Maize striate mosaic virus
Basic Information
| Genus |
Mastrevirus
|
| NCBI Assembly |
GCF_004130985.1 |
| Isolate |
Brazil |
| Release date |
2019/2/12 |
| Submitter |
Fontenele,R.S., Alves-Freitas,D.M.T., Silva,P.I.T., Foresti,J., Silva,P.R., Godinho,M.T., Varsani,A., Ribeiro,S.G., Tanno,P.I., Freitas,D.M.T.A. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
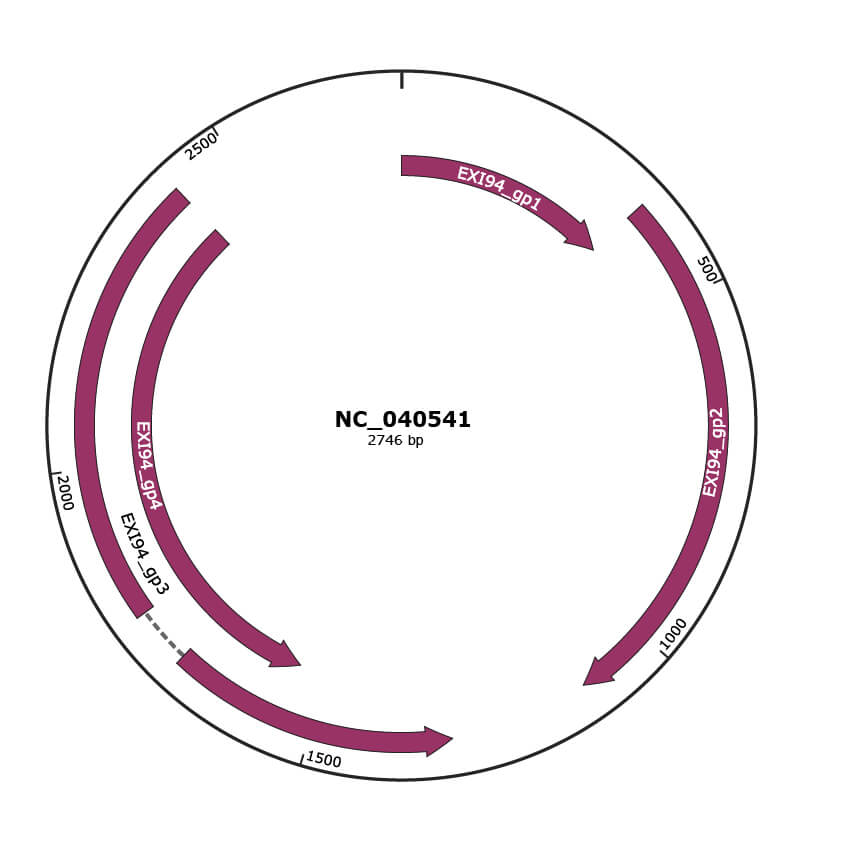
JBrowse
Genome
ATGGATTTTCTTTTGCAATTATTGCCGTTCTATCGCTATAAATCTTTACTCAGTGCTGTTGCCTTTGAGATGGAGAAGGGACCTGGTCCAGAGGTGTTTTCGCCCCCAGTGGTTGAGGTGCCTTTCTCCGAAACTCCCAGTGCTGGCTCGGACCAGACCTGGCGAACCTTGGTTCTTGTCTTCCTGTTCGTGGCTCTTAGTATCGGTATTGTTGCAGCTCTCTACTGGGTCTGTGTGCGTGACTGTGTGTTATCGGCTCGTGCGAAACGGGCCAGGACAATAACCGAGTTCGGTTTCGGCAACACTCCGGGTGATCGGAGGGCTCCTCCTCCGCAGGCCCTTGCAGCTGGTGGCCCTGTCTGATGCGTCCAATGACGGGAAAGAGGAAGAGGACCGCTGGTAGTTCTTCGGTAAATCGTCGGAAGTCCCGCCGTGTTTTACCTAGGACTGTGGCTCCGTATTCCCAGCTACCTTCCAGGCTTCCGAGCCTCCAGGTGCAAACATTTGCTTCGCAGGGTTCTGCCGTGGTGGAAGTTAAGAAGGGTGGTAATTGTCTGATGGTTACCTCCTACAGCCGTGGCTCTGACGAGAGTCAGAGACACACCAATGAGACCATGACCTACAAGATGTCGTTGGACCACGTCATGGTGTTACGTGCGGAGCTCTGTAAGTATAGCTTCAAGGCTACCCACTGTGGTTGGGTTGTGTATGACGCTAAACCCACGGGCAACCAGGTTACGTGCAAGACTATATTCGGCTACCCGGACGGGCTTGTGGATTACCCCACGACCTGGAAGGTTGCACGTGACGTGGCTCATCGCTTCGTGGTGAAGAAACGTTGGACCTACCGGATGGAATCCAATGGGTCTAACTCGTCTAAGGATTGGAGTAATGGGACTGGTATACCTCCTTGCAACCGGTCGGTGTACGTCAAGCAGTTCGTGAGCAAGCTCAACTGCCGAACGGAGTGGAAGAACACCACCGGGGGTGACTATGGCGATATCAAAGGCGGAGCCCTCTATGTTGTGCTCGCTGCCGGCCAAGGCATGGAGCACATGGCCTATGGTACCACGAGGATGTATTTCAAGAGCATCGGGAACCAGTGATATGTAACACACATATATATGTATTAATAAAGAGTCATGAGATACATCTTTATTCCTTACAAAGACTTAAGTATTAAGAAACTTAAGCTTTTCGGCGAGACGTTGGCGGTAAGTGGTCGAGTGCCTGAAAAGCGCCTCTCGTCTAAGCTTCTTTCACACAAACCAAACACAATTTAGATTACATGCAGCCGCCGGCCTATTCGGCATAGTTGAAGAATGATTCGCCTGGAGTCATGTGGTACACTACACAATTCTCCAGAAACCAGTCTATCTGACTGGTTGTCATGCTCATGAGCCAGTCCTCGTCCTCGTTCACCAATATAATGGCCGGTATTCCTCCTTTTATTTTTCTTTTTTTACCGTATTTAGGGTTGACGGTGTAATCATGCTGGCTCCCCACGATCGCCTTCCAGTTCGGGCAGAACTTGAAAGGTATGTCGTCTATGACGACATACGTGGCCTCTTCGCTCCAGGCGAAGTAGTCCACCTGGTGTTGGAAGTAGTTGTGTGGCCCGAGGCTTCTTGCCCATGTTGTCTTGCCCGTCCTCGTTCTTCCGCATATGTAGAGGCTTCGGGGACGTCTTCCTTGCCCTCGTTCCTTGTATGGTCCGCCATCCACGTCAGATCTCCCTTCGGATCGAGTGATCCTGTACATAGGAAGTAAGAGAATTCGCTTACAGTGTACAGGTCGTCCCGCAGCCAGGGCATGATGTTCTCATGGCAGGTGAGATCAATGTTTGACGGGATGGCATTCGTCGTGGGAGCATCTGGAAATAGCTTGGATGCACTGTATTCAAATTGGGCCAGTTTAGTAGCCCATTCAAACGGGAAGGCACCTCTGACCATTGAGAGGTAATCGCTCCTAGAGGTGGCAGAAGACATGATCTGACACATCTTGGCGTCCCGGCTTGGTGCCGAGTCTTGTTTCTTCGGCCTTCCAGCTCCACTGCACTTGAATGCTCCCTTGGATACTTCGTTAATGGTGTTCTTCCGTATGTACGCCAAACAGTCACGGACGTTTCTGCATGCCTGTATGTTAGGGTGAAAGACAACTGCACCAGGAATACTAGTCCCAGTGTAGTCAAAATACGTAGGATCGAAAGTGCTGATTTCGATCCTGGTTTGAATGAGGACGTGGCTGTGTAGCCCACCGTCCTTGTGATTTTCTTGAGCAACGTGTACGTAGAGTGGATCATAAGGGGTAACGAGGTTCCAGAGATGATCACAAAGAAACTCAGGGCCAATAGGACAGCGTGGGTACGTGAGGAAGACATTCTTGGCTCTGAAACGGAAGCTTGTGTGAGACATGGCGTATGGAATGAGGAACGGGTGGTTGTTTTGCAGATAGCTCCTCGAAAGAATTCCTAAGGACTTGGAGAGTGTTTTACTCTTGATACCTGAGCGCACCGTCTTCCGTTAGAATGGCCGGGCTTGGCTTCTATATATGGGCCGAATAAAGGAATTCTGGCGGGACCGGCCGGCCGACCGCGAAAGATGGTGCGCATAATAATATTACGCGCACCATCTGGAGCTGAGTAGGCGCCGATAGGGAGAGCCCGGGGCCGAGCGTAGCGAGTCCCTCGACGACAGCCTACGAAGCGACCGCTAGCCGTGTCGGCGGTGGTTCATGGGTTGCTGTA
Gene Information
|
NCBI Accession
|
YP_009551895.1
|
|
Location
|
1-363 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGATTTTCTTTTGCAATTATTGCCGTTCTATCGCTATAAATCTTTACTCAGTGCTGTTGCCTTTGAGATGGAGAAGGGACCTGGTCCAGAGGTGTTTTCGCCCCCAGTGGTTGAGGTGCCTTTCTCCGAAACTCCCAGTGCTGGCTCGGACCAGACCTGGCGAACCTTGGTTCTTGTCTTCCTGTTCGTGGCTCTTAGTATCGGTATTGTTGCAGCTCTCTACTGGGTCTGTGTGCGTGACTGTGTGTTATCGGCTCGTGCGAAACGGGCCAGGACAATAACCGAGTTCGGTTTCGGCAACACTCCGGGTGATCGGAGGGCTCCTCCTCCGCAGGCCCTTGCAGCTGGTGGCCCTGTCTGA |
|
Protein Sequence
|
MDFLLQLLPFYRYKSLLSAVAFEMEKGPGPEVFSPPVVEVPFSETPSAGSDQTWRTLVLVFLFVALSIGIVAALYWVCVRDCVLSARAKRARTITEFGFGNTPGDRRAPPPQALAAGGPV |
|
NCBI Accession
|
YP_009551896.1
|
|
Location
|
363-1106 |
|
Protein Name
|
capsid protein |
|
Coding Region
|
ATGCGTCCAATGACGGGAAAGAGGAAGAGGACCGCTGGTAGTTCTTCGGTAAATCGTCGGAAGTCCCGCCGTGTTTTACCTAGGACTGTGGCTCCGTATTCCCAGCTACCTTCCAGGCTTCCGAGCCTCCAGGTGCAAACATTTGCTTCGCAGGGTTCTGCCGTGGTGGAAGTTAAGAAGGGTGGTAATTGTCTGATGGTTACCTCCTACAGCCGTGGCTCTGACGAGAGTCAGAGACACACCAATGAGACCATGACCTACAAGATGTCGTTGGACCACGTCATGGTGTTACGTGCGGAGCTCTGTAAGTATAGCTTCAAGGCTACCCACTGTGGTTGGGTTGTGTATGACGCTAAACCCACGGGCAACCAGGTTACGTGCAAGACTATATTCGGCTACCCGGACGGGCTTGTGGATTACCCCACGACCTGGAAGGTTGCACGTGACGTGGCTCATCGCTTCGTGGTGAAGAAACGTTGGACCTACCGGATGGAATCCAATGGGTCTAACTCGTCTAAGGATTGGAGTAATGGGACTGGTATACCTCCTTGCAACCGGTCGGTGTACGTCAAGCAGTTCGTGAGCAAGCTCAACTGCCGAACGGAGTGGAAGAACACCACCGGGGGTGACTATGGCGATATCAAAGGCGGAGCCCTCTATGTTGTGCTCGCTGCCGGCCAAGGCATGGAGCACATGGCCTATGGTACCACGAGGATGTATTTCAAGAGCATCGGGAACCAGTGA |
|
Protein Sequence
|
MRPMTGKRKRTAGSSSVNRRKSRRVLPRTVAPYSQLPSRLPSLQVQTFASQGSAVVEVKKGGNCLMVTSYSRGSDESQRHTNETMTYKMSLDHVMVLRAELCKYSFKATHCGWVVYDAKPTGNQVTCKTIFGYPDGLVDYPTTWKVARDVAHRFVVKKRWTYRMESNGSNSSKDWSNGTGIPPCNRSVYVKQFVSKLNCRTEWKNTTGGDYGDIKGGALYVVLAAGQGMEHMAYGTTRMYFKSIGNQ |
|
NCBI Accession
|
YP_009551897.1
|
|
Location
|
1303-1704,1785-2414 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGTCTCACACAAGCTTCCGTTTCAGAGCCAAGAATGTCTTCCTCACGTACCCACGCTGTCCTATTGGCCCTGAGTTTCTTTGTGATCATCTCTGGAACCTCGTTACCCCTTATGATCCACTCTACGTACACGTTGCTCAAGAAAATCACAAGGACGGTGGGCTACACAGCCACGTCCTCATTCAAACCAGGATCGAAATCAGCACTTTCGATCCTACGTATTTTGACTACACTGGGACTAGTATTCCTGGTGCAGTTGTCTTTCACCCTAACATACAGGCATGCAGAAACGTCCGTGACTGTTTGGCGTACATACGGAAGAACACCATTAACGAAGTATCCAAGGGAGCATTCAAGTGCAGTGGAGCTGGAAGGCCGAAGAAACAAGACTCGGCACCAAGCCGGGACGCCAAGATGTGTCAGATCATGTCTTCTGCCACCTCTAGGAGCGATTACCTCTCAATGGTCAGAGGTGCCTTCCCGTTTGAATGGGCTACTAAACTGGCCCAATTTGAATACAGTGCATCCAAGCTATTTCCAGATGCTCCCACGACGAATGCCATCCCGTCAAACATTGATCTCACCTGCCATGAGAACATCATGCCCTGGCTGCGGGACGACCTGTACACTGAACGAGGGCAAGGAAGACGTCCCCGAAGCCTCTACATATGCGGAAGAACGAGGACGGGCAAGACAACATGGGCAAGAAGCCTCGGGCCACACAACTACTTCCAACACCAGGTGGACTACTTCGCCTGGAGCGAAGAGGCCACGTATGTCGTCATAGACGACATACCTTTCAAGTTCTGCCCGAACTGGAAGGCGATCGTGGGGAGCCAGCATGATTACACCGTCAACCCTAAATACGGTAAAAAAAGAAAAATAAAAGGAGGAATACCGGCCATTATATTGGTGAACGAGGACGAGGACTGGCTCATGAGCATGACAACCAGTCAGATAGACTGGTTTCTGGAGAATTGTGTAGTGTACCACATGACTCCAGGCGAATCATTCTTCAACTATGCCGAATAG |
|
Protein Sequence
|
MSHTSFRFRAKNVFLTYPRCPIGPEFLCDHLWNLVTPYDPLYVHVAQENHKDGGLHSHVLIQTRIEISTFDPTYFDYTGTSIPGAVVFHPNIQACRNVRDCLAYIRKNTINEVSKGAFKCSGAGRPKKQDSAPSRDAKMCQIMSSATSRSDYLSMVRGAFPFEWATKLAQFEYSASKLFPDAPTTNAIPSNIDLTCHENIMPWLRDDLYTERGQGRRPRSLYICGRTRTGKTTWARSLGPHNYFQHQVDYFAWSEEATYVVIDDIPFKFCPNWKAIVGSQHDYTVNPKYGKKRKIKGGIPAIILVNEDEDWLMSMTTSQIDWFLENCVVYHMTPGESFFNYAE |
|
NCBI Accession
|
YP_009551898.1
|
|
Location
|
1548-2414 |
|
Protein Name
|
RepA |
|
Coding Region
|
ATGTCTCACACAAGCTTCCGTTTCAGAGCCAAGAATGTCTTCCTCACGTACCCACGCTGTCCTATTGGCCCTGAGTTTCTTTGTGATCATCTCTGGAACCTCGTTACCCCTTATGATCCACTCTACGTACACGTTGCTCAAGAAAATCACAAGGACGGTGGGCTACACAGCCACGTCCTCATTCAAACCAGGATCGAAATCAGCACTTTCGATCCTACGTATTTTGACTACACTGGGACTAGTATTCCTGGTGCAGTTGTCTTTCACCCTAACATACAGGCATGCAGAAACGTCCGTGACTGTTTGGCGTACATACGGAAGAACACCATTAACGAAGTATCCAAGGGAGCATTCAAGTGCAGTGGAGCTGGAAGGCCGAAGAAACAAGACTCGGCACCAAGCCGGGACGCCAAGATGTGTCAGATCATGTCTTCTGCCACCTCTAGGAGCGATTACCTCTCAATGGTCAGAGGTGCCTTCCCGTTTGAATGGGCTACTAAACTGGCCCAATTTGAATACAGTGCATCCAAGCTATTTCCAGATGCTCCCACGACGAATGCCATCCCGTCAAACATTGATCTCACCTGCCATGAGAACATCATGCCCTGGCTGCGGGACGACCTGTACACTGTAAGCGAATTCTCTTACTTCCTATGTACAGGATCACTCGATCCGAAGGGAGATCTGACGTGGATGGCGGACCATACAAGGAACGAGGGCAAGGAAGACGTCCCCGAAGCCTCTACATATGCGGAAGAACGAGGACGGGCAAGACAACATGGGCAAGAAGCCTCGGGCCACACAACTACTTCCAACACCAGGTGGACTACTTCGCCTGGAGCGAAGAGGCCACGTATGTCGTCATAG |
|
Protein Sequence
|
MSHTSFRFRAKNVFLTYPRCPIGPEFLCDHLWNLVTPYDPLYVHVAQENHKDGGLHSHVLIQTRIEISTFDPTYFDYTGTSIPGAVVFHPNIQACRNVRDCLAYIRKNTINEVSKGAFKCSGAGRPKKQDSAPSRDAKMCQIMSSATSRSDYLSMVRGAFPFEWATKLAQFEYSASKLFPDAPTTNAIPSNIDLTCHENIMPWLRDDLYTVSEFSYFLCTGSLDPKGDLTWMADHTRNEGKEDVPEASTYAEERGRARQHGQEASGHTTTSNTRWTTSPGAKRPRMSS |