Tomato yellow margin leaf curl virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000843525.4 |
| Isolate |
Venezuela: Merida |
| Release date |
2017/10/11 |
| Submitter |
Nava,A., Londono,A., Polston,J.E., Nava,A.R., Patte,C.P., Hiebert,E., Palston,J.E. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
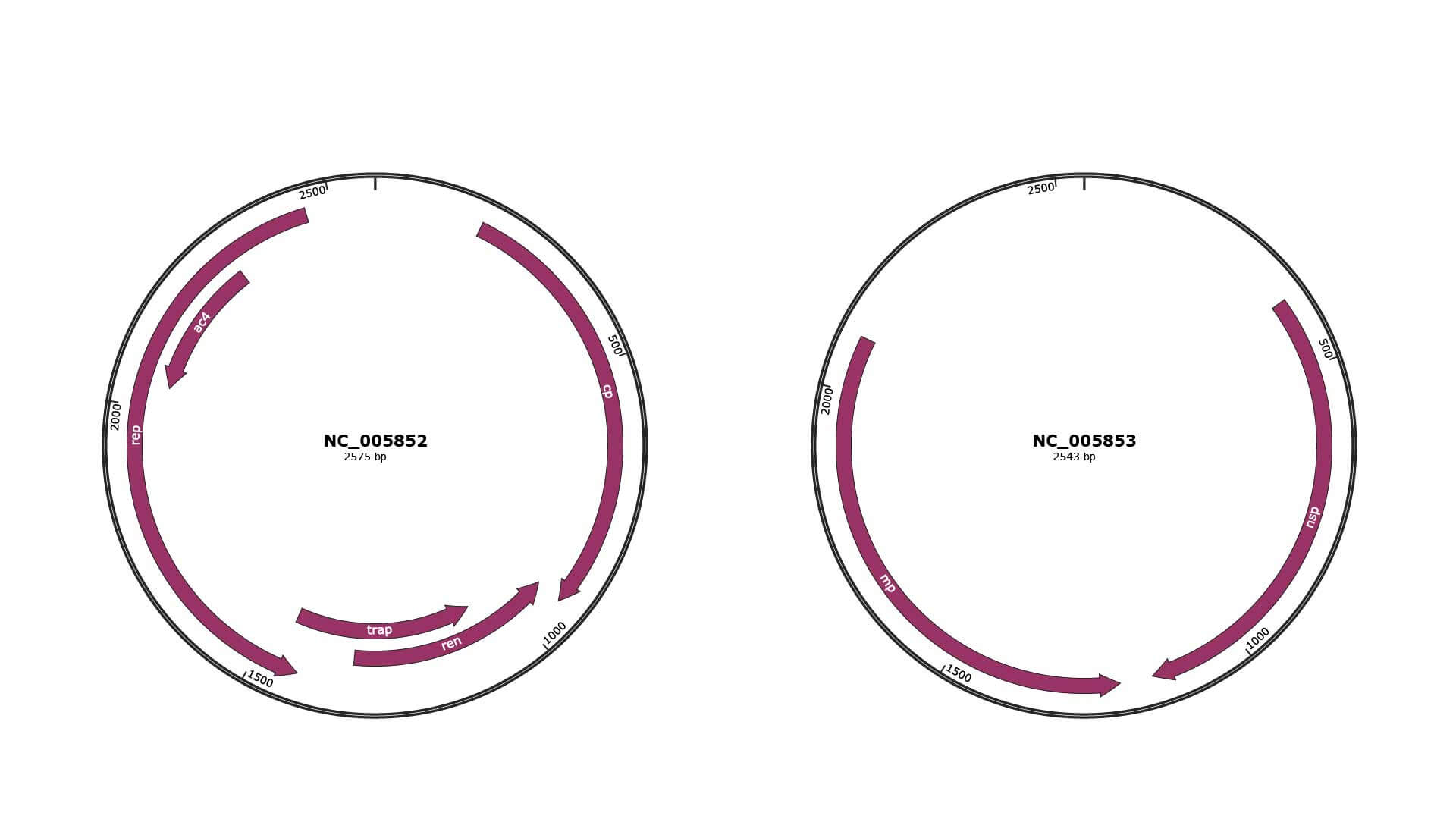
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTTGCCCCCCCTCCTCCTCGAGATGAGCGCCTGCTTTTTGGGACCACTTAATAAAGCAACCAATCAGATTGCTCCTGGAGAGTTAAATTATTAATTCGTGGTCCCCAAGTTCCGCCTTTTCCTTTATAAAGGCTGCAAGTGATAATGATTAATCAATAATTCAAAATGCCTAAGCGCGATGCTCCTTGGCGCTTATCGGCTGGGACCACTAAGGTCAGTCGTTCCTCCAATTATTCCCCTAGGAGTAATATGGGCCCAAAGGCCTCTGCTTGGGTTAATAGGCCCATGTACAGGAAGCCCAGAATTTACAGGACGTTAAGGGGGCCTGATATTCCTAAGGGTTGTGAAGGCCCATGTAAAGTTCAGTCCTTCGAGCAGAGGCATGATATTTCTCATGTTGGCAAGGTGCTTTGTGTTTCTGATGTGACACGTGGTAACGGTATTACCCACCGTGTAGGCAAGAGGTTCTGTGTCAAGTCTGTGTATATCTTAGGCAAGGTATGGATGGACGAGAATATCAAGTTGAAGAACCACACCAACAGCGTCATGTTCTGGTTGGTCAGAGACCGGAGACCTTATGGAACCCCCATGGACTTTGGCCAAGTGTTTAACATGTTTGATAACGAGCCAAGTACTGCCACTGTGAAGAACGATCTCCGTGATCGTTTCCAGGTTATGCACAAGTTTTATGCTAAGGTTACCGGTGGACAATATGCCAGCAATGAGCAAGCCTTGGTCAGGAGATTCTGGAAGGTCAACAACCATGTGGTGTACAACCATCAAGAAGCAGGGAAATACGAGAACCACACTGAGAATGCTCTATTATTGTATATGGCATGTACCCATGCGTCTAATCCTGTGTATGCTACATTAAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAATAAAGTTTGAATTTTATTTCATGATCTTCAAGCACATGGTTTACATATTTTCTGTCTGTTGCATAACTAACAGCTCTGATTACATTGTTTATTGAAATAACTCCTAACTGATCTAAATACAACAAGACATAATGTTTGAATCTATTTAAATATGTCGTCCCAGAAGCTTGAACTGATGTCGTCCAGACTTGGAAGTTCAGATAGGCCTTGTGTAGAGTCAATGCCTTCCTCAGGTTGTGGTTGAACCTGATTTGGATGTGGTACACTCTGGTCGTTGTGTACAGAGGGTCCTCCACTCGTTGAATCTTGAAAAAGAGGGGATTCGGCACCTCCCAGATAAAAACGCCATTCTGTGCCTGACGAGCAGTGATGGTTTCCCCTGTGCGTGAATCCATAGTTGCTGCAGAGGAGATGGACGTATATGGTACACCCGCAGCTTAGGTCTATTCTTTTACGTCGGGGTCTTCTCTTTGCAAGACGATGTGTTGGTTTAATAGAGGGGGGAGTCGAGGAAGATGAATTTTGCATTATGGAGTGTCCACGCTCTGAGAGATGTATTTTCCTCTTTGTCTAGGTACCTTTTATAGGAAGACCCCTCCCCTGGATTGCAAAGCACGATAGCGGGAATTCCACCTTTAATTTGAACAGGCTTTCCATATTTACAGTTGGACTGCCAGTCTTTCTGGGCCCCAATCAATTCTTTCCAGTGCTTTATTTTTAAATATTGTGGGTTGACATCATCAATGACGTTATACTCTACATCGTTTGAGTAAACCCTAGAATTGAAATCCATGTGACCACTTAGGTAATTATGAGAACCTAATGCACGTGCCCACATTGTTTTCCCTGTTCTAGAATCACCTTCAACGATTAAACTTATAGGTCTTTCTGGCCGCGCAGCGGAATCCCTCCCAAAATAATCATCTGCCCATTCTTGCATATCAACTGGAACATTTATGAATGACGATAGTCGAAAAGGAGGGACCCATGGTTCAGGAGGTTTACGAAATATTTTGGTTGCATTGGCTAACAAGTTATGATGTTGAAGAAAGAAGTGTTGCGGTTGTTCTTCCTTTATAATCTGCAACGCTTCTTCAGATGACCTAGCATTTAATGCCTTTGCGTATGTGTCATTAGCAGATTGCTGACCTCCTCTAGCAGATCTTCCGTCGATCTGGAATTCCCCCCATTGAATTGTGTCTCCGTCCTTATCAATGTAGGACTTGACATCGGAGCTGGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGTTGACCTGGTTGGGGAAACCAGATCGAAGAATCTGTTATTTTTGCACTGGTACTTGCCTTCGAACTGGATAAGCACATGCAGATGCGGTTCCCCATCTTCATGCAATTCTTTGCACACTTTAATGAATTTCTTGTTTGTCGGAGTGATTAGGTTTTGTAATTGGGAAAGTGCTTCTTCTTTGGATAGAGAGCACTTGGGGTATGTAAGGAAATAATTCTTGGCATTAATTTTAAAGGCACGTGCAGTAGGCATGCTTGGACACCAATTGGAGTCTCTCAACTCTCTCTAATGAATCGGTGTATAAGGGTCTTATATATACTATAAGCCTCTATAGGCTTAATAGACACGTGTAGGCCATCCGTATAATATT
ACCGGATGGCCGCGCGAATTTTTGGCCCTCCACGTGTCCAGATGAGCGCCTGCTTATTGGTGATCCCCCCCTCTCTGGAATTGGTCCCCCCCACTTTTGACCACTTTTGACCAATATTTGAATTAAATGCGCTCCCCCAGTCCGTACAGTACACGTGGCGCAATCTGGTCCATGCATTAAAGCTTAGTCATTCACTAGGAAAAAGTTTGTATATCCCCCCCCCCAACTTTGAATTTGTCCAGGTTTAGTCCCTCACATTATTTATATATACGTGGACCAGTCATAACCCATATGTGAAGGCTATTTACTATTATTCAAAATTCAAGTTGCTCTATTTAAAGGACGTTGTTGTCATTTTGGAGTAGTATCCGATATCTTAATATGTATCCAGTTAGATATAAACCTGATGCTAATAATTATAAGAGGAGATATTATTCACGTTCTAATGTGTTTAAGAGATCATCTGGTGTTAAACGTGCAGATGGGAAACGTAGAGCTACCCAACAAAATAAGTCTCATGAAGAGCCCAAGATGTCAGCCCAACGTATTCATGAGAATCAATATGGACCTGAATTTGTAATGACTCATATATATCTGCTATTTCCACATATATTAACTACCCCCATTTGGGTAAGATTGAACCTAACCCGAAGCAGGTCGTATATTAAGTTGAAACGACTCAGGTTTAAGGGAACTGTTAAGATTGAACGAGTACATGCTGATGTTGCCATGGATGGTTTACCCCCTAAGATTGAAGGTGTTTTTTCACTTGTTATTGTGGTGGATCGTAAACCTCATTTGAGTCCTTCAGGATCTCTGCTCACATTTGATGAGTTATTTGGTGCAAGGATTAATAGTCATGGTAATTTAGCGATAGCTTCCTCCTTCAAAGACAGATTCTACATTCGTCATGTGTTGAAGCGTGTTTTATCTGTGGAGAAGGATAGTACAATGGTCGACCTTGAAGGATCAACGTCACTCTCTAATAGGCGTTATAATTGTTGGGCTAGTTTTAAGGACTTAGATCATGACTCTTGTAAGGGTGTTTATGATAATATAAGCAAGAACGCCCTATTAATTTATTATTGTTGGATGTCTGATGTCACTTCTAAGGCATCTACCTTTGTATCATTTGATCTTGATTATGTTGGATGAATAATAATAAGACATTTGCTGAAATTGAGTATATAAAATACAATAACCAATATATTTATTTCAATGACTTTGGTGGTGTTGGGTTACAATTATTGTTAATACATTCATGGACTGTTGCCTTAACAAGTTCGTTAAGCTGGTTCATTGACATGGTGATGTTTGATTGAGCCCTTTGTTCCCCTATCACTGAAGCTGACTCTCCAGGGTCTAATGTGCAGGACCCCAGTCTGTTTAGATGTCTGTATGGGTGTATTGCGTTCTCCAGTTCAGAGTCTGTGTCTGTATGACCCATTCCTATGGTACTTCTTGATGCCCATGATTCTCCTGGTCTTAATTCCAGTGGAGTCTTTAACCCAACCCTTGACATTGTTGTGGATCTTATGAGTTTCCTATCCCATTTCCCGTAGTCCACGTGTGAGAAATCAACATCATTCTCTGTGAATTGTTTGGAATGAATCTTCACTGTTGGTGCACGGAATGGGATGTCTACAGAGTGTTTAGCTGTTGAGATCTTGAGCTTGCCTTTGAATTTGGCAAAGTGTGTTCTTTGATGAACATTTGAGTCACACACTCTGTAGTATAACTTCCATGGTATAGGATCCTTAAGAGAGAAGAAGGAAGATGAGAAGTAATGGAGATCTATGTTACAACGTATAGGGAATGTCCAGGACGCCTGTAATGATTCATTGTCTGTCATTCTCTTATCATGTATCTCCACAATTACAGTCCCTGTTGCGTTAATCGGAACCTGTTGCCTGTATTCTATGACACAGTGGTCTATCTTCATACAGCTACGACTGAGTCTTGCTGTTAATTGTGCAGCAGTGGAAGGAAACTGCAGAATAATCTCTGTTAGGTCATGAGATAACTGGTATTCATCTCTATGAGACTCTATGTAATTAAAAGCACTCGGAGGATTAACTAGCTGAGACTCCATTTAGTTTATTAGGTTGCGCAGCTAAATGCGTTCTGGGAATTTAGAGAGAGAATATTTATGAGAGAAGTTTGAAGGTTTGATGAAGATATGAAGATATGCATATGCCTTGCCCAGTTCCCCCTTTTATAGAACCCTAGCTCCTCTTAACATCTGGGTTTATAAAATGCACTCAAATATAGGATTTATAACACGCTAATTAAATGTTAAGGAATTAAATATTGACTTATTGAAGGAGAATATGAAGGGATATATATAATTAATATTGGTTTGATATGATAATTATGAGTTTCTGCAATGAGAAGGGATAATTGATGGCAGAGTAGTAAATATAGCCTTGGACACCAAATTGGAGTCTCTCAACTCTCTCTATTGAATCGGTGTATAAGGGTCTTATATATACTATAAGCCTCTATAGGCTTAATAGACACGTGTAGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_006456.1
|
|
Location
|
186-932 |
|
Gene Name
|
cp |
|
Protein Name
|
CP |
|
Coding Region
|
ATGCCTAAGCGCGATGCTCCTTGGCGCTTATCGGCTGGGACCACTAAGGTCAGTCGTTCCTCCAATTATTCCCCTAGGAGTAATATGGGCCCAAAGGCCTCTGCTTGGGTTAATAGGCCCATGTACAGGAAGCCCAGAATTTACAGGACGTTAAGGGGGCCTGATATTCCTAAGGGTTGTGAAGGCCCATGTAAAGTTCAGTCCTTCGAGCAGAGGCATGATATTTCTCATGTTGGCAAGGTGCTTTGTGTTTCTGATGTGACACGTGGTAACGGTATTACCCACCGTGTAGGCAAGAGGTTCTGTGTCAAGTCTGTGTATATCTTAGGCAAGGTATGGATGGACGAGAATATCAAGTTGAAGAACCACACCAACAGCGTCATGTTCTGGTTGGTCAGAGACCGGAGACCTTATGGAACCCCCATGGACTTTGGCCAAGTGTTTAACATGTTTGATAACGAGCCAAGTACTGCCACTGTGAAGAACGATCTCCGTGATCGTTTCCAGGTTATGCACAAGTTTTATGCTAAGGTTACCGGTGGACAATATGCCAGCAATGAGCAAGCCTTGGTCAGGAGATTCTGGAAGGTCAACAACCATGTGGTGTACAACCATCAAGAAGCAGGGAAATACGAGAACCACACTGAGAATGCTCTATTATTGTATATGGCATGTACCCATGCGTCTAATCCTGTGTATGCTACATTAAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAA |
|
Protein Sequence
|
MPKRDAPWRLSAGTTKVSRSSNYSPRSNMGPKASAWVNRPMYRKPRIYRTLRGPDIPKGCEGPCKVQSFEQRHDISHVGKVLCVSDVTRGNGITHRVGKRFCVKSVYILGKVWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYAKVTGGQYASNEQALVRRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_006457.1
|
|
Location
|
929-1327 |
|
Gene Name
|
ren |
|
Protein Name
|
REn |
|
Coding Region
|
ATGGATTCACGCACAGGGGAAACCATCACTGCTCGTCAGGCACAGAATGGCGTTTTTATCTGGGAGGTGCCGAATCCCCTCTTTTTCAAGATTCAACGAGTGGAGGACCCTCTGTACACAACGACCAGAGTGTACCACATCCAAATCAGGTTCAACCACAACCTGAGGAAGGCATTGACTCTACACAAGGCCTATCTGAACTTCCAAGTCTGGACGACATCAGTTCAAGCTTCTGGGACGACATATTTAAATAGATTCAAACATTATGTCTTGTTGTATTTAGATCAGTTAGGAGTTATTTCAATAAACAATGTAATCAGAGCTGTTAGTTATGCAACAGACAGAAAATATGTAAACCATGTGCTTGAAGATCATGAAATAAAATTCAAACTTTATTAA |
|
Protein Sequence
|
MDSRTGETITARQAQNGVFIWEVPNPLFFKIQRVEDPLYTTTRVYHIQIRFNHNLRKALTLHKAYLNFQVWTTSVQASGTTYLNRFKHYVLLYLDQLGVISINNVIRAVSYATDRKYVNHVLEDHEIKFKLY |
|
NCBI Accession
|
YP_006458.1
|
|
Location
|
1074-1460 |
|
Gene Name
|
trap |
|
Protein Name
|
TrAP |
|
Coding Region
|
ATGCAAAATTCATCTTCCTCGACTCCCCCCTCTATTAAACCAACACATCGTCTTGCAAAGAGAAGACCCCGACGTAAAAGAATAGACCTAAGCTGCGGGTGTACCATATACGTCCATCTCCTCTGCAGCAACTATGGATTCACGCACAGGGGAAACCATCACTGCTCGTCAGGCACAGAATGGCGTTTTTATCTGGGAGGTGCCGAATCCCCTCTTTTTCAAGATTCAACGAGTGGAGGACCCTCTGTACACAACGACCAGAGTGTACCACATCCAAATCAGGTTCAACCACAACCTGAGGAAGGCATTGACTCTACACAAGGCCTATCTGAACTTCCAAGTCTGGACGACATCAGTTCAAGCTTCTGGGACGACATATTTAAATAG |
|
Protein Sequence
|
MQNSSSSTPPSIKPTHRLAKRRPRRKRIDLSCGCTIYVHLLCSNYGFTHRGNHHCSSGTEWRFYLGGAESPLFQDSTSGGPSVHNDQSVPHPNQVQPQPEEGIDSTQGLSELPSLDDISSSFWDDIFK |
|
NCBI Accession
|
YP_006459.1
|
|
Location
|
1423-2457 |
|
Gene Name
|
rep |
|
Protein Name
|
REP |
|
Coding Region
|
ATGCCTACTGCACGTGCCTTTAAAATTAATGCCAAGAATTATTTCCTTACATACCCCAAGTGCTCTCTATCCAAAGAAGAAGCACTTTCCCAATTACAAAACCTAATCACTCCGACAAACAAGAAATTCATTAAAGTGTGCAAAGAATTGCATGAAGATGGGGAACCGCATCTGCATGTGCTTATCCAGTTCGAAGGCAAGTACCAGTGCAAAAATAACAGATTCTTCGATCTGGTTTCCCCAACCAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGATGTCAAGTCCTACATTGATAAGGACGGAGACACAATTCAATGGGGGGAATTCCAGATCGACGGAAGATCTGCTAGAGGAGGTCAGCAATCTGCTAATGACACATACGCAAAGGCATTAAATGCTAGGTCATCTGAAGAAGCGTTGCAGATTATAAAGGAAGAACAACCGCAACACTTCTTTCTTCAACATCATAACTTGTTAGCCAATGCAACCAAAATATTTCGTAAACCTCCTGAACCATGGGTCCCTCCTTTTCGACTATCGTCATTCATAAATGTTCCAGTTGATATGCAAGAATGGGCAGATGATTATTTTGGGAGGGATTCCGCTGCGCGGCCAGAAAGACCTATAAGTTTAATCGTTGAAGGTGATTCTAGAACAGGGAAAACAATGTGGGCACGTGCATTAGGTTCTCATAATTACCTAAGTGGTCACATGGATTTCAATTCTAGGGTTTACTCAAACGATGTAGAGTATAACGTCATTGATGATGTCAACCCACAATATTTAAAAATAAAGCACTGGAAAGAATTGATTGGGGCCCAGAAAGACTGGCAGTCCAACTGTAAATATGGAAAGCCTGTTCAAATTAAAGGTGGAATTCCCGCTATCGTGCTTTGCAATCCAGGGGAGGGGTCTTCCTATAAAAGGTACCTAGACAAAGAGGAAAATACATCTCTCAGAGCGTGGACACTCCATAATGCAAAATTCATCTTCCTCGACTCCCCCCTCTATTAA |
|
Protein Sequence
|
MPTARAFKINAKNYFLTYPKCSLSKEEALSQLQNLITPTNKKFIKVCKELHEDGEPHLHVLIQFEGKYQCKNNRFFDLVSPTRSTHFHPNIQGAKSSSDVKSYIDKDGDTIQWGEFQIDGRSARGGQQSANDTYAKALNARSSEEALQIIKEEQPQHFFLQHHNLLANATKIFRKPPEPWVPPFRLSSFINVPVDMQEWADDYFGRDSAARPERPISLIVEGDSRTGKTMWARALGSHNYLSGHMDFNSRVYSNDVEYNVIDDVNPQYLKIKHWKELIGAQKDWQSNCKYGKPVQIKGGIPAIVLCNPGEGSSYKRYLDKEENTSLRAWTLHNAKFIFLDSPLY |
|
NCBI Accession
|
YP_006460.1
|
|
Location
|
2043-2306 |
|
Gene Name
|
ac4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGAAGATGGGGAACCGCATCTGCATGTGCTTATCCAGTTCGAAGGCAAGTACCAGTGCAAAAATAACAGATTCTTCGATCTGGTTTCCCCAACCAGGTCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGATGTCAAGTCCTACATTGATAAGGACGGAGACACAATTCAATGGGGGGAATTCCAGATCGACGGAAGATCTGCTAGAGGAGGTCAGCAATCTGCTAATGACACATACGCAAAGGCATTAA |
|
Protein Sequence
|
MKMGNRICMCLSSSKASTSAKITDSSIWFPQPGQHISIRTFRELNPAPMSSPTLIRTETQFNGGNSRSTEDLLEEVSNLLMTHTQRH |
|
NCBI Accession
|
YP_006461.1
|
|
Location
|
382-1155 |
|
Gene Name
|
nsp |
|
Protein Name
|
NSP |
|
Coding Region
|
ATGTATCCAGTTAGATATAAACCTGATGCTAATAATTATAAGAGGAGATATTATTCACGTTCTAATGTGTTTAAGAGATCATCTGGTGTTAAACGTGCAGATGGGAAACGTAGAGCTACCCAACAAAATAAGTCTCATGAAGAGCCCAAGATGTCAGCCCAACGTATTCATGAGAATCAATATGGACCTGAATTTGTAATGACTCATATATATCTGCTATTTCCACATATATTAACTACCCCCATTTGGGTAAGATTGAACCTAACCCGAAGCAGGTCGTATATTAAGTTGAAACGACTCAGGTTTAAGGGAACTGTTAAGATTGAACGAGTACATGCTGATGTTGCCATGGATGGTTTACCCCCTAAGATTGAAGGTGTTTTTTCACTTGTTATTGTGGTGGATCGTAAACCTCATTTGAGTCCTTCAGGATCTCTGCTCACATTTGATGAGTTATTTGGTGCAAGGATTAATAGTCATGGTAATTTAGCGATAGCTTCCTCCTTCAAAGACAGATTCTACATTCGTCATGTGTTGAAGCGTGTTTTATCTGTGGAGAAGGATAGTACAATGGTCGACCTTGAAGGATCAACGTCACTCTCTAATAGGCGTTATAATTGTTGGGCTAGTTTTAAGGACTTAGATCATGACTCTTGTAAGGGTGTTTATGATAATATAAGCAAGAACGCCCTATTAATTTATTATTGTTGGATGTCTGATGTCACTTCTAAGGCATCTACCTTTGTATCATTTGATCTTGATTATGTTGGATGA |
|
Protein Sequence
|
MYPVRYKPDANNYKRRYYSRSNVFKRSSGVKRADGKRRATQQNKSHEEPKMSAQRIHENQYGPEFVMTHIYLLFPHILTTPIWVRLNLTRSRSYIKLKRLRFKGTVKIERVHADVAMDGLPPKIEGVFSLVIVVDRKPHLSPSGSLLTFDELFGARINSHGNLAIASSFKDRFYIRHVLKRVLSVEKDSTMVDLEGSTSLSNRRYNCWASFKDLDHDSCKGVYDNISKNALLIYYCWMSDVTSKASTFVSFDLDYVG |
|
NCBI Accession
|
YP_006462.1
|
|
Location
|
1211-2092 |
|
Gene Name
|
mp |
|
Protein Name
|
MP |
|
Coding Region
|
ATGGAGTCTCAGCTAGTTAATCCTCCGAGTGCTTTTAATTACATAGAGTCTCATAGAGATGAATACCAGTTATCTCATGACCTAACAGAGATTATTCTGCAGTTTCCTTCCACTGCTGCACAATTAACAGCAAGACTCAGTCGTAGCTGTATGAAGATAGACCACTGTGTCATAGAATACAGGCAACAGGTTCCGATTAACGCAACAGGGACTGTAATTGTGGAGATACATGATAAGAGAATGACAGACAATGAATCATTACAGGCGTCCTGGACATTCCCTATACGTTGTAACATAGATCTCCATTACTTCTCATCTTCCTTCTTCTCTCTTAAGGATCCTATACCATGGAAGTTATACTACAGAGTGTGTGACTCAAATGTTCATCAAAGAACACACTTTGCCAAATTCAAAGGCAAGCTCAAGATCTCAACAGCTAAACACTCTGTAGACATCCCATTCCGTGCACCAACAGTGAAGATTCATTCCAAACAATTCACAGAGAATGATGTTGATTTCTCACACGTGGACTACGGGAAATGGGATAGGAAACTCATAAGATCCACAACAATGTCAAGGGTTGGGTTAAAGACTCCACTGGAATTAAGACCAGGAGAATCATGGGCATCAAGAAGTACCATAGGAATGGGTCATACAGACACAGACTCTGAACTGGAGAACGCAATACACCCATACAGACATCTAAACAGACTGGGGTCCTGCACATTAGACCCTGGAGAGTCAGCTTCAGTGATAGGGGAACAAAGGGCTCAATCAAACATCACCATGTCAATGAACCAGCTTAACGAACTTGTTAAGGCAACAGTCCATGAATGTATTAACAATAATTGTAACCCAACACCACCAAAGTCATTGAAATAA |
|
Protein Sequence
|
MESQLVNPPSAFNYIESHRDEYQLSHDLTEIILQFPSTAAQLTARLSRSCMKIDHCVIEYRQQVPINATGTVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYRVCDSNVHQRTHFAKFKGKLKISTAKHSVDIPFRAPTVKIHSKQFTENDVDFSHVDYGKWDRKLIRSTTMSRVGLKTPLELRPGESWASRSTIGMGHTDTDSELENAIHPYRHLNRLGSCTLDPGESASVIGEQRAQSNITMSMNQLNELVKATVHECINNNCNPTPPKSLK |