Plantago lanceolata latent virus
Basic Information
| Genus | Capulavirus |
|---|---|
| NCBI Assembly | GCF_002824765.1 |
| Isolate | Finland: Aland archipelago |
| Release date | 2018/8/25 |
| Submitter | Bernardo,P., Muhire,B., Francois,S., Deshoux,M., Hartnady,P., Farkas,K., Kraberger,S., Filloux,D., Fernandez,E., Galzi,S., Ferdinand,R., Granier,M., Marais,A., Monge Blasco,P., Candresse,T., Escriu,F., Varsani,A., Harkins,G.W., Martin,D.P., Roumagnac,P., Frilander,M.J., Monge,P., Peterschmitt,M., Laine,A.L. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
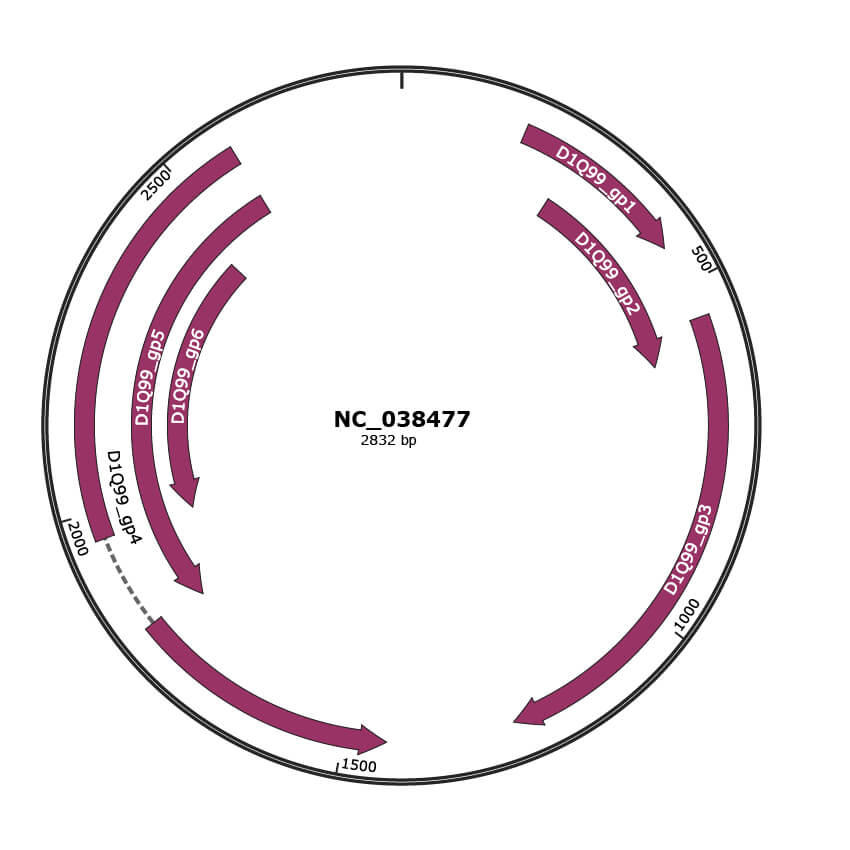
JBrowse
Genome
NC_038477
TAATATTACTGAAGTCCGCTGTGGGCCCCACCTTATCGTATTGGTCAAAAATGATGGGCCCTGCGAATCTGTTTTTTGAGTGACGTGTTTAATATGTCACGTATTTGGGACAGTATTTATACAATGATCTGCAGTATCTGTGATATTTGTATACAAATTTCTGACAGAAGCTAGTATTGTATGGAATACTGTTCCGAAGTACTCTTCTGGACGTATTTTTTGATAATTACTATTTATTTTGCATTGATATTATATTTCAATGGCAAAACGCTTCTACTTGGTCGACGAATTACCGAGCAGTTACGGGAAGTTAATTGCTATTGCCGGGAGGCAATGGCTTCAAGACCAGGAGAAGCGCGCGTTGGAGAATTCACTAATTCGGCAGGCCGACTTGTACCGTCAAGTTCGTGTAGGCTTTCAAAAATCCCAGAAGAGGGGTGAGCGTTGGAGCGTTAAAGTAGCGCGGTTTGAAGAAATTCTTCAAGCGGCTATAAATACGTCACGTTTGGGGCGTATTGAGTACGAGATCGAATCGCGAATTGTTAAGGACAATGGTGAAGCGAAAGAGGAGTACTGGTGTGACTACGACTTATGCGAAGCGGAGTAGGGTTGGCAGTGGTTATAGGCGACGTTGGAGTAGACGTCGTCGTATTGTTAGGCGTAAAGGTGTTTATGCAAGGCACAGATCTCAGTCTGTGTTACATTCCCTGTCTAATGCGACAGCAACGAAGGGAAAGGCTGGTTATGGATGGCATTTGAACGAGATACCTTTGGGTTCTTCTTACCCCGAGCGACATAGTGATAAAGTGAAGGTGAAGTCATTTAGGTTCCGTATGCAATTTAGAGATGGTGCTAACGGAGGAACCAATGCTGCAAATGTTCATAACCTATATCTTTATCTTGTGAAAGATAATAGTGGGGGTACCGAAGTTCCGTCATTCGATAAGATAGCAATGATGGACTACGGTAATGTTGCAACTGCAATTATCGACCACGATTCAGAGAAGAGATTCACTATTGTTAGGCAATGGAAGTATACTTTTACCGGGTCTTGTAATTCGCAATATCCCGGTAAAGATAGGATTGATTTTAACGACGTTGTTTACATTAATGTAGATACGGAGTTTAAGTCTGCGACAGATGGTAAGTATGCAAATACCCAAAAGAATGCTTGGGTTTTGTATATTATACCGCAGAGTTATGACTGTGTAATTGACGGACATGTTAATGTTCGTTTTGAATCGTTGGTGTAACTAAATATTTGTGAAATAAAAAGTTTATCTTTGGTGTATTTAACAAATATTTTGTTTTTGGGGGGTTAAAGTGTAAAAAAATTGTACTTGGTGTTGCCATTTGTAAAAAAATTGAAGGAAAAAAATGTTGCCCCGTGTATACAATAGAATAATTGGAGCCCGCGTGAGCGGGTGGAAGAACTTTTCAATAAAAGGGCTGTTGTATTTCTATATGTAATACGTTACATACAGACCATTCGTACATCTCATGTAGCTGTAGTGCAGCTCTGTACGATTGGTCTGGGTTACATAGTACTATAGTTGGAATTCCTCCGGGCACTTTTGTTTTTTTACGGTATTTTTCATTTACCGTAAAATCTTTTTGTGCTCCGAGGATTTCTTTTTTACATGGTAAAAACTGAAATGGAATATCATCTATTACATTATACATAGCGTGTTTGTCATACGCGCTCCAGTCCACACTTCCGCAGTAGTAATTGTGTCGGCCCAGTGATCTAGCCCATGCTGTTTTACCTGTTTTGGATGGGCCTTCAATGATTAATGTGATGGGCCTATCAGGTCTGTGGTCCTGCATCAGAAACAGTAATGGGCTGTTGTGAGTTCAACAGTAGTTGTTCTTCTAATTCTTCTTGGGCCGTATTTGAGGCCCAATCCAGATCTGCATGTTCAATATCTGGATCAATTAGTTGCATACTGTTGAAACTTACTGTGTAGAGGTTTGTTTCGGCCCATTGTTTAATGGGCTCAGGTAAATTAGGGAAAGCCCTGTATCTGGGTTCATACAGTACAGGGGGTTCTGGCCATCTGGAATTGGCTGCGTACTCCAGGTTGCGTAACTGTGTTGCCCATGTGTAGGGCTGTTCCGACTGGACTCTGGCGAGGAAGTCGGGCTTGGATGTAGACTCCTGGAGTATAGCAGTCCAGATTGTATCCCTAGACTTCTTAGGGCTACGTCTTGTAGCCTTAAGTACGCCTCGTTCGACGAAGTTTCCGTCCTTGGCGATGTAGTCGGCGACGTGGGCGTCGCTTCTGGGTACCTGGATATTGGGGTGGTGTGGTTGAGCATCACCACTGGTAATAGTGTTTGCGGTGGTGATGTCGAAGTATTTTGGGTCTCTGGTGGTGAGTCGCTTTGCGAGTTGGACGAGACAGTGGAGGTGTTTCGTTCCATCCTGATGATTTTCCTGACAAACTCTGGCATAAAAAATATCATAATTTTTTAATAGATTATATAAATAATCTAGTACGGATGTTGGTGTTAAATCGCATTTTGGGTAAGTTAGGAAAGCCGACTTACCCTGAAATCGGTATGTTAGTGGTTGACGTGGCATATTTCTAGAGAGAGAAATATTGTAGGGGTATTTTGGGTGGAAAAAAAAATAGGCTGAAAATGGTGTTTCCAGAGGGTTTTCAGACTAGTTTCGTGTTTAACAATGAAGTGAGCCGCGTAGCCAATTTATAGTAGTGAGCCAATGAGGCGAATTTAGCGAGAATTTGGAATCCGTAAATCTGGGCCGTTGATTGGATGTGTGGATGGATTAGTGCCACGTGGCGGGTACTGTGGGCGGCGGACTTCATA
Gene Information
| NCBI Accession | YP_009506569.1 |
|---|---|
| Location | 181-441 |
| Protein Name | V4 |
| Coding Region | ATGGAATACTGTTCCGAAGTACTCTTCTGGACGTATTTTTTGATAATTACTATTTATTTTGCATTGATATTATATTTCAATGGCAAAACGCTTCTACTTGGTCGACGAATTACCGAGCAGTTACGGGAAGTTAATTGCTATTGCCGGGAGGCAATGGCTTCAAGACCAGGAGAAGCGCGCGTTGGAGAATTCACTAATTCGGCAGGCCGACTTGTACCGTCAAGTTCGTGTAGGCTTTCAAAAATCCCAGAAGAGGGGTGA |
| Protein Sequence | MEYCSEVLFWTYFLIITIYFALILYFNGKTLLLGRRITEQLREVNCYCREAMASRPGEARVGEFTNSAGRLVPSSSCRLSKIPEEG |
| NCBI Accession | YP_009506570.1 |
|---|---|
| Location | 260-607 |
| Protein Name | V3 |
| Coding Region | ATGGCAAAACGCTTCTACTTGGTCGACGAATTACCGAGCAGTTACGGGAAGTTAATTGCTATTGCCGGGAGGCAATGGCTTCAAGACCAGGAGAAGCGCGCGTTGGAGAATTCACTAATTCGGCAGGCCGACTTGTACCGTCAAGTTCGTGTAGGCTTTCAAAAATCCCAGAAGAGGGGTGAGCGTTGGAGCGTTAAAGTAGCGCGGTTTGAAGAAATTCTTCAAGCGGCTATAAATACGTCACGTTTGGGGCGTATTGAGTACGAGATCGAATCGCGAATTGTTAAGGACAATGGTGAAGCGAAAGAGGAGTACTGGTGTGACTACGACTTATGCGAAGCGGAGTAG |
| Protein Sequence | MAKRFYLVDELPSSYGKLIAIAGRQWLQDQEKRALENSLIRQADLYRQVRVGFQKSQKRGERWSVKVARFEEILQAAINTSRLGRIEYEIESRIVKDNGEAKEEYWCDYDLCEAE |
| NCBI Accession | YP_009506571.1 |
|---|---|
| Location | 552-1253 |
| Protein Name | coat protein |
| Coding Region | ATGGTGAAGCGAAAGAGGAGTACTGGTGTGACTACGACTTATGCGAAGCGGAGTAGGGTTGGCAGTGGTTATAGGCGACGTTGGAGTAGACGTCGTCGTATTGTTAGGCGTAAAGGTGTTTATGCAAGGCACAGATCTCAGTCTGTGTTACATTCCCTGTCTAATGCGACAGCAACGAAGGGAAAGGCTGGTTATGGATGGCATTTGAACGAGATACCTTTGGGTTCTTCTTACCCCGAGCGACATAGTGATAAAGTGAAGGTGAAGTCATTTAGGTTCCGTATGCAATTTAGAGATGGTGCTAACGGAGGAACCAATGCTGCAAATGTTCATAACCTATATCTTTATCTTGTGAAAGATAATAGTGGGGGTACCGAAGTTCCGTCATTCGATAAGATAGCAATGATGGACTACGGTAATGTTGCAACTGCAATTATCGACCACGATTCAGAGAAGAGATTCACTATTGTTAGGCAATGGAAGTATACTTTTACCGGGTCTTGTAATTCGCAATATCCCGGTAAAGATAGGATTGATTTTAACGACGTTGTTTACATTAATGTAGATACGGAGTTTAAGTCTGCGACAGATGGTAAGTATGCAAATACCCAAAAGAATGCTTGGGTTTTGTATATTATACCGCAGAGTTATGACTGTGTAATTGACGGACATGTTAATGTTCGTTTTGAATCGTTGGTGTAA |
| Protein Sequence | MVKRKRSTGVTTTYAKRSRVGSGYRRRWSRRRRIVRRKGVYARHRSQSVLHSLSNATATKGKAGYGWHLNEIPLGSSYPERHSDKVKVKSFRFRMQFRDGANGGTNAANVHNLYLYLVKDNSGGTEVPSFDKIAMMDYGNVATAIIDHDSEKRFTIVRQWKYTFTGSCNSQYPGKDRIDFNDVVYINVDTEFKSATDGKYANTQKNAWVLYIIPQSYDCVIDGHVNVRFESLV |
| NCBI Accession | YP_009506572.1 |
|---|---|
| Location | 1438-1821,1961-2584 |
| Protein Name | replication-associated protein |
| Coding Region | ATGCCACGTCAACCACTAACATACCGATTTCAGGGTAAGTCGGCTTTCCTAACTTACCCAAAATGCGATTTAACACCAACATCCGTACTAGATTATTTATATAATCTATTAAAAAATTATGATATTTTTTATGCCAGAGTTTGTCAGGAAAATCATCAGGATGGAACGAAACACCTCCACTGTCTCGTCCAACTCGCAAAGCGACTCACCACCAGAGACCCAAAATACTTCGACATCACCACCGCAAACACTATTACCAGTGGTGATGCTCAACCACACCACCCCAATATCCAGGTACCCAGAAGCGACGCCCACGTCGCCGACTACATCGCCAAGGACGGAAACTTCGTCGAACGAGGCGTACTTAAGGCTACAAGACGTAGCCCTAAGAAGTCTAGGGATACAATCTGGACTGCTATACTCCAGGAGTCTACATCCAAGCCCGACTTCCTCGCCAGAGTCCAGTCGGAACAGCCCTACACATGGGCAACACAGTTACGCAACCTGGAGTACGCAGCCAATTCCAGATGGCCAGAACCCCCTGTACTGTATGAACCCAGATACAGGGCTTTCCCTAATTTACCTGAGCCCATTAAACAATGGGCCGAAACAAACCTCTACACAGACCACAGACCTGATAGGCCCATCACATTAATCATTGAAGGCCCATCCAAAACAGGTAAAACAGCATGGGCTAGATCACTGGGCCGACACAATTACTACTGCGGAAGTGTGGACTGGAGCGCGTATGACAAACACGCTATGTATAATGTAATAGATGATATTCCATTTCAGTTTTTACCATGTAAAAAAGAAATCCTCGGAGCACAAAAAGATTTTACGGTAAATGAAAAATACCGTAAAAAAACAAAAGTGCCCGGAGGAATTCCAACTATAGTACTATGTAACCCAGACCAATCGTACAGAGCTGCACTACAGCTACATGAGATGTACGAATGGTCTGTATGTAACGTATTACATATAGAAATACAACAGCCCTTTTATTGA |
| Protein Sequence | MPRQPLTYRFQGKSAFLTYPKCDLTPTSVLDYLYNLLKNYDIFYARVCQENHQDGTKHLHCLVQLAKRLTTRDPKYFDITTANTITSGDAQPHHPNIQVPRSDAHVADYIAKDGNFVERGVLKATRRSPKKSRDTIWTAILQESTSKPDFLARVQSEQPYTWATQLRNLEYAANSRWPEPPVLYEPRYRAFPNLPEPIKQWAETNLYTDHRPDRPITLIIEGPSKTGKTAWARSLGRHNYYCGSVDWSAYDKHAMYNVIDDIPFQFLPCKKEILGAQKDFTVNEKYRKKTKVPGGIPTIVLCNPDQSYRAALQLHEMYEWSVCNVLHIEIQQPFY |
| NCBI Accession | YP_009506573.1 |
|---|---|
| Location | 1808-2584 |
| Protein Name | RepA |
| Coding Region | ATGCCACGTCAACCACTAACATACCGATTTCAGGGTAAGTCGGCTTTCCTAACTTACCCAAAATGCGATTTAACACCAACATCCGTACTAGATTATTTATATAATCTATTAAAAAATTATGATATTTTTTATGCCAGAGTTTGTCAGGAAAATCATCAGGATGGAACGAAACACCTCCACTGTCTCGTCCAACTCGCAAAGCGACTCACCACCAGAGACCCAAAATACTTCGACATCACCACCGCAAACACTATTACCAGTGGTGATGCTCAACCACACCACCCCAATATCCAGGTACCCAGAAGCGACGCCCACGTCGCCGACTACATCGCCAAGGACGGAAACTTCGTCGAACGAGGCGTACTTAAGGCTACAAGACGTAGCCCTAAGAAGTCTAGGGATACAATCTGGACTGCTATACTCCAGGAGTCTACATCCAAGCCCGACTTCCTCGCCAGAGTCCAGTCGGAACAGCCCTACACATGGGCAACACAGTTACGCAACCTGGAGTACGCAGCCAATTCCAGATGGCCAGAACCCCCTGTACTGTATGAACCCAGATACAGGGCTTTCCCTAATTTACCTGAGCCCATTAAACAATGGGCCGAAACAAACCTCTACACAGTAAGTTTCAACAGTATGCAACTAATTGATCCAGATATTGAACATGCAGATCTGGATTGGGCCTCAAATACGGCCCAAGAAGAATTAGAAGAACAACTACTGTTGAACTCACAACAGCCCATTACTGTTTCTGATGCAGGACCACAGACCTGA |
| Protein Sequence | MPRQPLTYRFQGKSAFLTYPKCDLTPTSVLDYLYNLLKNYDIFYARVCQENHQDGTKHLHCLVQLAKRLTTRDPKYFDITTANTITSGDAQPHHPNIQVPRSDAHVADYIAKDGNFVERGVLKATRRSPKKSRDTIWTAILQESTSKPDFLARVQSEQPYTWATQLRNLEYAANSRWPEPPVLYEPRYRAFPNLPEPIKQWAETNLYTVSFNSMQLIDPDIEHADLDWASNTAQEELEEQLLLNSQQPITVSDAGPQT |
| NCBI Accession | YP_009506574.1 |
|---|---|
| Location | 1957-2466 |
| Protein Name | C3 |
| Coding Region | ATGATATTTTTTATGCCAGAGTTTGTCAGGAAAATCATCAGGATGGAACGAAACACCTCCACTGTCTCGTCCAACTCGCAAAGCGACTCACCACCAGAGACCCAAAATACTTCGACATCACCACCGCAAACACTATTACCAGTGGTGATGCTCAACCACACCACCCCAATATCCAGGTACCCAGAAGCGACGCCCACGTCGCCGACTACATCGCCAAGGACGGAAACTTCGTCGAACGAGGCGTACTTAAGGCTACAAGACGTAGCCCTAAGAAGTCTAGGGATACAATCTGGACTGCTATACTCCAGGAGTCTACATCCAAGCCCGACTTCCTCGCCAGAGTCCAGTCGGAACAGCCCTACACATGGGCAACACAGTTACGCAACCTGGAGTACGCAGCCAATTCCAGATGGCCAGAACCCCCTGTACTGTATGAACCCAGATACAGGGCTTTCCCTAATTTACCTGAGCCCATTAAACAATGGGCCGAAACAAACCTCTACACAGTAA |
| Protein Sequence | MIFFMPEFVRKIIRMERNTSTVSSNSQSDSPPETQNTSTSPPQTLLPVVMLNHTTPISRYPEATPTSPTTSPRTETSSNEAYLRLQDVALRSLGIQSGLLYSRSLHPSPTSSPESSRNSPTHGQHSYATWSTQPIPDGQNPLYCMNPDTGLSLIYLSPLNNGPKQTSTQ |