Paper mulberry leaf curl virus 2
Basic Information
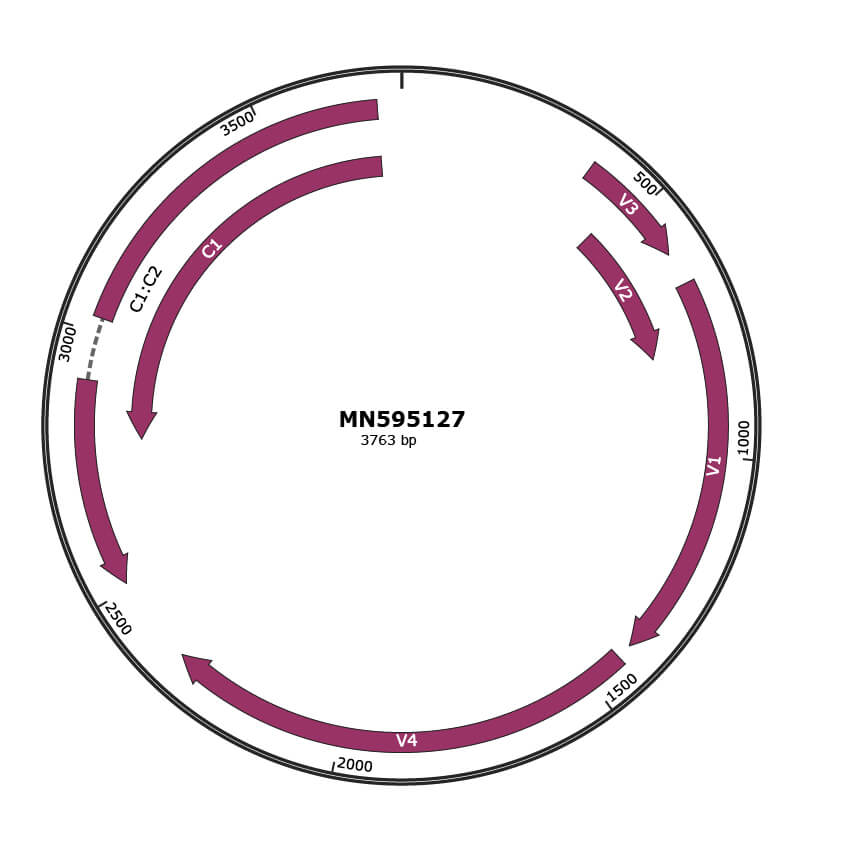
Genomic Organization
JBrowse
Genome
ACCTAGCTGGGAGCGGTGGGAGTGGTAGTAGGACACGTGTAAGGCTGAGATTTAACGAGAGCGAATAAAGCAAGCCAATAATGGAAGATGGACGGTGTAGATTGAAAGTTGAGTTAAACTTTGATCCAACGGTTAAAAAGTATGGTGGGAGCGTACGGGACCGTTGGATTGGAATCTACTTTAAGTTAGTGGACGCGGAATTATTGTTGAAATAATTGCGTGTGGGTCCCATATGTCTATTGAAGCTTAATGACGAAGCTTCTGCCGACAGTCCTCATAAGTAAATTTGAATTTCGAAATTACGTATTTGCCGCTTAATTGTCGTGGTGAACACGAAATTAATTATTATATAAAGGCAGTTAGAGTATATTTCGAAGCCATGGAGAGTTGTAAACTATCAGCAGAAGAATTTAGAGAGGTACTTTTCTTTGCTTGTGTAGCAGTAATTTTTTTTTCATTAGTATTAAATGTCTCAGTTTTTGTTAAAACGGCGGGATTTGCCCGAACGTTTAATGGGCACAATATACATGTGTGCCGTGAAGTATGTACAACTTCAGGAGGAAAAAAATATGAAAGTAGGAAATTTCCAGGGGATGGATGAGTGTAGATATTTGATCCGTTTAATACGCAGACATAGCAGAGTTCGGAATAGGCGAGAAGTAAATGGTGACTACGAGGGCTGGATCAAGAGTTATTGCGAAGGTACTCCCTGTATGGGGTGCCCGAGGGAAACGGAGCATAAGGCCCAAGGGGGGCAGGAAGAAAGGTGGCTCGAAGGGCCCAACTAAAGCCCGTGTTCGTATGGGCCGTGGATCTATTCCTTCTGGATTTAAAGGTCCATGTAAAACCCATACGTTAGATATAATAAAGACCATTCATAGGGATGGTCGTGGTTCTGGACAGCTGTCAAATATTGATAGGGGGGAAGATTTGGGTAATAGAGAAGGTCGACGTGTACGTGTCAGTAGGATGTTAATTAGAGGCAAATTATGGTTAGATGCGAATAACAGTAAGGCACCTGGGAGTAATCTGACGAAATTATGGTTTATTAAGGACAGGAGGCCTGGCAATGAGGTGGTGTCATTTTCTTCTTTGATGGATATGACTGATAGTGAACCACTATCAGCTGTTGTGAAGATGGACTACAGAGACAGATTCATTGTCCTTAAGGACATGGTGGTTGATCTGCATGGAGGCGAAAATTTTCGCATTAATGCTATTGATATAGATGAGATGATAGAATGTAATTGTGATGTATTGTTTAATCATGAAGATCAAGGCAGTTTGACGAACACCTTAGAGAATGCTATAATGGTGTACTATGCATGTAGTGATAGTATTCATCAGACCCAAATTACAGCTCAATGTAGATTATATTTCTTTGATAGTGTATCTAATTAAATATTAATAAGATTATAAATTTTTTCAGAATGGAGCGGAGTCATGACGTAGCTTTAAAAAATTACCACAGTTCGAAAAGCATTGAGTATCCATTATCAAATGATTTAGTTCAAATATCATTGGCCTTTCCTGGATTAGCCGAGATTAGTTGGTCTCGGGTGAAAGGACAATGTATGAAAATTGACCATTGTCAAATTGTGTATACGCCACAAGTTCCGGCAAATGCGGAAGGGACAGTTATAGTCGTTATACATGATAAGCGTATGGAGATGGATAAAAGCCTTCAGGCTGAGTATACATTCCCTATACGATGTCCTGTGACATTGAATTATTTCTCAACGAGTTTTTTTTCGTTGAGGGACGAGGTGCCATGGGCTGTTTATTACAAAGTAATAGATAGTACTATGTTAAGCGGTACGCATTTCTGCCAGTTTAAGGCGAGGATTAAGCTGAGTTCTGCAAAGCATTCACAATATATAATGTTTAGAGCTCCAACTATGGAGATTAACTCTAAGGAATTCACTAAAGATCAAGTGGATTTTATGCATGTGGCGATACCAAAACCCAATAGGGTTTTGTGTAGGAGTAGTTCTGTAATTCAAAGCAAGCCCAGATTTGAGTTGGGCCCTGGCGAGAATTGGGCTACTAAGAGTATGCTGGCAGGTGAAGAAGGAGATAATATGTCGGAGTCTGGTGCTGGCCCATATCAATCATTAAACAGATTGGGCCTCGACGCAATTGATCCAGGCCCTTCGGCAAGTCAATTGGGCCGTAATGAAACCCATTCTGATTTGGGTCGGATACAGTTGAATGCAAACGATTTAGCTGGTATAGTCAGCGAGGCGTTGATTAGAGGTAGCCAATTAGGTGTTGATAAGAGTGAAGAGGGTGATTCACAGAAAGATAATTCTGGAATCAAGAAAAAAAATGTAATGTAAAACATACGTTGTAAATATTGATTTTATTGAATATGAATAAAATTATAAATTTTTAAAATTGCCATGAATGAAAATAAGGTCGCAAACAGGTTTTCTATGCGCGACAAATTCCGTTAGTACAAGACACTAAAAAAAGCAATATATTTATATTAATGTTTTTAAACCGAAGGTTTAAAAGAAAGTGTCACTTTCATTCATATAATAAGTGATTACATTCTTGTGCCACCATGTCTTAATTTCCGTGGACATGGTTGAGAGCCAGTCCATATCAGGATTACAGAGAATAATGGTGGGTATCCCCCCTTTGATAGTACGATCTGGTTTATATTTAATATTAACCGTTACATTATGTTGACAACCTACTAATGATTTCATTATTTCAGACGAGATTCTAGTATAGTGAATGTCGTCTATTACATTGTATAATGCATAGTCATTGTAATCGTGGAATTTTAACTGGCCCGTGAAGTAGTTGTGTAGGCCCAATGATCTGGCCCAGCATGTCTTGCCTGATCTGCTCGGTCCGCAGATGTAGAGGGAGATTGGCCTGTTGGGCTTGTTCTCGGGGTCCTGCAATCAGCGGCATCGCAGTAGTAGTGGTGTAGGAGTGAAATGGTGTTTTCAGACTCGAACCGAGCCTTAGTTGAGCAATTGAAGCACAAATCATAATGAATGAAGGGTTTACTTACGAAAAGGATGTTGTCGTTTGCCCATTGCTGTATGTGTTGAGGGAGGTTTTGAAATTCTGTGAAAACCGGCATGAATGGCTCAACGACACGTTTGTAGTGGTCGTTGGCAAAGGATGATATGGCTGGCCAACGAAGGACGAAGTCCTGTGGTCGTTGGTCCTTGACTTTTGCCAGAAAGTCGTTTATGTCGGAGGCTGTGTCCAGAATGTCTTTCCAAATGGCGTTGGGATTTTTGGATGGGGATCTCTTCTTGTTGTTGAAAACCCCATCCTCATAAAAATTACCTGATTTTTTCAGGTATTTTTGACTAGCAGTGGGAGAGTGTAGTGGTTCAATATTTGGATGGTACCTTACGGTTGGCCCTTGTACAGGGTGTAATGGACCCATGTAGATGTCGAAGAAGCGACAGTTCCTTGTTTCGAACTGTTTGTCAAGTTGAACCATGGCGTGGACATGGGGTTCACCAGAAGCGTGAGTTTCCTCACACACAAGGATGTAGGTGATGTTGTGATGATGGAGAATGACCTTCAATTGTGTGGATACGTCATTCTTATGCAGTGGGCAGTTTGGGTATGTTAAGAAAATGTTTTTGGCTTTGAATCGGAATGATGTGGGAGGAGTGTTCGACATGTTGACAGTAGGGATTTGTAGTGGGCAATTGGGATAAGCAAATACTCTGGTTGATTGCATGTTGTTTGGAGGATGGGGTTCGCTCCCAGCTAGATTTATAATATT
Gene Information
|
NCBI Accession
|
QJX74424.1
|
|
Location
|
380-601 |
|
Protein Name
|
V3 |
|
Coding Region
|
ATGGAGAGTTGTAAACTATCAGCAGAAGAATTTAGAGAGGTACTTTTCTTTGCTTGTGTAGCAGTAATTTTTTTTTCATTAGTATTAAATGTCTCAGTTTTTGTTAAAACGGCGGGATTTGCCCGAACGTTTAATGGGCACAATATACATGTGTGCCGTGAAGTATGTACAACTTCAGGAGGAAAAAAATATGAAAGTAGGAAATTTCCAGGGGATGGATGA |
|
Protein Sequence
|
MESCKLSAEEFREVLFFACVAVIFFSLVLNVSVFVKTAGFARTFNGHNIHVCREVCTTSGGKKYESRKFPGDG |
|
NCBI Accession
|
QJX74423.1
|
|
Location
|
468-788 |
|
Protein Name
|
V2 |
|
Coding Region
|
ATGTCTCAGTTTTTGTTAAAACGGCGGGATTTGCCCGAACGTTTAATGGGCACAATATACATGTGTGCCGTGAAGTATGTACAACTTCAGGAGGAAAAAAATATGAAAGTAGGAAATTTCCAGGGGATGGATGAGTGTAGATATTTGATCCGTTTAATACGCAGACATAGCAGAGTTCGGAATAGGCGAGAAGTAAATGGTGACTACGAGGGCTGGATCAAGAGTTATTGCGAAGGTACTCCCTGTATGGGGTGCCCGAGGGAAACGGAGCATAAGGCCCAAGGGGGGCAGGAAGAAAGGTGGCTCGAAGGGCCCAACTAA |
|
Protein Sequence
|
MSQFLLKRRDLPERLMGTIYMCAVKYVQLQEEKNMKVGNFQGMDECRYLIRLIRRHSRVRNRREVNGDYEGWIKSYCEGTPCMGCPRETEHKAQGGQEERWLEGPN |
|
NCBI Accession
|
QJX74422.1
|
|
Location
|
664-1401 |
|
Protein Name
|
V1 |
|
Coding Region
|
ATGGTGACTACGAGGGCTGGATCAAGAGTTATTGCGAAGGTACTCCCTGTATGGGGTGCCCGAGGGAAACGGAGCATAAGGCCCAAGGGGGGCAGGAAGAAAGGTGGCTCGAAGGGCCCAACTAAAGCCCGTGTTCGTATGGGCCGTGGATCTATTCCTTCTGGATTTAAAGGTCCATGTAAAACCCATACGTTAGATATAATAAAGACCATTCATAGGGATGGTCGTGGTTCTGGACAGCTGTCAAATATTGATAGGGGGGAAGATTTGGGTAATAGAGAAGGTCGACGTGTACGTGTCAGTAGGATGTTAATTAGAGGCAAATTATGGTTAGATGCGAATAACAGTAAGGCACCTGGGAGTAATCTGACGAAATTATGGTTTATTAAGGACAGGAGGCCTGGCAATGAGGTGGTGTCATTTTCTTCTTTGATGGATATGACTGATAGTGAACCACTATCAGCTGTTGTGAAGATGGACTACAGAGACAGATTCATTGTCCTTAAGGACATGGTGGTTGATCTGCATGGAGGCGAAAATTTTCGCATTAATGCTATTGATATAGATGAGATGATAGAATGTAATTGTGATGTATTGTTTAATCATGAAGATCAAGGCAGTTTGACGAACACCTTAGAGAATGCTATAATGGTGTACTATGCATGTAGTGATAGTATTCATCAGACCCAAATTACAGCTCAATGTAGATTATATTTCTTTGATAGTGTATCTAATTAA |
|
Protein Sequence
|
MVTTRAGSRVIAKVLPVWGARGKRSIRPKGGRKKGGSKGPTKARVRMGRGSIPSGFKGPCKTHTLDIIKTIHRDGRGSGQLSNIDRGEDLGNREGRRVRVSRMLIRGKLWLDANNSKAPGSNLTKLWFIKDRRPGNEVVSFSSLMDMTDSEPLSAVVKMDYRDRFIVLKDMVVDLHGGENFRINAIDIDEMIECNCDVLFNHEDQGSLTNTLENAIMVYYACSDSIHQTQITAQCRLYFFDSVSN |
|
NCBI Accession
|
QJX74425.1
|
|
Location
|
1431-2339 |
|
Protein Name
|
V4 |
|
Coding Region
|
ATGGAGCGGAGTCATGACGTAGCTTTAAAAAATTACCACAGTTCGAAAAGCATTGAGTATCCATTATCAAATGATTTAGTTCAAATATCATTGGCCTTTCCTGGATTAGCCGAGATTAGTTGGTCTCGGGTGAAAGGACAATGTATGAAAATTGACCATTGTCAAATTGTGTATACGCCACAAGTTCCGGCAAATGCGGAAGGGACAGTTATAGTCGTTATACATGATAAGCGTATGGAGATGGATAAAAGCCTTCAGGCTGAGTATACATTCCCTATACGATGTCCTGTGACATTGAATTATTTCTCAACGAGTTTTTTTTCGTTGAGGGACGAGGTGCCATGGGCTGTTTATTACAAAGTAATAGATAGTACTATGTTAAGCGGTACGCATTTCTGCCAGTTTAAGGCGAGGATTAAGCTGAGTTCTGCAAAGCATTCACAATATATAATGTTTAGAGCTCCAACTATGGAGATTAACTCTAAGGAATTCACTAAAGATCAAGTGGATTTTATGCATGTGGCGATACCAAAACCCAATAGGGTTTTGTGTAGGAGTAGTTCTGTAATTCAAAGCAAGCCCAGATTTGAGTTGGGCCCTGGCGAGAATTGGGCTACTAAGAGTATGCTGGCAGGTGAAGAAGGAGATAATATGTCGGAGTCTGGTGCTGGCCCATATCAATCATTAAACAGATTGGGCCTCGACGCAATTGATCCAGGCCCTTCGGCAAGTCAATTGGGCCGTAATGAAACCCATTCTGATTTGGGTCGGATACAGTTGAATGCAAACGATTTAGCTGGTATAGTCAGCGAGGCGTTGATTAGAGGTAGCCAATTAGGTGTTGATAAGAGTGAAGAGGGTGATTCACAGAAAGATAATTCTGGAATCAAGAAAAAAAATGTAATGTAA |
|
Protein Sequence
|
MERSHDVALKNYHSSKSIEYPLSNDLVQISLAFPGLAEISWSRVKGQCMKIDHCQIVYTPQVPANAEGTVIVVIHDKRMEMDKSLQAEYTFPIRCPVTLNYFSTSFFSLRDEVPWAVYYKVIDSTMLSGTHFCQFKARIKLSSAKHSQYIMFRAPTMEINSKEFTKDQVDFMHVAIPKPNRVLCRSSSVIQSKPRFELGPGENWATKSMLAGEEGDNMSESGAGPYQSLNRLGLDAIDPGPSASQLGRNETHSDLGRIQLNANDLAGIVSEALIRGSQLGVDKSEEGDSQKDNSGIKKKNVM |
|
NCBI Accession
|
QJX74427.1
|
|
Location
|
NA |
|
Protein Name
|
C1:C2 |
|
Coding Region
|
ATGCAATCAACCAGAGTATTTGCTTATCCCAATTGCCCACTACAAATCCCTACTGTCAACATGTCGAACACTCCTCCCACATCATTCCGATTCAAAGCCAAAAACATTTTCTTAACATACCCAAACTGCCCACTGCATAAGAATGACGTATCCACACAATTGAAGGTCATTCTCCATCATCACAACATCACCTACATCCTTGTGTGTGAGGAAACTCACGCTTCTGGTGAACCCCATGTCCACGCCATGGTTCAACTTGACAAACAGTTCGAAACAAGGAACTGTCGCTTCTTCGACATCTACATGGGTCCATTACACCCTGTACAAGGGCCAACCGTAAGGTACCATCCAAATATTGAACCACTACACTCTCCCACTGCTAGTCAAAAATACCTGAAAAAATCAGGTAATTTTTATGAGGATGGGGTTTTCAACAACAAGAAGAGATCCCCATCCAAAAATCCCAACGCCATTTGGAAAGACATTCTGGACACAGCCTCCGACATAAACGACTTTCTGGCAAAAGTCAAGGACCAACGACCACAGGACTTCGTCCTTCGTTGGCCAGCCATATCATCCTTTGCCAACGACCACTACAAACGTGTCGTTGAGCCATTCATGCCGGTTTTCACAGAATTTCAAAACCTCCCTCAACACATACAGCAATGGGCAAACGACAACATCCTTTTCGACCCCGAGAACAAGCCCAACAGGCCAATCTCCCTCTACATCTGCGGACCGAGCAGATCAGGCAAGACATGCTGGGCCAGATCATTGGGCCTACACAACTACTTCACGGGCCAGTTAAAATTCCACGATTACAATGACTATGCATTATACAATGTAATAGACGACATTCACTATACTAGAATCTCGTCTGAAATAATGAAATCATTAGTAGGTTGTCAACATAATGTAACGGTTAATATTAAATATAAACCAGATCGTACTATCAAAGGGGGGATACCCACCATTATTCTCTGTAATCCTGATATGGACTGGCTCTCAACCATGTCCACGGAAATTAAGACATGGTGGCACAAGAATGTAATCACTTATTATATGAATGAAAGTGACACTTTCTTTTAA |
|
Protein Sequence
|
MQSTRVFAYPNCPLQIPTVNMSNTPPTSFRFKAKNIFLTYPNCPLHKNDVSTQLKVILHHHNITYILVCEETHASGEPHVHAMVQLDKQFETRNCRFFDIYMGPLHPVQGPTVRYHPNIEPLHSPTASQKYLKKSGNFYEDGVFNNKKRSPSKNPNAIWKDILDTASDINDFLAKVKDQRPQDFVLRWPAISSFANDHYKRVVEPFMPVFTEFQNLPQHIQQWANDNILFDPENKPNRPISLYICGPSRSGKTCWARSLGLHNYFTGQLKFHDYNDYALYNVIDDIHYTRISSEIMKSLVGCQHNVTVNIKYKPDRTIKGGIPTIILCNPDMDWLSTMSTEIKTWWHKNVITYYMNESDTFF |
|
NCBI Accession
|
QJX74426.1
|
|
Location
|
2792-3718 |
|
Protein Name
|
C1 |
|
Coding Region
|
ATGCAATCAACCAGAGTATTTGCTTATCCCAATTGCCCACTACAAATCCCTACTGTCAACATGTCGAACACTCCTCCCACATCATTCCGATTCAAAGCCAAAAACATTTTCTTAACATACCCAAACTGCCCACTGCATAAGAATGACGTATCCACACAATTGAAGGTCATTCTCCATCATCACAACATCACCTACATCCTTGTGTGTGAGGAAACTCACGCTTCTGGTGAACCCCATGTCCACGCCATGGTTCAACTTGACAAACAGTTCGAAACAAGGAACTGTCGCTTCTTCGACATCTACATGGGTCCATTACACCCTGTACAAGGGCCAACCGTAAGGTACCATCCAAATATTGAACCACTACACTCTCCCACTGCTAGTCAAAAATACCTGAAAAAATCAGGTAATTTTTATGAGGATGGGGTTTTCAACAACAAGAAGAGATCCCCATCCAAAAATCCCAACGCCATTTGGAAAGACATTCTGGACACAGCCTCCGACATAAACGACTTTCTGGCAAAAGTCAAGGACCAACGACCACAGGACTTCGTCCTTCGTTGGCCAGCCATATCATCCTTTGCCAACGACCACTACAAACGTGTCGTTGAGCCATTCATGCCGGTTTTCACAGAATTTCAAAACCTCCCTCAACACATACAGCAATGGGCAAACGACAACATCCTTTTCGTAAGTAAACCCTTCATTCATTATGATTTGTGCTTCAATTGCTCAACTAAGGCTCGGTTCGAGTCTGAAAACACCATTTCACTCCTACACCACTACTACTGCGATGCCGCTGATTGCAGGACCCCGAGAACAAGCCCAACAGGCCAATCTCCCTCTACATCTGCGGACCGAGCAGATCAGGCAAGACATGCTGGGCCAGATCATTGGGCCTACACAACTACTTCACGGGCCAGTTAA |
|
Protein Sequence
|
MQSTRVFAYPNCPLQIPTVNMSNTPPTSFRFKAKNIFLTYPNCPLHKNDVSTQLKVILHHHNITYILVCEETHASGEPHVHAMVQLDKQFETRNCRFFDIYMGPLHPVQGPTVRYHPNIEPLHSPTASQKYLKKSGNFYEDGVFNNKKRSPSKNPNAIWKDILDTASDINDFLAKVKDQRPQDFVLRWPAISSFANDHYKRVVEPFMPVFTEFQNLPQHIQQWANDNILFVSKPFIHYDLCFNCSTKARFESENTISLLHHYYCDAADCRTPRTSPTGQSPSTSADRADQARHAGPDHWAYTTTSRAS |