Chloris striate mosaic virus
Basic Information
| Genus |
Mastrevirus
|
| NCBI Assembly |
GCF_000839545.1 |
| Release date |
2015/2/12 |
| Submitter |
Andersen,M.T., Richardson,K.A., Harbison,S.A., Morris,B.A. |
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
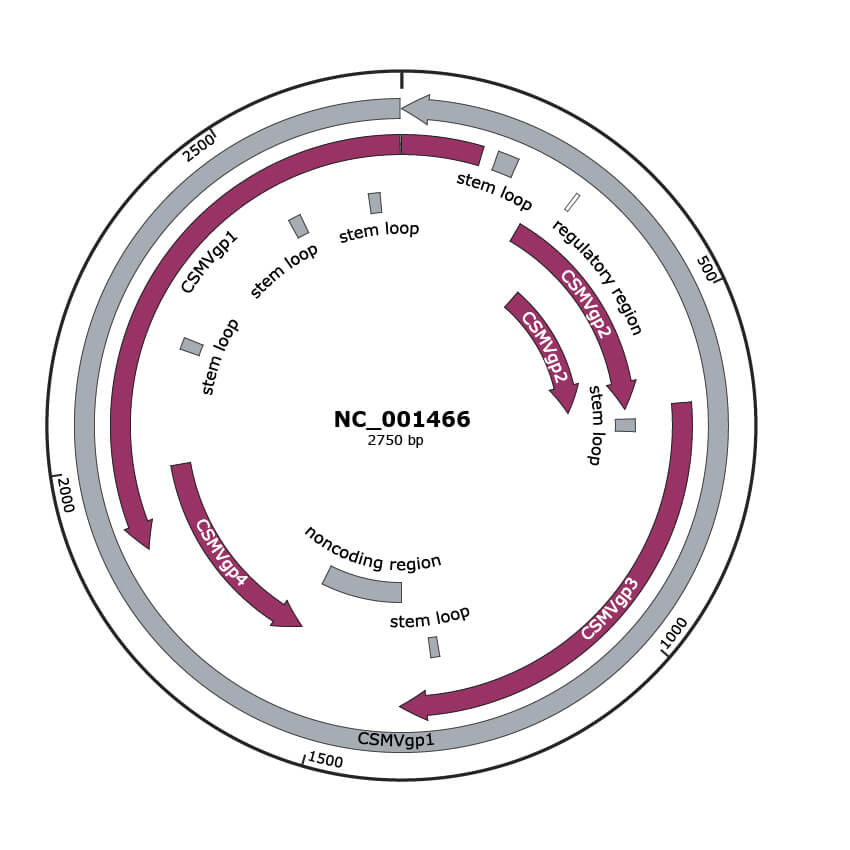
JBrowse
Genome
TAATAAAAGACGACGTGGCTTGATGGACAGCCGTAGGATGTGTTCTGAGATGTGGACTCCGAGCAAAACTATCTCTAATACCAGTTGCCCACCTGCCGAGTGCCCTCTTCGGCTTTTATGGGCCATAACAGGCCGGCTCTTTGCATGGGCGGGGGGGCAACCATAATATTACCGCCCCCCCGGCCCATGCGAGGGCCCATGCTCAACGGGTCCCGAGCGGCTTTGGCTTTCACATGGGCTTGTCCCCCGCGATGCGATCTGCTCTGCCATGCTTTGGCGGCTTTATAAAGCCGTTCTCAGACCTTTGTTTTCCAATGCAGTACCAGGGGTACGAGCAGCTCAGTAGATCTGGATCCGTGGAGCAACCCAGCCCCGGTGCTAGCTTTGCTTTCCCGGTGAAGGTGACAGCCCTCGTCTGTTTCGCAGCGATTGTTGGAGCCTGTATTCTTGTATTCTTGTACAAGACGTGCATTGCGGACTGCATAACGCAGTACCGGCTTACGGACTACGGCTGTCACACTTCGGCTGGGTTCGGAGGTGCGTTACCCGTGACCTCTGCGCAAGCTAGTGCTGGTACCAGCACCCCTGTGTGTGTTCCCTGTGCTCCTCAGGTACAGGCGTCCGTGGATCTACCCTCCGTAAGTAGGGTGTCATGAGTCCTGCCAGCTCATGGAAGAGGAAGAGGCCCTCTTCTTCCTCCGCTCAGGCGTCTAAGAAGCGCCGCGTGTACAGGCCTGCTGTTTCACGTTCTCTCGCTCGGCGAGAACCTCTGCAGGTGCAAGACTTTGTCTGGGATACAGATGTGGCTTTCAATAGGGGAGGAGGATGCTACCTCCTCACTAGCTATGCTCGAGGCTCTGCCGAGAATCAGCGGAAGACCGCTGAGACCATCACGTACAAGGTGGCAGTTAACCTGGGGTGTGCTATCTCCGGGACGATGCAGCAATATTGCATCAGCTCCCGACCGGTCTGCTGGATTGTATACGACGCGGCCCCCACTGGCTCTGCTGTTACCCCGAAGGACATCTTCGGGTACCCGGAAGGATTAGTTAACTGGCCTACTACTTGGAAGGTGGCCAGAGCGGTGTCCCACCGCTTCATAGTGAAGCGCCGATGGGTCTTCACCATGGAGTCCAACGGCTCGCGCTTCGACCGTGACTACACCAACCTCCCGGCTGCTATACCGCAGTCCCTTCCCGTTCTGAACAAGTTCGCGAAGCAGTTGGGCGTGCGGACCGAGTGGAAGAACGCTGAAGGCGGAGACTTCGGCGACATAAAGAGCGGAGCTCTTTACCTAGTCATGGCTCCGGCTAACGGAGCTGTCTTTGTAGCCCGCGGCAATGTCCGCGTGTATTTTAAGTCTGTTGGGAATCAGTGATTCCCCAGACTTCATTTTCAATAAACTGTGAGAGTTTGCTTGCCAAACAACATAATTTCATTCATAACGATGGCGCAGTATGCGCAATACATTTAAAAGAAGGGCGGACAGGACAAAGGCGGGCGGCTAAGGGAAGCCGCAAGGGGCAACACCACATCCCAAGAATGAGTTTTGGAATATGCAGCCGCTGGCTTCACGCTATTCCGAAGGAATGAAGGTTTCCCCTGGGAGAAGGTGATACACCACGGCGTTGCCGTGAAACCAGTCGACCTGTTGGGTCGACATCGACTGCAGCCAGTCTTCATCCTCGTTTACGAGGATAATACATGGAATCCCGTTGGGGATTCTTTTCTTCTTCCCGTACTTGGGGTTTACCGTCAGGTCATACTGGCTGCCGACGAGTCCCTTCCAACAAGGGACGAACTTGAACGGGATGTCATCAATGATGTTGAACTGGGCCTGGCAGTTCCATTCCTCTAGGAAGTTCACTGAGTGCTGCCAGTAGTGATGAGTTCCAAGACTTCTGGCCCAAGAAGTCTTTCCAGTTCTTGTTGGCCCACAGATGTACAGGCTTCGTCTCCGGACTCCAGGGCTCCAGACCTGGTTAGGTCAGACATCCATTGGAGGTCAATACGTGCTTGTTCCTCCGAAATACCTGCATGCAGACTGAGGGCTTGAGGACTTACAGTATACAGCTCCTGCTGGAGCCATTCTCCTATGACCGGATGGTCGGACATGTCCCTTGACGCGTATGGCGCGGAGTAGGTTTGAGGAGGGTCAGGGAACAGGGCATTTGCACTGTATTGGAATTGCTGTAGGCGTACCGCCCATTCGAAAGGGAAACTCTTTCGAACCATGCTCAGATATTCGTCCCTGGACGTGGCGTTTGCCATGATTTGTTTCATGGTCTTGTCCCTAGAGGCCGACTGGGTCGGACTCCTGTTGACCTTGGGTTTCAGGAATTTTCCAAATTCCCAGCTACTCTCAGGATGTTTCATACAGTATTTCAGAGTACTGGCTGGCTGCCTTGCAGCTTGGATATTTGGATGAAATTCATCCAGGTCAAAGTATTTTGGAGAGGTGGTTCTGAAATTTGCTTCGAGTTGGACGAAGGCATGTAAGTGGGGCTCACCGTCAGCATGGAATTCCCTGGAAATGTAAATATAATTACATTTCTTATTTTTTAGACGGTCAGCAATTTTCTGACCAGCCTCTTCGGGACTGATAGGACACCTGGGATAGGTGAGGAAGACATGTTTAGTCCTCAGGGAGAAGGCCTTCTCCCCAGGCGTCACTTGCCCTCCGCGAGATGGCACTTGTACGGAAGTGCCACTTCCCTCCCCCTCGCTCTCACTGACAGGCAGGGACGACA
Gene Information
|
NCBI Accession
|
NP_597785.2
|
|
Location
|
1864-2748,1->126 |
|
Protein Name
|
putative Rep A |
|
Coding Region
|
ATGGCCCATAAAAGCCGAAGAGGGCACTCGGCAGGTGGGCAACTGGTATTAGAGATAGTTTTGCTCGGAGTCCACATCTCAGAACACATCCTACGGCTGTCCATCAAGCCACGTCGTCTTTTATTATCGTCCCTGCCTGTCAGTGAGAGCGAGGGGGAGGGAAGTGGCACTTCCGTACAAGTGCCATCTCGCGGAGGGCAAGTGACGCCTGGGGAGAAGGCCTTCTCCCTGAGGACTAAACATGTCTTCCTCACCTATCCCAGGTGTCCTATCAGTCCCGAAGAGGCTGGTCAGAAAATTGCTGACCGTCTAAAAAATAAGAAATGTAATTATATTTACATTTCCAGGGAATTCCATGCTGACGGTGAGCCCCACTTACATGCCTTCGTCCAACTCGAAGCAAATTTCAGAACCACCTCTCCAAAATACTTTGACCTGGATGAATTTCATCCAAATATCCAAGCTGCAAGGCAGCCAGCCAGTACTCTGAAATACTGTATGAAACATCCTGAGAGTAGCTGGGAATTTGGAAAATTCCTGAAACCCAAGGTCAACAGGAGTCCGACCCAGTCGGCCTCTAGGGACAAGACCATGAAACAAATCATGGCAAACGCCACGTCCAGGGACGAATATCTGAGCATGGTTCGAAAGAGTTTCCCTTTCGAATGGGCGGTACGCCTACAGCAATTCCAATACAGTGCAAATGCCCTGTTCCCTGACCCTCCTCAAACCTACTCCGCGCCATACGCGTCAAGGGACATGTCCGACCATCCGGTCATAGGAGAATGGCTCCAGCAGGAGCTGTATACTGTAAGTCCTCAAGCCCTCAGTCTGCATGCAGGTATTTCGGAGGAACAAGCACGTATTGACCTCCAATGGATGTCTGACCTAACCAGGTCTGGAGCCCTGGAGTCCGGAGACGAAGCCTGTACATCTGTGGGCCAACAAGAACTGGAAAGACTTCTTGGGCCAGAAGTCTTGGAACTCATCACTACTGGCAGCACTCAGTGA |
|
Protein Sequence
|
MAHKSRRGHSAGGQLVLEIVLLGVHISEHILRLSIKPRRLLLSSLPVSESEGEGSGTSVQVPSRGGQVTPGEKAFSLRTKHVFLTYPRCPISPEEAGQKIADRLKNKKCNYIYISREFHADGEPHLHAFVQLEANFRTTSPKYFDLDEFHPNIQAARQPASTLKYCMKHPESSWEFGKFLKPKVNRSPTQSASRDKTMKQIMANATSRDEYLSMVRKSFPFEWAVRLQQFQYSANALFPDPPQTYSAPYASRDMSDHPVIGEWLQQELYTVSPQALSLHAGISEEQARIDLQWMSDLTRSGALESGDEACTSVGQQELERLLGPEVLELITTGSTQ |
|
NCBI Accession
|
NP_040950.1
|
|
Location
|
234-656 |
|
Protein Name
|
Hypothetical 14.5 KDa protein |
|
Coding Region
|
ATGGGCTTGTCCCCCGCGATGCGATCTGCTCTGCCATGCTTTGGCGGCTTTATAAAGCCGTTCTCAGACCTTTGTTTTCCAATGCAGTACCAGGGGTACGAGCAGCTCAGTAGATCTGGATCCGTGGAGCAACCCAGCCCCGGTGCTAGCTTTGCTTTCCCGGTGAAGGTGACAGCCCTCGTCTGTTTCGCAGCGATTGTTGGAGCCTGTATTCTTGTATTCTTGTACAAGACGTGCATTGCGGACTGCATAACGCAGTACCGGCTTACGGACTACGGCTGTCACACTTCGGCTGGGTTCGGAGGTGCGTTACCCGTGACCTCTGCGCAAGCTAGTGCTGGTACCAGCACCCCTGTGTGTGTTCCCTGTGCTCCTCAGGTACAGGCGTCCGTGGATCTACCCTCCGTAAGTAGGGTGTCATGA |
|
Protein Sequence
|
MGLSPAMRSALPCFGGFIKPFSDLCFPMQYQGYEQLSRSGSVEQPSPGASFAFPVKVTALVCFAAIVGACILVFLYKTCIADCITQYRLTDYGCHTSAGFGGALPVTSAQASAGTSTPVCVPCAPQVQASVDLPSVSRVS |
|
NCBI Accession
|
NP_040951.1
|
|
Location
|
315-656 |
|
Protein Name
|
Hypothetical 11.7 KDa protein |
|
Coding Region
|
ATGCAGTACCAGGGGTACGAGCAGCTCAGTAGATCTGGATCCGTGGAGCAACCCAGCCCCGGTGCTAGCTTTGCTTTCCCGGTGAAGGTGACAGCCCTCGTCTGTTTCGCAGCGATTGTTGGAGCCTGTATTCTTGTATTCTTGTACAAGACGTGCATTGCGGACTGCATAACGCAGTACCGGCTTACGGACTACGGCTGTCACACTTCGGCTGGGTTCGGAGGTGCGTTACCCGTGACCTCTGCGCAAGCTAGTGCTGGTACCAGCACCCCTGTGTGTGTTCCCTGTGCTCCTCAGGTACAGGCGTCCGTGGATCTACCCTCCGTAAGTAGGGTGTCATGA |
|
Protein Sequence
|
MQYQGYEQLSRSGSVEQPSPGASFAFPVKVTALVCFAAIVGACILVFLYKTCIADCITQYRLTDYGCHTSAGFGGALPVTSAQASAGTSTPVCVPCAPQVQASVDLPSVSRVS |
|
NCBI Accession
|
NP_040952.1
|
|
Location
|
653-1378 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGAGTCCTGCCAGCTCATGGAAGAGGAAGAGGCCCTCTTCTTCCTCCGCTCAGGCGTCTAAGAAGCGCCGCGTGTACAGGCCTGCTGTTTCACGTTCTCTCGCTCGGCGAGAACCTCTGCAGGTGCAAGACTTTGTCTGGGATACAGATGTGGCTTTCAATAGGGGAGGAGGATGCTACCTCCTCACTAGCTATGCTCGAGGCTCTGCCGAGAATCAGCGGAAGACCGCTGAGACCATCACGTACAAGGTGGCAGTTAACCTGGGGTGTGCTATCTCCGGGACGATGCAGCAATATTGCATCAGCTCCCGACCGGTCTGCTGGATTGTATACGACGCGGCCCCCACTGGCTCTGCTGTTACCCCGAAGGACATCTTCGGGTACCCGGAAGGATTAGTTAACTGGCCTACTACTTGGAAGGTGGCCAGAGCGGTGTCCCACCGCTTCATAGTGAAGCGCCGATGGGTCTTCACCATGGAGTCCAACGGCTCGCGCTTCGACCGTGACTACACCAACCTCCCGGCTGCTATACCGCAGTCCCTTCCCGTTCTGAACAAGTTCGCGAAGCAGTTGGGCGTGCGGACCGAGTGGAAGAACGCTGAAGGCGGAGACTTCGGCGACATAAAGAGCGGAGCTCTTTACCTAGTCATGGCTCCGGCTAACGGAGCTGTCTTTGTAGCCCGCGGCAATGTCCGCGTGTATTTTAAGTCTGTTGGGAATCAGTGA |
|
Protein Sequence
|
MSPASSWKRKRPSSSSAQASKKRRVYRPAVSRSLARREPLQVQDFVWDTDVAFNRGGGCYLLTSYARGSAENQRKTAETITYKVAVNLGCAISGTMQQYCISSRPVCWIVYDAAPTGSAVTPKDIFGYPEGLVNWPTTWKVARAVSHRFIVKRRWVFTMESNGSRFDRDYTNLPAAIPQSLPVLNKFAKQLGVRTEWKNAEGGDFGDIKSGALYLVMAPANGAVFVARGNVRVYFKSVGNQ |
|
NCBI Accession
|
NP_899201.1
|
|
Location
|
1577->1987 |
|
Protein Name
|
putative Rep B |
|
Coding Region
|
CCTAACCAGGTCTGGAGCCCTGGAGTCCGGAGACGAAGCCTGTACATCTGTGGGCCAACAAGAACTGGAAAGACTTCTTGGGCCAGAAGTCTTGGAACTCATCACTACTGGCAGCACTCAGTGAACTTCCTAGAGGAATGGAACTGCCAGGCCCAGTTCAACATCATTGATGACATCCCGTTCAAGTTCGTCCCTTGTTGGAAGGGACTCGTCGGCAGCCAGTATGACCTGACGGTAAACCCCAAGTACGGGAAGAAGAAAAGAATCCCCAACGGGATTCCATGTATTATCCTCGTAAACGAGGATGAAGACTGGCTGCAGTCGATGTCGACCCAACAGGTCGACTGGTTTCACGGCAACGCCGTGGTGTATCACCTTCTCCCAGGGGAAACCTTCATTCCTTCGGAATAG |
|
Protein Sequence
|
PNQVWSPGVRRRSLYICGPTRTGKTSWARSLGTHHYWQHSVNFLEEWNCQAQFNIIDDIPFKFVPCWKGLVGSQYDLTVNPKYGKKKRIPNGIPCIILVNEDEDWLQSMSTQQVDWFHGNAVVYHLLPGETFIPSE |