Triumfetta yellow mosaic virus
Basic Information
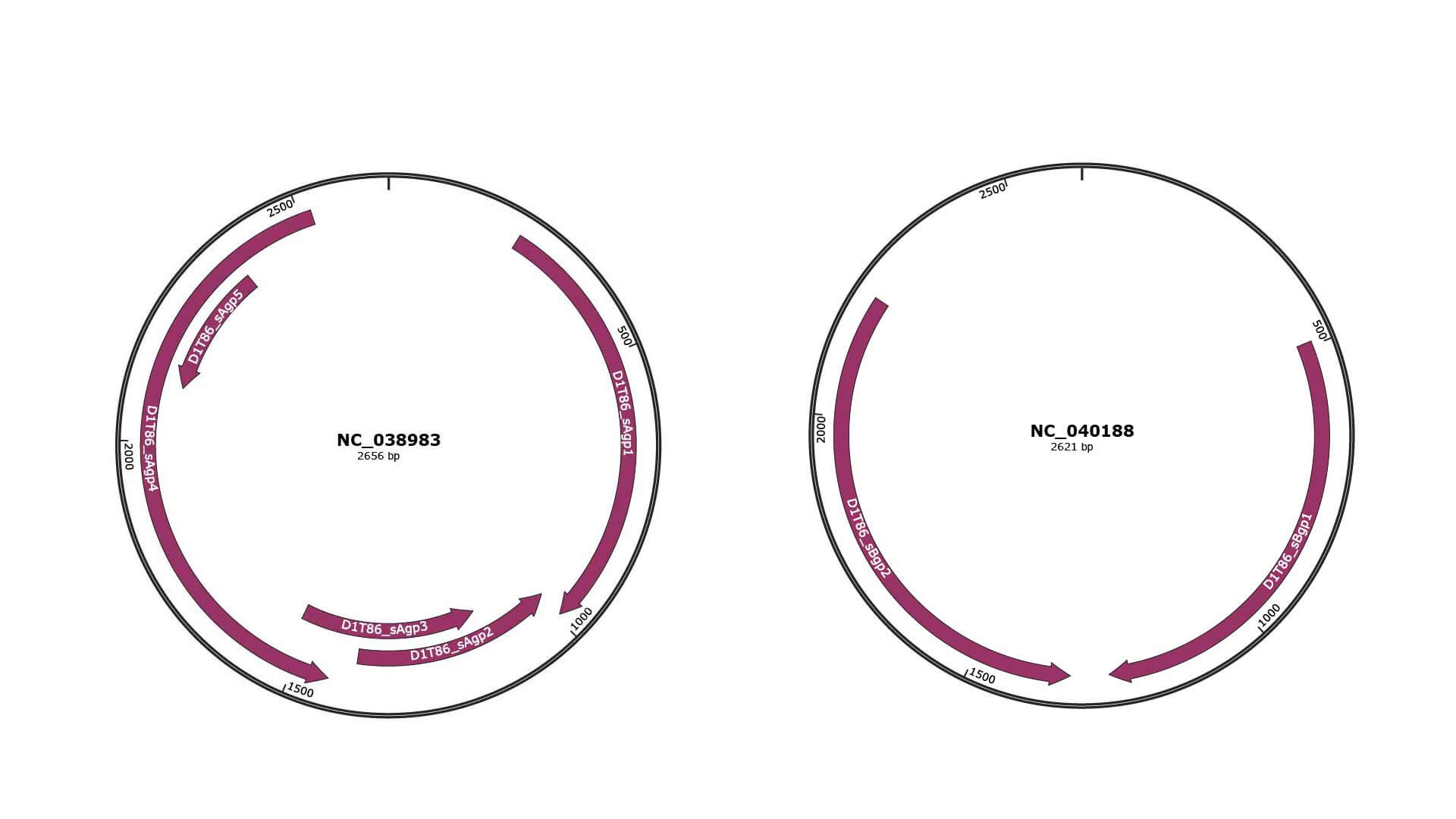
Genomic Organization
JBrowse
Genome
ACCTGAGGGCCGCGCGATTTTTTCGCCCCCCCCACGTGGCGTGCTGGTGACCCTCCGATCCCCTCACCCCCTTGGTGGAGTCGTGGTCCCCTCATTTGTGTACCCCCTTTCTCAATTTGGTTTAGCGCTTTTTTGGAGTCCGCGAAATGAGTTAAGCGCATATTTTGAGATCCGTGGACTGTATAACTGTTATGGTAACTTTAATTTAAATTAAAGTTTATTCACTCTATTTATCCAATCGTTTCGCGCTCTTGCGTTATCTTATTTGTCGCGCGATTGTTTCTAGACCGTCTGATAATATTAGTATGCAATATCTTATTGCATTATGAGACTTGAATTATGTGGCGCTACTAAACCATGACCCCATTGTACTACTTGTTCGACGTGGACCAATTAAGTCTTCGATGTATAGCCAATTTAATTTAGGAAATGTATATTTAAATCCTATTGTGATGAGGGAAGTGGATATCACGTCCATTTTAATATATTAAAATGTATCCCTCTAAGTATAAACGTGGAGTCTCATCCAATTATCGTCGTAGTTATCGACGAACTACTGTATTCAAGCCTTCCTATGGTGTTAAACGTGTTGATGGGAAACGTCGATCTGGTAACCAGAACAAGGCCCATGATGAGAATAAAATGTCAGCCCAACGGATACATGAGAACCAGTTTGGGCCTGAGTTTGTAATGGGCCACAACACAGCTATCTCAACGTTTATCAGTTATCCTAATCAAGGTAAGACCGAGCCCAACCGATCCAGGTCATATATTAAACTTAAACGATTACGTTTTAAGGGAACTGTTAAGATTGAACGTGTTCATTCTGATGTCATCATGGATGGGTTAAGTCCAAAGATCGAAGGAGTATTTTCCCTTGTTGTTGTTGTTGATCGTAAACCCCACTTGGGTACATCTGGATGTCTCCCCACGTTTGACGAGTTATTTGGTGCTAGAATCCACAGTCATGGTAATCTAGCCATAACACCTTCCCTTAAAGATCGTTTTTACATACGTCATGTGCTCAAACGTGTGCTATCTGTAGAGAAGGATTCATTGATGGTTGATCTAGAAGGGACGACATCCCTCTCTAATCGGCGTTTTAGCTGTTGGTCTTCGTTTAAGGATATTGATCGAGATTCATGTAACGGCGTTTATGCAAACATAAGCAAGAACGCTCTTTTAGTTTATTACTGTTGGATGTCGGATTCTTCTTCCAAGGCATCGACATTTGTATCATATGATCTGGATTATATTGGTTAAATGTAATAAGTGATTAGTTAATCATTCAAGCATACACTTAAAAGAACTTCTTATTCAATAATCTGTATTAATTTAAAGATTTCGGTTGTGGAGGAATACAATTCGTTTTAATACACTCTTGGACCGCAGTCCTAACTAGGTCGTTTATTTGGGACTCTGACATGGTGATATGTGATTCTGTCCTTCTAGCAGCCACTATTGAAGCAGAGTCACCTGGGTCTAACATGCTGGTCCCTAGTCTATGTAATCCTCGGTATGGGTGTGCTGCGTTCTCCAATTCTGAGTCCGCGCTCGATTCACCTAAACCTATGGTACTTTTGACTGCCCATGTCTCTCCTGGGCTAATCGATATTGGGCTTGGAAGCCCATAGTTTATTGTGGACGTGGACCGGATCAATTTCCTTTCCCATTTGCCATAACCCACATGGCTGAAATCAATATCTTTCTCTGTAAACTGTTTTGATAATATCTTAACCGTCGGTGCCCGGAAAGGAATATCAACGGAATGTTTCGCCGTTGACAGTTTCAGTTTTCCTTTGAATTTCGCGAAGTGAGTCCTCTGGTGAACGTTTGTGTCACACACCCTGTAATATAACCTCCATGGAATTGGGTCCTTAAGGGAGAAGAACGAGGATGAGAAATAGTGGAGGTCTATGTTACATCTGATGGGGAAAGTCCATGACGCCTGTAAGGATTCATTATCTGTCATCCTCTTGTCGTGGATCTCCACTATTACGGAACCTGTGGCGTTGATCGGTACTTGTTGTCTGTATTCTATGACGCAATGGTCGATCTTCATACAACTACGACTGAGTCTAGCGCTTATCTGTGACGCTGCAGAAGGAAACTGTAGCACAATCTCAGTTAGATCATGAGATAGTTGATATTCATCACGTTGAGATTCAATATAATTAAATGCACTTGGTGGATTAGCTAACTGAGACTCCATTTGAAGAATTATATAAGAAAATAAGGCCACGCAGTGGCCTGTGAAGGAGAATTGAATAAGGAAAATGAAAGAGTAAAGTGGATAAATGAGAAAGTAATCAGGGTTTCATAAATAATATATGTGTTACTGGTTTAGTCGAGGGATTGAGAGGAGATATTATATAATTGAGGTTTTATTTACAGGACTGTGTAAGAGATTGTATATAATTGGCTAATGGACTGGTTGTATTTATATAGCCCAAAGCTTCTCAGAGAAGGAGCTTCCTAATGGCATTTTATGTAAATAAGGCCTTGTACACCGATTGAGCTCTCGTTCAAAAGTCTATATGAATTGGTGTAATGGTGCCAATATATAGGTAGGAGTTCCATAGGAGTAAATGCACACGTGGCGGCCCTCAGATTATAGTATT
ACCTGAGGGCCGCGCGATTTTTTGCCCCCCACGTGGCGCTATCGTGGCCGTTGGATCCTCTCGCCCCCTCAGACCACGCGCGCTTTGACTCCTTTAATTTGAATTAAAGGAATTAACTTTTGTTTTATCCAATGATAGTGCGCCTGAGGAGCCTAGATATTTGTGTTAAGACTTGGTCACTAAGTTTTATGGCCCCTATAAAATTAAAGCACACTTGACGTTAACCTTTAATTCAGAATGCCTAAGCGGGATCCCTCATGGCGCCAGATGGCGGGAACCTCCAAGGTAAGCCGGGCTTCTAATTTTTCTCCTCTAGCAGGTCTTGGCCCAAAATTCAACAAGGCCTCTGAATGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATATACAGGACGTTAAGAACGCCGGATGTTCCTAGAGGCTGTGAAGGGCCCTGTAAGGTCCAGTCCTATGAGCAGCGTCATGATATCTCTCATGTTGGGAAGGTGATGTGTATATCTGACGTGACACGCGGTAACGGTATTACCCACCGTGTTGGTAAGCGTTTCTGTGTTAAGTCTGTTTACATTTTAGGGAAGATATGGATGGACGAGAATATCAAGCTGAAGAATCACACGAACAGTGTCATGTTCTGGTTGGTTAGAGACCGTAGACCTTATGGCACCCCAATGGATTTTGGTCAGGTGTTCAACATGTTCGACAACGAGCCCAGTACTGCAACGGTTAAGAACGATCTCCGTGATCGTTTCCAAGTCATGCATAAGTTCTATGGCAAGGTCACCGGTGGACAGTATGCCAGCAATGAACAGGCGTTGGTCAAACGGTTCTGGAAGGTCAACAATCATGTGGTCTACAATCATCAGGAAGCCGGGAAGTATGAGAATCACACGGAGAACGCATTATTATTGTATATGGCATGTACTCATGCCTCTAACCCTGTTTATGCAACTCTCAAGATTCGGATCTATTTTTATGATTCGATTACTAATTAATAAATTTTGAATTTTATTGAATGATTTTCCATTACATAATTGACATACGACCTGTCCGTTGCGAAACGAACAGCTCTAATTACATTATTAATCGTAATAACACCTAATTGGTCTAAGTACATCAAAACTAAAGATCTAAACCGAATTAAATAAGTCGTCACAGAAGCTGTCAGTGATGTCGTCCAGACTTGGAAGTTCAGGAACGCCTTGTGGAGATCCAATGCTCTCCTGAGGTTGTGGTTGAACCGTATCTGAACGTGGTACACTCTTGTCCTCGTGTACATGATGTCCTCTACTCGGCATATCTTGAAATAGAGGGGATTTGTTATTTCCCAGATATAGACGCCATTCTCTGCCTGATGTGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGACCGGTGCAGTTGATGTGGACGTATATTGAACAGCCGCACCCTAAGTCAACTCGTCGTCGCCTGATTTCTCTCTTCTTGGCAATCCTGTGTCGTGGTTTGATACAGGGGGGAGTCGAGGAAGATGAATTTAGCATTGTGGAGTGTCCAGCCTTTTAGTGATGCATTTTCCTCTCTCTCCAGAAAATCTTTATAACTAGCCCCCTCGCCAGGATTGCAGAGCACGATTGATGGGATACCCCCTTTAATTTGAACAGGTTTCCCGTACTTGCAATTTGACTGCCAATCTTTCTGAGCACCAATCAATTCTTTCCAGTGCTTTAACTTTAGATAATGGGGTGTGACATCATCAATGACGTTATACTCAACTTGATTTGAGTAAACCCTAGAATTGAAATCTAGATGTCCACTCAAGTAATTATGTCGTCCTAAAGCACGTGCCCACATCGTTTTCCCCGTTCGACTATCACCTTCGACAATCAAACTAATAGGTCGTTCTGGACGCGCAGCGTCACCCCTCCCAAAATAATCATCAGCCCATTCCTGCATCTCATCTGGAACGTTAGTGAATGAAGAGAGGGGAAACGGAGGAGTCCATGGCTCCGGAGCCTTCGAGAAAATTCTATCTAAATTAGAATTTAAATTATGAAATTGAAAAAGATATTTCTCAGGCAACTTCTCTCTGATAATTTGAAGTGCCGTTAGTTTGTCCGGAGCATTTAACGCCTCTGCTGCTGCATCGTTAGCTGTCTGTTGACCTCCTCTAGCACATCTTCCGTCGATCTGAAAAGTACCCCATTCGATGTAATCTCCGTCCTTCTGTATATATGATTTGGCGTCGGAGGCGGATTTACATGATTTGTAATCTCCATGACTGACATTGGAATGTTGGGGATGTCGCAAGTCGAAGAATCGACTATTTGTGCACTGGAATTTCCCTTCGAACTGCAGCAGAGCATGGAGATGAGGTGTTCCATCTTCGTGTAATTCTCTGCATATCCGGATATATTTCTTTTTAGTTGGGGTATTTAATGCTAGGATTTGGGAAAGTGCCTCCTCTTTGGAGATGGAACACCTGGGATAAGTGAGGAAATAATTTTTGGCGTTAACCTTAAAACGCTGCGAGGGTGGCATATTTGTAAATAAGGCTGTGTACTCCGATTGAGCTCTCGTTCAAAAGTCTCTATGAATTGGTGTATTGGTGCCAATATATAGGTAGGAGTTCCATAGGGGTAAATGCACACGTGGCGGCCCTCAGAATATAGTATT
Gene Information
|
NCBI Accession
|
YP_009547936.1
|
|
Location
|
493-1263 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTATCCCTCTAAGTATAAACGTGGAGTCTCATCCAATTATCGTCGTAGTTATCGACGAACTACTGTATTCAAGCCTTCCTATGGTGTTAAACGTGTTGATGGGAAACGTCGATCTGGTAACCAGAACAAGGCCCATGATGAGAATAAAATGTCAGCCCAACGGATACATGAGAACCAGTTTGGGCCTGAGTTTGTAATGGGCCACAACACAGCTATCTCAACGTTTATCAGTTATCCTAATCAAGGTAAGACCGAGCCCAACCGATCCAGGTCATATATTAAACTTAAACGATTACGTTTTAAGGGAACTGTTAAGATTGAACGTGTTCATTCTGATGTCATCATGGATGGGTTAAGTCCAAAGATCGAAGGAGTATTTTCCCTTGTTGTTGTTGTTGATCGTAAACCCCACTTGGGTACATCTGGATGTCTCCCCACGTTTGACGAGTTATTTGGTGCTAGAATCCACAGTCATGGTAATCTAGCCATAACACCTTCCCTTAAAGATCGTTTTTACATACGTCATGTGCTCAAACGTGTGCTATCTGTAGAGAAGGATTCATTGATGGTTGATCTAGAAGGGACGACATCCCTCTCTAATCGGCGTTTTAGCTGTTGGTCTTCGTTTAAGGATATTGATCGAGATTCATGTAACGGCGTTTATGCAAACATAAGCAAGAACGCTCTTTTAGTTTATTACTGTTGGATGTCGGATTCTTCTTCCAAGGCATCGACATTTGTATCATATGATCTGGATTATATTGGTTAA |
|
Protein Sequence
|
MYPSKYKRGVSSNYRRSYRRTTVFKPSYGVKRVDGKRRSGNQNKAHDENKMSAQRIHENQFGPEFVMGHNTAISTFISYPNQGKTEPNRSRSYIKLKRLRFKGTVKIERVHSDVIMDGLSPKIEGVFSLVVVVDRKPHLGTSGCLPTFDELFGARIHSHGNLAITPSLKDRFYIRHVLKRVLSVEKDSLMVDLEGTTSLSNRRFSCWSSFKDIDRDSCNGVYANISKNALLVYYCWMSDSSSKASTFVSYDLDYIG |
|
NCBI Accession
|
YP_009547937.1
|
|
Location
|
1331-2212 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGAGTCTCAGTTAGCTAATCCACCAAGTGCATTTAATTATATTGAATCTCAACGTGATGAATATCAACTATCTCATGATCTAACTGAGATTGTGCTACAGTTTCCTTCTGCAGCGTCACAGATAAGCGCTAGACTCAGTCGTAGTTGTATGAAGATCGACCATTGCGTCATAGAATACAGACAACAAGTACCGATCAACGCCACAGGTTCCGTAATAGTGGAGATCCACGACAAGAGGATGACAGATAATGAATCCTTACAGGCGTCATGGACTTTCCCCATCAGATGTAACATAGACCTCCACTATTTCTCATCCTCGTTCTTCTCCCTTAAGGACCCAATTCCATGGAGGTTATATTACAGGGTGTGTGACACAAACGTTCACCAGAGGACTCACTTCGCGAAATTCAAAGGAAAACTGAAACTGTCAACGGCGAAACATTCCGTTGATATTCCTTTCCGGGCACCGACGGTTAAGATATTATCAAAACAGTTTACAGAGAAAGATATTGATTTCAGCCATGTGGGTTATGGCAAATGGGAAAGGAAATTGATCCGGTCCACGTCCACAATAAACTATGGGCTTCCAAGCCCAATATCGATTAGCCCAGGAGAGACATGGGCAGTCAAAAGTACCATAGGTTTAGGTGAATCGAGCGCGGACTCAGAATTGGAGAACGCAGCACACCCATACCGAGGATTACATAGACTAGGGACCAGCATGTTAGACCCAGGTGACTCTGCTTCAATAGTGGCTGCTAGAAGGACAGAATCACATATCACCATGTCAGAGTCCCAAATAAACGACCTAGTTAGGACTGCGGTCCAAGAGTGTATTAAAACGAATTGTATTCCTCCACAACCGAAATCTTTAAATTAA |
|
Protein Sequence
|
MESQLANPPSAFNYIESQRDEYQLSHDLTEIVLQFPSAASQISARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWRLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTEKDIDFSHVGYGKWERKLIRSTSTINYGLPSPISISPGETWAVKSTIGLGESSADSELENAAHPYRGLHRLGTSMLDPGDSASIVAARRTESHITMSESQINDLVRTAVQECIKTNCIPPQPKSLN |
|
NCBI Accession
|
YP_009508394.1
|
|
Location
|
238-993 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGGGATCCCTCATGGCGCCAGATGGCGGGAACCTCCAAGGTAAGCCGGGCTTCTAATTTTTCTCCTCTAGCAGGTCTTGGCCCAAAATTCAACAAGGCCTCTGAATGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATATACAGGACGTTAAGAACGCCGGATGTTCCTAGAGGCTGTGAAGGGCCCTGTAAGGTCCAGTCCTATGAGCAGCGTCATGATATCTCTCATGTTGGGAAGGTGATGTGTATATCTGACGTGACACGCGGTAACGGTATTACCCACCGTGTTGGTAAGCGTTTCTGTGTTAAGTCTGTTTACATTTTAGGGAAGATATGGATGGACGAGAATATCAAGCTGAAGAATCACACGAACAGTGTCATGTTCTGGTTGGTTAGAGACCGTAGACCTTATGGCACCCCAATGGATTTTGGTCAGGTGTTCAACATGTTCGACAACGAGCCCAGTACTGCAACGGTTAAGAACGATCTCCGTGATCGTTTCCAAGTCATGCATAAGTTCTATGGCAAGGTCACCGGTGGACAGTATGCCAGCAATGAACAGGCGTTGGTCAAACGGTTCTGGAAGGTCAACAATCATGTGGTCTACAATCATCAGGAAGCCGGGAAGTATGAGAATCACACGGAGAACGCATTATTATTGTATATGGCATGTACTCATGCCTCTAACCCTGTTTATGCAACTCTCAAGATTCGGATCTATTTTTATGATTCGATTACTAATTAA |
|
Protein Sequence
|
MPKRDPSWRQMAGTSKVSRASNFSPLAGLGPKFNKASEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYGKVTGGQYASNEQALVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_009508395.1
|
|
Location
|
990-1388 |
|
Protein Name
|
replication-enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCACATCAGGCAGAGAATGGCGTCTATATCTGGGAAATAACAAATCCCCTCTATTTCAAGATATGCCGAGTAGAGGACATCATGTACACGAGGACAAGAGTGTACCACGTTCAGATACGGTTCAACCACAACCTCAGGAGAGCATTGGATCTCCACAAGGCGTTCCTGAACTTCCAAGTCTGGACGACATCACTGACAGCTTCTGTGACGACTTATTTAATTCGGTTTAGATCTTTAGTTTTGATGTACTTAGACCAATTAGGTGTTATTACGATTAATAATGTAATTAGAGCTGTTCGTTTCGCAACGGACAGGTCGTATGTCAATTATGTAATGGAAAATCATTCAATAAAATTCAAAATTTATTAA |
|
Protein Sequence
|
MDSRTGELITAHQAENGVYIWEITNPLYFKICRVEDIMYTRTRVYHVQIRFNHNLRRALDLHKAFLNFQVWTTSLTASVTTYLIRFRSLVLMYLDQLGVITINNVIRAVRFATDRSYVNYVMENHSIKFKIY |
|
NCBI Accession
|
YP_009508396.1
|
|
Location
|
1129-1524 |
|
Protein Name
|
transactivating protein |
|
Coding Region
|
ATGCTAAATTCATCTTCCTCGACTCCCCCCTGTATCAAACCACGACACAGGATTGCCAAGAAGAGAGAAATCAGGCGACGACGAGTTGACTTAGGGTGCGGCTGTTCAATATACGTCCACATCAACTGCACCGGTCATGGATTCACGCACAGGGGAACTCATCACTGCACATCAGGCAGAGAATGGCGTCTATATCTGGGAAATAACAAATCCCCTCTATTTCAAGATATGCCGAGTAGAGGACATCATGTACACGAGGACAAGAGTGTACCACGTTCAGATACGGTTCAACCACAACCTCAGGAGAGCATTGGATCTCCACAAGGCGTTCCTGAACTTCCAAGTCTGGACGACATCACTGACAGCTTCTGTGACGACTTATTTAATTCGGTTTAG |
|
Protein Sequence
|
MLNSSSSTPPCIKPRHRIAKKREIRRRRVDLGCGCSIYVHINCTGHGFTHRGTHHCTSGREWRLYLGNNKSPLFQDMPSRGHHVHEDKSVPRSDTVQPQPQESIGSPQGVPELPSLDDITDSFCDDLFNSV |
|
NCBI Accession
|
YP_009508397.1
|
|
Location
|
1436-2521 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCACCCTCGCAGCGTTTTAAGGTTAACGCCAAAAATTATTTCCTCACTTATCCCAGGTGTTCCATCTCCAAAGAGGAGGCACTTTCCCAAATCCTAGCATTAAATACCCCAACTAAAAAGAAATATATCCGGATATGCAGAGAATTACACGAAGATGGAACACCTCATCTCCATGCTCTGCTGCAGTTCGAAGGGAAATTCCAGTGCACAAATAGTCGATTCTTCGACTTGCGACATCCCCAACATTCCAATGTCAGTCATGGAGATTACAAATCATGTAAATCCGCCTCCGACGCCAAATCATATATACAGAAGGACGGAGATTACATCGAATGGGGTACTTTTCAGATCGACGGAAGATGTGCTAGAGGAGGTCAACAGACAGCTAACGATGCAGCAGCAGAGGCGTTAAATGCTCCGGACAAACTAACGGCACTTCAAATTATCAGAGAGAAGTTGCCTGAGAAATATCTTTTTCAATTTCATAATTTAAATTCTAATTTAGATAGAATTTTCTCGAAGGCTCCGGAGCCATGGACTCCTCCGTTTCCCCTCTCTTCATTCACTAACGTTCCAGATGAGATGCAGGAATGGGCTGATGATTATTTTGGGAGGGGTGACGCTGCGCGTCCAGAACGACCTATTAGTTTGATTGTCGAAGGTGATAGTCGAACGGGGAAAACGATGTGGGCACGTGCTTTAGGACGACATAATTACTTGAGTGGACATCTAGATTTCAATTCTAGGGTTTACTCAAATCAAGTTGAGTATAACGTCATTGATGATGTCACACCCCATTATCTAAAGTTAAAGCACTGGAAAGAATTGATTGGTGCTCAGAAAGATTGGCAGTCAAATTGCAAGTACGGGAAACCTGTTCAAATTAAAGGGGGTATCCCATCAATCGTGCTCTGCAATCCTGGCGAGGGGGCTAGTTATAAAGATTTTCTGGAGAGAGAGGAAAATGCATCACTAAAAGGCTGGACACTCCACAATGCTAAATTCATCTTCCTCGACTCCCCCCTGTATCAAACCACGACACAGGATTGCCAAGAAGAGAGAAATCAGGCGACGACGAGTTGA |
|
Protein Sequence
|
MPPSQRFKVNAKNYFLTYPRCSISKEEALSQILALNTPTKKKYIRICRELHEDGTPHLHALLQFEGKFQCTNSRFFDLRHPQHSNVSHGDYKSCKSASDAKSYIQKDGDYIEWGTFQIDGRCARGGQQTANDAAAEALNAPDKLTALQIIREKLPEKYLFQFHNLNSNLDRIFSKAPEPWTPPFPLSSFTNVPDEMQEWADDYFGRGDAARPERPISLIVEGDSRTGKTMWARALGRHNYLSGHLDFNSRVYSNQVEYNVIDDVTPHYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLEREENASLKGWTLHNAKFIFLDSPLYQTTTQDCQEERNQATTS |
|
NCBI Accession
|
YP_009508398.1
|
|
Location
|
2107-2364 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGAACACCTCATCTCCATGCTCTGCTGCAGTTCGAAGGGAAATTCCAGTGCACAAATAGTCGATTCTTCGACTTGCGACATCCCCAACATTCCAATGTCAGTCATGGAGATTACAAATCATGTAAATCCGCCTCCGACGCCAAATCATATATACAGAAGGACGGAGATTACATCGAATGGGGTACTTTTCAGATCGACGGAAGATGTGCTAGAGGAGGTCAACAGACAGCTAACGATGCAGCAGCAGAGGCGTTAA |
|
Protein Sequence
|
MEHLISMLCCSSKGNSSAQIVDSSTCDIPNIPMSVMEITNHVNPPPTPNHIYRRTEITSNGVLFRSTEDVLEEVNRQLTMQQQRR |