Chenopodium leaf curl virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002821805.1 |
| Isolate |
USA: Florida, Citra |
| Release date |
2018/8/25 |
| Submitter |
Ng,T.F., Duffy,S., Polston,J.E., Bixby,E., Vallad,G.E., Breitbart,M., Ng,T.F.F., Vallad,G. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
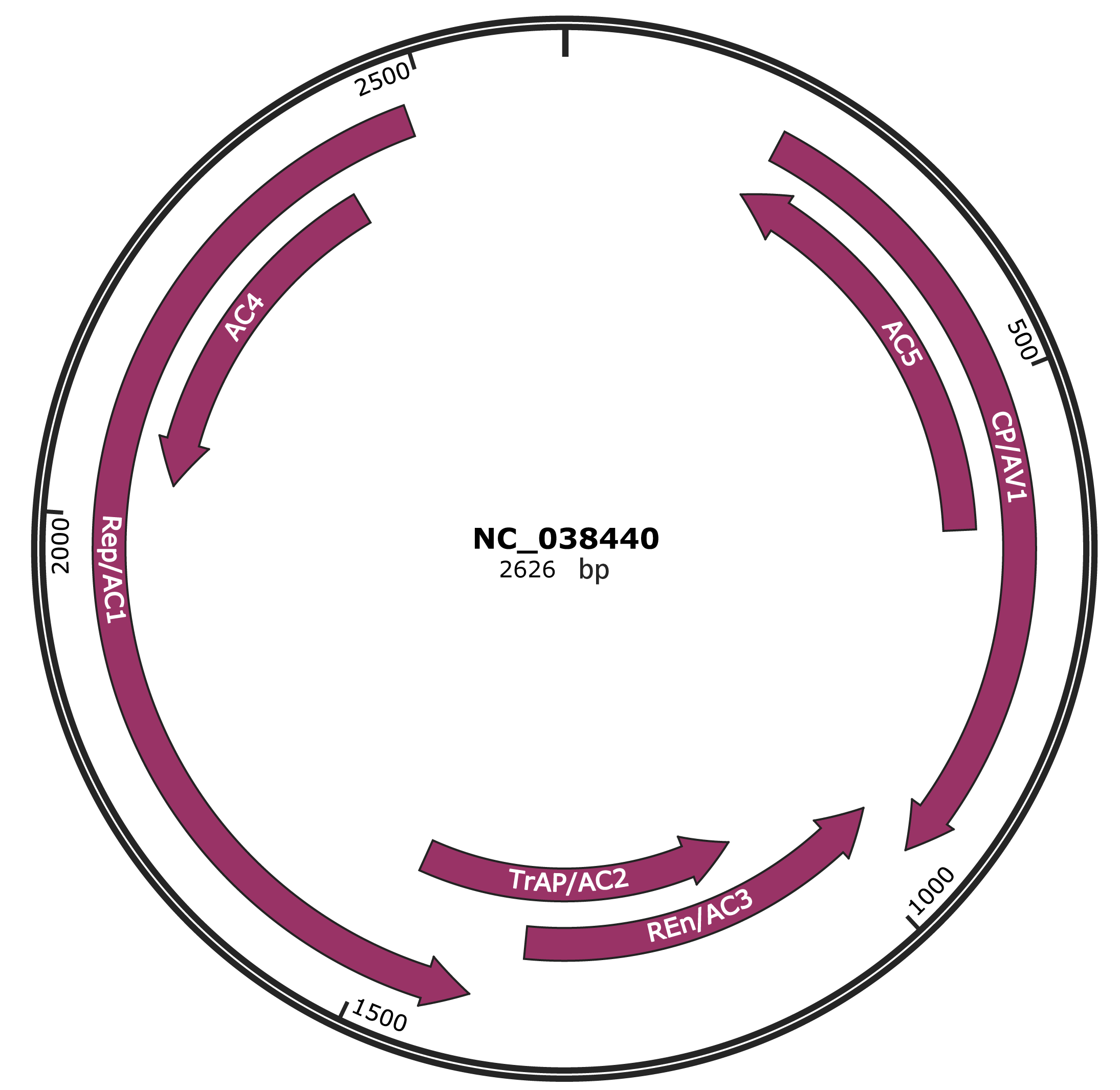
JBrowse
Genome
ACTGGATGGCCGCGCGATTTTTGGAGTCCTTTACTCTGGAGAGGCCCATTTCGCTACCGGCCCACACTTTAATTTAAAGTAAAGTCTATTTCGTCCATTCATAGTGAGTCTGACGAGCGTAGATATCCGGACCTACTTGGTCGCTAAGTTAGTGGGTGCAGTTATAAATTAAAGTGTCATTGGCCCACGCTCTTTAACTCAAAATGCCTAAGAGGGAAGCCCCATGGCGATTACTGGCGGGAACCTCGAAGGTTAGCCGAAATGCGAAATATTCTACCCGTCTAGGAAGTGGGCCAACATTTAACAAGGCCACTGAATGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATATACCGGATGATCCGTACTCCAGATGTGCCCAGAGGGTGTGAAGGGCCTTGTAAAGTCCAGTCATTCGAACAGCGACATGATGTGTCACATACTGGGAAAGTGATATGCATATCCGACGTGACACGGGGTAATGGTATAACCCACCGTGTTGGTAAGCGATTCTGTGTTAAGTCCGTGTACATTCTGGGCAAGATATGGATGGATGAGAACATCAAGTTGAAGAACCACACGAACAGTGTTATGTTCTGGTTGGTTAGGGATCGAAGACCGTATGGTACTCCCATGGATTTCGGTCAGGTGTTCAACATGTTCGACAATGAGCCTAGCACTGCTACTGTGAAGAACGATCTACGTGATCGTTATCAGGTCATGCACCGGTTCTATGGCAAGGTTACGGGTGGACAGTATGCCAGCAACGAGCAGGCTATAGTCAAGCGCTTCTGGAAGGTCAACAATCATGTGGTGTACAATCACCAGGAAGCTGGGAAGTACGAGAACCACACGGAGAACGCGCTATTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTATATGCAACTTTGAAGATCCGAATCTATTTCTATGATTCGATTATGAATTAATAAATTTTGAATTTTATTGAATGTCTAAAGAGCACATTAGTTACATAAGACCGGTCTGTCGCAAAACTAGCAGCCCTAATTACATTGTTTATGGAAATAACGCCTAACTGATCTAAATACATATTAACTAATTGCCTAAATCTATTTAAGTACGTCGTCCCAGAAGCTGTCAGAGAAGTCGTCCAGACTTGGAAGGTTAAGAAGGCCTTGTGGAGATCCAACACTCTCCGCAGGTTGTGGTTTGCCCTGATCTGGATGTGGTACACTCTGCTGGACGTGTACGCCGGTTCCTCCACCCTGTCTATCCTGAAATAGAGGGGATTTTCGATCTCCCATATAAAAACGCCATTCTCCGCTTGAGCTGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGCCCGGAACAGCCAATATGCACGTATATGGAGCACCCGCAATCTAAATCAATCCTGCGCCTCCTGATCCCCCTCTTCTTGGCTATCTTGTGCGCTATCTTGATAGAGGGGGGATGTGAGGGTGATGAAGACCGCATTTTTTATTGTCCAGTTCTTTAGTGATGTGTTTTCAATTTTGTCCAAGAACTCCTTATAACTGGCACCCTCACCAGGATTGCAAAGCACGATAGACGGTATCCCGCCTTTAATTTGAACTGGCCTGCCGTACTTGCAGTTTGATTGCCAGTCCTTCTGGGCCCCCAGAAGTTCTTTCCAGTGCTTTAATTTTAGATATTGCGGTGCGACGTCATCGATGACGTTATACTCCACTTCGTTAGAATAAACCCGGGCATTGAAATCAAGGTGACCACTGAGATAATTATGTGGACCCAAGGCACGAGCCCACATCGTCTTTCCCGTCCTTGAGTCACCTTCGACGATTATACTTATCGGTCTTTCTGGCCGCGCAGCGACGCCGTTTCCGAAGTAATCATCCGCCCAAGCTTGCATATCTACTGGAACGTTAGTGAACGACGAGAGAGGAAACGGAGGAACCCATCGTTCAGGAGGTTTGTGAAATAGGCGCTCAATGTTAGCCTTGACGTTGTGATAGCTAACGATAAACGTCTTTGGGTCTCCCGCCTTTATAATGTCGAGAGCCTCTCTCGCAGTAGTTGCATTAACAGCGTTGTGATACACGTCGTCTTTATTCGCCTTTGAACCCCCAGACACTTTGTATTGTCCGGATTCACAATAATCACCTTCCTTGGTGATGTAATTCTTGACGGCGTTGGTGTCTTTAGCGCCTTGGACGTTCGGGTGAAATCCGGCAGACCTTCTGGGGTGAGTGAGGTCGAAAAATCTAGCATCCTTGATGTTGGACTTACCGGAGAGTTGGATGAGACAGTGTAAATGAGGGAACCCATCTGCGTGTTCCTCTCTTGCGACTCTGATGTATGTAGGTTTGACGACTGACCAAGGCAGGGATTGAAGCAAGAGAAGAGCTTCATCTTTGGGTATGTCGCACTGGGGATATGTTAAGAAAATATTTCTAGCTTGGATACGAAAGGAATTAGGGTTTCGTGGCATTTTTGTAATTTATGAAGAGGACTCCAGACCAGGACTCCGGGTTTCCTCTCCTCAAAAACTTAATATTCGTGGAGTCCTGGAGTCCCATTTATACTAAAACCCTCTGGGGGACTCCAGGGGCAAAAGCGGCCATCCATATAATATT
Gene Information
|
NCBI Accession
|
YP_009506378.1
|
|
Location
|
194-637 |
|
Gene Name
|
AC5 |
|
Protein Name
|
AC5 protein |
|
Coding Region
|
ATGGGAGTACCATACGGTCTTCGATCCCTAACCAACCAGAACATAACACTGTTCGTGTGGTTCTTCAACTTGATGTTCTCATCCATCCATATCTTGCCCAGAATGTACACGGACTTAACACAGAATCGCTTACCAACACGGTGGGTTATACCATTACCCCGTGTCACGTCGGATATGCATATCACTTTCCCAGTATGTGACACATCATGTCGCTGTTCGAATGACTGGACTTTACAAGGCCCTTCACACCCTCTGGGCACATCTGGAGTACGGATCATCCGGTATATCCTGGGCTTCCTGTACATGGGCCTGTTCACCCATTCAGTGGCCTTGTTAAATGTTGGCCCACTTCCTAGACGGGTAGAATATTTCGCATTTCGGCTAACCTTCGAGGTTCCCGCCAGTAATCGCCATGGGGCTTCCCTCTTAGGCATTTTGAGTTAA |
|
Protein Sequence
|
MGVPYGLRSLTNQNITLFVWFFNLMFSSIHILPRMYTDLTQNRLPTRWVIPLPRVTSDMHITFPVCDTSCRCSNDWTLQGPSHPLGTSGVRIIRYILGFLYMGLFTHSVALLNVGPLPRRVEYFAFRLTFEVPASNRHGASLLGILS |
|
NCBI Accession
|
YP_009506379.1
|
|
Location
|
204-959 |
|
Gene Name
|
CP/AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGAGGGAAGCCCCATGGCGATTACTGGCGGGAACCTCGAAGGTTAGCCGAAATGCGAAATATTCTACCCGTCTAGGAAGTGGGCCAACATTTAACAAGGCCACTGAATGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATATACCGGATGATCCGTACTCCAGATGTGCCCAGAGGGTGTGAAGGGCCTTGTAAAGTCCAGTCATTCGAACAGCGACATGATGTGTCACATACTGGGAAAGTGATATGCATATCCGACGTGACACGGGGTAATGGTATAACCCACCGTGTTGGTAAGCGATTCTGTGTTAAGTCCGTGTACATTCTGGGCAAGATATGGATGGATGAGAACATCAAGTTGAAGAACCACACGAACAGTGTTATGTTCTGGTTGGTTAGGGATCGAAGACCGTATGGTACTCCCATGGATTTCGGTCAGGTGTTCAACATGTTCGACAATGAGCCTAGCACTGCTACTGTGAAGAACGATCTACGTGATCGTTATCAGGTCATGCACCGGTTCTATGGCAAGGTTACGGGTGGACAGTATGCCAGCAACGAGCAGGCTATAGTCAAGCGCTTCTGGAAGGTCAACAATCATGTGGTGTACAATCACCAGGAAGCTGGGAAGTACGAGAACCACACGGAGAACGCGCTATTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTATATGCAACTTTGAAGATCCGAATCTATTTCTATGATTCGATTATGAATTAA |
|
Protein Sequence
|
MPKREAPWRLLAGTSKVSRNAKYSTRLGSGPTFNKATEWVNRPMYRKPRIYRMIRTPDVPRGCEGPCKVQSFEQRHDVSHTGKVICISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHRFYGKVTGGQYASNEQAIVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
|
NCBI Accession
|
YP_009506380.1
|
|
Location
|
956-1354 |
|
Gene Name
|
REn/AC3 |
|
Protein Name
|
replication enhancer |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCAGCTCAAGCGGAGAATGGCGTTTTTATATGGGAGATCGAAAATCCCCTCTATTTCAGGATAGACAGGGTGGAGGAACCGGCGTACACGTCCAGCAGAGTGTACCACATCCAGATCAGGGCAAACCACAACCTGCGGAGAGTGTTGGATCTCCACAAGGCCTTCTTAACCTTCCAAGTCTGGACGACTTCTCTGACAGCTTCTGGGACGACGTACTTAAATAGATTTAGGCAATTAGTTAATATGTATTTAGATCAGTTAGGCGTTATTTCCATAAACAATGTAATTAGGGCTGCTAGTTTTGCGACAGACCGGTCTTATGTAACTAATGTGCTCTTTAGACATTCAATAAAATTCAAAATTTATTAA |
|
Protein Sequence
|
MDSRTGELITAAQAENGVFIWEIENPLYFRIDRVEEPAYTSSRVYHIQIRANHNLRRVLDLHKAFLTFQVWTTSLTASGTTYLNRFRQLVNMYLDQLGVISINNVIRAASFATDRSYVTNVLFRHSIKFKIY |
|
NCBI Accession
|
YP_009506381.1
|
|
Location
|
1101-1490 |
|
Gene Name
|
TrAP/AC2 |
|
Protein Name
|
transcription activator |
|
Coding Region
|
ATGCGGTCTTCATCACCCTCACATCCCCCCTCTATCAAGATAGCGCACAAGATAGCCAAGAAGAGGGGGATCAGGAGGCGCAGGATTGATTTAGATTGCGGGTGCTCCATATACGTGCATATTGGCTGTTCCGGGCATGGATTCACGCACAGGGGAACTCATCACTGCAGCTCAAGCGGAGAATGGCGTTTTTATATGGGAGATCGAAAATCCCCTCTATTTCAGGATAGACAGGGTGGAGGAACCGGCGTACACGTCCAGCAGAGTGTACCACATCCAGATCAGGGCAAACCACAACCTGCGGAGAGTGTTGGATCTCCACAAGGCCTTCTTAACCTTCCAAGTCTGGACGACTTCTCTGACAGCTTCTGGGACGACGTACTTAAATAG |
|
Protein Sequence
|
MRSSSPSHPPSIKIAHKIAKKRGIRRRRIDLDCGCSIYVHIGCSGHGFTHRGTHHCSSSGEWRFYMGDRKSPLFQDRQGGGTGVHVQQSVPHPDQGKPQPAESVGSPQGLLNLPSLDDFSDSFWDDVLK |
|
NCBI Accession
|
YP_009506382.1
|
|
Location
|
1402-2481 |
|
Gene Name
|
Rep/AC1 |
|
Protein Name
|
replication initiator protein |
|
Coding Region
|
ATGCCACGAAACCCTAATTCCTTTCGTATCCAAGCTAGAAATATTTTCTTAACATATCCCCAGTGCGACATACCCAAAGATGAAGCTCTTCTCTTGCTTCAATCCCTGCCTTGGTCAGTCGTCAAACCTACATACATCAGAGTCGCAAGAGAGGAACACGCAGATGGGTTCCCTCATTTACACTGTCTCATCCAACTCTCCGGTAAGTCCAACATCAAGGATGCTAGATTTTTCGACCTCACTCACCCCAGAAGGTCTGCCGGATTTCACCCGAACGTCCAAGGCGCTAAAGACACCAACGCCGTCAAGAATTACATCACCAAGGAAGGTGATTATTGTGAATCCGGACAATACAAAGTGTCTGGGGGTTCAAAGGCGAATAAAGACGACGTGTATCACAACGCTGTTAATGCAACTACTGCGAGAGAGGCTCTCGACATTATAAAGGCGGGAGACCCAAAGACGTTTATCGTTAGCTATCACAACGTCAAGGCTAACATTGAGCGCCTATTTCACAAACCTCCTGAACGATGGGTTCCTCCGTTTCCTCTCTCGTCGTTCACTAACGTTCCAGTAGATATGCAAGCTTGGGCGGATGATTACTTCGGAAACGGCGTCGCTGCGCGGCCAGAAAGACCGATAAGTATAATCGTCGAAGGTGACTCAAGGACGGGAAAGACGATGTGGGCTCGTGCCTTGGGTCCACATAATTATCTCAGTGGTCACCTTGATTTCAATGCCCGGGTTTATTCTAACGAAGTGGAGTATAACGTCATCGATGACGTCGCACCGCAATATCTAAAATTAAAGCACTGGAAAGAACTTCTGGGGGCCCAGAAGGACTGGCAATCAAACTGCAAGTACGGCAGGCCAGTTCAAATTAAAGGCGGGATACCGTCTATCGTGCTTTGCAATCCTGGTGAGGGTGCCAGTTATAAGGAGTTCTTGGACAAAATTGAAAACACATCACTAAAGAACTGGACAATAAAAAATGCGGTCTTCATCACCCTCACATCCCCCCTCTATCAAGATAGCGCACAAGATAGCCAAGAAGAGGGGGATCAGGAGGCGCAGGATTGA |
|
Protein Sequence
|
MPRNPNSFRIQARNIFLTYPQCDIPKDEALLLLQSLPWSVVKPTYIRVAREEHADGFPHLHCLIQLSGKSNIKDARFFDLTHPRRSAGFHPNVQGAKDTNAVKNYITKEGDYCESGQYKVSGGSKANKDDVYHNAVNATTAREALDIIKAGDPKTFIVSYHNVKANIERLFHKPPERWVPPFPLSSFTNVPVDMQAWADDYFGNGVAARPERPISIIVEGDSRTGKTMWARALGPHNYLSGHLDFNARVYSNEVEYNVIDDVAPQYLKLKHWKELLGAQKDWQSNCKYGRPVQIKGGIPSIVLCNPGEGASYKEFLDKIENTSLKNWTIKNAVFITLTSPLYQDSAQDSQEEGDQEAQD |
|
NCBI Accession
|
YP_009506383.1
|
|
Location
|
2037-2402 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGAAGCTCTTCTCTTGCTTCAATCCCTGCCTTGGTCAGTCGTCAAACCTACATACATCAGAGTCGCAAGAGAGGAACACGCAGATGGGTTCCCTCATTTACACTGTCTCATCCAACTCTCCGGTAAGTCCAACATCAAGGATGCTAGATTTTTCGACCTCACTCACCCCAGAAGGTCTGCCGGATTTCACCCGAACGTCCAAGGCGCTAAAGACACCAACGCCGTCAAGAATTACATCACCAAGGAAGGTGATTATTGTGAATCCGGACAATACAAAGTGTCTGGGGGTTCAAAGGCGAATAAAGACGACGTGTATCACAACGCTGTTAATGCAACTACTGCGAGAGAGGCTCTCGACATTATAA |
|
Protein Sequence
|
MKLFSCFNPCLGQSSNLHTSESQERNTQMGSLIYTVSSNSPVSPTSRMLDFSTSLTPEGLPDFTRTSKALKTPTPSRITSPRKVIIVNPDNTKCLGVQRRIKTTCITTLLMQLLRERLSTL |