Centrosema yellow spot virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000896055.1 |
| Isolate |
Brazil |
| Release date |
2015/2/22 |
| Submitter |
Silva,S.J.C., Castillo-Urquiza,G.P., Hora,B.T. Jr., Assuncao,I.P., Lima,G.S.A., Pio-Ribeiro,G., Mizubuti,E.S.G., Zerbini,F.M. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
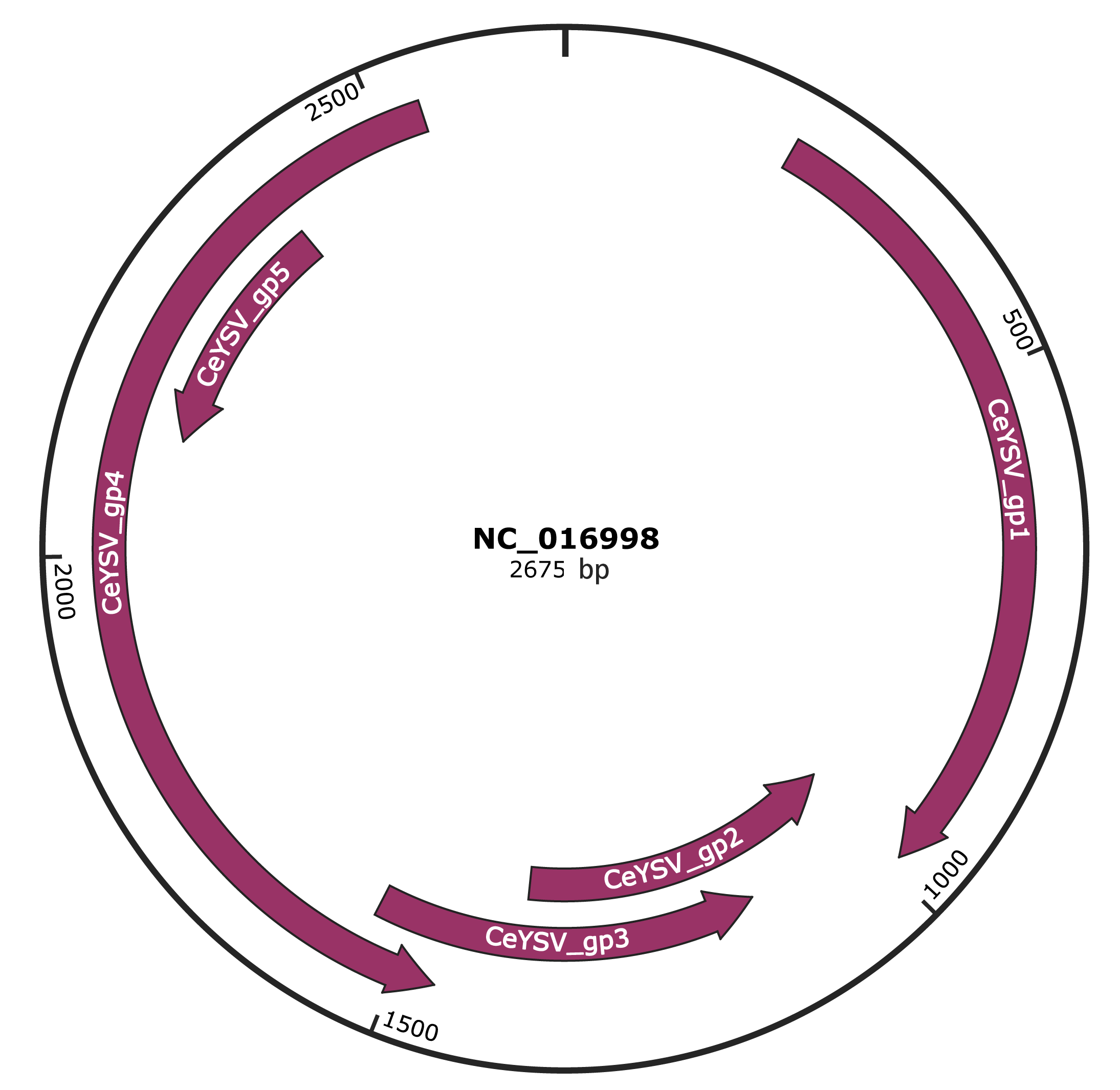
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTGTGGCCCCCCCCCCCGCTCGCGCCAGTTGCGGCGCGTTGTCGGCTTTGCCGTGTGGGTCCACAATCAATGAGGGAGCGTCCTGAAAGCTTGGTTATTTAAAATGACTTGGAGGGTAAGTTAGTAATTTTGTATAAATTAGGACCCCACATAGTGGTCTCGTCAGTGTTTGGGCGAGACTCCCCACACTTTAATTCAGAATGTCTAAGCGGGATGGCTCGTGGCGCTCGATGGCGGGAATCTCCAAGGTTAGCCGCTCTCTCAATTTCTCACCTCGTGGAGGTATTGGGCCTATGGGGCCCAAATATAATAGAGCCTCTGCTTGGGTTAATAGGCCCATGTATAGGAAGCCCAGAATATATAGGATGTATAGATCGCCCGATGTTCCCAAAGGGTGTGAAGGGCCGTGCAAGGTCCAGTCTTATGAACAGCGCCACGATATCGCCCATACTGGGAAGGTGCTGTGCATTTCCGACGTGACTCGTGGTAGCGGTATTACTCACCGTGTCGGTAAGCGCTTCTGTGTGAAGTCCGTGTATATTTTAGGTAAGATATGGATGGATGACAACATCAAGTTGAAGAACCACACCAACAATGTCATGTTCTGGCTGGTTAGAGATCGGAGACCATATGGTACTCCTATGGATTTCGGTCAGGTGTTCAACCTTTATGACAATGAGCCCAGTACCGCCACCGTGAAGAATGATCTCCGCGATCGTTTTCAAGTGATGCACAAGTTCAACGCTACGGTCACGGGTGGTCAGTATGCTGCGAAGGAGCAGGCTTTGGTGAAGCGTTTTTGGAAGGTGAACAACCATGTGACGTATAACCACCAGGAAGCTGCGAAGTACGAGAATCACACTGAGAACGCCCTATTATTGTATATGGCATGTACACATGCCTCTAACCCCGTGTATGCAACCCTTAAGATTCGGATCTATTTTTATGATTCGATTTCTAATTAATAAAGTTTAAATTTTATTGAATGATTTTCGAGTACAGCACTTACATATGATCTGTTTGTTGCGAAGCGAACAGCTCTAATTACATTGTTAATGGAAATAACGCCTAATCTATCTAAATACAATAACACAAAATGTTTAAATCTATTTAAATAAGTCGTCCCAGAAACTGTCTGTGAAGTCGTCCAGACTTGGAAATTGAGGAATGCCTTGTGGAGATCCAACGCTCTCCGCAGGTTGTGGTTGAACCGTATCTGGATGTGGTAGACTCTGGTGTTGGTGTATATGGGGTCTTCTACCCTGGTTATCTTGAAATAGAGGGGATTTGTTATCTCCCAGATATACGCGCCATTCTCTGCCTGAGGCGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGGTTAATCGATAAGCTTGATATCGAATTCCTGCAGTTGATGTGGATGTATACGGTGCACCCGCAGTCGAGGTCTATGCGTCTACGACGAGTTGCCCTGCGCTTGGCTGCTCTGTGTTGTGGTTTGATAGAGGGGGGAGTCGAGGAAGATGAATTTCGCATTATGGAGTGTCCACGCTCTTAGAGATGCATTTTCCTCTTTGTCGAGGAAATATTTATAACTGGCCCCCTCTCCTGGATTACATAGCACAATTGATGGGATACCTCCTTTAATTTGAACTGGCTTCCCGTATTTGCAGTTGCTTTGCCAGTCTTTCTGGGCCCCAATGAGCTCTTTCCAGTGCTTTAGCTTTAGATATTGCGGAGTGACATCATCAATGACGTTATATTCCGCTTCATTTGAATAAACCCTAGAATTGAAATCCAGATGTCCACTCAAATAATTATGTGGGCCCAATGCACGAGCCCACATCGTCTTCCCCGTTCGACTATCACCCTCGACGATGATACTAATAGGTCTCTCCGGCCGCGCAGCGGCACCTCTTCCAAAATAATCATCAGCCCATTCTTGCATATCTTGTGGGACGTTAGTGAATGAGGAGAGTGGAAACGGAGGAACCCATGGATTCGGAGCCTTACTAAATATCCTGTCCAGATTACTGGACAGATTGTGATACTGGAAGAGAAACTTCTCCGGAAGTTTCTCTCGGATTATTTGCATCGCAGCTTGTTTGCTGGGTGCATTTATTGCCTCTGCGGCAGCGTCGTTAGCAGTCTGCTGACCTCCTCTAGCAGATCTGCCGTCGATCTGGAATTCACCCCATTCGAGAGTATCTCCGTCCTTGTCGATGTAGGACTTGACGTCGGACGATGATTTAGCTCCCTGAATGTTTGGATGGAAATGTGCTGACCTGGTTGGGGATACCAAGTCGAACAATCTCTGATTTGTGATCTGTGCTTTGCCTTCGAGTTGGATAAGCACGTGGAGATGAGGTTGCCCATCTTCGTGTAACTCTCGGCAGATTTTGATGTATTTCTTATTTGATGGAAGAGATAGGGTTTGTAATTGGGAAAGTGCTGCTTCTTTCGAAATAGAGCACTGTGGATATGTGAGAAATATATTTTTGGCTTGAAGCCTAAATCTTTTAGGAGCTGATGGCATTTTATGTAAATAAGAGTGTGTACTCTAATTGAGCTCTCTCTCAAAAATGCATATGAATTGGAGTATTGGAGTGCAATATATAGTAGAAGTTCCTAAGGGCTCAGGAACACGTGGCGGCCATCCGTTATAATATT
Gene Information
|
NCBI Accession
|
YP_005352890.1
|
|
Location
|
222-986 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGTCTAAGCGGGATGGCTCGTGGCGCTCGATGGCGGGAATCTCCAAGGTTAGCCGCTCTCTCAATTTCTCACCTCGTGGAGGTATTGGGCCTATGGGGCCCAAATATAATAGAGCCTCTGCTTGGGTTAATAGGCCCATGTATAGGAAGCCCAGAATATATAGGATGTATAGATCGCCCGATGTTCCCAAAGGGTGTGAAGGGCCGTGCAAGGTCCAGTCTTATGAACAGCGCCACGATATCGCCCATACTGGGAAGGTGCTGTGCATTTCCGACGTGACTCGTGGTAGCGGTATTACTCACCGTGTCGGTAAGCGCTTCTGTGTGAAGTCCGTGTATATTTTAGGTAAGATATGGATGGATGACAACATCAAGTTGAAGAACCACACCAACAATGTCATGTTCTGGCTGGTTAGAGATCGGAGACCATATGGTACTCCTATGGATTTCGGTCAGGTGTTCAACCTTTATGACAATGAGCCCAGTACCGCCACCGTGAAGAATGATCTCCGCGATCGTTTTCAAGTGATGCACAAGTTCAACGCTACGGTCACGGGTGGTCAGTATGCTGCGAAGGAGCAGGCTTTGGTGAAGCGTTTTTGGAAGGTGAACAACCATGTGACGTATAACCACCAGGAAGCTGCGAAGTACGAGAATCACACTGAGAACGCCCTATTATTGTATATGGCATGTACACATGCCTCTAACCCCGTGTATGCAACCCTTAAGATTCGGATCTATTTTTATGATTCGATTTCTAATTAA |
|
Protein Sequence
|
MSKRDGSWRSMAGISKVSRSLNFSPRGGIGPMGPKYNRASAWVNRPMYRKPRIYRMYRSPDVPKGCEGPCKVQSYEQRHDIAHTGKVLCISDVTRGSGITHRVGKRFCVKSVYILGKIWMDDNIKLKNHTNNVMFWLVRDRRPYGTPMDFGQVFNLYDNEPSTATVKNDLRDRFQVMHKFNATVTGGQYAAKEQALVKRFWKVNNHVTYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSISN |
|
NCBI Accession
|
YP_005352891.1
|
|
Location
|
983-1381 |
|
Protein Name
|
replication-enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCGCCTCAGGCAGAGAATGGCGCGTATATCTGGGAGATAACAAATCCCCTCTATTTCAAGATAACCAGGGTAGAAGACCCCATATACACCAACACCAGAGTCTACCACATCCAGATACGGTTCAACCACAACCTGCGGAGAGCGTTGGATCTCCACAAGGCATTCCTCAATTTCCAAGTCTGGACGACTTCACAGACAGTTTCTGGGACGACTTATTTAAATAGATTTAAACATTTTGTGTTATTGTATTTAGATAGATTAGGCGTTATTTCCATTAACAATGTAATTAGAGCTGTTCGCTTCGCAACAAACAGATCATATGTAAGTGCTGTACTCGAAAATCATTCAATAAAATTTAAACTTTATTAA |
|
Protein Sequence
|
MDSRTGELITAPQAENGAYIWEITNPLYFKITRVEDPIYTNTRVYHIQIRFNHNLRRALDLHKAFLNFQVWTTSQTVSGTTYLNRFKHFVLLYLDRLGVISINNVIRAVRFATNRSYVSAVLENHSIKFKLY |
|
NCBI Accession
|
YP_005352892.1
|
|
Location
|
1128-1541 |
|
Protein Name
|
transactivating protein |
|
Coding Region
|
ATGCGAAATTCATCTTCCTCGACTCCCCCCTCTATCAAACCACAACACAGAGCAGCCAAGCGCAGGGCAACTCGTCGTAGACGCATAGACCTCGACTGCGGGTGCACCGTATACATCCACATCAACTGCAGGAATTCGATATCAAGCTTATCGATTAACCATGGATTCACGCACAGGGGAACTCATCACTGCGCCTCAGGCAGAGAATGGCGCGTATATCTGGGAGATAACAAATCCCCTCTATTTCAAGATAACCAGGGTAGAAGACCCCATATACACCAACACCAGAGTCTACCACATCCAGATACGGTTCAACCACAACCTGCGGAGAGCGTTGGATCTCCACAAGGCATTCCTCAATTTCCAAGTCTGGACGACTTCACAGACAGTTTCTGGGACGACTTATTTAAATAG |
|
Protein Sequence
|
MRNSSSSTPPSIKPQHRAAKRRATRRRRIDLDCGCTVYIHINCRNSISSLSINHGFTHRGTHHCASGREWRVYLGDNKSPLFQDNQGRRPHIHQHQSLPHPDTVQPQPAESVGSPQGIPQFPSLDDFTDSFWDDLFK |
|
NCBI Accession
|
YP_005352893.1
|
|
Location
|
1462-2541 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCATCAGCTCCTAAAAGATTTAGGCTTCAAGCCAAAAATATATTTCTCACATATCCACAGTGCTCTATTTCGAAAGAAGCAGCACTTTCCCAATTACAAACCCTATCTCTTCCATCAAATAAGAAATACATCAAAATCTGCCGAGAGTTACACGAAGATGGGCAACCTCATCTCCACGTGCTTATCCAACTCGAAGGCAAAGCACAGATCACAAATCAGAGATTGTTCGACTTGGTATCCCCAACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCATCGTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACTCTCGAATGGGGTGAATTCCAGATCGACGGCAGATCTGCTAGAGGAGGTCAGCAGACTGCTAACGACGCTGCCGCAGAGGCAATAAATGCACCCAGCAAACAAGCTGCGATGCAAATAATCCGAGAGAAACTTCCGGAGAAGTTTCTCTTCCAGTATCACAATCTGTCCAGTAATCTGGACAGGATATTTAGTAAGGCTCCGAATCCATGGGTTCCTCCGTTTCCACTCTCCTCATTCACTAACGTCCCACAAGATATGCAAGAATGGGCTGATGATTATTTTGGAAGAGGTGCCGCTGCGCGGCCGGAGAGACCTATTAGTATCATCGTCGAGGGTGATAGTCGAACGGGGAAGACGATGTGGGCTCGTGCATTGGGCCCACATAATTATTTGAGTGGACATCTGGATTTCAATTCTAGGGTTTATTCAAATGAAGCGGAATATAACGTCATTGATGATGTCACTCCGCAATATCTAAAGCTAAAGCACTGGAAAGAGCTCATTGGGGCCCAGAAAGACTGGCAAAGCAACTGCAAATACGGGAAGCCAGTTCAAATTAAAGGAGGTATCCCATCAATTGTGCTATGTAATCCAGGAGAGGGGGCCAGTTATAAATATTTCCTCGACAAAGAGGAAAATGCATCTCTAAGAGCGTGGACACTCCATAATGCGAAATTCATCTTCCTCGACTCCCCCCTCTATCAAACCACAACACAGAGCAGCCAAGCGCAGGGCAACTCGTCGTAG |
|
Protein Sequence
|
MPSAPKRFRLQAKNIFLTYPQCSISKEAALSQLQTLSLPSNKKYIKICRELHEDGQPHLHVLIQLEGKAQITNQRLFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGQQTANDAAAEAINAPSKQAAMQIIREKLPEKFLFQYHNLSSNLDRIFSKAPNPWVPPFPLSSFTNVPQDMQEWADDYFGRGAAARPERPISIIVEGDSRTGKTMWARALGPHNYLSGHLDFNSRVYSNEAEYNVIDDVTPQYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKYFLDKEENASLRAWTLHNAKFIFLDSPLYQTTTQSSQAQGNSS |
|
NCBI Accession
|
YP_005352894.1
|
|
Location
|
2124-2381 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGCAACCTCATCTCCACGTGCTTATCCAACTCGAAGGCAAAGCACAGATCACAAATCAGAGATTGTTCGACTTGGTATCCCCAACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCATCGTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACTCTCGAATGGGGTGAATTCCAGATCGACGGCAGATCTGCTAGAGGAGGTCAGCAGACTGCTAACGACGCTGCCGCAGAGGCAATAA |
|
Protein Sequence
|
MGNLISTCLSNSKAKHRSQIRDCSTWYPQPGQHISIQTFRELNHRPTSSPTSTRTEILSNGVNSRSTADLLEEVSRLLTTLPQRQ |