Passion fruit chlorotic mottle virus
Basic Information
| Genus |
Citlodavirus
|
| NCBI Assembly |
GCF_004132865.1 |
| Isolate |
Brazil |
| Release date |
2019/2/12 |
| Submitter |
Fontenele,R.S., Abreu,R.A., Lamas,N.S., Alves-Freitas,D.M.T., Vidal,A.H., Poppiel,R.R., Melo,F.L., Lacorte,C., Martin,D.P., Campos,M.A., Varsani,A., Ribeiro,S.G. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
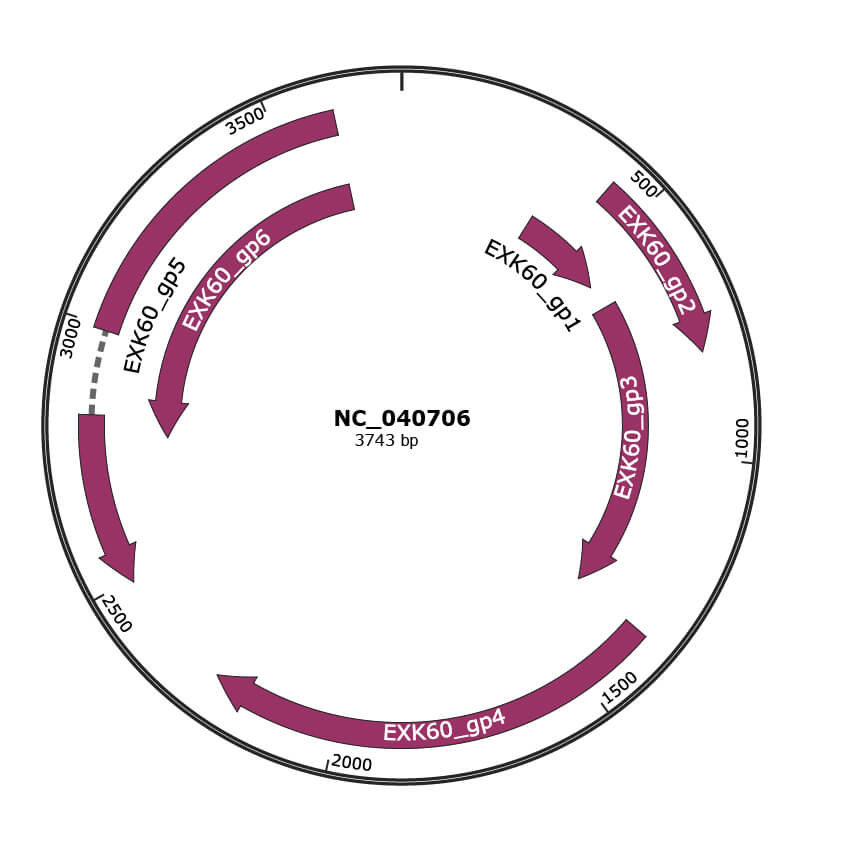
JBrowse
Genome
TAATATTACAAGCGCCCTCGTCGGTCACACGTGGCAGGATCTGGACCATTGAATGTGATGTACAGATGGACGGTTGAGATTCACGTATTATGGAGGAGAATAAATGCGATGTCAGTAAAGACATCAGAAAGGACATTTATTGATAGTGGAGAGAGAAAAGGTAAGGTTTTTTGAATTATTGTAGATAACACAGCACGTGGTGGGGTCGGTGAGACATTAAAGGTAGATTTTTATAGCGGGAAAGTGGTTAGCACTTTCACATCTTCAAAAATCGTACCGATGTGACTGGGGGTGTATAAAAGAGCAATAATTGCAGCTCTTTTGTACCTAGAAATGAGCATATCTTCTGAAATATTTGAGGAGATAAAAGAAAATAAGGTGAGTATCACCGTTTTTTTTATTATTTTCTTTTGCGTATCTGTTATAAATGTCGTGTGCTGTGCCTTTGGATTTTGGCAATCTGCCGGACCACGTGGTGGGGCTGTTGTGTATGTTGGCGGTGAGGCTATTAATGATGGAGGAGAAGAGATATGTTCTGGAAAAAAGGCACAGCCTGGCTAACAGGCATAGGATTCTGATAAGAATTATTCGCAAATGGGGCAGGAAAAATCGCGTAAAGGCGAATGGTGACTACGCGGAGTGGAAGAACTTATGGGCCTCCTACGGCCCAGACAAGGAGAAGATTTCCGCCCATGAGAAGGAGGCCAGCTATGGACCGAGTGATTGGGCCGTCAAAAAAAACTGTGAAGCGGATGAAAAAGGGAAAGTCCGGCGGGATTCCGGTTGGATGTAAGGGGCCTTGTAAAACCCATACAGTCGACGTTATTGCGACTGTAACTCATGATGGCAAGGGGCCAGGTTTAGTATCAAATATCAGCAAAGGTGATGACTTTGGTCAGCGTGAGGGTAGACGTATTCGGGTGACGAAATTATTACTGAGGGGTAAAGTATGGCTCCCTCAGGATAAGGCGACCATCGCTGGATCGAATATAATGAGACTGTGGGTTATGAAGGATAGGCGCCCTGGCAGTCAGCATGTTGCATTTGAGGCATTGTTTGACATGGCTGACAAAGAGCCCTCTACGGCATTAGTGAAGATGGATTATAGAGACAGATTTATTGTTATTAAGGATATGGAAATCGACCTGCATGGAGGGAGAGATTTCCGTGTGGACGAGGAAACATTTGATATAATGGTTCCGATAAATTGTGACGTGTTATTTGATCACAATGACGAGGGGTCTTTGACCACCACGTTAGAGAACGGGATTATCGTTTATTATGCTGTTACGGATCCCGCTCAAGTGATGCAACTCACAGCACAGTGTAGATTGTACTTTTTTGACTCTACGTCCAATTAATGCAAATGTTGTTTTTTTTAATCAGGATGTCGGATTCACAAATTAAGGTGTTTAATGAGTATCACAGCAGTAAGCGTGTTGAGTATCCTCTGACAAATGAGAAGACAATGATAAAGCTGGAATTCCCCTCTATGGGAGATATAAGTTGGTCAAGACTTAAGGGTCATTGTTTAAAAATTGACCATTGTCAGATAAGTTACACCCCTCAGGTGCCAGCAAATGCTAGTGGCAATGTATGCTTTGAGATACATGATATGCGAATGGAAGCGGATAAAACGTTACAGGCAGAGTACACGGTGCCCATCAGGTGTGCGGTGGAGTTGAATTTTTTTTCAACTTCTTTTTTCAGTATGAAAGACGATGTGCCATGGGAAGTGTTTTATTCCGTAGAGAATAGTGATGTACGTTCTGGTACGAGATTCTGTAAGATGAAAGCAAGGGTTAAGCTGTCTAGTGCTAAGCACAGCACCCATATTAACTTTAGATCCCCGACGATAAAAATAATATCGAGGGGGTTTAGCGAACGTGATGTTGATTTTCATCACGTGGCAATACCTAAGGCAGAGAGGTTACTCTGCAGGGGTAGTTCTGTAATAACGAGCAGGCCTCGTTTTGAGATCGAGGCTGGTGATAGTTGGGCCAGTAAGTCCAGCATTGGTGGTAGCGACGTGGACTATCCGTATAAGGAACTGGGCCGATTAAACGCGGATGCATTAGAGATTGGGCCCAGTGCAAGCCAAGTTGGTATTGGGCCAGGTAATGAGCCCAATAAAGGAAAGGTTGTAATGGATGCAGTTGAATTTGCTGAGGTGGTGGCGGATGCAGTACGGCATGGAAGTGTAATAAACAATAATATTATTAATGATAATAAGAAAAAGGCTCCGGCATAATGTGGGTCGGAGCATAGGAGCGAACTTGAGAGCGATACTTGCGGAGCGAAATACAACGCGAGAAAAGGATTATGTTTATTAATATATGCTGCGCAGCACAGGCGAAATGTAATGAGCCGTTTTTAATATGGGTGTTGCAACTTCATTTCAAATGTTATAAAATGTTCAGAAAACAACAGATAGTACTTTTTATTGAGATGGTAAAAGTAGAGTACATAATAATTTGGATAATGAATCCAAATTAGTCGAACCACTTTTCCTCTGGGGATAGGGTGTACTCATCGACGTTTGTTTCCCACCAAAGTCTGATGTCAGGTGACATCATGTCCCTCCAATCCATGTCTGGATTGCAGAGAACTATTGTTGGAATACCTCCGTTGATGGTCCTATCCGGTTTATACTTAATGTTAACTGTGAAATCTTTTTGGCATCCCAATAAAGATTTCATTATTTCTGTTGTGATTTTGCTATAACTTATGTCGTCTATTACATTATACAGAGCAAAATCATTATAATTATGAAACTTCAACGATCCGGTGGAGTAGTTATGTAATCCCATAGATCTGGCCCAGCAAGTCTTTCCCGTGCGAGAAGGTCCACAGATGAAGATGGACTTGGGCCTGTTGGGCTTTGCGTCGGGCTCCTGCAAGCATCACAGTAGTAGTAATGCATTGAGCGTATGGGAATTTCAGACTCTGTTAGCAGATGTGCTCTGCAGTCAAAGCATAAATTAATGCGTACAAATTCTGTACTCACGCATAATATGTTGCGATTAGCCCATGCCCTGACATGATGTGGTAGATTTGGGAAGTCGATGAACTGGGGAGTGTAAGGGACAAATCTACGTTGGAAGTGATCCCTTGCGAATGATTGAATTGCTGGCCAGCGTAGAACATAGTCCATGGGACGATGTTCCTTCACCATGCGGTAGAAGGTATCTTCGTCCGTAGAGATTTGGAGTATGTCTCTCCAGATTGTCTGTAAGTCTCTAGAAGGTGGTCTCCTGCTGGTGGAGAAATCACCTTCCTCAATGAAGTCGTTATCCTTGCGGATATATCGGTATGAAGCTGCTGGTGATCTAAGTGGTTCGAACGGCGGATGAAATATTCTGTTATCGTGCAATTCGTCTTTTATGTCGAAGAACCTTGGGTTAGTCGTATCAAGACGACGTCGCATTTGGACCATAGCATGTATATGGGGGTCTCCGTTTTGATGAGTTTCAAAACAGACGCAAATAAAAAAAATATCGAAGCTGCTGGGCTTTGATTTTAGGAAATTAAGGATATATTCCTTTGGGAGGAAGCATTGAGCGAAGGTTAGGAAAATGTTTTTTGCACTGAAGCGGAAGTTGGATGTTGAAGGCATTTTTTGTTTTCTGAAGTGAATCGAGGAGTCAACGCAAAGCGTACGGCGGATGAAAAGTCAACGGTGTGAGTAAACTCTATGGGATAACTAAGAGTGTGAGTGTGACCGTATACGAGGGCGCTACTTA
Gene Information
|
NCBI Accession
|
YP_009553192.1
|
|
Location
|
334-561 |
|
Protein Name
|
hypothetical protein |
|
Coding Region
|
ATGAGCATATCTTCTGAAATATTTGAGGAGATAAAAGAAAATAAGGTGAGTATCACCGTTTTTTTTATTATTTTCTTTTGCGTATCTGTTATAAATGTCGTGTGCTGTGCCTTTGGATTTTGGCAATCTGCCGGACCACGTGGTGGGGCTGTTGTGTATGTTGGCGGTGAGGCTATTAATGATGGAGGAGAAGAGATATGTTCTGGAAAAAAGGCACAGCCTGGCTAA |
|
Protein Sequence
|
MSISSEIFEEIKENKVSITVFFIIFFCVSVINVVCCAFGFWQSAGPRGGAVVYVGGEAINDGGEEICSGKKAQPG |
|
NCBI Accession
|
YP_009553193.1
|
|
Location
|
428-793 |
|
Protein Name
|
hypothetical v2 protein |
|
Coding Region
|
ATGTCGTGTGCTGTGCCTTTGGATTTTGGCAATCTGCCGGACCACGTGGTGGGGCTGTTGTGTATGTTGGCGGTGAGGCTATTAATGATGGAGGAGAAGAGATATGTTCTGGAAAAAAGGCACAGCCTGGCTAACAGGCATAGGATTCTGATAAGAATTATTCGCAAATGGGGCAGGAAAAATCGCGTAAAGGCGAATGGTGACTACGCGGAGTGGAAGAACTTATGGGCCTCCTACGGCCCAGACAAGGAGAAGATTTCCGCCCATGAGAAGGAGGCCAGCTATGGACCGAGTGATTGGGCCGTCAAAAAAAACTGTGAAGCGGATGAAAAAGGGAAAGTCCGGCGGGATTCCGGTTGGATGTAA |
|
Protein Sequence
|
MSCAVPLDFGNLPDHVVGLLCMLAVRLLMMEEKRYVLEKRHSLANRHRILIRIIRKWGRKNRVKANGDYAEWKNLWASYGPDKEKISAHEKEASYGPSDWAVKKNCEADEKGKVRRDSGWM |
|
NCBI Accession
|
YP_009553194.1
|
|
Location
|
624-1361 |
|
Protein Name
|
capsid protein |
|
Coding Region
|
ATGGTGACTACGCGGAGTGGAAGAACTTATGGGCCTCCTACGGCCCAGACAAGGAGAAGATTTCCGCCCATGAGAAGGAGGCCAGCTATGGACCGAGTGATTGGGCCGTCAAAAAAAACTGTGAAGCGGATGAAAAAGGGAAAGTCCGGCGGGATTCCGGTTGGATGTAAGGGGCCTTGTAAAACCCATACAGTCGACGTTATTGCGACTGTAACTCATGATGGCAAGGGGCCAGGTTTAGTATCAAATATCAGCAAAGGTGATGACTTTGGTCAGCGTGAGGGTAGACGTATTCGGGTGACGAAATTATTACTGAGGGGTAAAGTATGGCTCCCTCAGGATAAGGCGACCATCGCTGGATCGAATATAATGAGACTGTGGGTTATGAAGGATAGGCGCCCTGGCAGTCAGCATGTTGCATTTGAGGCATTGTTTGACATGGCTGACAAAGAGCCCTCTACGGCATTAGTGAAGATGGATTATAGAGACAGATTTATTGTTATTAAGGATATGGAAATCGACCTGCATGGAGGGAGAGATTTCCGTGTGGACGAGGAAACATTTGATATAATGGTTCCGATAAATTGTGACGTGTTATTTGATCACAATGACGAGGGGTCTTTGACCACCACGTTAGAGAACGGGATTATCGTTTATTATGCTGTTACGGATCCCGCTCAAGTGATGCAACTCACAGCACAGTGTAGATTGTACTTTTTTGACTCTACGTCCAATTAA |
|
Protein Sequence
|
MVTTRSGRTYGPPTAQTRRRFPPMRRRPAMDRVIGPSKKTVKRMKKGKSGGIPVGCKGPCKTHTVDVIATVTHDGKGPGLVSNISKGDDFGQREGRRIRVTKLLLRGKVWLPQDKATIAGSNIMRLWVMKDRRPGSQHVAFEALFDMADKEPSTALVKMDYRDRFIVIKDMEIDLHGGRDFRVDEETFDIMVPINCDVLFDHNDEGSLTTTLENGIIVYYAVTDPAQVMQLTAQCRLYFFDSTSN |
|
NCBI Accession
|
YP_009553195.1
|
|
Location
|
1361-2251 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGCAAATGTTGTTTTTTTTAATCAGGATGTCGGATTCACAAATTAAGGTGTTTAATGAGTATCACAGCAGTAAGCGTGTTGAGTATCCTCTGACAAATGAGAAGACAATGATAAAGCTGGAATTCCCCTCTATGGGAGATATAAGTTGGTCAAGACTTAAGGGTCATTGTTTAAAAATTGACCATTGTCAGATAAGTTACACCCCTCAGGTGCCAGCAAATGCTAGTGGCAATGTATGCTTTGAGATACATGATATGCGAATGGAAGCGGATAAAACGTTACAGGCAGAGTACACGGTGCCCATCAGGTGTGCGGTGGAGTTGAATTTTTTTTCAACTTCTTTTTTCAGTATGAAAGACGATGTGCCATGGGAAGTGTTTTATTCCGTAGAGAATAGTGATGTACGTTCTGGTACGAGATTCTGTAAGATGAAAGCAAGGGTTAAGCTGTCTAGTGCTAAGCACAGCACCCATATTAACTTTAGATCCCCGACGATAAAAATAATATCGAGGGGGTTTAGCGAACGTGATGTTGATTTTCATCACGTGGCAATACCTAAGGCAGAGAGGTTACTCTGCAGGGGTAGTTCTGTAATAACGAGCAGGCCTCGTTTTGAGATCGAGGCTGGTGATAGTTGGGCCAGTAAGTCCAGCATTGGTGGTAGCGACGTGGACTATCCGTATAAGGAACTGGGCCGATTAAACGCGGATGCATTAGAGATTGGGCCCAGTGCAAGCCAAGTTGGTATTGGGCCAGGTAATGAGCCCAATAAAGGAAAGGTTGTAATGGATGCAGTTGAATTTGCTGAGGTGGTGGCGGATGCAGTACGGCATGGAAGTGTAATAAACAATAATATTATTAATGATAATAAGAAAAAGGCTCCGGCATAA |
|
Protein Sequence
|
MQMLFFLIRMSDSQIKVFNEYHSSKRVEYPLTNEKTMIKLEFPSMGDISWSRLKGHCLKIDHCQISYTPQVPANASGNVCFEIHDMRMEADKTLQAEYTVPIRCAVELNFFSTSFFSMKDDVPWEVFYSVENSDVRSGTRFCKMKARVKLSSAKHSTHINFRSPTIKIISRGFSERDVDFHHVAIPKAERLLCRGSSVITSRPRFEIEAGDSWASKSSIGGSDVDYPYKELGRLNADALEIGPSASQVGIGPGNEPNKGKVVMDAVEFAEVVADAVRHGSVINNNIINDNKKKAPA |
|
NCBI Accession
|
YP_009553196.1
|
|
Location
|
2493-2828,2993-3616 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGCCTTCAACATCCAACTTCCGCTTCAGTGCAAAAAACATTTTCCTAACCTTCGCTCAATGCTTCCTCCCAAAGGAATATATCCTTAATTTCCTAAAATCAAAGCCCAGCAGCTTCGATATTTTTTTTATTTGCGTCTGTTTTGAAACTCATCAAAACGGAGACCCCCATATACATGCTATGGTCCAAATGCGACGTCGTCTTGATACGACTAACCCAAGGTTCTTCGACATAAAAGACGAATTGCACGATAACAGAATATTTCATCCGCCGTTCGAACCACTTAGATCACCAGCAGCTTCATACCGATATATCCGCAAGGATAACGACTTCATTGAGGAAGGTGATTTCTCCACCAGCAGGAGACCACCTTCTAGAGACTTACAGACAATCTGGAGAGACATACTCCAAATCTCTACGGACGAAGATACCTTCTACCGCATGGTGAAGGAACATCGTCCCATGGACTATGTTCTACGCTGGCCAGCAATTCAATCATTCGCAAGGGATCACTTCCAACGTAGATTTGTCCCTTACACTCCCCAGTTCATCGACTTCCCAAATCTACCACATCATGTCAGGGCATGGGCTAATCGCAACATATTATGCGTGAGTACAGAATTTACTTGCTGGGCCAGATCTATGGGATTACATAACTACTCCACCGGATCGTTGAAGTTTCATAATTATAATGATTTTGCTCTGTATAATGTAATAGACGACATAAGTTATAGCAAAATCACAACAGAAATAATGAAATCTTTATTGGGATGCCAAAAAGATTTCACAGTTAACATTAAGTATAAACCGGATAGGACCATCAACGGAGGTATTCCAACAATAGTTCTCTGCAATCCAGACATGGATTGGAGGGACATGATGTCACCTGACATCAGACTTTGGTGGGAAACAAACGTCGATGAGTACACCCTATCCCCAGAGGAAAAGTGGTTCGACTAA |
|
Protein Sequence
|
MPSTSNFRFSAKNIFLTFAQCFLPKEYILNFLKSKPSSFDIFFICVCFETHQNGDPHIHAMVQMRRRLDTTNPRFFDIKDELHDNRIFHPPFEPLRSPAASYRYIRKDNDFIEEGDFSTSRRPPSRDLQTIWRDILQISTDEDTFYRMVKEHRPMDYVLRWPAIQSFARDHFQRRFVPYTPQFIDFPNLPHHVRAWANRNILCVSTEFTCWARSMGLHNYSTGSLKFHNYNDFALYNVIDDISYSKITTEIMKSLLGCQKDFTVNIKYKPDRTINGGIPTIVLCNPDMDWRDMMSPDIRLWWETNVDEYTLSPEEKWFD |
|
NCBI Accession
|
YP_009553197.1
|
|
Location
|
2777-3616 |
|
Protein Name
|
RepA |
|
Coding Region
|
ATGCCTTCAACATCCAACTTCCGCTTCAGTGCAAAAAACATTTTCCTAACCTTCGCTCAATGCTTCCTCCCAAAGGAATATATCCTTAATTTCCTAAAATCAAAGCCCAGCAGCTTCGATATTTTTTTTATTTGCGTCTGTTTTGAAACTCATCAAAACGGAGACCCCCATATACATGCTATGGTCCAAATGCGACGTCGTCTTGATACGACTAACCCAAGGTTCTTCGACATAAAAGACGAATTGCACGATAACAGAATATTTCATCCGCCGTTCGAACCACTTAGATCACCAGCAGCTTCATACCGATATATCCGCAAGGATAACGACTTCATTGAGGAAGGTGATTTCTCCACCAGCAGGAGACCACCTTCTAGAGACTTACAGACAATCTGGAGAGACATACTCCAAATCTCTACGGACGAAGATACCTTCTACCGCATGGTGAAGGAACATCGTCCCATGGACTATGTTCTACGCTGGCCAGCAATTCAATCATTCGCAAGGGATCACTTCCAACGTAGATTTGTCCCTTACACTCCCCAGTTCATCGACTTCCCAAATCTACCACATCATGTCAGGGCATGGGCTAATCGCAACATATTATGCGTGAGTACAGAATTTGTACGCATTAATTTATGCTTTGACTGCAGAGCACATCTGCTAACAGAGTCTGAAATTCCCATACGCTCAATGCATTACTACTACTGTGATGCTTGCAGGAGCCCGACGCAAAGCCCAACAGGCCCAAGTCCATCTTCATCTGTGGACCTTCTCGCACGGGAAAGACTTGCTGGGCCAGATCTATGGGATTACATAACTACTCCACCGGATCGTTGA |
|
Protein Sequence
|
MPSTSNFRFSAKNIFLTFAQCFLPKEYILNFLKSKPSSFDIFFICVCFETHQNGDPHIHAMVQMRRRLDTTNPRFFDIKDELHDNRIFHPPFEPLRSPAASYRYIRKDNDFIEEGDFSTSRRPPSRDLQTIWRDILQISTDEDTFYRMVKEHRPMDYVLRWPAIQSFARDHFQRRFVPYTPQFIDFPNLPHHVRAWANRNILCVSTEFVRINLCFDCRAHLLTESEIPIRSMHYYYCDACRSPTQSPTGPSPSSSVDLLARERLAGPDLWDYITTPPDR |