French bean severe leaf curl virus
Basic Information
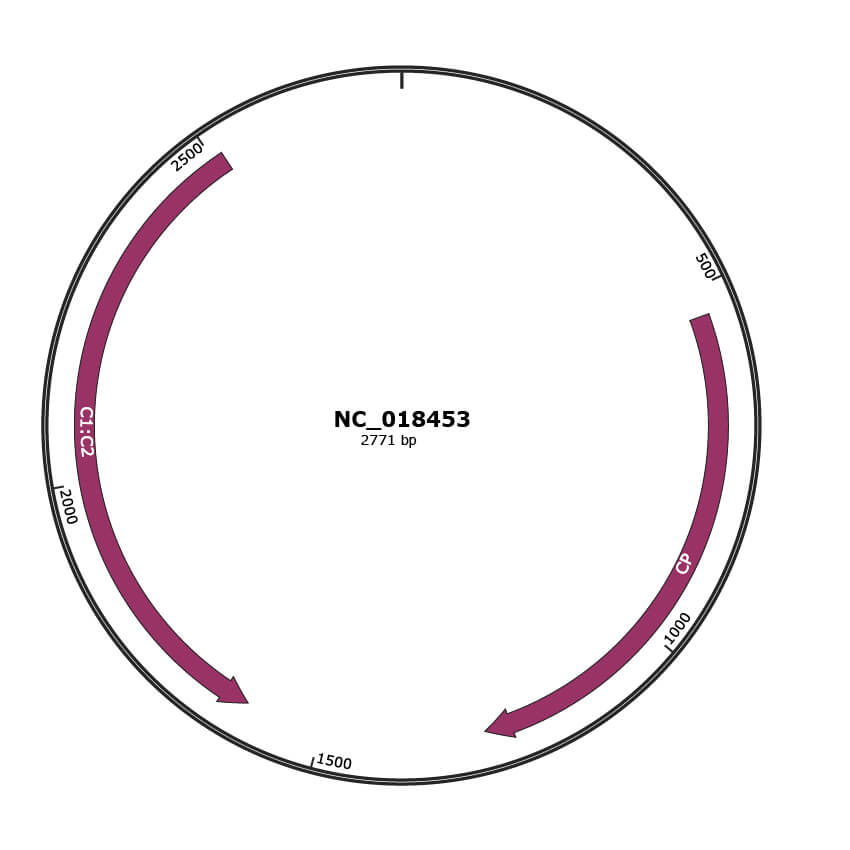
Genomic Organization
JBrowse
Genome
ACGGTTGCGCGTGTGGGCCCCACAGCCTTATCGTGGGGCCCACGTTTTGGCTTTTAGTCGAAGCGTAAGCAAGACGTCATGTCGGCCCCACAGCAATATAAAAGGAACCACAGTTGAGGATCTGAATGTTCTCGTAGAGGTCATTGGGACAACGTGTGGTGTATGGAATATTGCTCAGAATTTATATTCTGGTGGGAAGCCGCTGTTATTGTAATTGTTTTAGGTTTATTGATTTATATCAATGGAAAGTCGCTTATACTTAATCGAGGAATTGCCAGAGACGTACGGTCGTTTACAGGGATTTTGCACAGACTTATTCCTGGGCCGGATGATACAGAAGGCCCAAGACGAAGGACTTACGGGAGAAGTAACTCGTTACAGACTACTCAGACAGTGTTACCGCCAATCCCAGAGACGGAAAGAGAAATGGGCCATCAAAGTGGCCCAATTCAATGAAGACCTTGCCACTATTATAAATAGGGGTAGATGGGCCTCTGAAGAGGCCCAGAAACTCCTAGCGTACAAAAAAAAAATAGAAGATGGCTCGCACAAGATCGGGGAGACAGTATTCGGCCCAGGCCCCATCTTGGGGCCGGAAGAAGACAAGAACACCCCGTTCGAGACCTACACTGATTGGGCCGATTCGAAGGCCCAATTACCAAATCAAGACCCGCTATGCCCCCCACAGACCTCAGACTAAGATACACTCCTTGTCTGCGGCAAGGGTTGTATCTGGGTCGGATAATGGTTATGGATGGCACATCTCGGACGTTCCTATTGGATCGGGCTTTGAAGATAGGCATAGTGATAAAATTAGAATTTTAAATTTTAATTTTAAGTTACAGATGAGGACTTCTCAACAGGGACAGAACACGTCATGCTGGCATAACGTGTATTTGTTTTTAGTTAGAGACAATAGTGGAGGAACAGCTGTTCCGAAATTTAATTCAATATGTATGATGGATAATTCCAACCCTTCCACTGCTGAGATTGACCATGATTCGAAGGATCGTTTCACGATTATGAGAAGATGGAGATTCCAGTTCAAAGGAAACAGCACATCTGGATCCGTTGCTTATGACTGTGCTAGGAATACTTATGATTTTAGGAAATTTGTTAAATTAAGTTCAATTACTGAATTTAAGAGTGCTACAAGTGGATCTTATGCTAATACGCAAAAGAACGCTTGGGTATTGTATTTTGTTCCTCAGACGTACGATATGACTGTTGACGGTCATTGTACGATCAAATATGTATCAATTGTGTAATCAATTAATAAAAAATAATTGAATTATGATATCGCTATCAATCATCACACGCTATAATACCAGATAATCAGAAAAACGATACGATAATAGTAATATAATCAAAGTCGAAGACTTTTAATTAATTAAAAGAAAGGATCTTTTATTTCCACATGAATTACATTGGATAAGGACCATTCGTACATTTCACTGCCCATTAATGCAGCTTTGTATGATTGATCTGGATTACACAGTACAATGGTTGGAATTCTACATTTTTTTCTATATTTTTCGTTGACTGTAAAATCCTTTTGACATCCTAGTAATTCTTTTTTACATGGAAGAAATTGAAAAGGAATATCATCTATGACGGTGTAAGTAGCAAAATTATTCCACACACTAAAATCAACACCCCCACAAAAATAATTATGTAGACCCATGCTCCTGGCCCATGCTGTTTTGCCTGTTTTTGTTGGGCCAAACAATTATTAGAGTCACTGGGCGGTCCGGTCTCTGATCCTGAAAATGATTGTACAACAGGATCTTCAGAATTACCAATCCATTCATCAGTAATAAAGTCTTCTGTTAAATTATGAGCCCATTGCATATCTGTTACTGATATTTCTGGTTGAACTAATTGCATGGATTGAAGACTTACTGTGAATAAGTTGGTGTCTGCCCATTCTCTAATGGGCTCGGGTACATTATTGAACACTGTCCATTTGGGAATGTACACACTAGGTTGCTCTGGCCACTTACTATTTGCTGCATATTCGAGATTTCGTAATTGAGTTGCCCAGACATATGGTTGCTCAATCTGGACTCTACCGAGAAACTCGGACTTGGAGGTGGATTCATTGATGATGTTTGTCCATATTGAATCCCTGCTCTTCTTAGGGCTTCTTCTACTTGCCCTAAGTATTCCTCGTTCCTCAAATTGTCCTCCCTTGGCAATATAGTCTGCCACATCAGCATCTCTTCTTGGGACCTGGCAATTGGGGTGGTAAACCCCAGTTCTGTTTGGGTCTGAGATGTCAAAATATCTCTGTGATGTGGTGTTGAACCTCTTGTCCAGTTGGACAAGACAGTGAAGGTGTGGCTCACCGTCCTGGTGATTCTCCGTACAGACCCTAGCATATATAGGATTAAAATTCTTTAATAATTGATATAAGTAATCAATTACGAAAAGTGGAGTTAAGGGGCATTTTGGGTAAGTCAAAAAAATAGACTTACCCTGGAGACGGAAGGAGTTGTTGTTGCGTCGAGGCATGATGCGTATAAAAATAATGGTAATAGAAGGGAGCTCAAGATTCGATTTGGCAATTCTTTATTCTACAAGGTTTTGCGTGAGAAGTGAGCTCCCTCCTGTTGCGTTATATAATACAAATGGACGGCTGTGATTTATCCACGTGTCTTTCATCTTGCGAGCCGACAAAAGTGAGTGGGTACTTTTACTTTATTAAATAAAGTTGTTTGAATGCGGACCGAAGGTCCGTAGTGCGGTTCTCACGCGCAACCTTTAATATT
Gene Information
|
NCBI Accession
|
YP_006590004.1
|
|
Location
|
540-1268 |
|
Gene Name
|
CP |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGGCTCGCACAAGATCGGGGAGACAGTATTCGGCCCAGGCCCCATCTTGGGGCCGGAAGAAGACAAGAACACCCCGTTCGAGACCTACACTGATTGGGCCGATTCGAAGGCCCAATTACCAAATCAAGACCCGCTATGCCCCCCACAGACCTCAGACTAAGATACACTCCTTGTCTGCGGCAAGGGTTGTATCTGGGTCGGATAATGGTTATGGATGGCACATCTCGGACGTTCCTATTGGATCGGGCTTTGAAGATAGGCATAGTGATAAAATTAGAATTTTAAATTTTAATTTTAAGTTACAGATGAGGACTTCTCAACAGGGACAGAACACGTCATGCTGGCATAACGTGTATTTGTTTTTAGTTAGAGACAATAGTGGAGGAACAGCTGTTCCGAAATTTAATTCAATATGTATGATGGATAATTCCAACCCTTCCACTGCTGAGATTGACCATGATTCGAAGGATCGTTTCACGATTATGAGAAGATGGAGATTCCAGTTCAAAGGAAACAGCACATCTGGATCCGTTGCTTATGACTGTGCTAGGAATACTTATGATTTTAGGAAATTTGTTAAATTAAGTTCAATTACTGAATTTAAGAGTGCTACAAGTGGATCTTATGCTAATACGCAAAAGAACGCTTGGGTATTGTATTTTGTTCCTCAGACGTACGATATGACTGTTGACGGTCATTGTACGATCAAATATGTATCAATTGTGTAA |
|
Protein Sequence
|
MARTRSGRQYSAQAPSWGRKKTRTPRSRPTLIGPIRRPNYQIKTRYAPHRPQTKIHSLSAARVVSGSDNGYGWHISDVPIGSGFEDRHSDKIRILNFNFKLQMRTSQQGQNTSCWHNVYLFLVRDNSGGTAVPKFNSICMMDNSNPSTAEIDHDSKDRFTIMRRWRFQFKGNSTSGSVAYDCARNTYDFRKFVKLSSITEFKSATSGSYANTQKNAWVLYFVPQTYDMTVDGHCTIKYVSIV |
|
NCBI Accession
|
YP_006590005.1
|
|
Location
|
1609-2514 |
|
Gene Name
|
C1:C2 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGCCTCGACGCAACAACAACTCCTTCCGTCTCCAGGGTAAGTCTATTTTTTTGACTTACCCAAAATGCCCCTTAACTCCACTTTTCGTAATTGATTACTTATATCAATTATTAAAGAATTTTAATCCTATATATGCTAGGGTCTGTACGGAGAATCACCAGGACGGTGAGCCACACCTTCACTGTCTTGTCCAACTGGACAAGAGGTTCAACACCACATCACAGAGATATTTTGACATCTCAGACCCAAACAGAACTGGGGTTTACCACCCCAATTGCCAGGTCCCAAGAAGAGATGCTGATGTGGCAGACTATATTGCCAAGGGAGGACAATTTGAGGAACGAGGAATACTTAGGGCAAGTAGAAGAAGCCCTAAGAAGAGCAGGGATTCAATATGGACAAACATCATCAATGAATCCACCTCCAAGTCCGAGTTTCTCGGTAGAGTCCAGATTGAGCAACCATATGTCTGGGCAACTCAATTACGAAATCTCGAATATGCAGCAAATAGTAAGTGGCCAGAGCAACCTAGTGTGTACATTCCCAAATGGACAGTGTTCAATAATGTACCCGAGCCCATTAGAGAATGGGCAGACACCAACTTATTCACAGTAAGTCTTCAATCCATGCAATTAGTTCAACCAGAAATATCAGTAACAGATATGCAATGGGCTCATAATTTAACAGAAGACTTTATTACTGATGAATGGATTGGTAATTCTGAAGATCCTGTTGTACAATCATTTTCAGGATCAGAGACCGGACCGCCCAGTGACTCTAATAATTGTTTGGCCCAACAAAAACAGGCAAAACAGCATGGGCCAGGAGCATGGGTCTACATAATTATTTTTGTGGGGGTGTTGATTTTAGTGTGTGGAATAATTTTGCTACTTACACCGTCATAG |
|
Protein Sequence
|
MPRRNNNSFRLQGKSIFLTYPKCPLTPLFVIDYLYQLLKNFNPIYARVCTENHQDGEPHLHCLVQLDKRFNTTSQRYFDISDPNRTGVYHPNCQVPRRDADVADYIAKGGQFEERGILRASRRSPKKSRDSIWTNIINESTSKSEFLGRVQIEQPYVWATQLRNLEYAANSKWPEQPSVYIPKWTVFNNVPEPIREWADTNLFTVSLQSMQLVQPEISVTDMQWAHNLTEDFITDEWIGNSEDPVVQSFSGSETGPPSDSNNCLAQQKQAKQHGPGAWVYIIIFVGVLILVCGIILLLTPS |