Grapevine red blotch virus
Basic Information
| Genus |
Grablovirus
|
| NCBI Assembly |
GCF_000909815.1 |
| Isolate |
USA |
| Release date |
2015/2/22 |
| Submitter |
Al Rwahnih,M., Dave,A., Anderson,M.M., Rowhani,A., Uyemoto,J.K., Sudarshana,M.R., Sudarshana,M. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
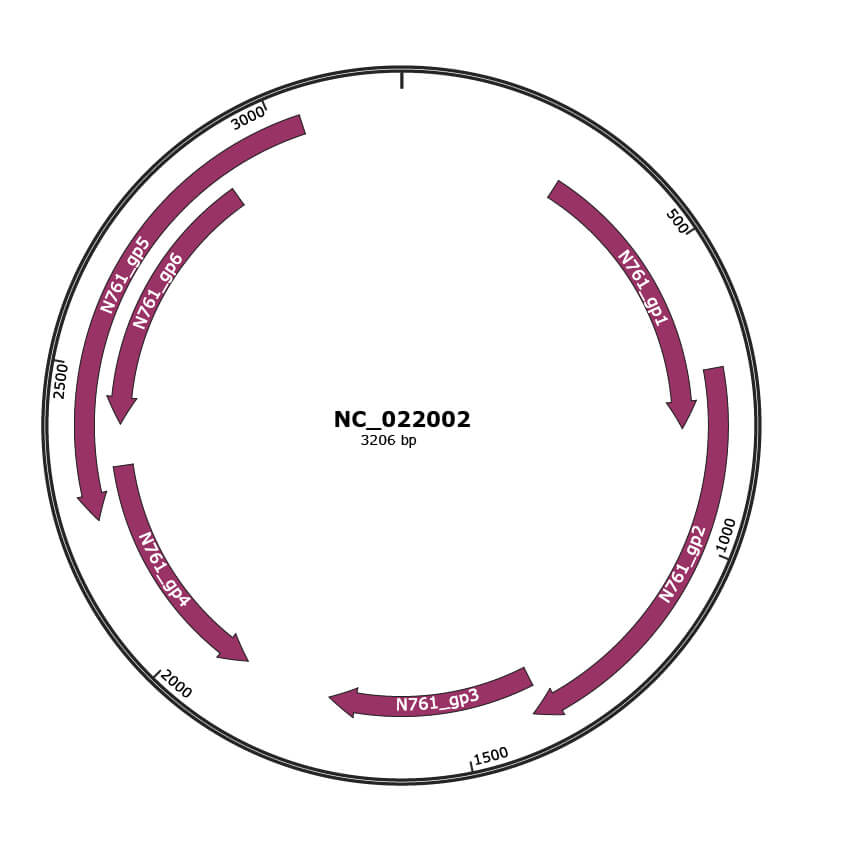
JBrowse
Genome
ACTGGCACTTCCCATGGTACGTGGTATTCTTGCGGAGCAAGTTTCTCTACTTTGGCAAATGCTTCTGATTGGTTGGTGTGGAATTTATTCTTTTCTTTTGTCGGCCACTTGCGTGGCTTTTACGCGAAGCTAAAGTGGCCGCATATATGTTTTTTAGTTAGGGCATATTATTAATGGAGGATCGATGCGGGTGGAAACGCACTTTGGCTGTTGTGCTAATTTCTCTCTCAATATTTTGGGTGTTGTACTGGTTAGTATTCTTCTCTCGTCCCATTTGTAAGAGGAATCGGAATGGTAACACTGAACAAACGGAATCGCGTTCTTCCTGAGTGCGATTCCTGCAGTTCTAGTGAAAGTTCTTTGAATGATATTGATATTTGTGGTGATGATGATGGGTTAGGGGATGAGGCTTTAGACGCTGGATCCGTTTATTCGTCGTCACAGAAACTGTTAGTTTCTGTGGCTAAAGATGTTCTTTTAGATGACTGTGATTCAACGATATTGGATATATCGTTGCCTTCTGCTTTATGGTTTTTGTCGCAAAGATATTTGACTTGTTGTTTGAGGAAAGAATTACTGCCTCTGCCAGGTATATCCGAGAAACAGACTGTTTTATTGCGACAGCTGATTAGGCGTGTCGCTCGTCGTCATTGTTTATTTACTTACAAGTGCGAGGAGTGGTTTGAGGGTTGTTTGAAGATAAAGAAGGATGGTAATGAAAAAAAGGAGCCGCCAACGGAAGCAGAGAAGAAGGCGCAGGACGACTGGGAGGAGTTCTGCCGTAAGGCGGCGTGCTCGGCCTCGTAGTAGGCCTTGTCAGTTTGCATTCCATGGGAATTCTTTTGGGGGTACCCCTTCCCTTTTTTTTTTGACTCCGATTGCTTTAGGTACTGGTGCGGAAGACAGAACAGGTCCAGTATTGACTGTCAGCAGTATGTATTTGAAAGGTGTTGTGCTTCCGTCGGATAATGTCACCGATGGATTGCATGATATTTATTTTTGGATAATTTTGGATCGGTTTCCTACTGGAACTGATCCTTCGGTATCTGATATATTCACTGGTAGTGATAACAGCGGAAGCATGATTGAGACATTAACGAGGAATCGTTTGAATCGTAAGAGATTTCGTATTTTGGGTTCGAAGAAACTTGTTGTTGGCGTGAATAAGAAGCCGCAGGAGTCATTGCCACATTCACGTGCAGCATTTAATATTTTTCAAAGACGTCGTCTGGTTGTCGCTTTTAAAAACGACGTGTCTGGTGGAGGACGTAATGATGTTGAAAGGAATCGTATTTATTTGTCTGCGGCTTCTGCAAGTGGACATACGTTTAGATTGTATCTAAATGGAATTGTAAACTTTTATAATGGAGTTATTTTTCAATAGACCACGCTGTTTATTATGGCGTGTGTATGATCAAGTTTCTGAGTTTGGTTTGTATGATGGTGGTGAAGATGTTGATATCCCCATTGTTGGGGATGATGAAGATGAAGAAATGGTTACAACTGGATATGGTGAATTCGTTAAGACGTTGAAGAGACGTCGATCTGAGCGCGGAGAGGTGACAAAGACTTACAAGCGAAGAATTGCATTGACTGAACCTGATCGTAGTAGAACTGAAGTTGAAGAATTGAGAGATTATTTGTTAGAGGAAGATTATGATAAGCATAGAAGACGTCTGGACCTGGAGCTAGGCTCAGGCTTGCATAGTCCAGACAGTCGTTGTACAGTAATGTGAATGTTGTATTTGGATATTTGAATAATAGAATATGGTGCAGGAGTTTATTAAAATTATAATGTAAACACTTCGAAATAAATCACACTTCAATACCAGACAATCAGGCACGATTTCTTTATGAAAGAACCCAGCCGCGAAGCGGCTGGCTGACCTTTTATTTATCAGTACAACGGTCTATCAATTTTTACAAAGATAATGTTTTCTTCAGCCCACGGCTTGAATGTTGCATGCCAATTGGTGATTGCATCATAGTAAGAGTTATCTGGATTACAAAGAACAATTGATGGGATCCCTCCTTTGATTTTCCGCTTTGGACGATATTTTTCATTTGCAATGTAATTGAATTGACAACCTAATAAGGCTTTTTTACAAGGCAAATATTGGAATGGTATATCGTCAATAATATTGTACAAAGCGTCGTCTATGTATAGACTGAAGTCTACTGATTCACACCAGTAGTTATGTATTCCCAATGATATAGCCCATTGCGTTTTACCCGTCTTCGATGGTCCTTCAATCACCAGGCTCTTCCTCCTTCGGTGCGTCGCTTCCTGCATTGTTGAGTTCATCGTCAGTGTTATATATTCTTTCAACATAATCCAAGTAATACGCGTCCAGCTTGTCGTCTATTATATGCTGGACGCGTTTTGTTTCTTGTTCAAGGAAATTGTTTATTCCTGGTCCAAGGTTTCGTTGTGCTGAGCTTTTGCGTACCACGTAGAGTTCGTTTTGGACCCAGAGATGAATTTCTGGTGGAAGGTTATTCCAAGCTGTCCACTGATTGGCATGTGGGGTAGGGGTGGGAGGCCATGTTTGAGCAGCAAAGTATTCAAGTCGTTGTAGATTGAGGACGTATTGGTAGGGGTAATGTTGTTTGACGAGTTGCAGAAACTCGTCTTTGGAATTTGCAACTCGTAGGAATTCTCCAAAATCCAGTTCTCTGGATTGCTTCTTTGATTTGAGAGTTGGCTTTGTACCGTGCTCGACGGTATCTCCTTCTTTTCCGACGTAATTAAGCACGTCGGCGACATCTCTGGGCTTTGTGATATTGGGGTGATAGGAATGAGACGATATGGTGATGTCAAAGTGTTTTGGATTGCGAATAGCCTGTCGTTTTTTGAAGATGAGCAAGGCGTGTAGGTGTGGCTCGCCATTCTGATGTTTTTCTTCTCCGATGAGAGCGTAATCTAGGGTTTTTTGGAACTTGGATTTGAAGAAGTCTAGGGCAAACTGTTTATGGACTGGGCACTGAGGGTATGTGAGGAAGAAGTTTTTTGAGCGGAGATTGAAGGAGCTACTTGATGCCATCTTGGTTGTATAAGATGGGTTGGTACTCTTTATATAGTGGTTGATTAGATGACATCAGGTGATGTCAGCTATTTTGTTTTATTATCCCTCAATTCTAGCTTATAGTTTTGGTGGTATTTTGGTACTCAGGGCAAAATTTGTATTGAAGTGCCATATAATATT
Gene Information
|
NCBI Accession
|
YP_008400113.1
|
|
Location
|
292-807 |
|
Protein Name
|
V2 protein |
|
Coding Region
|
ATGGTAACACTGAACAAACGGAATCGCGTTCTTCCTGAGTGCGATTCCTGCAGTTCTAGTGAAAGTTCTTTGAATGATATTGATATTTGTGGTGATGATGATGGGTTAGGGGATGAGGCTTTAGACGCTGGATCCGTTTATTCGTCGTCACAGAAACTGTTAGTTTCTGTGGCTAAAGATGTTCTTTTAGATGACTGTGATTCAACGATATTGGATATATCGTTGCCTTCTGCTTTATGGTTTTTGTCGCAAAGATATTTGACTTGTTGTTTGAGGAAAGAATTACTGCCTCTGCCAGGTATATCCGAGAAACAGACTGTTTTATTGCGACAGCTGATTAGGCGTGTCGCTCGTCGTCATTGTTTATTTACTTACAAGTGCGAGGAGTGGTTTGAGGGTTGTTTGAAGATAAAGAAGGATGGTAATGAAAAAAAGGAGCCGCCAACGGAAGCAGAGAAGAAGGCGCAGGACGACTGGGAGGAGTTCTGCCGTAAGGCGGCGTGCTCGGCCTCGTAG |
|
Protein Sequence
|
MVTLNKRNRVLPECDSCSSSESSLNDIDICGDDDGLGDEALDAGSVYSSSQKLLVSVAKDVLLDDCDSTILDISLPSALWFLSQRYLTCCLRKELLPLPGISEKQTVLLRQLIRRVARRHCLFTYKCEEWFEGCLKIKKDGNEKKEPPTEAEKKAQDDWEEFCRKAACSAS |
|
NCBI Accession
|
YP_008400114.1
|
|
Location
|
710-1384 |
|
Protein Name
|
V1 protein |
|
Coding Region
|
ATGGTAATGAAAAAAAGGAGCCGCCAACGGAAGCAGAGAAGAAGGCGCAGGACGACTGGGAGGAGTTCTGCCGTAAGGCGGCGTGCTCGGCCTCGTAGTAGGCCTTGTCAGTTTGCATTCCATGGGAATTCTTTTGGGGGTACCCCTTCCCTTTTTTTTTTGACTCCGATTGCTTTAGGTACTGGTGCGGAAGACAGAACAGGTCCAGTATTGACTGTCAGCAGTATGTATTTGAAAGGTGTTGTGCTTCCGTCGGATAATGTCACCGATGGATTGCATGATATTTATTTTTGGATAATTTTGGATCGGTTTCCTACTGGAACTGATCCTTCGGTATCTGATATATTCACTGGTAGTGATAACAGCGGAAGCATGATTGAGACATTAACGAGGAATCGTTTGAATCGTAAGAGATTTCGTATTTTGGGTTCGAAGAAACTTGTTGTTGGCGTGAATAAGAAGCCGCAGGAGTCATTGCCACATTCACGTGCAGCATTTAATATTTTTCAAAGACGTCGTCTGGTTGTCGCTTTTAAAAACGACGTGTCTGGTGGAGGACGTAATGATGTTGAAAGGAATCGTATTTATTTGTCTGCGGCTTCTGCAAGTGGACATACGTTTAGATTGTATCTAAATGGAATTGTAAACTTTTATAATGGAGTTATTTTTCAATAG |
|
Protein Sequence
|
MVMKKRSRQRKQRRRRRTTGRSSAVRRRARPRSRPCQFAFHGNSFGGTPSLFFLTPIALGTGAEDRTGPVLTVSSMYLKGVVLPSDNVTDGLHDIYFWIILDRFPTGTDPSVSDIFTGSDNSGSMIETLTRNRLNRKRFRILGSKKLVVGVNKKPQESLPHSRAAFNIFQRRRLVVAFKNDVSGGGRNDVERNRIYLSAASASGHTFRLYLNGIVNFYNGVIFQ |
|
NCBI Accession
|
YP_008400115.1
|
|
Location
|
1365-1736 |
|
Protein Name
|
V3 protein |
|
Coding Region
|
ATGGAGTTATTTTTCAATAGACCACGCTGTTTATTATGGCGTGTGTATGATCAAGTTTCTGAGTTTGGTTTGTATGATGGTGGTGAAGATGTTGATATCCCCATTGTTGGGGATGATGAAGATGAAGAAATGGTTACAACTGGATATGGTGAATTCGTTAAGACGTTGAAGAGACGTCGATCTGAGCGCGGAGAGGTGACAAAGACTTACAAGCGAAGAATTGCATTGACTGAACCTGATCGTAGTAGAACTGAAGTTGAAGAATTGAGAGATTATTTGTTAGAGGAAGATTATGATAAGCATAGAAGACGTCTGGACCTGGAGCTAGGCTCAGGCTTGCATAGTCCAGACAGTCGTTGTACAGTAATGTGA |
|
Protein Sequence
|
MELFFNRPRCLLWRVYDQVSEFGLYDGGEDVDIPIVGDDEDEEMVTTGYGEFVKTLKRRRSERGEVTKTYKRRIALTEPDRSRTEVEELRDYLLEEDYDKHRRRLDLELGSGLHSPDSRCTVM |
|
NCBI Accession
|
YP_008400116.1
|
|
Location
|
1898-2332 |
|
Protein Name
|
C2 protein |
|
Coding Region
|
ATGTTGAAAGAATATATAACACTGACGATGAACTCAACAATGCAGGAAGCGACGCACCGAAGGAGGAAGAGCCTGGTGATTGAAGGACCATCGAAGACGGGTAAAACGCAATGGGCTATATCATTGGGAATACATAACTACTGGTGTGAATCAGTAGACTTCAGTCTATACATAGACGACGCTTTGTACAATATTATTGACGATATACCATTCCAATATTTGCCTTGTAAAAAAGCCTTATTAGGTTGTCAATTCAATTACATTGCAAATGAAAAATATCGTCCAAAGCGGAAAATCAAAGGAGGGATCCCATCAATTGTTCTTTGTAATCCAGATAACTCTTACTATGATGCAATCACCAATTGGCATGCAACATTCAAGCCGTGGGCTGAAGAAAACATTATCTTTGTAAAAATTGATAGACCGTTGTACTGA |
|
Protein Sequence
|
MLKEYITLTMNSTMQEATHRRRKSLVIEGPSKTGKTQWAISLGIHNYWCESVDFSLYIDDALYNIIDDIPFQYLPCKKALLGCQFNYIANEKYRPKRKIKGGIPSIVLCNPDNSYYDAITNWHATFKPWAEENIIFVKIDRPLY |
|
NCBI Accession
|
YP_008400117.1
|
|
Location
|
2250-3044 |
|
Protein Name
|
C1 protein |
|
Coding Region
|
ATGGCATCAAGTAGCTCCTTCAATCTCCGCTCAAAAAACTTCTTCCTCACATACCCTCAGTGCCCAGTCCATAAACAGTTTGCCCTAGACTTCTTCAAATCCAAGTTCCAAAAAACCCTAGATTACGCTCTCATCGGAGAAGAAAAACATCAGAATGGCGAGCCACACCTACACGCCTTGCTCATCTTCAAAAAACGACAGGCTATTCGCAATCCAAAACACTTTGACATCACCATATCGTCTCATTCCTATCACCCCAATATCACAAAGCCCAGAGATGTCGCCGACGTGCTTAATTACGTCGGAAAAGAAGGAGATACCGTCGAGCACGGTACAAAGCCAACTCTCAAATCAAAGAAGCAATCCAGAGAACTGGATTTTGGAGAATTCCTACGAGTTGCAAATTCCAAAGACGAGTTTCTGCAACTCGTCAAACAACATTACCCCTACCAATACGTCCTCAATCTACAACGACTTGAATACTTTGCTGCTCAAACATGGCCTCCCACCCCTACCCCACATGCCAATCAGTGGACAGCTTGGAATAACCTTCCACCAGAAATTCATCTCTGGGTCCAAAACGAACTCTACGTGGTACGCAAAAGCTCAGCACAACGAAACCTTGGACCAGGAATAAACAATTTCCTTGAACAAGAAACAAAACGCGTCCAGCATATAATAGACGACAAGCTGGACGCGTATTACTTGGATTATGTTGAAAGAATATATAACACTGACGATGAACTCAACAATGCAGGAAGCGACGCACCGAAGGAGGAAGAGCCTGGTGATTGA |
|
Protein Sequence
|
MASSSSFNLRSKNFFLTYPQCPVHKQFALDFFKSKFQKTLDYALIGEEKHQNGEPHLHALLIFKKRQAIRNPKHFDITISSHSYHPNITKPRDVADVLNYVGKEGDTVEHGTKPTLKSKKQSRELDFGEFLRVANSKDEFLQLVKQHYPYQYVLNLQRLEYFAAQTWPPTPTPHANQWTAWNNLPPEIHLWVQNELYVVRKSSAQRNLGPGINNFLEQETKRVQHIIDDKLDAYYLDYVERIYNTDDELNNAGSDAPKEEEPGD |
|
NCBI Accession
|
YP_008400118.1
|
|
Location
|
2408-2890 |
|
Protein Name
|
C3 protein |
|
Coding Region
|
ATGGCGAGCCACACCTACACGCCTTGCTCATCTTCAAAAAACGACAGGCTATTCGCAATCCAAAACACTTTGACATCACCATATCGTCTCATTCCTATCACCCCAATATCACAAAGCCCAGAGATGTCGCCGACGTGCTTAATTACGTCGGAAAAGAAGGAGATACCGTCGAGCACGGTACAAAGCCAACTCTCAAATCAAAGAAGCAATCCAGAGAACTGGATTTTGGAGAATTCCTACGAGTTGCAAATTCCAAAGACGAGTTTCTGCAACTCGTCAAACAACATTACCCCTACCAATACGTCCTCAATCTACAACGACTTGAATACTTTGCTGCTCAAACATGGCCTCCCACCCCTACCCCACATGCCAATCAGTGGACAGCTTGGAATAACCTTCCACCAGAAATTCATCTCTGGGTCCAAAACGAACTCTACGTGGTACGCAAAAGCTCAGCACAACGAAACCTTGGACCAGGAATAA |
|
Protein Sequence
|
MASHTYTPCSSSKNDRLFAIQNTLTSPYRLIPITPISQSPEMSPTCLITSEKKEIPSSTVQSQLSNQRSNPENWILENSYELQIPKTSFCNSSNNITPTNTSSIYNDLNTLLLKHGLPPLPHMPISGQLGITFHQKFISGSKTNSTWYAKAQHNETLDQE |