Vernonia crinkle virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_001907745.1 |
| Isolate |
Uganda |
| Release date |
2016/12/18 |
| Submitter |
Mollel,H.G., Ndunguru,J., Sseruwagi,P., Alicai,T., Colvin,J., Navas-Castillo,J., Fiallo-Olive,E. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
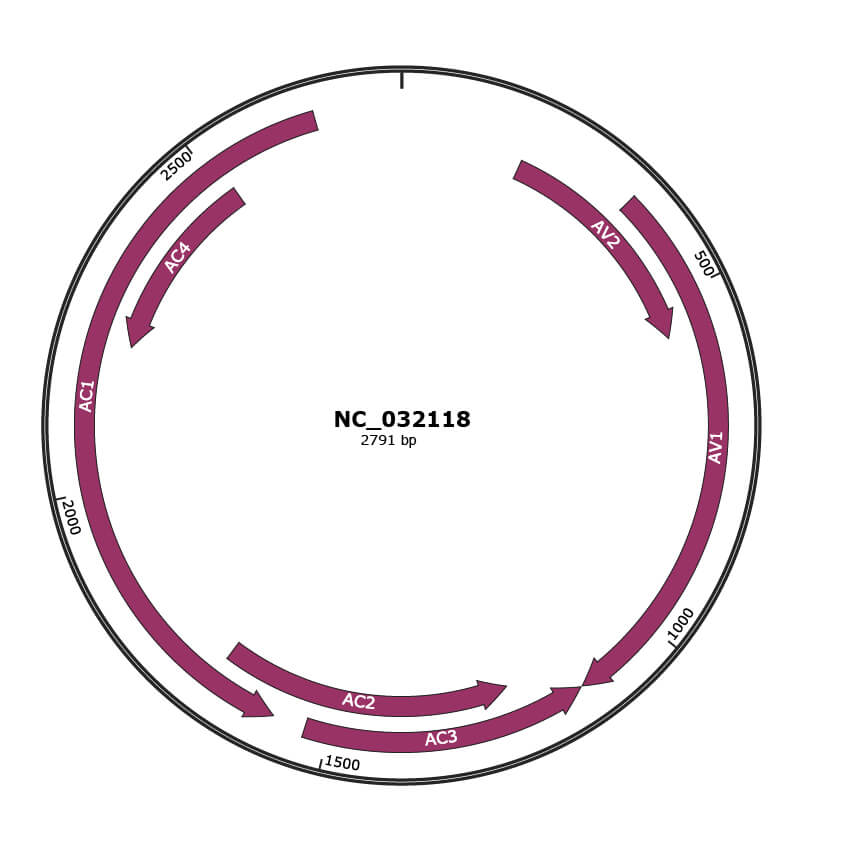
JBrowse
Genome
ACCGGGTGGCCGCGGTTTTTTTTAGGGCTACGTGGACGAACGACAGCCAAGGAATTTGAAAAAACGAAACTTAGACGCGCCTTGGGGACCACGGTGAAAAATCAACCAATAGGGGCGCAGCCTTTGTCTTTAGTTTGAATTAGGGTTTCTTTAAGACTTGCCTACTAAGCTACGGCTTTTAAGTCAAAAATGTTCGACCCTCTACTGAACCCTTTTCCTCGTTCGTATCATGGATTTCGTATTATGCTTGCTGTAAAATATTTACAGATCTGTCAGGAAAAATACTCCAACGGTACTAAGGGACATACGTATTTACAGGAATTGATACGTATTCTACGACGCAGCGATTTCAATGAAGCGTCCGATCAATATACCGATTTCATCACCGTCTTTGGTGAGCAAAGTCCGACGGAGGCTGAACTTCGACAGCCCAGCTTCTGCGAGGCCCATTTCTCCCTATGTCCGAAGTGCTCGGGCCCAATGGCAAAACAGGCCCATGTTCAGGAAGCCCAGGATATACCGAATGTATCGTTCGTCGGACGTTCCCCGGGGCTGTGAAGGCCCGTGTAAGATCCAGTCATTTGATCAGCGTGATTCCGTTGTTCATACGGGTAATGTTAGGTGTCTTAGTGATGTCACCCGTGGAAGTGGTCTTACACATCGTACTGGGAAACGTTTATGTATTAAATCTATTTACATAATAGGTAAGATCTGGATGGACGAGAATGTGAAGAAGTCCAATCATACTAACACGTGTATGTTTTGGTTAGTTAGGGATAGGCGTCCTTATGGAACTAGTCCTCAGGATTTTGGTCAGGTTTTTAACATGTTTGACAACGAGCCCAGTACTGCTACTGTGAAAAATGATATGCGTGATCGGTACCAGGTGTTGAGGAAATTCAAGGTGACCGTTACTGGAGGACCTTACGCTTGTAAAGAGTCTGCAATTGTTAATAAGTTTTTGAATCTGTACCATCATGTTACCTATAACCATCAGGAGGCAGCGAAGTACGAGAACCATACGGAGAATGCTTTGTTGTTGTATATGGCATGTACTCATGCTTCAAATCCTGTGTATGCAAGTCTGAAAATACGAATGTACTTCTATGACAGTGTAACGAATTGAAATTAATAAAGATTGAATTTTATATCATAATTTGTGTCTACATGTACAGTTTGTTCCAATACATTCCATAATACATGATTGATAGCCCTAATTACAATGTTAATTGTGACTATTCCTGCTTGGTTGATGTACTTCATGATCTGTGTCTTGAACACTCTCAAGAAATGCAATGTCTGAGGCTGTAAACCAGTCCAGATCTTCAAGTTGATAAAACACTTGTGAAGACCTAGAGCTTTCCGCAGGTTGTGGTTGAATCTGATTTGCAGGTGTATCACGTCTTTGTTCATTGTGAACGGTCGTTTGTGGTGTTCCAGTATGGTGAAGTACAGAGGGTTGTGGAGGTTCCAGATATACTCTCCATTCATTGCCTGAATTGCAGTAATGGGTTCCCCTGTGCGTGAATCCATGGTTCCTGCAATTGAGATGAATCAGGTAGGCGCAGCCGCAGGGAAGGTCAATCTTCTTCCGGCGTATTGACCTCCGTTTCTTCTCTCTGTGTTGGGCTTTGATGTTCGGTGGAGAAGAGTGGTTCGGTGATGGTGTGGAACAACGCATTTTTTATAGCCCAGTATTTTAGTGCGTTGTTTTTTTCCTCGTCAAGGAACTCTTTATAGGACGACGTTGGGCCCGGATTGCACAGGAAGATTGTTGGGATCCCGCCTTTAATTTGAATTGGTTTCCCGTACTTCGTGTTGCTTTGCCAGTCTCGTTGGGCCCCCATGAATTCCTTGAAATGTTTCAAATAATGAGGGTCAACATCGTCAATGATATTAAACCAGGCATCATTTGAATATATTTTAGGGCTTAGATCCAGATGTCCACATAAATAGTTATGAGGACCTAAGGAACGTGCCCATAATGTTTTTCCAGTACGTGAATCACCTTCTAATACTAAACTTAAGGGCCTTATTGGCCGCGCAGCGGCAGCACATACGTTTTCAGAAGCCCATTCTTCCAGTGTATCTGGAACGTTATTAAACGAAGAAGATAAAAACGGACTAATATATTGCTCCATAGGAGGAGCGAAAATCCTATCTAAATTAGCATTTAAATTATGAAATTGTAAAACAAAATCTTTAGGAGCCTTCTCCTTTAATATATCGAGGGCCTGTGACTTAGACCCTGAATTGAGTGCCTCGGCATATGCGTCGTTGGCATTCTGGCAACCTCCTCTAGCAGATCGTCCATCGATCTGGAAAACTCCATGATCAAGCACGTCTCCGTCTTTTTCCATGTAGGATTTAACATCGGAGCTAGACTTAGCTCCCTGGATGTTAGGATGGAATTGGGTTGAGCGATTAGGTGAGTTGAGGTCGAAGAAACGGTTGTTTCTGCACTTGAATTTTCCTTCGAATTGGATGAGCACGTGTAGATGAGGTTCCCCATTTTCATGTAATTCTCTGCAAATTCTGATGAATAATTTATTTGTTGGGGTATCTAGGGCTAGCAATTGTGAAAGTGCCTCTTCTTTGGTAAGTGAGCAGCGTGGATAAGTAAGGAAGAAGTTTCTGGCATTTACAAGAAAGGCCCCTGATCTTGGCATGTTTGGCAGAAATGTATCGGGGACACTCAAACTTGCTCTGCAATTGGGGACATCGGGGACGCATTTATACCTAGTCCCCAATACCGGCTCTGTCGGTCAAAAGCGGCCACCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_009329828.1
|
|
Location
|
190-558 |
|
Gene Name
|
AV2 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGTTCGACCCTCTACTGAACCCTTTTCCTCGTTCGTATCATGGATTTCGTATTATGCTTGCTGTAAAATATTTACAGATCTGTCAGGAAAAATACTCCAACGGTACTAAGGGACATACGTATTTACAGGAATTGATACGTATTCTACGACGCAGCGATTTCAATGAAGCGTCCGATCAATATACCGATTTCATCACCGTCTTTGGTGAGCAAAGTCCGACGGAGGCTGAACTTCGACAGCCCAGCTTCTGCGAGGCCCATTTCTCCCTATGTCCGAAGTGCTCGGGCCCAATGGCAAAACAGGCCCATGTTCAGGAAGCCCAGGATATACCGAATGTATCGTTCGTCGGACGTTCCCCGGGGCTGTGA |
|
Protein Sequence
|
MFDPLLNPFPRSYHGFRIMLAVKYLQICQEKYSNGTKGHTYLQELIRILRRSDFNEASDQYTDFITVFGEQSPTEAELRQPSFCEAHFSLCPKCSGPMAKQAHVQEAQDIPNVSFVGRSPGL |
|
NCBI Accession
|
YP_009329829.1
|
|
Location
|
353-1126 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGAAGCGTCCGATCAATATACCGATTTCATCACCGTCTTTGGTGAGCAAAGTCCGACGGAGGCTGAACTTCGACAGCCCAGCTTCTGCGAGGCCCATTTCTCCCTATGTCCGAAGTGCTCGGGCCCAATGGCAAAACAGGCCCATGTTCAGGAAGCCCAGGATATACCGAATGTATCGTTCGTCGGACGTTCCCCGGGGCTGTGAAGGCCCGTGTAAGATCCAGTCATTTGATCAGCGTGATTCCGTTGTTCATACGGGTAATGTTAGGTGTCTTAGTGATGTCACCCGTGGAAGTGGTCTTACACATCGTACTGGGAAACGTTTATGTATTAAATCTATTTACATAATAGGTAAGATCTGGATGGACGAGAATGTGAAGAAGTCCAATCATACTAACACGTGTATGTTTTGGTTAGTTAGGGATAGGCGTCCTTATGGAACTAGTCCTCAGGATTTTGGTCAGGTTTTTAACATGTTTGACAACGAGCCCAGTACTGCTACTGTGAAAAATGATATGCGTGATCGGTACCAGGTGTTGAGGAAATTCAAGGTGACCGTTACTGGAGGACCTTACGCTTGTAAAGAGTCTGCAATTGTTAATAAGTTTTTGAATCTGTACCATCATGTTACCTATAACCATCAGGAGGCAGCGAAGTACGAGAACCATACGGAGAATGCTTTGTTGTTGTATATGGCATGTACTCATGCTTCAAATCCTGTGTATGCAAGTCTGAAAATACGAATGTACTTCTATGACAGTGTAACGAATTGA |
|
Protein Sequence
|
MKRPINIPISSPSLVSKVRRRLNFDSPASARPISPYVRSARAQWQNRPMFRKPRIYRMYRSSDVPRGCEGPCKIQSFDQRDSVVHTGNVRCLSDVTRGSGLTHRTGKRLCIKSIYIIGKIWMDENVKKSNHTNTCMFWLVRDRRPYGTSPQDFGQVFNMFDNEPSTATVKNDMRDRYQVLRKFKVTVTGGPYACKESAIVNKFLNLYHHVTYNHQEAAKYENHTENALLLYMACTHASNPVYASLKIRMYFYDSVTN |
|
NCBI Accession
|
YP_009329830.1
|
|
Location
|
1129-1533 |
|
Gene Name
|
AC3 |
|
Protein Name
|
REn |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACCCATTACTGCAATTCAGGCAATGAATGGAGAGTATATCTGGAACCTCCACAACCCTCTGTACTTCACCATACTGGAACACCACAAACGACCGTTCACAATGAACAAAGACGTGATACACCTGCAAATCAGATTCAACCACAACCTGCGGAAAGCTCTAGGTCTTCACAAGTGTTTTATCAACTTGAAGATCTGGACTGGTTTACAGCCTCAGACATTGCATTTCTTGAGAGTGTTCAAGACACAGATCATGAAGTACATCAACCAAGCAGGAATAGTCACAATTAACATTGTAATTAGGGCTATCAATCATGTATTATGGAATGTATTGGAACAAACTGTACATGTAGACACAAATTATGATATAAAATTCAATCTTTATTAA |
|
Protein Sequence
|
MDSRTGEPITAIQAMNGEYIWNLHNPLYFTILEHHKRPFTMNKDVIHLQIRFNHNLRKALGLHKCFINLKIWTGLQPQTLHFLRVFKTQIMKYINQAGIVTINIVIRAINHVLWNVLEQTVHVDTNYDIKFNLY |
|
NCBI Accession
|
YP_009329831.1
|
|
Location
|
1226-1681 |
|
Gene Name
|
AC2 |
|
Protein Name
|
TrAP |
|
Coding Region
|
ATGCGTTGTTCCACACCATCACCGAACCACTCTTCTCCACCGAACATCAAAGCCCAACACAGAGAGAAGAAACGGAGGTCAATACGCCGGAAGAAGATTGACCTTCCCTGCGGCTGCGCCTACCTGATTCATCTCAATTGCAGGAACCATGGATTCACGCACAGGGGAACCCATTACTGCAATTCAGGCAATGAATGGAGAGTATATCTGGAACCTCCACAACCCTCTGTACTTCACCATACTGGAACACCACAAACGACCGTTCACAATGAACAAAGACGTGATACACCTGCAAATCAGATTCAACCACAACCTGCGGAAAGCTCTAGGTCTTCACAAGTGTTTTATCAACTTGAAGATCTGGACTGGTTTACAGCCTCAGACATTGCATTTCTTGAGAGTGTTCAAGACACAGATCATGAAGTACATCAACCAAGCAGGAATAGTCACAATTAA |
|
Protein Sequence
|
MRCSTPSPNHSSPPNIKAQHREKKRRSIRRKKIDLPCGCAYLIHLNCRNHGFTHRGTHYCNSGNEWRVYLEPPQPSVLHHTGTPQTTVHNEQRRDTPANQIQPQPAESSRSSQVFYQLEDLDWFTASDIAFLESVQDTDHEVHQPSRNSHN |
|
NCBI Accession
|
YP_009329832.1
|
|
Location
|
1581-2669 |
|
Gene Name
|
AC1 |
|
Protein Name
|
Rep |
|
Coding Region
|
ATGCCAAGATCAGGGGCCTTTCTTGTAAATGCCAGAAACTTCTTCCTTACTTATCCACGCTGCTCACTTACCAAAGAAGAGGCACTTTCACAATTGCTAGCCCTAGATACCCCAACAAATAAATTATTCATCAGAATTTGCAGAGAATTACATGAAAATGGGGAACCTCATCTACACGTGCTCATCCAATTCGAAGGAAAATTCAAGTGCAGAAACAACCGTTTCTTCGACCTCAACTCACCTAATCGCTCAACCCAATTCCATCCTAACATCCAGGGAGCTAAGTCTAGCTCCGATGTTAAATCCTACATGGAAAAAGACGGAGACGTGCTTGATCATGGAGTTTTCCAGATCGATGGACGATCTGCTAGAGGAGGTTGCCAGAATGCCAACGACGCATATGCCGAGGCACTCAATTCAGGGTCTAAGTCACAGGCCCTCGATATATTAAAGGAGAAGGCTCCTAAAGATTTTGTTTTACAATTTCATAATTTAAATGCTAATTTAGATAGGATTTTCGCTCCTCCTATGGAGCAATATATTAGTCCGTTTTTATCTTCTTCGTTTAATAACGTTCCAGATACACTGGAAGAATGGGCTTCTGAAAACGTATGTGCTGCCGCTGCGCGGCCAATAAGGCCCTTAAGTTTAGTATTAGAAGGTGATTCACGTACTGGAAAAACATTATGGGCACGTTCCTTAGGTCCTCATAACTATTTATGTGGACATCTGGATCTAAGCCCTAAAATATATTCAAATGATGCCTGGTTTAATATCATTGACGATGTTGACCCTCATTATTTGAAACATTTCAAGGAATTCATGGGGGCCCAACGAGACTGGCAAAGCAACACGAAGTACGGGAAACCAATTCAAATTAAAGGCGGGATCCCAACAATCTTCCTGTGCAATCCGGGCCCAACGTCGTCCTATAAAGAGTTCCTTGACGAGGAAAAAAACAACGCACTAAAATACTGGGCTATAAAAAATGCGTTGTTCCACACCATCACCGAACCACTCTTCTCCACCGAACATCAAAGCCCAACACAGAGAGAAGAAACGGAGGTCAATACGCCGGAAGAAGATTGA |
|
Protein Sequence
|
MPRSGAFLVNARNFFLTYPRCSLTKEEALSQLLALDTPTNKLFIRICRELHENGEPHLHVLIQFEGKFKCRNNRFFDLNSPNRSTQFHPNIQGAKSSSDVKSYMEKDGDVLDHGVFQIDGRSARGGCQNANDAYAEALNSGSKSQALDILKEKAPKDFVLQFHNLNANLDRIFAPPMEQYISPFLSSSFNNVPDTLEEWASENVCAAAARPIRPLSLVLEGDSRTGKTLWARSLGPHNYLCGHLDLSPKIYSNDAWFNIIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEFLDEEKNNALKYWAIKNALFHTITEPLFSTEHQSPTQREETEVNTPEED |
|
NCBI Accession
|
YP_009329833.1
|
|
Location
|
2219-2518 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGAAAATGGGGAACCTCATCTACACGTGCTCATCCAATTCGAAGGAAAATTCAAGTGCAGAAACAACCGTTTCTTCGACCTCAACTCACCTAATCGCTCAACCCAATTCCATCCTAACATCCAGGGAGCTAAGTCTAGCTCCGATGTTAAATCCTACATGGAAAAAGACGGAGACGTGCTTGATCATGGAGTTTTCCAGATCGATGGACGATCTGCTAGAGGAGGTTGCCAGAATGCCAACGACGCATATGCCGAGGCACTCAATTCAGGGTCTAAGTCACAGGCCCTCGATATATTAA |
|
Protein Sequence
|
MKMGNLIYTCSSNSKENSSAETTVSSTSTHLIAQPNSILTSRELSLAPMLNPTWKKTETCLIMEFSRSMDDLLEEVARMPTTHMPRHSIQGLSHRPSIY |