Eragrostis curvula streak virus
Basic Information
| Genus |
Eragrovirus
|
| NCBI Assembly |
GCF_000884795.1 |
| Isolate |
South Africa |
| Release date |
2015/2/22 |
| Submitter |
Varsani,A., Shepherd,D.N., Dent,K., Monjane,A.L., Rybicki,E.P., Martin,D.P. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
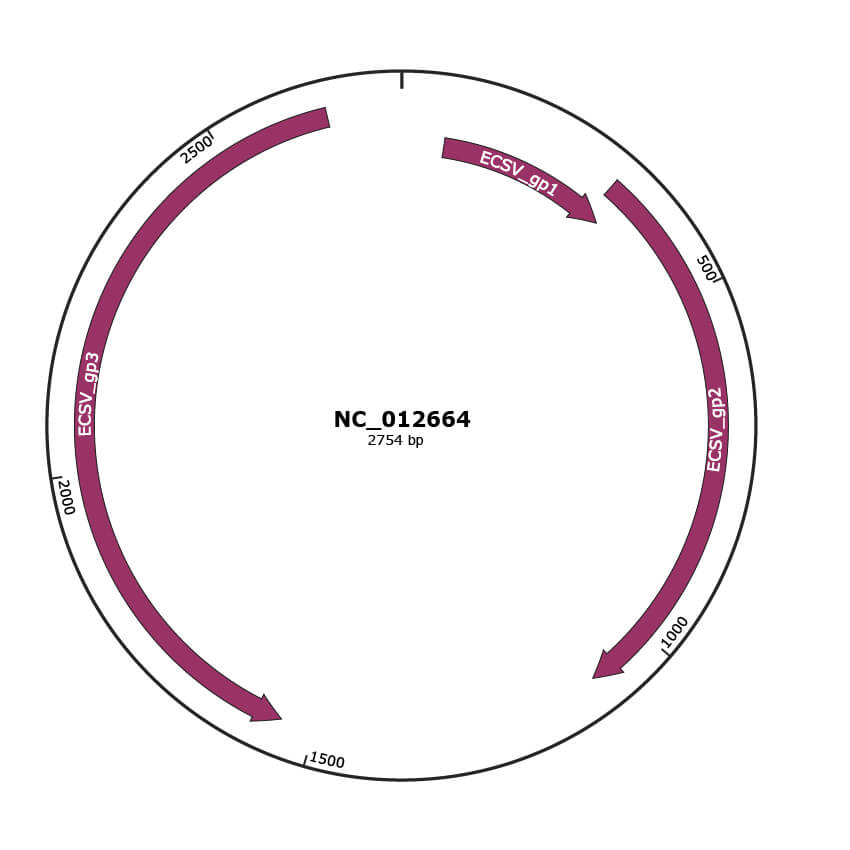
JBrowse
Genome
TAAGATTCCCGCTCCCCCCCCCCGCGAGCGCGTAGCGCGAGCCCGCCGGCCCATTTCGAAATAAAGATGTCAGGCCCACCTCCCTGCGATCGCACCGAGCCAGTACAGACAATACCTTTGTTGCTTTGCCATGGCCGGCGCAGTCTGCCGCTTTGCCATGCGGAGGTCCTTCCACCACAAGACTTAGGTCAGATCCGTTACTTGGTAAAGCGATTCAAGGCCCGTGTCCTTATTAGGACGATTGCGGAACAGTACAGCGGCAGTTCCTTAGCAGATAAGCTTGAGCTTATCTGGACGTTCTGTGATACCTTACAACATGAAGCGGAAGAGGAATGAAGCAGTTCCTGCGGGTCGCCGTTATCCTCAACGGCGTCGTATGTACTACCGTCCTCGTAAGCCTTTCTTTCCCCGCCCAGTGTATACAAGGTCCTCCAGTGTTAAACGTCCTGCCCTACAGATTAGTGGTCTCGTTTACGGGAACTCGAGTACGGGAGCCGTTAAAATTAACACTGGAGCACTTAGCCTTGTCACTGCATTTAAGGCGGGGACTGCAGAAGAGTGCAGACACTCTAATCAAACAATTGTGAAGTCCTTTGACATTAGTGGTACTCTGTACGTTCAGTCTCCCACTAGTTCAAACTGTGGTCCTGTTGTTGTTTACTTCTGGCTAATCTATGATTCAGAGCCTAGGCAGGCTATTCCTAACATAACAGATGTGTTCTCCATGCCTTGGACTAGTGTGCCGTCAAGTTGGCGTATATCTCGCTCTTCTTCACACCGATTTGTTGTGAAGAGGAAGTGGCATTACGAATTGATGTCAGATGGTGTCCTTCCCCAGAGTAACACGAAAGTGCAGACTCATAATCCCGTTTCCAGGAACATGATGGACTTCTCTAAGTACATCAATAATCTTGGTGTGCCAACGGAGTGGATGAGTACTGGTGATGGAACCATTGGTGATATCAAGAAGGGCGCGTTGTACCTCGCTGCTGCCTGCCGACAGGGAATTGTTGGAGATGCAACCAAGATTACTATAGAAGTAGAGTTTATCGGGCAGTCTCGTACTTATTTCAAGAGCATTGGCTACCAGTGATGTACTTCTTATTGCGAAACATTGTTGAATAAACATGCTAAACATAATGTTTGTTGTTGCTGTGAGCCGGGAGGCGAGGTCCGTCAAGGCCGAAGGCCTGACGGTTCCTCTGAGGCGCGAAGCGCGAAGCGCGAGTGCCGTGGAACCATATTTGCCGTTAACATTTCCTTAATTAAACGCCCCTGCGAGGCGGCGGGCGAAGCCCGACGACATACGCGCAGCGTATTACACAAGAGTAAAACACTAACAAGAATTGATACTCTCATCCCATAGTGCCTCATTAGGCCCCATGAGGTTACAGTTACAATCCACACACTTATCTAAAATACACTGAGCGCTGTGTCGCTCCGAGAACTCAAAATAAGTTGTAGGTATGTTACATGCGTCTTCATACTCCTGCTCGGCCCTTGACTTGAAGTGCGGCATTGGCATGAATTGATGTACACGGCCACAGTTACACGGCTTGGTCACCTGGATCACTATCTGAAGCCCACATTGGAGATTCAGGGTCATCTTCTCCGGTTTGCTCCCGCAGAGTAAGTGAGACTCCGCCAAAGAGAGCATCTTGGATATCCACGAAGACCGCATTTTTGCTAGTCCACGATCTAAGTTGGTGATTTTCTTCACAGTCAAGGAAGCATTTATAGGACTGGTCCGAGTTACAGAGCACGATAGCTGGTTTACCACCTTTAACCAGAACCGGTTTCCCATATTTCAGGTTACTTTGCCAGTCTTTCTGAGCTCCTAGAAACTCCTTCCAATGCTTTAGATATTTAGGGGTGACGTCATCGATGACGTTGTAACTTGCCTCGTTGTCGAATACGGCTCCGTTGAGGTCCAGATGTCCGCTGAGATAGTTGTGACGGCCCAATGATCTAGCCCAAGCCGTTTTTCCTGTACGGGAATCACCCTCAATTATCAATGATAATGGTCTATCCGGTATAGGATCTGCCCTTAAGTTATTTGCTACCCAGTCGGATAAGACTCTCGGTACAGAAAAACTGCTCTCTGAATATTTTGGAACAAAACTTGCTCGTACCTCAGACCATATGCGCCTGGCGTTGGTTACCAGGTTATGGTGTTGCAGCCAGAATGTACGCGGCTCGTTGTCTTTCACAAGCTGCAGAGCCTCCTCGATTGTACCTGAATTCACCGCTTGGTGCCACCATTCGTCTTGCTCAGCCTTTCTCTTGCGCCCCGTCAGCCTCTTGTCACATGGTACAGTACCATGTTCGTAGAAAGACCCAGCTTCTTTCTGTATGTACTTCAGACTCTTGGATACGGAACGACAAGTCTCAATCTTCGGATGGAATTCCCCGAAGTCGAATATACGAGGGTCTCGTATATCTCTACGCTCACTTGTACATACGATAGCATGAAGATGGTTGTTACCATCTTGGTGTTTTTCCTGTTGTACGCGTACGTACACTACGTGGCTAGCAAGAGTTGAGTGGGAAGTGAGGAACTCTCCCACATCCTTAGGCTCTCTTGGGCATTGTGAGTAAGTGAGGAAGAACGCCTTCCCTTGGATCCTAAATCTATGGCTGGATGAAGCCATCCTCAAACTAGTTTGGTCAAACCAAAACCCCTGGGTCAATTGTGAGGAATGAGGATGGAGGTTGTTATATAGCCTCTGGGGCCTCTGGGGGGGGGGGAGCGTC
Gene Information
|
NCBI Accession
|
YP_002875757.1
|
|
Location
|
67-336 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGTCAGGCCCACCTCCCTGCGATCGCACCGAGCCAGTACAGACAATACCTTTGTTGCTTTGCCATGGCCGGCGCAGTCTGCCGCTTTGCCATGCGGAGGTCCTTCCACCACAAGACTTAGGTCAGATCCGTTACTTGGTAAAGCGATTCAAGGCCCGTGTCCTTATTAGGACGATTGCGGAACAGTACAGCGGCAGTTCCTTAGCAGATAAGCTTGAGCTTATCTGGACGTTCTGTGATACCTTACAACATGAAGCGGAAGAGGAATGA |
|
Protein Sequence
|
MSGPPPCDRTEPVQTIPLLLCHGRRSLPLCHAEVLPPQDLGQIRYLVKRFKARVLIRTIAEQYSGSSLADKLELIWTFCDTLQHEAEEE |
|
NCBI Accession
|
YP_002875758.1
|
|
Location
|
317-1093 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGAAGCGGAAGAGGAATGAAGCAGTTCCTGCGGGTCGCCGTTATCCTCAACGGCGTCGTATGTACTACCGTCCTCGTAAGCCTTTCTTTCCCCGCCCAGTGTATACAAGGTCCTCCAGTGTTAAACGTCCTGCCCTACAGATTAGTGGTCTCGTTTACGGGAACTCGAGTACGGGAGCCGTTAAAATTAACACTGGAGCACTTAGCCTTGTCACTGCATTTAAGGCGGGGACTGCAGAAGAGTGCAGACACTCTAATCAAACAATTGTGAAGTCCTTTGACATTAGTGGTACTCTGTACGTTCAGTCTCCCACTAGTTCAAACTGTGGTCCTGTTGTTGTTTACTTCTGGCTAATCTATGATTCAGAGCCTAGGCAGGCTATTCCTAACATAACAGATGTGTTCTCCATGCCTTGGACTAGTGTGCCGTCAAGTTGGCGTATATCTCGCTCTTCTTCACACCGATTTGTTGTGAAGAGGAAGTGGCATTACGAATTGATGTCAGATGGTGTCCTTCCCCAGAGTAACACGAAAGTGCAGACTCATAATCCCGTTTCCAGGAACATGATGGACTTCTCTAAGTACATCAATAATCTTGGTGTGCCAACGGAGTGGATGAGTACTGGTGATGGAACCATTGGTGATATCAAGAAGGGCGCGTTGTACCTCGCTGCTGCCTGCCGACAGGGAATTGTTGGAGATGCAACCAAGATTACTATAGAAGTAGAGTTTATCGGGCAGTCTCGTACTTATTTCAAGAGCATTGGCTACCAGTGA |
|
Protein Sequence
|
MKRKRNEAVPAGRRYPQRRRMYYRPRKPFFPRPVYTRSSSVKRPALQISGLVYGNSSTGAVKINTGALSLVTAFKAGTAEECRHSNQTIVKSFDISGTLYVQSPTSSNCGPVVVYFWLIYDSEPRQAIPNITDVFSMPWTSVPSSWRISRSSSHRFVVKRKWHYELMSDGVLPQSNTKVQTHNPVSRNMMDFSKYINNLGVPTEWMSTGDGTIGDIKKGALYLAAACRQGIVGDATKITIEVEFIGQSRTYFKSIGYQ |
|
NCBI Accession
|
YP_002875759.1
|
|
Location
|
1548-2651 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGGCTTCATCCAGCCATAGATTTAGGATCCAAGGGAAGGCGTTCTTCCTCACTTACTCACAATGCCCAAGAGAGCCTAAGGATGTGGGAGAGTTCCTCACTTCCCACTCAACTCTTGCTAGCCACGTAGTGTACGTACGCGTACAACAGGAAAAACACCAAGATGGTAACAACCATCTTCATGCTATCGTATGTACAAGTGAGCGTAGAGATATACGAGACCCTCGTATATTCGACTTCGGGGAATTCCATCCGAAGATTGAGACTTGTCGTTCCGTATCCAAGAGTCTGAAGTACATACAGAAAGAAGCTGGGTCTTTCTACGAACATGGTACTGTACCATGTGACAAGAGGCTGACGGGGCGCAAGAGAAAGGCTGAGCAAGACGAATGGTGGCACCAAGCGGTGAATTCAGGTACAATCGAGGAGGCTCTGCAGCTTGTGAAAGACAACGAGCCGCGTACATTCTGGCTGCAACACCATAACCTGGTAACCAACGCCAGGCGCATATGGTCTGAGGTACGAGCAAGTTTTGTTCCAAAATATTCAGAGAGCAGTTTTTCTGTACCGAGAGTCTTATCCGACTGGGTAGCAAATAACTTAAGGGCAGATCCTATACCGGATAGACCATTATCATTGATAATTGAGGGTGATTCCCGTACAGGAAAAACGGCTTGGGCTAGATCATTGGGCCGTCACAACTATCTCAGCGGACATCTGGACCTCAACGGAGCCGTATTCGACAACGAGGCAAGTTACAACGTCATCGATGACGTCACCCCTAAATATCTAAAGCATTGGAAGGAGTTTCTAGGAGCTCAGAAAGACTGGCAAAGTAACCTGAAATATGGGAAACCGGTTCTGGTTAAAGGTGGTAAACCAGCTATCGTGCTCTGTAACTCGGACCAGTCCTATAAATGCTTCCTTGACTGTGAAGAAAATCACCAACTTAGATCGTGGACTAGCAAAAATGCGGTCTTCGTGGATATCCAAGATGCTCTCTTTGGCGGAGTCTCACTTACTCTGCGGGAGCAAACCGGAGAAGATGACCCTGAATCTCCAATGTGGGCTTCAGATAGTGATCCAGGTGACCAAGCCGTGTAA |
|
Protein Sequence
|
MASSSHRFRIQGKAFFLTYSQCPREPKDVGEFLTSHSTLASHVVYVRVQQEKHQDGNNHLHAIVCTSERRDIRDPRIFDFGEFHPKIETCRSVSKSLKYIQKEAGSFYEHGTVPCDKRLTGRKRKAEQDEWWHQAVNSGTIEEALQLVKDNEPRTFWLQHHNLVTNARRIWSEVRASFVPKYSESSFSVPRVLSDWVANNLRADPIPDRPLSLIIEGDSRTGKTAWARSLGRHNYLSGHLDLNGAVFDNEASYNVIDDVTPKYLKHWKEFLGAQKDWQSNLKYGKPVLVKGGKPAIVLCNSDQSYKCFLDCEENHQLRSWTSKNAVFVDIQDALFGGVSLTLREQTGEDDPESPMWASDSDPGDQAV |