGAATTGCTTGCTGTTCCAACGTGGTGTTGGATGGTTTGAAGGACCAGGACGGTTGGATGCTGCAGATGATGCAGGTGCCCTCATCTCTACTACTCTATGGGTGTGGCTCCGATGCTCTCAGAAAACTTGCTACTGGTTTCGCTGGTGCCGGTGCCACCCCTCGTTAGATGGGCTGCGTATTTATAATGGGCCGGCGGGGGAGCGAAACCAATAATATTACCGCTCCCCCTCCCTGGCCCATTAGTAGGCCCCTTGCCTCGGTGCGCTGCGCCTTTGGTCCCCGTTCCTTGCCGCCTTTGGCAGAAGATCGCACTCAGGCTGCTGTAAAATGGCACCGCCATTTGAGTGTTTTTGCTTTGGTGCCTTTGGTTTGCGGCTTTAAAAAGAGGCGGAGGCTCAGAGATCGCACCAAAACCAAAGGTACGCAGGTTGCTTGTCTTCGAACTTGGGTCATTAAGTTTTGCTTCGTTTGTAAGTTTTTAT
Gene Information
|
NCBI Accession
|
NP_569143.1
|
|
Location
|
join(2357-2672,1-89) |
|
Protein Name
|
hypothetical protein |
|
Coding Region
|
ATGGGCTGCGTATTTATAATGGGCCGGCGGGGGAGCGAAACCAATAATATTACCGCTCCCCCTCCCTGGCCCATTAGTAGGCCCCTTGCCTCGGTGCGCTGCGCCTTTGGTCCCCGTTCCTTGCCGCCTTTGGCAGAAGATCGCACTCAGGCTGCTGTAAAATGGCACCGCCATTTGAGTGTTTTTGCTTTGGTGCCTTTGGTTTGCGGCTTTAAAAAGAGGCGGAGGCTCAGAGATCGCACCAAAACCAAAGGTACGCAGGTTGCTTGTCTTCGAACTTGGGTCATTAAGTTTTGCTTCGTTTGTAAGTTTTTATGGATCCCTATGGTAGCCGTCCTAGCCATCCTGATGATGGTGCACTGCATGGTATACTTGTGGCATTTATTGCGGTGCTTTGCCTCATAG |
|
Protein Sequence
|
MGCVFIMGRRGSETNNITAPPPWPISRPLASVRCAFGPRSLPPLAEDRTQAAVKWHRHLSVFALVPLVCGFKKRRRLRDRTKTKGTQVACLRTWVIKFCFVCKFLWIPMVAVLAILMMVHCMVYLWHLLRCFAS |
|
NCBI Accession
|
NP_569144.1
|
|
Location
|
join(2671-2672,1-253) |
|
Protein Name
|
hypothetical protein |
|
Coding Region
|
ATGGATCCCTATGGTAGCCGTCCTAGCCATCCTGATGATGGTGCACTGCATGGTATACTTGTGGCATTTATTGCGGTGCTTTGCCTCATAGGTTGCCTTTGGGCAGCATACCGACTGTTCCTTAAGGAGTGCCTTACTGATTGCAGTCAGCACACTTCATCAGGCGTCGTCGCGGGTCCTCGTCCGGCTGCAACAGGTCCTACTGCTGTTGTTGTACATAATGGTGCAGAAGCGCAAAGATCTTCGGCGTTCTGA |
|
Protein Sequence
|
MDPYGSRPSHPDDGALHGILVAFIAVLCLIGCLWAAYRLFLKECLTDCSQHTSSGVVAGPRPAATGPTAVVVHNGAEAQRSSAF |
|
NCBI Accession
|
NP_569145.1
|
|
Location
|
219-986 |
|
Protein Name
|
hypothetical protein |
|
Coding Region
|
ATGGTGCAGAAGCGCAAAGATCTTCGGCGTTCTGATGCCGGTTCTGCCGTTCGGGCCAAACTGCATAAGGCCTCGACTGGGAAGGCCTTCCCTGTAGGGAAGCGGGCTCCTCTGCAGATACGGTCCTATGCATGGGAGACGCCTGCCACGGCGACCACCCCTTCCGGACCTATCAGTATTACTGACGGTACCATCTTCATGTGTAACACCATTGACCCTGGGACTGGAGACGATCAGAGATCGCGGCATACCACGATGCTCTATAAGATGTCATTGAACGTGGTGCTCTGGCCTGGTGCGACTACGGCCCAAATAGTTGGGCCTTTCCGCGTGAACTTCTGGCTTGTGTATGATGCTGCCCCGACTGGAGTTGTCCCGAAGCTGACGGACATCTTTGACGTGGCCTATCCGAAGTGGGGAAACACTTGGCAGGTTTCCCGCTCTAATGTGCATAGGTTCATAGTTAAGCGTAAATGGAAGGTGGACTACCAGTCCTCTGGCGTCCCTGTTGGCAAGAGACAGAGCAGCGGTGTTGAATACGCCCCTGTTAATAATGTGGTGGAGTGCAACAAGTTCTTCGAGAAGCTGCGTGTGAAGACCGAATGGGCGAACACCTCTACCGGTGCAATTGGGGACGTGAAGAAGGGTGCGTTGTACCTGTGTGCCAATACCCGGCAGATGCCTGCTGGTGACTCAGTCACCACGAGTTGTACCACCATGATGCAAGGGTCTACCCGATTGTACTTCAAAGTGCTGGGGAACCAGTAA |
|
Protein Sequence
|
MVQKRKDLRRSDAGSAVRAKLHKASTGKAFPVGKRAPLQIRSYAWETPATATTPSGPISITDGTIFMCNTIDPGTGDDQRSRHTTMLYKMSLNVVLWPGATTAQIVGPFRVNFWLVYDAAPTGVVPKLTDIFDVAYPKWGNTWQVSRSNVHRFIVKRKWKVDYQSSGVPVGKRQSSGVEYAPVNNVVECNKFFEKLRVKTEWANTSTGAIGDVKKGALYLCANTRQMPAGDSVTTSCTTMMQGSTRLYFKVLGNQ |
|
NCBI Accession
|
NP_569146.1
|
|
Location
|
1159->1568 |
|
Protein Name
|
hypothetical protein |
|
Coding Region
|
CAGCCTAACGGGCCGCGGAGACCACGAAGCATATACATCTGCGGCCCAAGCCGAACTGGAAAGACCACTTGGGCCAGAAACATCGGGAGGCACAACTACTACAACTCAACCGTAGACTTCACACACTATGACAAAGATGCAATCTACAACGTCATCGACGATGTGCCTTTCAAGTTCTTGCCGCAGTGGAAGGCGCTGGTGGGAGCACAGCGTGACTACATAGTGAATCCCAAGTACGGTAAGAAGAAGAAAATCCCTGGGGGAATCCCGTCCATCATTCTAACCAATGACGACGAAGACTGGATCAAGGACATGAAACCTGCACAAGTGGAGTACCTGCACGCGAACGCCCACGTACATTACATGTACGAAGGACAGAAGTTCTACGTCCTGCCGGCCGAAGAGTGA |
|
Protein Sequence
|
QPNGPRRPRSIYICGPSRTGKTTWARNIGRHNYYNSTVDFTHYDKDAIYNVIDDVPFKFLPQWKALVGAQRDYIVNPKYGKKKKIPGGIPSIILTNDDEDWIKDMKPAQVEYLHANAHVHYMYEGQKFYVLPAEE |
|
NCBI Accession
|
NP_569147.1
|
|
Location
|
1620-2273 |
|
Protein Name
|
hypothetical protein |
|
Coding Region
|
ATGAGGGCACCTGCATCATCTGCAGCATCCAACCGTCCTGGTCCTTCAAACCATCCAACACCACGTTGGAACAGCAAGCAATTCTTCCTTACCTATCCACACTGCAACCTAACACCATCCGAGCTGATGAAGGAATTGTTCTCTCGCCTGACCGAGAAAATTCCAGGATACATTAAGGTATCCCAAGAGTTCCATAAGGACGGGGACCCGCATCTCCATGTCCTTATACAGCTAAACACCAAACTATGCACAAGGAACCCCAAGTTCTTTGATGTTCAGGGTTTCCACCCAAACATTCAGCCCGTCAGAGATGCTGAAAAGGTTTTCGGATACATATCCAAAACCAACGGTGACTCTGATGAAATGGGTGAACTCCAACTCAGGATCAAGAAACCCGAGAAGCCTACCCGTGATCAAAGGATGGCTATGATAATAGCCTCCTCCACCAATAGGAATGAATACCTGTCCATGGTCCGTAAAGAATTCCCATTTGACTGGGCCATCAGACTCCAGCAGTTTGAATACAGTGCAGCAGCCTTGTTTACCGAACCACCTCCGGTATATCAGTCACCGTTCCCAAATGAGCAGATCGTCTGTCCGCCGGAGCTCGTTGACATCATAGACCAGGAATGGAACCAGGTAACTACCGATTAA |
|
Protein Sequence
|
MRAPASSAASNRPGPSNHPTPRWNSKQFFLTYPHCNLTPSELMKELFSRLTEKIPGYIKVSQEFHKDGDPHLHVLIQLNTKLCTRNPKFFDVQGFHPNIQPVRDAEKVFGYISKTNGDSDEMGELQLRIKKPEKPTRDQRMAMIIASSTNRNEYLSMVRKEFPFDWAIRLQQFEYSAAALFTEPPPVYQSPFPNEQIVCPPELVDIIDQEWNQVTTD |