Tomato yellow vein streak virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000874525.1 |
| Isolate |
Brazil |
| Release date |
2015/2/13 |
| Submitter |
Albuquerque,L.C., Martin,D.P., Avila,A.C., Inoue-Nagata,A.K., Ribeiro,S.G., Daniels,J., Fernandes-Carrijo,F.R. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
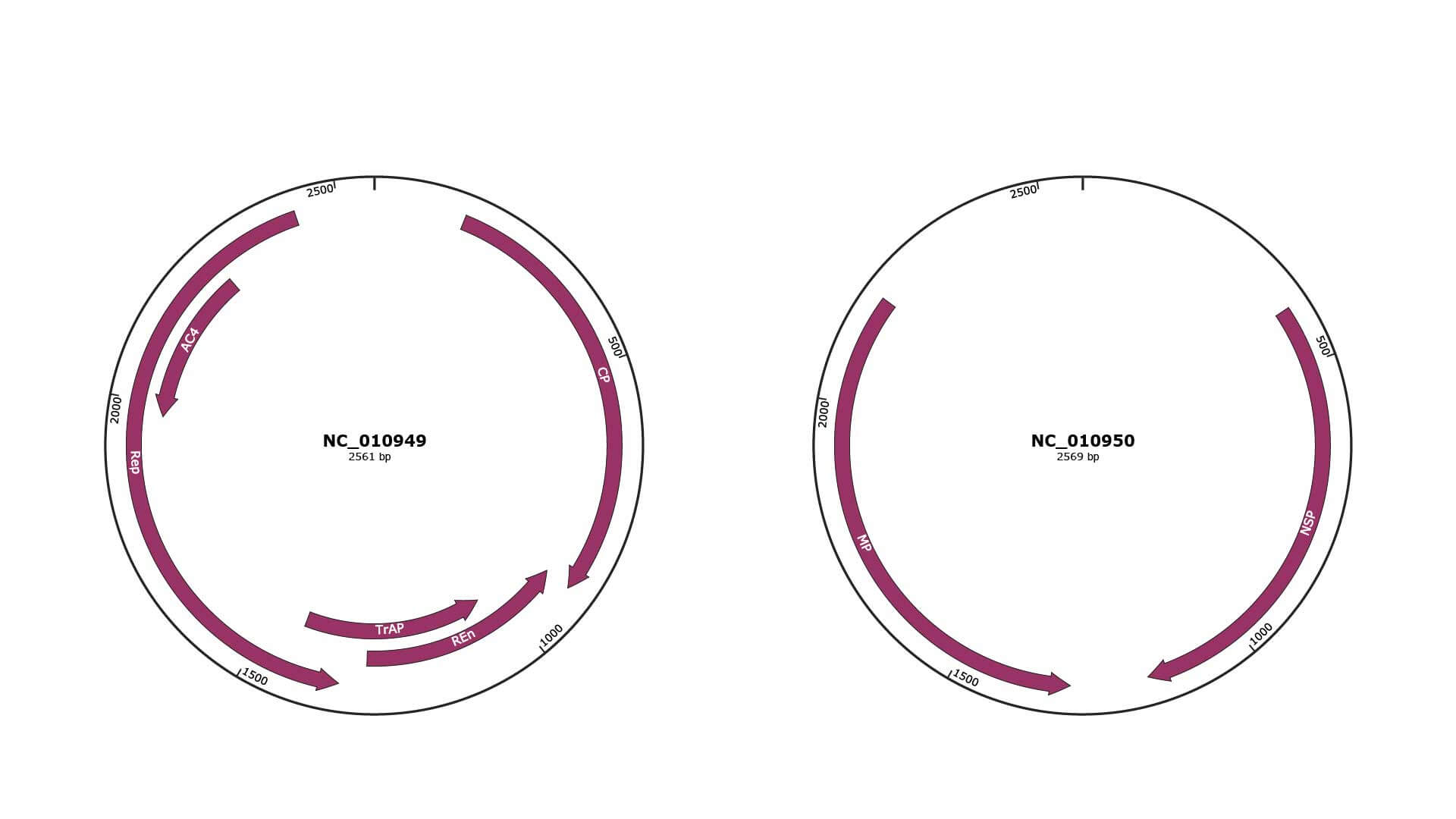
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTTTAGTGGTCCCCCTTTGAATGGCCAATCAGATTTTATCCTGAACTCTTAATTATTTTGAAATTCTTAGGCGCTAAGTTGTTAAAGTTATATATATTGGACATTCATTAGTGGTCGACATACTTTAATTCAAAATGCCAAAGCGGGATGCCCCATGGCGTATAATGGCGGGGACCACTAAAGTGTCCCGCTCTTCCAATTATTCACCTCGTGGAGGTATTTCCAAGCGGGATGCTTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATTTATCGAACGTTGAGAGGCCCTGATGTTCCTAAAGGGTGTGAAGGCCCATGTAAGGTCCAGTCCTACGAGCAGCGTCATGACATTTCTCATCTTGGCAAGGTGATGTGTATCTCTGATATCACACGTGGTAATTGTATTACACACCGTGTCGGTAAGCGTTTCTGTGTTAAGTCCGTATACATTTTAGGGAAGATATGGATGGACGAAAATATTAAATTGAAAAACCACACGAACAGCGTCATCTTCTGGTTGGTAAGGGATCGGAGACCGTATGGGACACCTATGGATTTTGGCCAAGTGTTTAATATGTTTGATAATGAGCCTAGTACTGCTACTGTGAAGAACGATCTTCGTGATCGGTTTCAAGTCATGCATAGGTTTAATGCTAAGGTTACGGGTGGACAGTATGCTAGCAACGAGCAAGCTCTTGTGCGGCGTTTCTGGAAGGTCAACAATCATGTGGTCTACAACCATCAGGAAGCAGGGAAATATGAGAATCACACGGAGAACGCTTTGTTATTGTATATGGCATGTACACATGCTTCTAACCCACTGTATGCAACTTTGAAAATTCGGATCTATTTTTATGATTCGATTACAAATTAATAAAGTCTAAATTTTATTGAATGATTTTCAAGTACATAATTTACATAAGATTTGTCTGTTGCGAAACGAACAGCTCTGATTACATTATTAACGGAAATAACACCTAATTGGTTTAAATACAATAAGACTAAATACTTAAATCTACTTAAATATGTCATCCCAGAAGCTCTCAGGGATGTCGTCCAGACTTGGAAATTGAGAAAAGCCTTGTGGAGATCCAACGCTTTCCGCAGGTTGTGGTTGAAACGTATCTGTAGATGGTATATCCGTGTCGTTGTGTAGAGGGGGTCCTCTACGTTGATTATCTTGAAATAGAGGGGATTGGTAATCTCCCAAATAAAGACGCCATTCGCTGCTTGAGGCGCAGTGATGAGTTCCCCGGTGCGTGAATCCATTGTTGCGACAGTTGAGATGGATGTAAATGGAGCAGCCGCAGTTTAGGTCAATGCGTCTTCGGCGAATTACCTTCCGTTTGGCTGCTCTGTGTCGTGGTTTGATAGAGGGGGGAGTTGAGGAAGATGTATTTAGCATTATGCAGTGTCCACGTTTTTAAAGATATATTTTCATGTTTGTCTAGGAAGTCTTTATAACTAGCCCCCTCTCCTGGATTGCAGAGCACGATTGATGGGATTCCTCCTTTAATTTGAACTGGCTTCCCGTATTTGCAGTTGCTTTGCCAGTCACGTTGGGCCCCAATGAGCTCTTTCCAATGTTTTAGCTTTAGGTATTGCGGAGTGACATCATCAATGACGTTATAATGCACCTCATTTGAATAAACCCTAGAATTAAAATCTAGATGTCCACTCAGATAATTATGTGGGCCTAATGCACGAGCCCACATCGTCTTTCCTGTACGACTATCACCCTCAATTATAATACTAATAGGTCTCTCCGGCCGCGCAGCGGCACCCCTTCCGAAATATTCGTCAGCCCACTCTTGCATCTCGTCAGGAACATTAGTGAAGGAGGAAAGTTGAAACGGAGAAACCCATGGCTCTGGAGCCTTTGCAAATATTCTCTGGACATGTGTTCTTATTTTATCCAGATGTAGAACATAATCTCGAGGTTGCTCTTCTTTTAATATATTGAGTGCCGTGGTTGGATTATCTGCGTTGAGAACCTTGGCATAAGTGTCGTTTGCAGATTGGCAACCTCCTCTAGCTGATCTTCCATCGATCTGGAAAGTTCCAAAATCAATGAAGTCTCCGTCTTTCTCCATGTAGGTCTTGACGTCTGACGAGCTTTTAGCTCCCTGAATGTTTGGATGGAAATGTGCTGATCTGGTTGGGGATACCAAATCGAAGAATCGTTGATTGTGGCATTTGAATTTGCCTTCGAACTGTATAAGCACGTGGAGATGAGGTTCCCCATCTTCGTGAAGTTCTCTGGTTACGCGAATAAATTTCTTGTTGGTAGGTGTTTGAAGTGCCTGTAATTGTGAAAGAGCTTCGTCTTTAGTTAATGAACAATGAGGATATGTAAGGAAGAAATTTTTTGCATTTACTAAGAAACGCTTTGGAAGGGGCATTTTAGTAATATAAAGAGTTGCTCCCCGATTGAGCTCCTTCAAACTTGGCAAATGAATTGGGGAAAGGGTCTCAATATATAGTAGAGTCCATTATAGAATATATTTGCCACGTGGCGGCCATCCGTTATAATATT
ACCGGATGGCCGCGCGATTTTTTTATGGTGGACCCCATGTGAATATAATTGAGCGCATTTTTGACGTCCGCGAATTTAGTTGAGCGCAAATTTTGAGTTCCGCCAGCTTATCAAGTCGTACAACTTTAATTTGAAATAAAGTAGAGATATTTTGCTTAACCAATGAATTCGCATCTGACGAGCTTATTTATTTGTTATAGTATTTATGAGTCATGACGTTGACTGATCGTTACTTGTGTGTCAGTTGAGATATATATGGCGAGTCATATCATTATACCGTGTGTTTCTATTTTTTACGTGGACCAATAGGTTATTGTTATGGAATGTTATTAAGTTACATATTAAAGTATGATTTTTATATATAAACTCCGTGATAATTGAAATAGATATCAACATATAACATGTATATTAATAAGTATAGACGTGGCTGGATATCTAATCAACGACGAGGCTATTCACGTCAGTCTTTCTTCAAGCGTTCTTATTATGTTAAACGTACAGATGGGAAACGTCGATCGAGTAGCACGACTCAAGTCAATGAGGAGAGCAGATTGTCACAACAGCGAATTCATGAGAACCAGTTTGGTCCAGAATTTGTAATGGTTCATAATACAGCCGTATCAACCTTTATTACTTTCCCCAATCTTGGTAAAACTGAACCGAATCGATCTAGGTCATATATAAAGTTGAAACGTTTGCGTTTCAAAGGTACTGTTAAAATTGAACGTTTGCATACTGATATGAAAATGGACTGTATAATTCCAAATATCGAAGGAGTGTTTTCGTTGGTCATCGTAGTTGATCGTAAACCCCATTTGAATCCAACAGGATGTCTACATACATTTGATGAGCTATTTGGTGCACGAATACACAGTCATGGCAATTTAGCTATAACCGCATCTCTGAAAGACCGATTTTACATACGTCATGTTTGGAAGAAAGTAATATCTGTTGAGAAAGATAGCATGATGGTTGATCTTGAAGGAACGACATCACTATCTAACAAGCGTTATAATTGTTGGTCAGCTTTTAAGGATCTTGATCATGATTCATGTAATGGGGTTTATGCGAATATAAGCAAGAACGCCCTTTTAGTTTACTATTGTTGGATGTCTGATACCATGTCTACAGCATCCTCATTTGTATCGTTTGATCTTGATTATGTGGGTTAAATAATAATATTATGAGCTATAATTACAGTCAGACTTACATAAGAGATTCAATCACTCAAGAAAACCTTATAAGATAATAATAATTATCTGTGGCTGCGCAGCTGAATATACCCACCATAAAAAACTAGATATTTTATTTCAAAGATTTGGGCTGTGAAGGAATACAATTAGTTTTAATACATTCTTGGACCGTCGTCCTAACAAGATCGTTTAATTGGGCCATTGATAGTGTTATATTCGATTGCGTTCTTTGGGCCCCAATTATTGAAGCCGAATCACCTGGGTCTAAGATGGCAGTGCCCAACCTGTTAAGATCCTTGTATGGATGTAACACTTCAGCAATATCTGATTCTGCTTCTAACTGGGCCGGCCCTATTGTACTCCGTGTGGCCCAAGACTCTCCTGGGTTTAATTCTATTGGGCCGGGAAGCCCAAATCTAGAAGTGGATGCGGATCTTATCAATTTCCTCTCCCACTTCCCATAACCCACATGAGAAAAGTCGATGTCATTTACGGTAAATTGTTTGGACATTATCTTTACTGTGGGTGCTCTGAAAGGTATATCAACCGAATGTTTTGCAGTTGATAGCTTCAGCTTCCCTTTGAATTTTGCGAAGTGTGTCATCTGATGAACATTTGAATCACAAACCTTATAATATAGCTTCCATGGAATTGGGTCTTTGAGGGAGAAGAATGACGATGAGAAATAGTGGAGATCTATGTTGCATCTTATAGGAAAAGTCCATGACGCCTGTAATGATTCATTTTCAGTCATCCTCTGGTCATGAATCTCCACAATTACTGATCCTGTTGCGTTTATGGGTACCTGTTGCCTATATTCTATGACGCAATGGTCAATCTTCATACAGCTTCTATTTAGTCTTGCACTTAATTGAGTCGCTTTTGAAGGAAACTGCAATATGATTTCCGTAAGGTCGTGAGATAGCTGATATTCATCACGACGAGATTCTATATAATTAAAGGCGTTTGGTGGGCAAACTATTTGAGAATCCATATATCTTAAATATGGCTAAGCAGCGATAACGTTTATGTAACTGAGTGGGAGAGGAAAATAAGATATAAATATTTGAAGGATAATTTAGTTGTGAGAGAAAACAATGAAATGAATGATAATATATTATGAAGAAGCTGCTATTCTTATATAGACATTGAACTGGTTATAGAGAGTCTGGTTAATTAATAATAAGGATATGTATTGAAGAAATATGTTGAGTTTATGGTAAAACCCTTTGATGGGGGTTTATTTGTAAATATGAGAGTTGCTCCCCGATTGAGCTCCTTCAAACTTGGCAAATGAATTGGGGAAAGGGTCTCAATATATAGTAGAGTCCATTATAGAATATATTTGCCACGTGGCGGCCATCCGTTATAATATT
Gene Information
|
NCBI Accession
|
YP_001974404.1
|
|
Location
|
156-899 |
|
Gene Name
|
CP |
|
Protein Name
|
AV1 |
|
Coding Region
|
ATGCCAAAGCGGGATGCCCCATGGCGTATAATGGCGGGGACCACTAAAGTGTCCCGCTCTTCCAATTATTCACCTCGTGGAGGTATTTCCAAGCGGGATGCTTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATTTATCGAACGTTGAGAGGCCCTGATGTTCCTAAAGGGTGTGAAGGCCCATGTAAGGTCCAGTCCTACGAGCAGCGTCATGACATTTCTCATCTTGGCAAGGTGATGTGTATCTCTGATATCACACGTGGTAATTGTATTACACACCGTGTCGGTAAGCGTTTCTGTGTTAAGTCCGTATACATTTTAGGGAAGATATGGATGGACGAAAATATTAAATTGAAAAACCACACGAACAGCGTCATCTTCTGGTTGGTAAGGGATCGGAGACCGTATGGGACACCTATGGATTTTGGCCAAGTGTTTAATATGTTTGATAATGAGCCTAGTACTGCTACTGTGAAGAACGATCTTCGTGATCGGTTTCAAGTCATGCATAGGTTTAATGCTAAGGTTACGGGTGGACAGTATGCTAGCAACGAGCAAGCTCTTGTGCGGCGTTTCTGGAAGGTCAACAATCATGTGGTCTACAACCATCAGGAAGCAGGGAAATATGAGAATCACACGGAGAACGCTTTGTTATTGTATATGGCATGTACACATGCTTCTAACCCACTGTATGCAACTTTGAAAATTCGGATCTATTTTTATGATTCGATTACAAATTAA |
|
Protein Sequence
|
MPKRDAPWRIMAGTTKVSRSSNYSPRGGISKRDAWVNRPMYRKPRIYRTLRGPDVPKGCEGPCKVQSYEQRHDISHLGKVMCISDITRGNCITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVIFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHRFNAKVTGGQYASNEQALVRRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPLYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_001974405.1
|
|
Location
|
896-1294 |
|
Gene Name
|
REn |
|
Protein Name
|
AC3 |
|
Coding Region
|
ATGGATTCACGCACCGGGGAACTCATCACTGCGCCTCAAGCAGCGAATGGCGTCTTTATTTGGGAGATTACCAATCCCCTCTATTTCAAGATAATCAACGTAGAGGACCCCCTCTACACAACGACACGGATATACCATCTACAGATACGTTTCAACCACAACCTGCGGAAAGCGTTGGATCTCCACAAGGCTTTTCTCAATTTCCAAGTCTGGACGACATCCCTGAGAGCTTCTGGGATGACATATTTAAGTAGATTTAAGTATTTAGTCTTATTGTATTTAAACCAATTAGGTGTTATTTCCGTTAATAATGTAATCAGAGCTGTTCGTTTCGCAACAGACAAATCTTATGTAAATTATGTACTTGAAAATCATTCAATAAAATTTAGACTTTATTAA |
|
Protein Sequence
|
MDSRTGELITAPQAANGVFIWEITNPLYFKIINVEDPLYTTTRIYHLQIRFNHNLRKALDLHKAFLNFQVWTTSLRASGMTYLSRFKYLVLLYLNQLGVISVNNVIRAVRFATDKSYVNYVLENHSIKFRLY |
|
NCBI Accession
|
YP_001974406.1
|
|
Location
|
1041-1430 |
|
Gene Name
|
TrAP |
|
Protein Name
|
AC2 |
|
Coding Region
|
ATGCTAAATACATCTTCCTCAACTCCCCCCTCTATCAAACCACGACACAGAGCAGCCAAACGGAAGGTAATTCGCCGAAGACGCATTGACCTAAACTGCGGCTGCTCCATTTACATCCATCTCAACTGTCGCAACAATGGATTCACGCACCGGGGAACTCATCACTGCGCCTCAAGCAGCGAATGGCGTCTTTATTTGGGAGATTACCAATCCCCTCTATTTCAAGATAATCAACGTAGAGGACCCCCTCTACACAACGACACGGATATACCATCTACAGATACGTTTCAACCACAACCTGCGGAAAGCGTTGGATCTCCACAAGGCTTTTCTCAATTTCCAAGTCTGGACGACATCCCTGAGAGCTTCTGGGATGACATATTTAAGTAG |
|
Protein Sequence
|
MLNTSSSTPPSIKPRHRAAKRKVIRRRRIDLNCGCSIYIHLNCRNNGFTHRGTHHCASSSEWRLYLGDYQSPLFQDNQRRGPPLHNDTDIPSTDTFQPQPAESVGSPQGFSQFPSLDDIPESFWDDIFK |
|
NCBI Accession
|
YP_001974407.1
|
|
Location
|
1342-2427 |
|
Gene Name
|
Rep |
|
Protein Name
|
AC1 |
|
Coding Region
|
ATGCCCCTTCCAAAGCGTTTCTTAGTAAATGCAAAAAATTTCTTCCTTACATATCCTCATTGTTCATTAACTAAAGACGAAGCTCTTTCACAATTACAGGCACTTCAAACACCTACCAACAAGAAATTTATTCGCGTAACCAGAGAACTTCACGAAGATGGGGAACCTCATCTCCACGTGCTTATACAGTTCGAAGGCAAATTCAAATGCCACAATCAACGATTCTTCGATTTGGTATCCCCAACCAGATCAGCACATTTCCATCCAAACATTCAGGGAGCTAAAAGCTCGTCAGACGTCAAGACCTACATGGAGAAAGACGGAGACTTCATTGATTTTGGAACTTTCCAGATCGATGGAAGATCAGCTAGAGGAGGTTGCCAATCTGCAAACGACACTTATGCCAAGGTTCTCAACGCAGATAATCCAACCACGGCACTCAATATATTAAAAGAAGAGCAACCTCGAGATTATGTTCTACATCTGGATAAAATAAGAACACATGTCCAGAGAATATTTGCAAAGGCTCCAGAGCCATGGGTTTCTCCGTTTCAACTTTCCTCCTTCACTAATGTTCCTGACGAGATGCAAGAGTGGGCTGACGAATATTTCGGAAGGGGTGCCGCTGCGCGGCCGGAGAGACCTATTAGTATTATAATTGAGGGTGATAGTCGTACAGGAAAGACGATGTGGGCTCGTGCATTAGGCCCACATAATTATCTGAGTGGACATCTAGATTTTAATTCTAGGGTTTATTCAAATGAGGTGCATTATAACGTCATTGATGATGTCACTCCGCAATACCTAAAGCTAAAACATTGGAAAGAGCTCATTGGGGCCCAACGTGACTGGCAAAGCAACTGCAAATACGGGAAGCCAGTTCAAATTAAAGGAGGAATCCCATCAATCGTGCTCTGCAATCCAGGAGAGGGGGCTAGTTATAAAGACTTCCTAGACAAACATGAAAATATATCTTTAAAAACGTGGACACTGCATAATGCTAAATACATCTTCCTCAACTCCCCCCTCTATCAAACCACGACACAGAGCAGCCAAACGGAAGGTAATTCGCCGAAGACGCATTGA |
|
Protein Sequence
|
MPLPKRFLVNAKNFFLTYPHCSLTKDEALSQLQALQTPTNKKFIRVTRELHEDGEPHLHVLIQFEGKFKCHNQRFFDLVSPTRSAHFHPNIQGAKSSSDVKTYMEKDGDFIDFGTFQIDGRSARGGCQSANDTYAKVLNADNPTTALNILKEEQPRDYVLHLDKIRTHVQRIFAKAPEPWVSPFQLSSFTNVPDEMQEWADEYFGRGAAARPERPISIIIEGDSRTGKTMWARALGPHNYLSGHLDFNSRVYSNEVHYNVIDDVTPQYLKLKHWKELIGAQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLDKHENISLKTWTLHNAKYIFLNSPLYQTTTQSSQTEGNSPKTH |
|
NCBI Accession
|
YP_001974408.1
|
|
Location
|
1977-2270 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGGAACCTCATCTCCACGTGCTTATACAGTTCGAAGGCAAATTCAAATGCCACAATCAACGATTCTTCGATTTGGTATCCCCAACCAGATCAGCACATTTCCATCCAAACATTCAGGGAGCTAAAAGCTCGTCAGACGTCAAGACCTACATGGAGAAAGACGGAGACTTCATTGATTTTGGAACTTTCCAGATCGATGGAAGATCAGCTAGAGGAGGTTGCCAATCTGCAAACGACACTTATGCCAAGGTTCTCAACGCAGATAATCCAACCACGGCACTCAATATATTAA |
|
Protein Sequence
|
MGNLISTCLYSSKANSNATINDSSIWYPQPDQHISIQTFRELKARQTSRPTWRKTETSLILELSRSMEDQLEEVANLQTTLMPRFSTQIIQPRHSIY |
|
NCBI Accession
|
YP_001974409.1
|
|
Location
|
402-1172 |
|
Gene Name
|
NSP |
|
Protein Name
|
BV1 |
|
Coding Region
|
ATGTATATTAATAAGTATAGACGTGGCTGGATATCTAATCAACGACGAGGCTATTCACGTCAGTCTTTCTTCAAGCGTTCTTATTATGTTAAACGTACAGATGGGAAACGTCGATCGAGTAGCACGACTCAAGTCAATGAGGAGAGCAGATTGTCACAACAGCGAATTCATGAGAACCAGTTTGGTCCAGAATTTGTAATGGTTCATAATACAGCCGTATCAACCTTTATTACTTTCCCCAATCTTGGTAAAACTGAACCGAATCGATCTAGGTCATATATAAAGTTGAAACGTTTGCGTTTCAAAGGTACTGTTAAAATTGAACGTTTGCATACTGATATGAAAATGGACTGTATAATTCCAAATATCGAAGGAGTGTTTTCGTTGGTCATCGTAGTTGATCGTAAACCCCATTTGAATCCAACAGGATGTCTACATACATTTGATGAGCTATTTGGTGCACGAATACACAGTCATGGCAATTTAGCTATAACCGCATCTCTGAAAGACCGATTTTACATACGTCATGTTTGGAAGAAAGTAATATCTGTTGAGAAAGATAGCATGATGGTTGATCTTGAAGGAACGACATCACTATCTAACAAGCGTTATAATTGTTGGTCAGCTTTTAAGGATCTTGATCATGATTCATGTAATGGGGTTTATGCGAATATAAGCAAGAACGCCCTTTTAGTTTACTATTGTTGGATGTCTGATACCATGTCTACAGCATCCTCATTTGTATCGTTTGATCTTGATTATGTGGGTTAA |
|
Protein Sequence
|
MYINKYRRGWISNQRRGYSRQSFFKRSYYVKRTDGKRRSSSTTQVNEESRLSQQRIHENQFGPEFVMVHNTAVSTFITFPNLGKTEPNRSRSYIKLKRLRFKGTVKIERLHTDMKMDCIIPNIEGVFSLVIVVDRKPHLNPTGCLHTFDELFGARIHSHGNLAITASLKDRFYIRHVWKKVISVEKDSMMVDLEGTTSLSNKRYNCWSAFKDLDHDSCNGVYANISKNALLVYYCWMSDTMSTASSFVSFDLDYVG |
|
NCBI Accession
|
YP_001974410.1
|
|
Location
|
1306-2187 |
|
Gene Name
|
MP |
|
Protein Name
|
BC1 |
|
Coding Region
|
ATGGATTCTCAAATAGTTTGCCCACCAAACGCCTTTAATTATATAGAATCTCGTCGTGATGAATATCAGCTATCTCACGACCTTACGGAAATCATATTGCAGTTTCCTTCAAAAGCGACTCAATTAAGTGCAAGACTAAATAGAAGCTGTATGAAGATTGACCATTGCGTCATAGAATATAGGCAACAGGTACCCATAAACGCAACAGGATCAGTAATTGTGGAGATTCATGACCAGAGGATGACTGAAAATGAATCATTACAGGCGTCATGGACTTTTCCTATAAGATGCAACATAGATCTCCACTATTTCTCATCGTCATTCTTCTCCCTCAAAGACCCAATTCCATGGAAGCTATATTATAAGGTTTGTGATTCAAATGTTCATCAGATGACACACTTCGCAAAATTCAAAGGGAAGCTGAAGCTATCAACTGCAAAACATTCGGTTGATATACCTTTCAGAGCACCCACAGTAAAGATAATGTCCAAACAATTTACCGTAAATGACATCGACTTTTCTCATGTGGGTTATGGGAAGTGGGAGAGGAAATTGATAAGATCCGCATCCACTTCTAGATTTGGGCTTCCCGGCCCAATAGAATTAAACCCAGGAGAGTCTTGGGCCACACGGAGTACAATAGGGCCGGCCCAGTTAGAAGCAGAATCAGATATTGCTGAAGTGTTACATCCATACAAGGATCTTAACAGGTTGGGCACTGCCATCTTAGACCCAGGTGATTCGGCTTCAATAATTGGGGCCCAAAGAACGCAATCGAATATAACACTATCAATGGCCCAATTAAACGATCTTGTTAGGACGACGGTCCAAGAATGTATTAAAACTAATTGTATTCCTTCACAGCCCAAATCTTTGAAATAA |
|
Protein Sequence
|
MDSQIVCPPNAFNYIESRRDEYQLSHDLTEIILQFPSKATQLSARLNRSCMKIDHCVIEYRQQVPINATGSVIVEIHDQRMTENESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYKVCDSNVHQMTHFAKFKGKLKLSTAKHSVDIPFRAPTVKIMSKQFTVNDIDFSHVGYGKWERKLIRSASTSRFGLPGPIELNPGESWATRSTIGPAQLEAESDIAEVLHPYKDLNRLGTAILDPGDSASIIGAQRTQSNITLSMAQLNDLVRTTVQECIKTNCIPSQPKSLK |