Catharanthus yellow mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000928135.1 |
| Isolate |
Pakistan:Islamabad |
| Release date |
2015/2/22 |
| Submitter |
Mustujab,A., Tahir,M. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
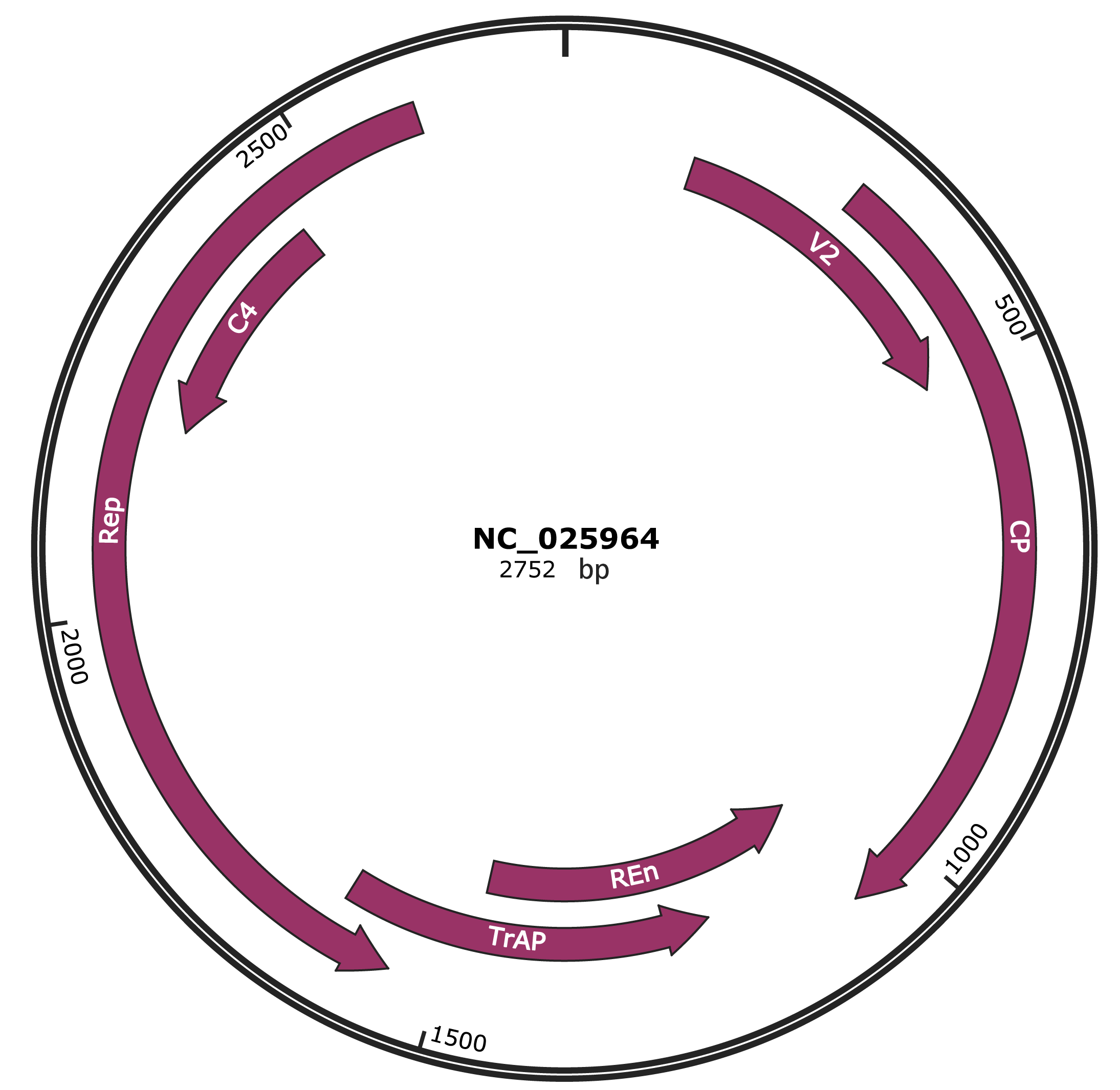
JBrowse
Genome
ACCGGATGGCCGCGATTTTTTTGTGGGCCCCACAAAGCACTAACTGACAAGGACATATGGACCAATGAGAATCGTTCTACATCGCCTCATTGTTTTGTGGTCCCCCTATATAATTACTTGCTGAGTAAGATTGTTGTAAACATGTGGGACCCACTAGTGAACGAGTTTCCMGAAACTGTTCATGGGTTTAGGTGCATGTTGGCAGTGAAATATCTCCAACTAGTTGCAGATACGTATTCTCCAGATACGGTGGGATACGATTTAATACGTGATTTAATTTCAGTAATAAGGGCCAGGAATTATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCCTCGAAGGTACGCCGCCGTCTGAACTTCGACAGCCCATATGCGAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACAAAGGCAAGGGCATGGGCGAACAGGCCCATGAACAGAAAGCCCAGGATGTACAGGATGTACAGAAGTCCAGATGTTCCGAGGGGATGTGAAGGCCCATGCAAGGTCCAGTCATTTGAGTCCAGACATGATATCCAGCACATTGGTAAAGTCATGTGTGTTAGTGATGTTACTCGTGGTATTGGGCTGACCCACAGGGTTGGCAAGAGGTTCTGTGTTAAGTCCGTTTATGTTCTGGGCAAAATCTGGATGGATGAGAACATCAAGACTAAGAATCATACGAATAGTGTCATGTTTTTTCTTGTTAGGGATCGTAGACCCGTTGACAAGCCTCAAGATTTTGGTGAGGTTTTTAACATGTTTGATAATGAGCCCAGCACGGCGACTGTGAAGAATGTTCATCGTGATAGATACCAGGTATTAAGGAAGTGGCACGCAACTGTGACAGGTGGTCTATATGCATCGAAGGAGCAGGCTCTCGTGAAGAAGTTTATTAGGGTTAATAATTATGTTGTGTACAACCAGCAAGAGGCTGGCAAGTATGAGAATCATACTGAGAATGCATTGATGTTGTATATGGCGTGTACGCACGCCTCTAACCCTGTGTATGCTACATTGAAGATACGGATCTATTTTTATGATTCAGTATCGAATTAATAAATATTGAATTTTATATCATGATTCTCAATTACATTAATTGTGCCCTCAAGTACATCATATAATACATGTCTGAAAGCCTTAATACAATTATTTATACTAATTACGCCTAAACTATCTAAATATCGTAAAACTTGAGTCTTAAAGACTCTTAAGAAATGCCCAGTCTGAGGATGTAAACGAGTGTGGATCCTCAGGCCCAAGTAACACTTCATTATCCCCAGTCTCTTCCTGAGGTTGTGATTGAACTGGACCCTGATGTTGATGATGTCGTGGTTCATGTTGAGTGGCCTGCTGTGGTGTTCTGTTATCTTGAAGTAGAGGGGATTTTGAATCTCCCAGATATACACGCCATTCTCTGCTTGAGCTGCAGTGATGGATTCCCCTGTGCGTGAATCCATGGTTGTGGCAGTTGATGTGTACGTAGTATGAGCACCCACAGTTTAGATCAACCCTCTTACGCCGGATGGCTCTACGCTTAGCAGCTCTGTGTTGGACCTTGATTGGAACCTGAGTATAGTGGGCCTTCGAGGGAGATGAAGGTTGCATTTTTTAGTGCCCAGGCTTTCAATGCGCTATTCTTCTCCTCGTCCAGGTACTCCTTATAGCTGGAATTGGGCCCAGGATTGCAGAGGAAGATAGTGGGAATACCACCTTTAATTTGAACTGGCTTCCCGTACTTTGTATTTGATTGCCAGTCCCTTTGGGCCCCCATGAACTCTTTAAAGTGCTTTAGGTAGTGGGGATCAACGTCATCAATGACGTTGTACCAGGCCTCATTATTGTAGACCTTTGGGCTAAGGTCTAGATGCCCACACAGATAATTATGTGGTCCAAGTGATCTGGCCCACATCGTCTTTCCCGTTCTACTGTCACCCTCTATGACTATACTTATGGGTCTCAAAGGCCGCGCAGCGGCACTGACAACATTCTCGGCAGCCCACTCCTCAAGTTCTTCGGGAACTTGATCAAAGGAAGAAGACGAAAAAGGAGAAACATAAACCTCTACAGGAGGTGTAAAAATCCTATCTAAATTACATTTTAAATTATGATATTGAAAAATAAAATCTTTAGGGAGTTTTTCCCTAATTATTGCTAAAGCTGCGTCAGCAGAACCGGCATTTAACGCCTCTGCTGCAACATCATTAGCTGTCTGTTGACCTCCTCGAGCAGATCTTCCATCGATCTGAAACTCACCCCAGTCGATGTAATCACCGTCCTTCTCGATGTAGGACTTGACATCAGAGCTGGACTTAGCTCCCTGGAAGTTTGGGTGGAATTGAGTTGAGGTATAGGGGTGAGTGACATCAAAATGTCTGGGGTTTCTGAACTGGGATTTACCTTTGAACTGGATGAGGGCATGGATATGCAGAGACCCATCTTGGTGTTTTTCTTGTGACACTCTGATAAATAATTTATCAGAAGGACAGGAAATGTTTTTAAGGAGTTCGAGCATTTGCTCCTTTGGTAATGGACATTTCGGATAAGTGAGGAAGATATTTTTGGCCTTCACTTGGAACTGGTGTGTACGAGGCATAATGAATTGGGTGCTCTCTAAAACTCTATGGAATGGGGTGCTTTGGGTGCCTATTTATACCGAGCCCCCAAATGGCATATTCGTAATTTCGAAATAACTTTCGAAATCCTCACGCTCCAAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_009112872.1
|
|
Location
|
142-507 |
|
Gene Name
|
V2 |
|
Protein Name
|
pre coat protein |
|
Coding Region
|
ATGTGGGACCCACTAGTGAACGAGTTTCCMGAAACTGTTCATGGGTTTAGGTGCATGTTGGCAGTGAAATATCTCCAACTAGTTGCAGATACGTATTCTCCAGATACGGTGGGATACGATTTAATACGTGATTTAATTTCAGTAATAAGGGCCAGGAATTATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCCTCGAAGGTACGCCGCCGTCTGAACTTCGACAGCCCATATGCGAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACAAAGGCAAGGGCATGGGCGAACAGGCCCATGAACAGAAAGCCCAGGATGTACAGGATGTACAGAAGTCCAGATGTTCCGAGGGGATGTGA |
|
Protein Sequence
|
MWDPLVNEFPETVHGFRCMLAVKYLQLVADTYSPDTVGYDLIRDLISVIRARNYVEATSRYNHFHARLEGTPPSELRQPICEPCCCPHCPRHKGKGMGEQAHEQKAQDVQDVQKSRCSEGM |
|
NCBI Accession
|
YP_009112873.1
|
|
Location
|
302-1072 |
|
Gene Name
|
CP |
|
Protein Name
|
Coat Protein |
|
Coding Region
|
ATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCCTCGAAGGTACGCCGCCGTCTGAACTTCGACAGCCCATATGCGAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACAAAGGCAAGGGCATGGGCGAACAGGCCCATGAACAGAAAGCCCAGGATGTACAGGATGTACAGAAGTCCAGATGTTCCGAGGGGATGTGAAGGCCCATGCAAGGTCCAGTCATTTGAGTCCAGACATGATATCCAGCACATTGGTAAAGTCATGTGTGTTAGTGATGTTACTCGTGGTATTGGGCTGACCCACAGGGTTGGCAAGAGGTTCTGTGTTAAGTCCGTTTATGTTCTGGGCAAAATCTGGATGGATGAGAACATCAAGACTAAGAATCATACGAATAGTGTCATGTTTTTTCTTGTTAGGGATCGTAGACCCGTTGACAAGCCTCAAGATTTTGGTGAGGTTTTTAACATGTTTGATAATGAGCCCAGCACGGCGACTGTGAAGAATGTTCATCGTGATAGATACCAGGTATTAAGGAAGTGGCACGCAACTGTGACAGGTGGTCTATATGCATCGAAGGAGCAGGCTCTCGTGAAGAAGTTTATTAGGGTTAATAATTATGTTGTGTACAACCAGCAAGAGGCTGGCAAGTATGAGAATCATACTGAGAATGCATTGATGTTGTATATGGCGTGTACGCACGCCTCTAACCCTGTGTATGCTACATTGAAGATACGGATCTATTTTTATGATTCAGTATCGAATTAA |
|
Protein Sequence
|
MSKRPADIIISTPASKVRRRLNFDSPYASRAAAPIVRVTKARAWANRPMNRKPRMYRMYRSPDVPRGCEGPCKVQSFESRHDIQHIGKVMCVSDVTRGIGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNSVMFFLVRDRRPVDKPQDFGEVFNMFDNEPSTATVKNVHRDRYQVLRKWHATVTGGLYASKEQALVKKFIRVNNYVVYNQQEAGKYENHTENALMLYMACTHASNPVYATLKIRIYFYDSVSN |
|
NCBI Accession
|
YP_009112874.1
|
|
Location
|
1069-1473 |
|
Gene Name
|
REn |
|
Protein Name
|
Replication Enhancer Protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAATCCATCACTGCAGCTCAAGCAGAGAATGGCGTGTATATCTGGGAGATTCAAAATCCCCTCTACTTCAAGATAACAGAACACCACAGCAGGCCACTCAACATGAACCACGACATCATCAACATCAGGGTCCAGTTCAATCACAACCTCAGGAAGAGACTGGGGATAATGAAGTGTTACTTGGGCCTGAGGATCCACACTCGTTTACATCCTCAGACTGGGCATTTCTTAAGAGTCTTTAAGACTCAAGTTTTACGATATTTAGATAGTTTAGGCGTAATTAGTATAAATAATTGTATTAAGGCTTTCAGACATGTATTATATGATGTACTTGAGGGCACAATTAATGTAATTGAGAATCATGATATAAAATTCAATATTTATTAA |
|
Protein Sequence
|
MDSRTGESITAAQAENGVYIWEIQNPLYFKITEHHSRPLNMNHDIINIRVQFNHNLRKRLGIMKCYLGLRIHTRLHPQTGHFLRVFKTQVLRYLDSLGVISINNCIKAFRHVLYDVLEGTINVIENHDIKFNIY |
|
NCBI Accession
|
YP_009112875.1
|
|
Location
|
1214-1621 |
|
Gene Name
|
TrAP |
|
Protein Name
|
Transactivator Protein |
|
Coding Region
|
ATGCAACCTTCATCTCCCTCGAAGGCCCACTATACTCAGGTTCCAATCAAGGTCCAACACAGAGCTGCTAAGCGTAGAGCCATCCGGCGTAAGAGGGTTGATCTAAACTGTGGGTGCTCATACTACGTACACATCAACTGCCACAACCATGGATTCACGCACAGGGGAATCCATCACTGCAGCTCAAGCAGAGAATGGCGTGTATATCTGGGAGATTCAAAATCCCCTCTACTTCAAGATAACAGAACACCACAGCAGGCCACTCAACATGAACCACGACATCATCAACATCAGGGTCCAGTTCAATCACAACCTCAGGAAGAGACTGGGGATAATGAAGTGTTACTTGGGCCTGAGGATCCACACTCGTTTACATCCTCAGACTGGGCATTTCTTAAGAGTCTTTAA |
|
Protein Sequence
|
MQPSSPSKAHYTQVPIKVQHRAAKRRAIRRKRVDLNCGCSYYVHINCHNHGFTHRGIHHCSSSREWRVYLGDSKSPLLQDNRTPQQATQHEPRHHQHQGPVQSQPQEETGDNEVLLGPEDPHSFTSSDWAFLKSL |
|
NCBI Accession
|
YP_009112876.1
|
|
Location
|
1551-2609 |
|
Gene Name
|
Rep |
|
Protein Name
|
replication associated Protein |
|
Coding Region
|
ATGCCTCGTACACACCAGTTCCAAGTGAAGGCCAAAAATATCTTCCTCACTTATCCGAAATGTCCATTACCAAAGGAGCAAATGCTCGAACTCCTTAAAAACATTTCCTGTCCTTCTGATAAATTATTTATCAGAGTGTCACAAGAAAAACACCAAGATGGGTCTCTGCATATCCATGCCCTCATCCAGTTCAAAGGTAAATCCCAGTTCAGAAACCCCAGACATTTTGATGTCACTCACCCCTATACCTCAACTCAATTCCACCCAAACTTCCAGGGAGCTAAGTCCAGCTCTGATGTCAAGTCCTACATCGAGAAGGACGGTGATTACATCGACTGGGGTGAGTTTCAGATCGATGGAAGATCTGCTCGAGGAGGTCAACAGACAGCTAATGATGTTGCAGCAGAGGCGTTAAATGCCGGTTCTGCTGACGCAGCTTTAGCAATAATTAGGGAAAAACTCCCTAAAGATTTTATTTTTCAATATCATAATTTAAAATGTAATTTAGATAGGATTTTTACACCTCCTGTAGAGGTTTATGTTTCTCCTTTTTCGTCTTCTTCCTTTGATCAAGTTCCCGAAGAACTTGAGGAGTGGGCTGCCGAGAATGTTGTCAGTGCCGCTGCGCGGCCTTTGAGACCCATAAGTATAGTCATAGAGGGTGACAGTAGAACGGGAAAGACGATGTGGGCCAGATCACTTGGACCACATAATTATCTGTGTGGGCATCTAGACCTTAGCCCAAAGGTCTACAATAATGAGGCCTGGTACAACGTCATTGATGACGTTGATCCCCACTACCTAAAGCACTTTAAAGAGTTCATGGGGGCCCAAAGGGACTGGCAATCAAATACAAAGTACGGGAAGCCAGTTCAAATTAAAGGTGGTATTCCCACTATCTTCCTCTGCAATCCTGGGCCCAATTCCAGCTATAAGGAGTACCTGGACGAGGAGAAGAATAGCGCATTGAAAGCCTGGGCACTAAAAAATGCAACCTTCATCTCCCTCGAAGGCCCACTATACTCAGGTTCCAATCAAGGTCCAACACAGAGCTGCTAA |
|
Protein Sequence
|
MPRTHQFQVKAKNIFLTYPKCPLPKEQMLELLKNISCPSDKLFIRVSQEKHQDGSLHIHALIQFKGKSQFRNPRHFDVTHPYTSTQFHPNFQGAKSSSDVKSYIEKDGDYIDWGEFQIDGRSARGGQQTANDVAAEALNAGSADAALAIIREKLPKDFIFQYHNLKCNLDRIFTPPVEVYVSPFSSSSFDQVPEELEEWAAENVVSAAARPLRPISIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYNNEAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEYLDEEKNSALKAWALKNATFISLEGPLYSGSNQGPTQSC |
|
NCBI Accession
|
YP_009112877.1
|
|
Location
|
2195-2452 |
|
Gene Name
|
C4 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGGTCTCTGCATATCCATGCCCTCATCCAGTTCAAAGGTAAATCCCAGTTCAGAAACCCCAGACATTTTGATGTCACTCACCCCTATACCTCAACTCAATTCCACCCAAACTTCCAGGGAGCTAAGTCCAGCTCTGATGTCAAGTCCTACATCGAGAAGGACGGTGATTACATCGACTGGGGTGAGTTTCAGATCGATGGAAGATCTGCTCGAGGAGGTCAACAGACAGCTAATGATGTTGCAGCAGAGGCGTTAA |
|
Protein Sequence
|
MGLCISMPSSSSKVNPSSETPDILMSLTPIPQLNSTQTSRELSPALMSSPTSRRTVITSTGVSFRSMEDLLEEVNRQLMMLQQRR |