Bromus catharticus striate mosaic virus
Basic Information
| Genus |
Mastrevirus
|
| NCBI Assembly |
GCF_000890415.1 |
| Isolate |
Australia |
| Release date |
2015/2/22 |
| Submitter |
Hadfield,J., Martin,D.P., Stainton,D., Kraberger,S., Owor,B.E., Shepherd,D.N., Lakay,F., Markham,P.G., Greber,R.S., Briddon,R.W., Varsani,A., Hatfield,J. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
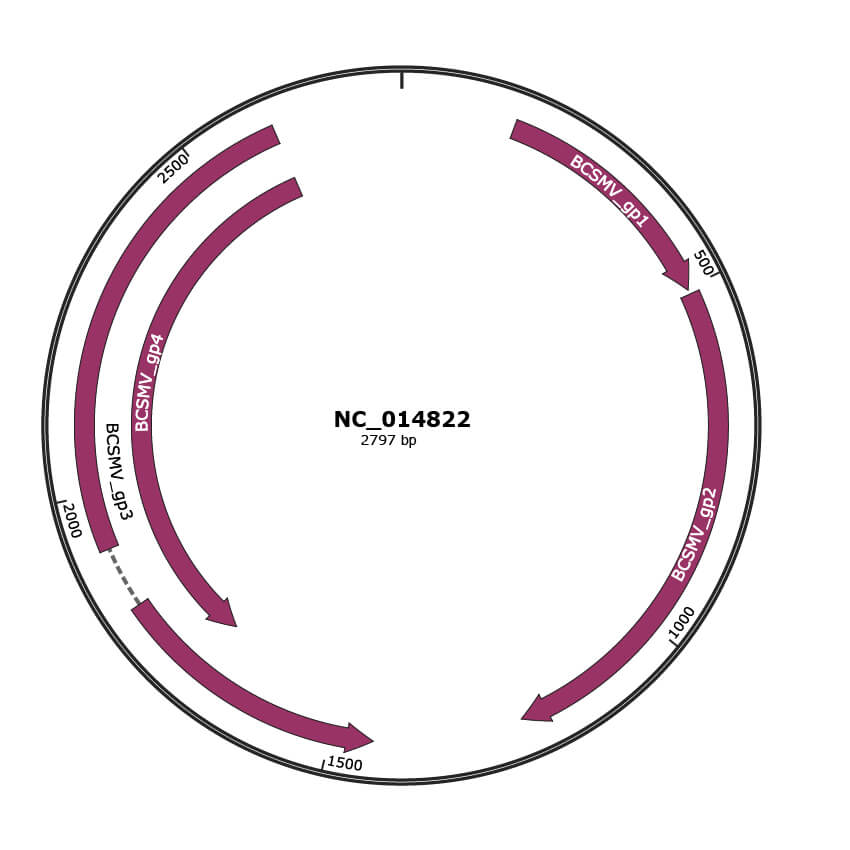
JBrowse
Genome
TAATATTACCGCCCATCTTTAGCCGAGGGACCATGCCCAACCGGTCCCGAGGCGCCCGGACCCCCCAAACACTAGGGGTTGCACCCCGCAATATGATTTTCGAATCTGACTGCCATCTTCCTTTGTTTTGTCTTTATAAGACTAGATCGCACTAGTACGCTATGGCGGAGTACCCTCAGTCTGCTTTCGTTTTATCTGGTGCGATTCCACATCAAAGCAAGGACGAAGGCTTTGCCTCGTCTTTGAAGGTTACTGCTCTATCTTTGTTCGCAGCATTCATTGCTGCTGCCATCTTGTGTTTCCTATACAAGACTTGTCTTGCAGATTGCTATACGCAATACCGGACTACCGGTCTGAGCAGTACATCTTCATCTGGCTTTGGTCGAACCTCTGAGGCTTCGACAGCTGTCCCGCGGACAGCGTCTGAGGTTTCTATTCCCTTAGGGGATAGATCTGCTACTCCATCTTCCTGTTTACCTACATCTGGTATTTCATCTATTTGATTTGTCATGACGTCTTCCTCGAAGAGGAAACGTGGATCTGGTAAGACGAAGACGCGCAAGAAGGCGCGTTACACGAAGTGGACATCATCGAGAACAACGTCAGCTGCAGACTCTCTGCAGGTACAGACGTTCCTGTGGGCTGAGGATCAGTCCTTCAATACTGGTGGAGGTTGCAGACTGCTAACCTCCTTCACGCGTGGTTCAGGAGAGAACCAACGCAAATCCCAGGAGACCATTACGTACAAGGTTGCCGTCAACCTTGGCATCTCCGCCTCCACTACCGTTCAGAAGTATTGCCTGACCAGCCATCCTATATGTTGGCTGGTCTACGATAAGACGCCTGGGATTGCTGACCTGACTCCAACTGACATCTTTGATGTCCCGACTGGGTTGAACAACTGGCCTTCAACCTGGAAGGTCAAGCGCGAAGCATCTCACCGCTTCGTGGTGAAACGGCGCTGGCCGTTTAGACTGTCCGTCAATGGCTCTACGTTCTCTGCAGATTATACGAAGCTGCCGGTGCCCAATACAGACAACCTGTGTACGATCAACAGGTTCGCCAAGGGACTTGGAGTGCGAACCGAATGGAAGGACACGGTTTCTGCTGACGCCTCCGACATCAAGGGCGGAGCCCTGTACATAGTATTAGCCCCGGCTAATGGGCTTGTATTCACAGCTAGAGGTGTCATTAAAGTGTACTTCAAGAGTGTGGGCAATCAGTAGCCCAATGTAATGAGCCCATAGGGCGATGAATAAAATGGCACATTTTATTATGTCATTATGACGAACGAGTACAACGAGAAAATTACATAATTGGTTTTTGTGGGTCGCGAGGGGGAACCCGGAGCACGCACCCAAAAACACTAAACACACAAACCCAGAATATCTATAGGATACATGGCCGGCGCGTGCCGATAGTCACGCTGTAGCTGGCCCTAAGCTTCGAAGAAGCTCTCCCCTGCATACATGTAATGTATGATACAGTTTGTCTCAAACCAGCCAACCTGACTAGGTTGCATTTGTTTGAGCCAGTCTTCGTCCTCGTTCACGAGGATTATTGATGGAACTCCATTCTTGAGCATACGTCGTTTACCATATTTTGGATTTACGGTAATGTCAAACTGGCATCCAACAAGCCCTTTCCAACAAGGAACGAACTTGAATGGTATGTCATCTATGACATTGTAAGTTGCGTTAGCAACTAAGTTGAGGAAGTCGACGCTGTGTTGCCAGTAGTTGTGAGCTCCCAGACTTCTAGCCCAAGAAGTCTTTCCAGTTCTTGTTGGTCCGCAAATGTAGAGTGATCTTCTTCGTTCATCAGGACGTCTGTCCTGCTAATATCAGACATCCATTGGAGGTCAAGCCTCGCTTGGTCCTCCGTTACGCCATTATGTATGGAATATGCATAAGGACTTACAGAAAATAATTCTGCTTGGAGCCATGCTCCAATCACCGGATGTTCATCCTGTGCTGGCATCCCGAAGGGATCCATATATGGCGTAGGAACCGAAGGGAATAAGCTCTCTGCGGAGTATTGGAATTGTTGCAACCTCGTTGCCCAATCGAATGGGAACGTATTCCTGACCATCGAGAGATAGTCCTCCTTGCAGGTACTGCTCTTGATTATCTCCGCCATTTTGGCGTCTTTAGTTGATGGAGCATCAACCTTCTTCTTCTTCTGCTTGGTGCTTGCTTGGAAAACCCCCGTTTCTACGAAACATAAGGGGTTTTTTTTGATGTATGCTAACACCTTGTGTGGCATTCTTGCATTCTGCACGTTAGGATGAAATTCTTCGACGTCGAAGAATTTAGCACTCTTGGTGCGAACATATTTCTTGCATTGTACCAGACAATGCAAATGGTAAGATCCATCTTGATGTTCTTCTCTTGCCACGTAGACATACGTGGGTTCGAACCTTCGAAGAAGGCTTGAGAGGTGTTCTTGCATGAACACCGGATCAAGGTGGCACTTGCTGTACGTTAAGAAAATGTTCCTTGATCTTACCTCGAAGCATGCTGCGACCGCCCCTGGGGCGCCAACCTCCCCGCTCGGTGAGCGGGGGGCGCCAGTTTGCCCCCTGGCGTCTGATGTCTCACTGACAAAGGAGGCCATCTCGTCAGAGGCTATCGTGGATAGACTCTCAGCCCTTGGATGATCTTTGAGATCCGAGGTTTTGAAAAACTCCCTTCCTAGACCCTTGCCCCTTGGCGCCCCCCCCCCCGCGCCCTATCTTATAGGGCCTCGGGTGGGTGGCTTTTTTCTGGGCCGGGCCGGCGTAAAGATGGGCAAGCAA
Gene Information
|
NCBI Accession
|
YP_004089625.1
|
|
Location
|
162-503 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGCGGAGTACCCTCAGTCTGCTTTCGTTTTATCTGGTGCGATTCCACATCAAAGCAAGGACGAAGGCTTTGCCTCGTCTTTGAAGGTTACTGCTCTATCTTTGTTCGCAGCATTCATTGCTGCTGCCATCTTGTGTTTCCTATACAAGACTTGTCTTGCAGATTGCTATACGCAATACCGGACTACCGGTCTGAGCAGTACATCTTCATCTGGCTTTGGTCGAACCTCTGAGGCTTCGACAGCTGTCCCGCGGACAGCGTCTGAGGTTTCTATTCCCTTAGGGGATAGATCTGCTACTCCATCTTCCTGTTTACCTACATCTGGTATTTCATCTATTTGA |
|
Protein Sequence
|
MAEYPQSAFVLSGAIPHQSKDEGFASSLKVTALSLFAAFIAAAILCFLYKTCLADCYTQYRTTGLSSTSSSGFGRTSEASTAVPRTASEVSIPLGDRSATPSSCLPTSGISSI |
|
NCBI Accession
|
YP_004089626.1
|
|
Location
|
510-1226 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGACGTCTTCCTCGAAGAGGAAACGTGGATCTGGTAAGACGAAGACGCGCAAGAAGGCGCGTTACACGAAGTGGACATCATCGAGAACAACGTCAGCTGCAGACTCTCTGCAGGTACAGACGTTCCTGTGGGCTGAGGATCAGTCCTTCAATACTGGTGGAGGTTGCAGACTGCTAACCTCCTTCACGCGTGGTTCAGGAGAGAACCAACGCAAATCCCAGGAGACCATTACGTACAAGGTTGCCGTCAACCTTGGCATCTCCGCCTCCACTACCGTTCAGAAGTATTGCCTGACCAGCCATCCTATATGTTGGCTGGTCTACGATAAGACGCCTGGGATTGCTGACCTGACTCCAACTGACATCTTTGATGTCCCGACTGGGTTGAACAACTGGCCTTCAACCTGGAAGGTCAAGCGCGAAGCATCTCACCGCTTCGTGGTGAAACGGCGCTGGCCGTTTAGACTGTCCGTCAATGGCTCTACGTTCTCTGCAGATTATACGAAGCTGCCGGTGCCCAATACAGACAACCTGTGTACGATCAACAGGTTCGCCAAGGGACTTGGAGTGCGAACCGAATGGAAGGACACGGTTTCTGCTGACGCCTCCGACATCAAGGGCGGAGCCCTGTACATAGTATTAGCCCCGGCTAATGGGCTTGTATTCACAGCTAGAGGTGTCATTAAAGTGTACTTCAAGAGTGTGGGCAATCAGTAG |
|
Protein Sequence
|
MTSSSKRKRGSGKTKTRKKARYTKWTSSRTTSAADSLQVQTFLWAEDQSFNTGGGCRLLTSFTRGSGENQRKSQETITYKVAVNLGISASTTVQKYCLTSHPICWLVYDKTPGIADLTPTDIFDVPTGLNNWPSTWKVKREASHRFVVKRRWPFRLSVNGSTFSADYTKLPVPNTDNLCTINRFAKGLGVRTEWKDTVSADASDIKGGALYIVLAPANGLVFTARGVIKVYFKSVGNQ |
|
NCBI Accession
|
YP_004089627.1
|
|
Location
|
1439-1831,1921-2616 |
|
Protein Name
|
Rep |
|
Coding Region
|
ATGGCCTCCTTTGTCAGTGAGACATCAGACGCCAGGGGGCAAACTGGCGCCCCCCGCTCACCGAGCGGGGAGGTTGGCGCCCCAGGGGCGGTCGCAGCATGCTTCGAGGTAAGATCAAGGAACATTTTCTTAACGTACAGCAAGTGCCACCTTGATCCGGTGTTCATGCAAGAACACCTCTCAAGCCTTCTTCGAAGGTTCGAACCCACGTATGTCTACGTGGCAAGAGAAGAACATCAAGATGGATCTTACCATTTGCATTGTCTGGTACAATGCAAGAAATATGTTCGCACCAAGAGTGCTAAATTCTTCGACGTCGAAGAATTTCATCCTAACGTGCAGAATGCAAGAATGCCACACAAGGTGTTAGCATACATCAAAAAAAACCCCTTATGTTTCGTAGAAACGGGGGTTTTCCAAGCAAGCACCAAGCAGAAGAAGAAGAAGGTTGATGCTCCATCAACTAAAGACGCCAAAATGGCGGAGATAATCAAGAGCAGTACCTGCAAGGAGGACTATCTCTCGATGGTCAGGAATACGTTCCCATTCGATTGGGCAACGAGGTTGCAACAATTCCAATACTCCGCAGAGAGCTTATTCCCTTCGGTTCCTACGCCATATATGGATCCCTTCGGGATGCCAGCACAGGATGAACATCCGGTGATTGGAGCATGGCTCCAAGCAGAATTATTTTCTAGACGTCCTGATGAACGAAGAAGATCACTCTACATTTGCGGACCAACAAGAACTGGAAAGACTTCTTGGGCTAGAAGTCTGGGAGCTCACAACTACTGGCAACACAGCGTCGACTTCCTCAACTTAGTTGCTAACGCAACTTACAATGTCATAGATGACATACCATTCAAGTTCGTTCCTTGTTGGAAAGGGCTTGTTGGATGCCAGTTTGACATTACCGTAAATCCAAAATATGGTAAACGACGTATGCTCAAGAATGGAGTTCCATCAATAATCCTCGTGAACGAGGACGAAGACTGGCTCAAACAAATGCAACCTAGTCAGGTTGGCTGGTTTGAGACAAACTGTATCATACATTACATGTATGCAGGGGAGAGCTTCTTCGAAGCTTAG |
|
Protein Sequence
|
MASFVSETSDARGQTGAPRSPSGEVGAPGAVAACFEVRSRNIFLTYSKCHLDPVFMQEHLSSLLRRFEPTYVYVAREEHQDGSYHLHCLVQCKKYVRTKSAKFFDVEEFHPNVQNARMPHKVLAYIKKNPLCFVETGVFQASTKQKKKKVDAPSTKDAKMAEIIKSSTCKEDYLSMVRNTFPFDWATRLQQFQYSAESLFPSVPTPYMDPFGMPAQDEHPVIGAWLQAELFSRRPDERRRSLYICGPTRTGKTSWARSLGAHNYWQHSVDFLNLVANATYNVIDDIPFKFVPCWKGLVGCQFDITVNPKYGKRRMLKNGVPSIILVNEDEDWLKQMQPSQVGWFETNCIIHYMYAGESFFEA |
|
NCBI Accession
|
YP_004089628.1
|
|
Location
|
1705-2616 |
|
Protein Name
|
RepA |
|
Coding Region
|
ATGGCCTCCTTTGTCAGTGAGACATCAGACGCCAGGGGGCAAACTGGCGCCCCCCGCTCACCGAGCGGGGAGGTTGGCGCCCCAGGGGCGGTCGCAGCATGCTTCGAGGTAAGATCAAGGAACATTTTCTTAACGTACAGCAAGTGCCACCTTGATCCGGTGTTCATGCAAGAACACCTCTCAAGCCTTCTTCGAAGGTTCGAACCCACGTATGTCTACGTGGCAAGAGAAGAACATCAAGATGGATCTTACCATTTGCATTGTCTGGTACAATGCAAGAAATATGTTCGCACCAAGAGTGCTAAATTCTTCGACGTCGAAGAATTTCATCCTAACGTGCAGAATGCAAGAATGCCACACAAGGTGTTAGCATACATCAAAAAAAACCCCTTATGTTTCGTAGAAACGGGGGTTTTCCAAGCAAGCACCAAGCAGAAGAAGAAGAAGGTTGATGCTCCATCAACTAAAGACGCCAAAATGGCGGAGATAATCAAGAGCAGTACCTGCAAGGAGGACTATCTCTCGATGGTCAGGAATACGTTCCCATTCGATTGGGCAACGAGGTTGCAACAATTCCAATACTCCGCAGAGAGCTTATTCCCTTCGGTTCCTACGCCATATATGGATCCCTTCGGGATGCCAGCACAGGATGAACATCCGGTGATTGGAGCATGGCTCCAAGCAGAATTATTTTCTGTAAGTCCTTATGCATATTCCATACATAATGGCGTAACGGAGGACCAAGCGAGGCTTGACCTCCAATGGATGTCTGATATTAGCAGGACAGACGTCCTGATGAACGAAGAAGATCACTCTACATTTGCGGACCAACAAGAACTGGAAAGACTTCTTGGGCTAGAAGTCTGGGAGCTCACAACTACTGGCAACACAGCGTCGACTTCCTCAACTTAG |
|
Protein Sequence
|
MASFVSETSDARGQTGAPRSPSGEVGAPGAVAACFEVRSRNIFLTYSKCHLDPVFMQEHLSSLLRRFEPTYVYVAREEHQDGSYHLHCLVQCKKYVRTKSAKFFDVEEFHPNVQNARMPHKVLAYIKKNPLCFVETGVFQASTKQKKKKVDAPSTKDAKMAEIIKSSTCKEDYLSMVRNTFPFDWATRLQQFQYSAESLFPSVPTPYMDPFGMPAQDEHPVIGAWLQAELFSVSPYAYSIHNGVTEDQARLDLQWMSDISRTDVLMNEEDHSTFADQQELERLLGLEVWELTTTGNTASTSST |