Tomato yellow mottle virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000904935.1 |
| Isolate |
Costa Rica |
| Release date |
2015/2/22 |
| Submitter |
Maliano,M.R., Melgarejo,T., Rojas,M., Barboza,N., Gilbertson,R.L. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
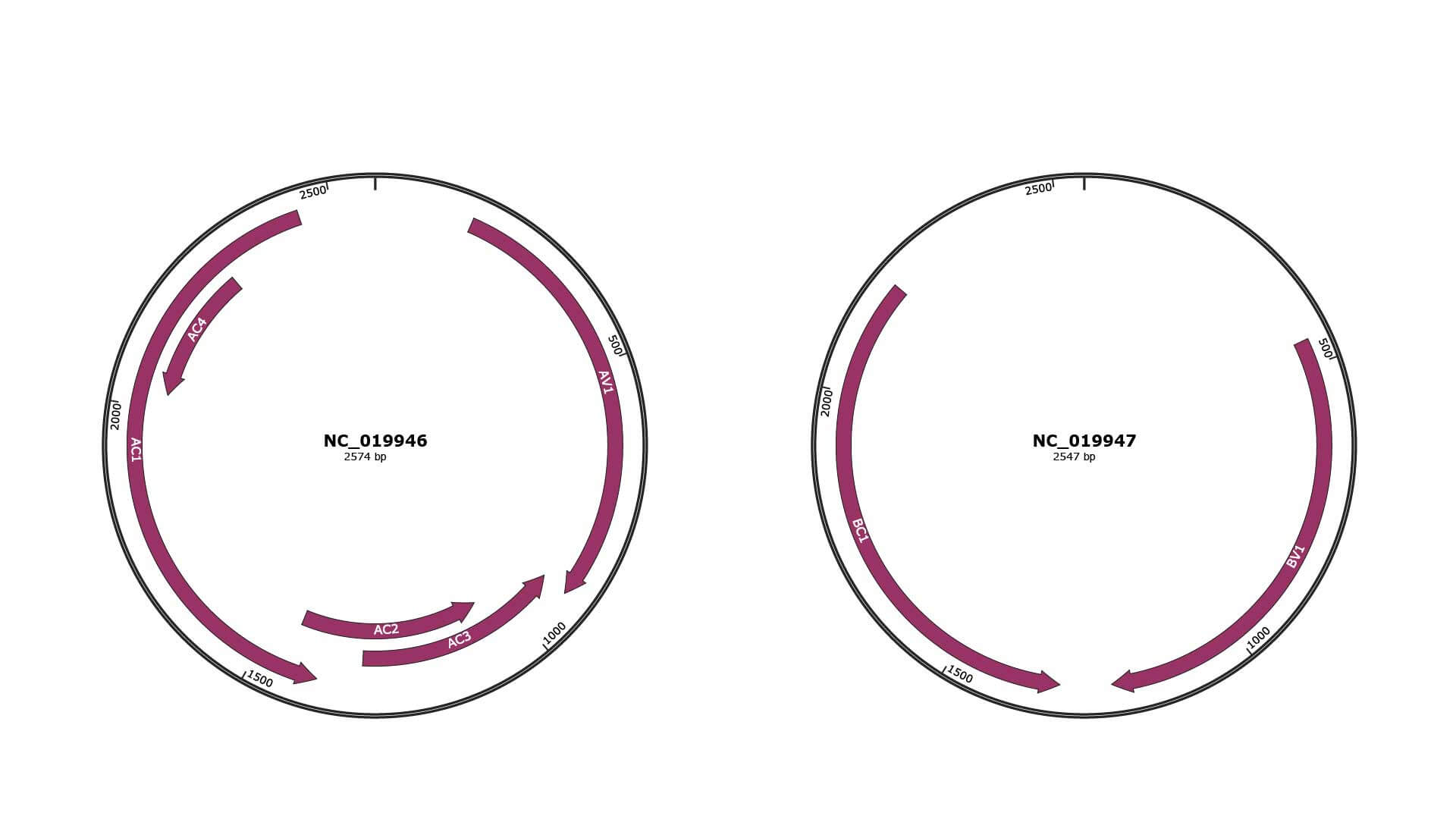
JBrowse
Genome
ACCGGATGGCCGCGTGCCCCGACCCGCTTCCGTAAAGTGCGCTGGGACCACAACTAAAAACACGACGTCCAATCACATCACGTCTGACGAGTCTAGATATTAAGACTTGCTGACTAAGTTGTGGGCCTATAAAACAATAATTGGTTCCATTTTGATCTTTAATTCAAAATGCCTAAGCGGGATGCCCCTTGGCGTTTAAGCGCGGGGACCACTAAGGTCTCCCGCTCTAGTAATTATTCTCCAAATGGAGGTATGGGCCCTAAGGCCACTTCTTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATCTATCGCACGTTGAGAGGCCCTGATGTGCCCAAAGGCTGCGAAGGTCCCTGTAAGGTCCAGTCCTACGAGCAGCGTCATGACGTCTCTCATGTTGGTAAAGTCATGTGCATCTCAGACATCACACGAGGTGGTGGTATTACCCACCGTGTAGGTAAACGTTTTTGCGTTAAGTCTGTTTACATTTTAGGGAAGGTATGGATGGACGATAACATCAAGTTGAAGAACCACACGAATAGTGTTATGTTCTGGCTGGTTAGAGACCGGAGACCCTATGGCACCCCTATGGATTTTGGTCAAGTGTTCAACATGTACGACAATGAGCCCAGTACAGCCACTGTTAAGAACGATCTTCGTGATCGTTTTCAAGTGCTACACAAGTTCTACGCCAAGGTCACGGGTGGACAGTATGCCAGCAATGAGCAGGCGTTGGTCAAGCGTTTCTGGAAGGTTAACAACCATGTCGTCTATAACCATCAAGAAGCAGGGAAATACGAGAATCACACTGAGAATGCTTTGTTATTGTACATGGCATGTACTCATGCCTCTAATCCTGTGTATGCAACATTAAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAATAAAGATTTACTTTTATTTCATGATTCTCAAGTACATGATTTACATATGCCTTGTCTGTTGCGAAACGAACAGCTCTAATTACATTGTTAATCCCAATAACACCTATTCTATCTAAATACAGTAAAACTAAATACTTAAATCTATTTAAGTAAGTCTTCCCAGAAGCTCGAATTGATGTCGTCCAGACTTGGAAGTTCAGAAAAGCTTTGTGAAGATTCAGTGCCCTCCTGAGGTTGTGGTTGCACCTGATTTGAATGTGGTAGATTCTGGTCGATGTGTAAAGTGGCTCTTCTACTCGACACATCCTGAAATAGAGGGGATTTGGAACATCCCAAATAAAAACGGAATTCTCTGCCTGATGCGCAGTGATGCTCTCCCCTGTGCGTGAATCCATTGTTGGAGCAGTTGATGTGTAGGAATATTGAACAGCCACAGTTTAGGTCTATACGTTTCCTACGTATTGCTCTTCTCTTAGCGTTCCTGTGATGAGGTTTGATAGAGGGGGGAGTTGAGGAAGATGAATTTAGCATTTTTGAGAGTCCACTGTTTTAGTGACGCATTTTCCTCTTTGTCGAGGAAATCTTTATAGCTCCCCCCGTCTCCTGGATTGCACAGCACGATTGATGGTATGCCCCCTTTAATTTGAACTGGCTTGCCGTACTTACAGTTGGACTGCCAATCTTTCTGGGCCCCAATCAACTCTTTCCAGTGCTTTAACTTTAAGTAGTGCGGTGCGACGTCATCGATGACGTTATATTCCACTTCGTTCGAGTAAACCCTAGAATTGAAATCTAAATGACCACTCAAGTAATTATGTGGGCCTAAAGAACGAGCCCACATTGTCTTCCCTGTTCTTGAATCACCCTCGACGATGATACTAATAGGTCTTTCCGGCCGCGCAGCGGCACCTCTTCCAAAATAATCATCAGCCCATTCCTGCATCTCGTCAGGAACAGCGTTGAATGATGAGAGTTGAAACGGAGGAACCCATGGTTCTGGAGCCTTTTGAAAGATCCTATTTGCATTATTGACCAAATTATGATAATGAAGAAAATAATGAGCAGGTTGTTCTTCTTTTAAAATTTGTAGTGCAGATTCAGCAGACCCAGCGTTTAACGCTTTTGCATATGAATCATTGGTTGTCTGTATACCTCCTCTACTTGATCTTCCATCGATCTGGAAAACTCCAAAATCAAGGAATTCTCCGTCTTTCTCCATGTATGATTTAACGTCTGAGCTGCTCTTAGCTCCCTGAATGTTCGGATGGAAATATGCTGATCTGCTTGTGGAACTGAGGTCGAAGAGTTTCTGGTTGTATATTTGGACTTTACCCTCGAGTTGTATAAGCACATGGAGATGAGGTTCCCCATCTTCGTGGAGTTCCCTTGCGACACGAATGAATAATTTATTCGAAGGTAGAGAGATATTCTGGAGTTGAAAGAGAGCCTCTTCTTTTGTTAAAGAACAGCGAGGATATGTTAAGAATATATTTTTAGCCGATAGTCTAAATTTTTTCGGCGGGGGCATTTTTGTAATAAAGAGCGTAACACCAATTGGGTTCCTCTCCAAAATGTCTAAGCAATTGGTGTTTTGGTGTTGAATTTATACTACAACTCTCAATACTAGAACTCTCCAAAAGCGGCCATCCGTATAATATT
ACCGGATGGCCGCCCGATTGTTTGTGCCTCTCTGGATGGTCGCCACGTGCCCCTTGGAGTGCTTTATATACTATTGGGCCTTCTGTTGAATAAGGCCCAGGCCCATTTATGGTGCTGTATTACAATTATTTCGGGACCACTAAAAATGACAAGGACAGCTGACCAATTACTCAGCAACTTCCGAGTTAAATTATTAACGACTTTATTACTACTTTATGTTTAATGATTTTTGTGAGGACCAGCTTTGTCATTTTTACATGAATTTGAATTAACTTGGCGCGACCTCAAATTGCTGTAATTATGTGGACCTACCATGTTAATGGATAATGTAGTACGACATAACCAATTAAATTTCAGCTACAACATCAAGTTACATTTCTATATCTGTGACATATTAATTTAAATAGTTAACCAAGTGTACAGGTTGACATCTCAATTGATTATCATTTTGTGAATATGTATCATTCTAGATACAGGCGCACCTGGTTATCTACACAACGTCGAGCATATAATCGACAACCACCGTTTAAGCGTCTATATACTTCGAGACGTAATGAACTTAAACGTCGTCCCATTAGCGATGTTATTGCTTATGACGATAAGAAGATGTCTGCTCAGCGTATACATGAGGATCAATTTGGACCAGAATTCGTTATGTTGCATAATACAGCTTTTTCAACTTATGTTACTTATCCCAGCATAGTGAAGAATGTACCTAACAGAGTTAAGTCATATATTAAGATAAAACGGTTACGTTTTAAGGGGACTTTGAAGATAGAACGTGTACATGCAGATGTTAACATGGACTGTCCAGTTTCTAAGATAGAAGGAGTGTTCTCTATGGTTATTGTGGTTGATCGTAAACCACATTTGAACGCAACAGGATGTCTACTGACGTTTGACGAGTTATTTGGGGCTAGGATTCATAGTCATGGTAATCTAGCTATAACTCCAGCCTTGAAAGATCGTTTTTATATTCGTCATGTATTGAAACGAGTATTATCGGTTGAGAAAGATAGCTTGATGGTGGACCTTGAAGGAACGACAACGTTTTCTAGCAAACGATTTAGTTGTTGGTCTTCTTTTAACGACCTTGAGCGAGATTCATGTAATGGTGTTTATGCTAATATTAGCAAGAACGCTATCTTGGTGTATTATTGCTGGATGTCAGACGTAATGTCTAAGGCATCAACATTTGTATCATTCGATCTCGACTATGTTGGCTAAATAAAAATGTTTTTGTTGTACGTTTATTTATTTCAGCTAATTAAACATTGACAAGAGGCTTATAAGAATAATAGAAATATAATATTTTCATTTCAAAGATTTGGGCACGGGAGGAACACAGTTTGTGTTAATACACTCTTGAACAGTTGACCTGACAATGTCATTTAACTGTGACATAGACATTGTTAAGTTGGACTCCGTTCGCTGAATCCCAATTACTGACGCAGAATCACCTGGGTCTAAAATAGGGGTGCTTAATCTGTTCAGCTCTCTGTAAGGGTATAGTGCGTCAGTAACCTCCGATTCCGCATTTGAATGGGCTGTTCCTATGGTACTTCTACTAGCCCAAGATTCCCCAGGCCTTATTTCTATTGGGCCTGGTAGCCCAATTATTCGTGACGATGCGGAACGGACTAGTCTTCTCTCCCACTTTCCGAAACCCACGTGATGGAAATCAATATCCTTCTCCGTAAACTGTTTCGACAAGATCCTGACCGTGGGTGCTCGGAAAGGTATATCCACTGAATTTTTCGCAGTAGACAGTTTGAGTTTCCCTTTGAACTTGGCGAAGTGCGTCCTTTGGTGTACATTCGAGTCACTGACCTTGTAATATAACTTCCAAGGTATAGGATCTTTTAACGAGAAGAACGACGATGAAAAATAATGTAGATCTATGTTACATCTGATCGGAAATGTCCACGACGCTTGTAATGACTCATTGTCCTGCATCCTTTTGTCATGGATCTCCACTATCACCGTTCCAGATGCGTTAATAGGCACTTGTTGCCTGTATTCAATGACGCAGTGGTCTATTTTCATACAGCTGCGACTCAATCGAGCACTTAGCTGAGCCGCCGTCGACGGAAACTGCAAGACAATTTCAGTTAGGTCATGAGAAAGCTGATACTCTTCACGATGAGAGTCTATGTAATTAAAGGCATTAGGAGGAATGACTAGCTGAGAATCCATATATGAAGAGTAGGCCGCGCAGCGGAATTGCTTGCCGGAGTGTAACAGCCGACGACCTATTTGAAGAGTGGAATAGAGATAAGTGAAGAAAACTACGAAATATGTGTAATAAATATGTTTAAATTATTTATATTATAAACAACTCAAGTGGTATACCCCTATATATAGACAATTATGAGTAATAAATTATTTCAGTGTTGAAGATAATATCGAGGGGCATTTTTGTAATAAAGAGCGTAACACCAATTGGGTTCCTCTCCAAAATGTCTAAGCAATTGGTGTTTTGGTGTTGAATTTATACTACAACTCTCAATACTAGAACTCTCCAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_007250558.1
|
|
Location
|
169-915 |
|
Gene Name
|
AV1 |
|
Protein Name
|
capsid protein |
|
Coding Region
|
ATGCCTAAGCGGGATGCCCCTTGGCGTTTAAGCGCGGGGACCACTAAGGTCTCCCGCTCTAGTAATTATTCTCCAAATGGAGGTATGGGCCCTAAGGCCACTTCTTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATCTATCGCACGTTGAGAGGCCCTGATGTGCCCAAAGGCTGCGAAGGTCCCTGTAAGGTCCAGTCCTACGAGCAGCGTCATGACGTCTCTCATGTTGGTAAAGTCATGTGCATCTCAGACATCACACGAGGTGGTGGTATTACCCACCGTGTAGGTAAACGTTTTTGCGTTAAGTCTGTTTACATTTTAGGGAAGGTATGGATGGACGATAACATCAAGTTGAAGAACCACACGAATAGTGTTATGTTCTGGCTGGTTAGAGACCGGAGACCCTATGGCACCCCTATGGATTTTGGTCAAGTGTTCAACATGTACGACAATGAGCCCAGTACAGCCACTGTTAAGAACGATCTTCGTGATCGTTTTCAAGTGCTACACAAGTTCTACGCCAAGGTCACGGGTGGACAGTATGCCAGCAATGAGCAGGCGTTGGTCAAGCGTTTCTGGAAGGTTAACAACCATGTCGTCTATAACCATCAAGAAGCAGGGAAATACGAGAATCACACTGAGAATGCTTTGTTATTGTACATGGCATGTACTCATGCCTCTAATCCTGTGTATGCAACATTAAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAA |
|
Protein Sequence
|
MPKRDAPWRLSAGTTKVSRSSNYSPNGGMGPKATSWVNRPMYRKPRIYRTLRGPDVPKGCEGPCKVQSYEQRHDVSHVGKVMCISDITRGGGITHRVGKRFCVKSVYILGKVWMDDNIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMYDNEPSTATVKNDLRDRFQVLHKFYAKVTGGQYASNEQALVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_007250559.1
|
|
Location
|
912-1310 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAGAGCATCACTGCGCATCAGGCAGAGAATTCCGTTTTTATTTGGGATGTTCCAAATCCCCTCTATTTCAGGATGTGTCGAGTAGAAGAGCCACTTTACACATCGACCAGAATCTACCACATTCAAATCAGGTGCAACCACAACCTCAGGAGGGCACTGAATCTTCACAAAGCTTTTCTGAACTTCCAAGTCTGGACGACATCAATTCGAGCTTCTGGGAAGACTTACTTAAATAGATTTAAGTATTTAGTTTTACTGTATTTAGATAGAATAGGTGTTATTGGGATTAACAATGTAATTAGAGCTGTTCGTTTCGCAACAGACAAGGCATATGTAAATCATGTACTTGAGAATCATGAAATAAAAGTAAATCTTTATTAA |
|
Protein Sequence
|
MDSRTGESITAHQAENSVFIWDVPNPLYFRMCRVEEPLYTSTRIYHIQIRCNHNLRRALNLHKAFLNFQVWTTSIRASGKTYLNRFKYLVLLYLDRIGVIGINNVIRAVRFATDKAYVNHVLENHEIKVNLY |
|
NCBI Accession
|
YP_007250560.1
|
|
Location
|
1057-1446 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCTAAATTCATCTTCCTCAACTCCCCCCTCTATCAAACCTCATCACAGGAACGCTAAGAGAAGAGCAATACGTAGGAAACGTATAGACCTAAACTGTGGCTGTTCAATATTCCTACACATCAACTGCTCCAACAATGGATTCACGCACAGGGGAGAGCATCACTGCGCATCAGGCAGAGAATTCCGTTTTTATTTGGGATGTTCCAAATCCCCTCTATTTCAGGATGTGTCGAGTAGAAGAGCCACTTTACACATCGACCAGAATCTACCACATTCAAATCAGGTGCAACCACAACCTCAGGAGGGCACTGAATCTTCACAAAGCTTTTCTGAACTTCCAAGTCTGGACGACATCAATTCGAGCTTCTGGGAAGACTTACTTAAATAG |
|
Protein Sequence
|
MLNSSSSTPPSIKPHHRNAKRRAIRRKRIDLNCGCSIFLHINCSNNGFTHRGEHHCASGREFRFYLGCSKSPLFQDVSSRRATLHIDQNLPHSNQVQPQPQEGTESSQSFSELPSLDDINSSFWEDLLK |
|
NCBI Accession
|
YP_007250561.1
|
|
Location
|
1388-2443 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCCCCGCCGAAAAAATTTAGACTATCGGCTAAAAATATATTCTTAACATATCCTCGCTGTTCTTTAACAAAAGAAGAGGCTCTCTTTCAACTCCAGAATATCTCTCTACCTTCGAATAAATTATTCATTCGTGTCGCAAGGGAACTCCACGAAGATGGGGAACCTCATCTCCATGTGCTTATACAACTCGAGGGTAAAGTCCAAATATACAACCAGAAACTCTTCGACCTCAGTTCCACAAGCAGATCAGCATATTTCCATCCGAACATTCAGGGAGCTAAGAGCAGCTCAGACGTTAAATCATACATGGAGAAAGACGGAGAATTCCTTGATTTTGGAGTTTTCCAGATCGATGGAAGATCAAGTAGAGGAGGTATACAGACAACCAATGATTCATATGCAAAAGCGTTAAACGCTGGGTCTGCTGAATCTGCACTACAAATTTTAAAAGAAGAACAACCTGCTCATTATTTTCTTCATTATCATAATTTGGTCAATAATGCAAATAGGATCTTTCAAAAGGCTCCAGAACCATGGGTTCCTCCGTTTCAACTCTCATCATTCAACGCTGTTCCTGACGAGATGCAGGAATGGGCTGATGATTATTTTGGAAGAGGTGCCGCTGCGCGGCCGGAAAGACCTATTAGTATCATCGTCGAGGGTGATTCAAGAACAGGGAAGACAATGTGGGCTCGTTCTTTAGGCCCACATAATTACTTGAGTGGTCATTTAGATTTCAATTCTAGGGTTTACTCGAACGAAGTGGAATATAACGTCATCGATGACGTCGCACCGCACTACTTAAAGTTAAAGCACTGGAAAGAGTTGATTGGGGCCCAGAAAGATTGGCAGTCCAACTGTAAGTACGGCAAGCCAGTTCAAATTAAAGGGGGCATACCATCAATCGTGCTGTGCAATCCAGGAGACGGGGGGAGCTATAAAGATTTCCTCGACAAAGAGGAAAATGCGTCACTAAAACAGTGGACTCTCAAAAATGCTAAATTCATCTTCCTCAACTCCCCCCTCTATCAAACCTCATCACAGGAACGCTAA |
|
Protein Sequence
|
MPPPKKFRLSAKNIFLTYPRCSLTKEEALFQLQNISLPSNKLFIRVARELHEDGEPHLHVLIQLEGKVQIYNQKLFDLSSTSRSAYFHPNIQGAKSSSDVKSYMEKDGEFLDFGVFQIDGRSSRGGIQTTNDSYAKALNAGSAESALQILKEEQPAHYFLHYHNLVNNANRIFQKAPEPWVPPFQLSSFNAVPDEMQEWADDYFGRGAAARPERPISIIVEGDSRTGKTMWARSLGPHNYLSGHLDFNSRVYSNEVEYNVIDDVAPHYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGDGGSYKDFLDKEENASLKQWTLKNAKFIFLNSPLYQTSSQER |
|
NCBI Accession
|
YP_007250562.1
|
|
Location
|
2029-2286 |
|
Gene Name
|
AC4 |
|
Protein Name
|
hypothetical protein |
|
Coding Region
|
ATGGGGAACCTCATCTCCATGTGCTTATACAACTCGAGGGTAAAGTCCAAATATACAACCAGAAACTCTTCGACCTCAGTTCCACAAGCAGATCAGCATATTTCCATCCGAACATTCAGGGAGCTAAGAGCAGCTCAGACGTTAAATCATACATGGAGAAAGACGGAGAATTCCTTGATTTTGGAGTTTTCCAGATCGATGGAAGATCAAGTAGAGGAGGTATACAGACAACCAATGATTCATATGCAAAAGCGTTAA |
|
Protein Sequence
|
MGNLISMCLYNSRVKSKYTTRNSSTSVPQADQHISIRTFRELRAAQTLNHTWRKTENSLILEFSRSMEDQVEEVYRQPMIHMQKR |
|
NCBI Accession
|
YP_007250563.1
|
|
Location
|
457-1227 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTATCATTCTAGATACAGGCGCACCTGGTTATCTACACAACGTCGAGCATATAATCGACAACCACCGTTTAAGCGTCTATATACTTCGAGACGTAATGAACTTAAACGTCGTCCCATTAGCGATGTTATTGCTTATGACGATAAGAAGATGTCTGCTCAGCGTATACATGAGGATCAATTTGGACCAGAATTCGTTATGTTGCATAATACAGCTTTTTCAACTTATGTTACTTATCCCAGCATAGTGAAGAATGTACCTAACAGAGTTAAGTCATATATTAAGATAAAACGGTTACGTTTTAAGGGGACTTTGAAGATAGAACGTGTACATGCAGATGTTAACATGGACTGTCCAGTTTCTAAGATAGAAGGAGTGTTCTCTATGGTTATTGTGGTTGATCGTAAACCACATTTGAACGCAACAGGATGTCTACTGACGTTTGACGAGTTATTTGGGGCTAGGATTCATAGTCATGGTAATCTAGCTATAACTCCAGCCTTGAAAGATCGTTTTTATATTCGTCATGTATTGAAACGAGTATTATCGGTTGAGAAAGATAGCTTGATGGTGGACCTTGAAGGAACGACAACGTTTTCTAGCAAACGATTTAGTTGTTGGTCTTCTTTTAACGACCTTGAGCGAGATTCATGTAATGGTGTTTATGCTAATATTAGCAAGAACGCTATCTTGGTGTATTATTGCTGGATGTCAGACGTAATGTCTAAGGCATCAACATTTGTATCATTCGATCTCGACTATGTTGGCTAA |
|
Protein Sequence
|
MYHSRYRRTWLSTQRRAYNRQPPFKRLYTSRRNELKRRPISDVIAYDDKKMSAQRIHEDQFGPEFVMLHNTAFSTYVTYPSIVKNVPNRVKSYIKIKRLRFKGTLKIERVHADVNMDCPVSKIEGVFSMVIVVDRKPHLNATGCLLTFDELFGARIHSHGNLAITPALKDRFYIRHVLKRVLSVEKDSLMVDLEGTTTFSSKRFSCWSSFNDLERDSCNGVYANISKNAILVYYCWMSDVMSKASTFVSFDLDYVG |
|
NCBI Accession
|
YP_007250564.1
|
|
Location
|
1315-2196 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGATTCTCAGCTAGTCATTCCTCCTAATGCCTTTAATTACATAGACTCTCATCGTGAAGAGTATCAGCTTTCTCATGACCTAACTGAAATTGTCTTGCAGTTTCCGTCGACGGCGGCTCAGCTAAGTGCTCGATTGAGTCGCAGCTGTATGAAAATAGACCACTGCGTCATTGAATACAGGCAACAAGTGCCTATTAACGCATCTGGAACGGTGATAGTGGAGATCCATGACAAAAGGATGCAGGACAATGAGTCATTACAAGCGTCGTGGACATTTCCGATCAGATGTAACATAGATCTACATTATTTTTCATCGTCGTTCTTCTCGTTAAAAGATCCTATACCTTGGAAGTTATATTACAAGGTCAGTGACTCGAATGTACACCAAAGGACGCACTTCGCCAAGTTCAAAGGGAAACTCAAACTGTCTACTGCGAAAAATTCAGTGGATATACCTTTCCGAGCACCCACGGTCAGGATCTTGTCGAAACAGTTTACGGAGAAGGATATTGATTTCCATCACGTGGGTTTCGGAAAGTGGGAGAGAAGACTAGTCCGTTCCGCATCGTCACGAATAATTGGGCTACCAGGCCCAATAGAAATAAGGCCTGGGGAATCTTGGGCTAGTAGAAGTACCATAGGAACAGCCCATTCAAATGCGGAATCGGAGGTTACTGACGCACTATACCCTTACAGAGAGCTGAACAGATTAAGCACCCCTATTTTAGACCCAGGTGATTCTGCGTCAGTAATTGGGATTCAGCGAACGGAGTCCAACTTAACAATGTCTATGTCACAGTTAAATGACATTGTCAGGTCAACTGTTCAAGAGTGTATTAACACAAACTGTGTTCCTCCCGTGCCCAAATCTTTGAAATGA |
|
Protein Sequence
|
MDSQLVIPPNAFNYIDSHREEYQLSHDLTEIVLQFPSTAAQLSARLSRSCMKIDHCVIEYRQQVPINASGTVIVEIHDKRMQDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYKVSDSNVHQRTHFAKFKGKLKLSTAKNSVDIPFRAPTVRILSKQFTEKDIDFHHVGFGKWERRLVRSASSRIIGLPGPIEIRPGESWASRSTIGTAHSNAESEVTDALYPYRELNRLSTPILDPGDSASVIGIQRTESNLTMSMSQLNDIVRSTVQECINTNCVPPVPKSLK |