Tomato yellow leaf distortion virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000896215.1 |
| Isolate |
Cuba |
| Release date |
2015/2/22 |
| Submitter |
Fiallo-Olive,E., Martinez-Zubiaur,Y., Rivera-Bustamante,R.F., Hernandez-Zepeda,C., Trejo-Saavedra,D., Carrillo-Trip,J., Rivera-Bustamante,R. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
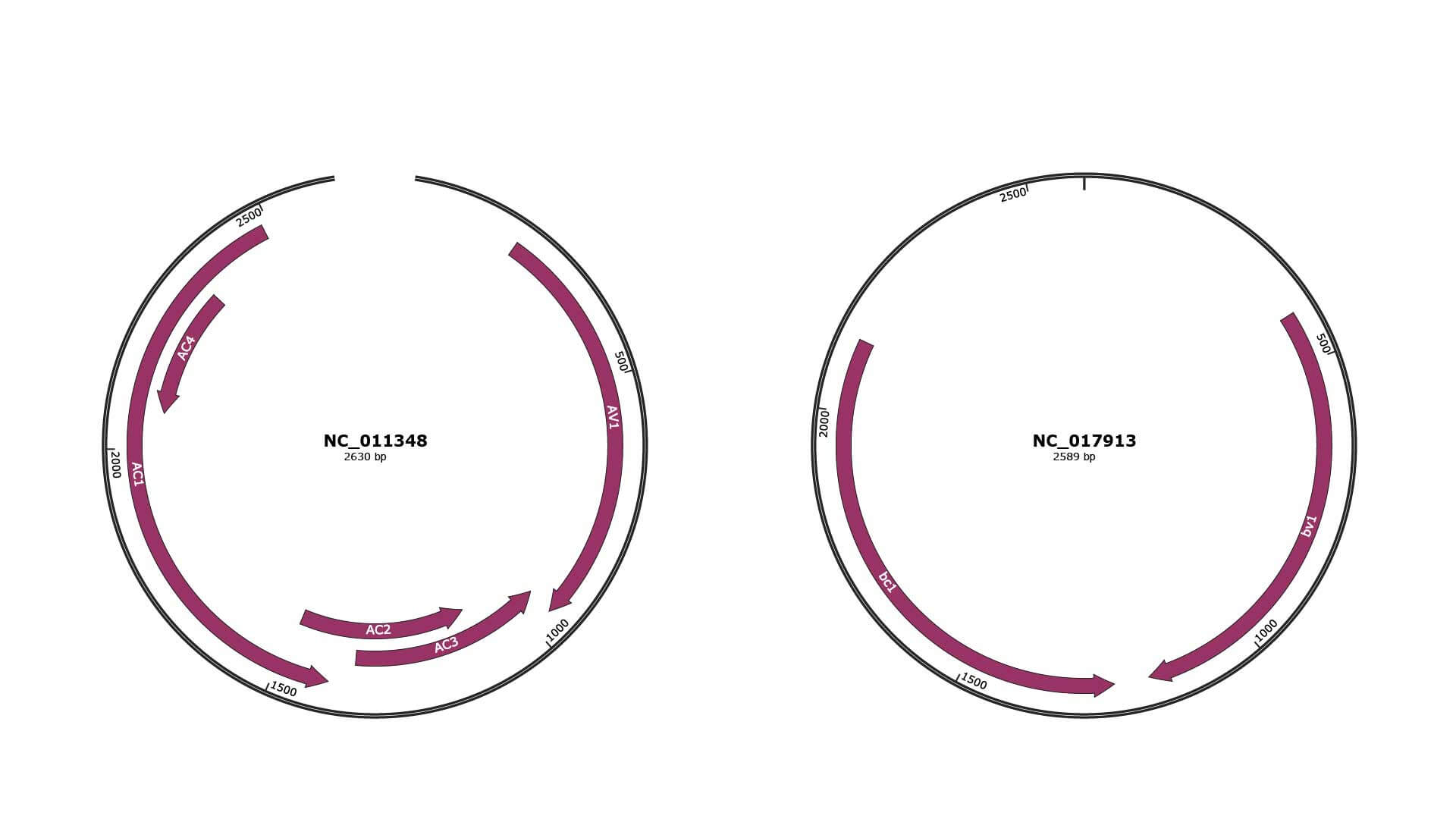
JBrowse
Genome
ACCGGATGGCCGCGCTTTGGGGTACCCCCCCCCGCGCGCTCTCATTGGTGCCGTACTCTCTCACGCGCGCCGCTTTTCATTACTCGTGTCATCGGCCAATCATATTGCGCCTGCCGCGCCTGTTTATTTCAAACTACTTGGGCCCGAAGTTGTTGACTGGTCTATAAATGAAAAGCTTATTGGGCCTGTGTCTTTAACTCAAAATGCCTAAGCGCGATCTTCCATGGCGCTCGATCGCGGGAACGTCAAAGGTGAGCCGCAATGCGAATTACTCACCACGTGGCGGTATGGGCCCAAAATTCAACAAGGCCCAGGCTTGGGTTGATCGGCCTATGTTCAAGAAGCCCAGGATATATCGGACTTTGACCAGTCCAGATGTGCCACGAGGCTGTGAAGGGCCTTGTAAGATCCAGTCGTTTGAGCAAAGGCATGACATCTCTCATGTCGGTAAGGTCATGTGTATATCCGATGTCACACGTGGCAATGGCATTACCCACCGTGTGGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATTTTAGTTAAGGTATGGATGGATGAGAACATCAAGCTCAAGAATCACACGAACAGTGTGATGTTCTGGTTGGTCCGAGACCGTCGACCGTATGGTACGCCTATGGATTTCGGTCAGGTGTTCAACATGTTCGACAACGAGCCTAGTACAGCCACGGTTAAGAACGATCTGCGTGATCGTTTCCAGGTATTGCACAAGTTCTACTCGAAGGTGACAGGTGGACAGTATGCCAGTAATGAACAGGCGCTGGTCAAGCGTTTCTGGAAGGTCAATACTCGTGTCGTCTACAACCACCAGGAAGCCGCTAAGTACGAGAATCATACGGAGAACGCCCTGTTATTGTACATGGCATGTACTCATGCCTCTAACCCCGTGTATGCAACCTTGAAGATTCGGATCTATTTTTACGATTCGATCATGAATTAATAAAATTTAAATTTTATTGAATGATTTTCCAGTACATGACTCACATACGATCTGTCTGTCGCGAATCGAACAGCTCTGATTACATTGTTTATGCAAATCACGCCTAACTGATCTAAGTACATGTTAACTAAATGTCTAAACCTAATTAAATAAGTTGACCCAGAAGCTTTCATCGATGTCGTCCAGACTTGGAAGTTCAGGTAAGCTTTGTGGAGATGCAACGCTCTCCTCAGGTTGTGGTTGAACCGTATCTGGATATGGTAGACCCTTGTCCTGGTGTACAACGGATCCTCTACCCTGTACATCTTGAAATACAGGGGATTTTCTATCTCCCAGGTATACACGCCATTCTCCGCCTGACGTGCAGTGATGAGTTCCCCGGTGCGTGAATCCATGTCCCGTGCAGCCTATGTGGAAGTAGATGGAGCAACCGCACTCCAGATCAATCCGCCTCCTCCTGATCGCCCTCTTCTTGGCCTGCCTGTGTGCCTTCTTGATAGAGGGCGGATGTGAGGGTGATGAAGATCGCATTCTTGACAGTCCAGTTCCTGAGAGATGCGTTTTCCTCTTTGTCCAGGAAAGCTTTATAGCTAGCACCCTCACCAGGATTGCAAAGCACGATTGATGGGATTCCACCTTTAATTTGAACTGGCTTGCCGTATTTGCAATTTGACTGCCAGTCTTTTTGGGCCCCGATCAATTCTTTCCAGTGCTTTAGCTTTAGATAGTGCGGTGCGACGTCATCAATGACGTTATACTCCACTTCATTCGAAAAGACTCGACCATTGAAGTCCAGGTGTCCACTTAGATAATTATGTGGGCCTAACGCACGAGCCCACATGGTCTTCCCTGTCCTTGAATCACCTTCTACGATGATACTCAATGGTCTCTGTGGCCGCGCAGCGGAACCTCTTCCAAAATAATCATCCGCCCACTCCTGCATCTCATCGGGAACGTTAGTGAAGGACGAGAGTTGAAACGGAGGAACCCACGGTTCCGGAGCCTTTTTGAATATCCTCTCTAGATTGGAGCGGATGTTATGATTCTGCAAGACGAAATCTTTTGGCTGTTCTTCCCTTAAAACCGCCATGGCAGATTGAACAGAATCTGCATTTAACGCCTTGGCATATGAATCATTAGCAGACTGCTTGCCTCCTCTAGCAGATCTGCCGTCGATCTGGAATTCTCCCCATTCCAGTGTATCTCCGTCCTTGTCGATGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGTATGTTCGGATGGAAATGTGCTGACCTGGTTGGGGAGACCAGATCGAAGAATCTGTTATTCTTGCATTGGTATTTTCCTTCGAACTGTATGAGCACATGGAGATGAGGCTCCCCATTCTCATGAAGCTCTCTGCAGATTTTGATGAACTTCTTGTTAACTGGTGTTTCAAGGTTTTGTAATTGGGAAAGTGCCTCTTCTTTTGTCAGAGAGCACTGTGGATAAGTGAGGAAATAGTTTTTGGCTGAGACTTTGAAACGCTTAACCGATGGCATTTTTGTAATAAGAGGGGTGTACCCCGATTGAGCTCTCTCAAAACTTGCTCTATGAATTGGGGTCTGGGGTCTCATTTATACTAGAAGGCTCTATAGAACTCTCAATCTCGTTCGCACACGTGGCGGCCATCCGCTATAATATT
ACCGGATGGCCGCGCTTTGGGGTACCCCCCCGCGCGCTCTCATTGGTGCCGTACTCTCTCTCACGCGCGCCGCCTCTGGTGCCGCACTCTCACTCGCCCTCCCATTGGTGTTTGTAAAACACGTTCCTTTTCCTGCCGTTCCTTTAATTCAAATTAAAGGTTAATACTTTTGTCGCGCGATATGCTTTGGACTTTGAATTATTGTCTCGCGACGAATTAATATGGCCCATTGTACTTGGTGATGGACGTGGCTAAATTTGGGCCGTGCTACTGAGTCTATTTGCAACTAATGTTGAACAACTTGCTTATAAATGGGACTGGAATGAAATCTTATGGTGTATCCGACTCAGTAGTCGACCACGTGTTTGTAATTATCTTCTAATTAATTTGTCTATCCATTATTATCTTCGGATAATGTATCCTTTGAGAAGTAAACGTGGTTCATTTTTTACGCCACGTCGTTTTTATCCACGTAACACTGTCCTCAAGCGTTCAACCTCGTCGAAGAGACATGACTCGAAACGTCGACTTGTTAATTCCAACAAGCCCAGTGATGAGCCCAAGATGTCAGTCCAACGCATTCATGAGAATCAGTATGGGCCAGATTTCTCTATGGCCCATAATTCAGCTGTCTCGACGTATGTCAGTTATCCTAGCCTGGGAAAGTCCGAACCCAACCGAAGCAGGTCCTATATTAAGTTGAAACAGCTACGTTTCAAAGGGACTGTGAAGATTGAACGTGTTCAGACGGACCTGAACATGGACGGTTCTACCCCCAAGTTGAAGAGTCTTCTCCATGTGATTGTTGTGGATCGCAAACCCCACTTGGGTCCTTCTGGATGTCTACATACGTTTGACGAGCTATTCGGTGCTAGGATCCACAGTCATGGTAACCTCAGCGTTACCCCTTCCTTGAAAGATCGTTATTACATCCGCCACGTGTGCAAACGTGTATTATCTGTCGAGAAGGATACGCTTATGGTAGACGTGGAAGGATCTATTTCACTCTCTAACAGGCGTTTTAGTTGTTGGTCTACGTTTAAGGATCTTGATCGTGATTCGTGCAAGGGTGTTTATGATAATATAAGCAAGAACGCCCTACTAGTTTATTACTGCTGGATGTCCGATACGCCTTCAAAGGCATCGACATTTGTATCATTTGATCTTGATTACGTTGGTTAATGAAATAAATAACATTTATCCAAAGATGATTATCTATATATGAAAAGGAAAATATAAACTTTATTGAAATGATTTGGGCTTGGAAGCCTGACAGTTATTGTTAATACACTCTTGGACAGTTGTCCTAACCAAATCATTTAATTGGGCCATAGACATCGTGATATTGGACTCGGCTCTCTGGGCCCCTACAATGGAGGCAGACTCTCCCGGATCCATAACGCTGGTCCCTAGCCTGTTGAGGTGCCTGTATGGATGGAGCTCGTTCTCCACCTCTGAATCCGCCTCTGACAGGCCTGTTCCTATAGTACTCCTGGAAGCCCATGACTCTCCAGGCCTTATCTCAATTGGGCCTCTTATTCCAAGCCTTGACATGGACGCGCATCTAATGGGCTTCCTTTCCCATTTCCCGTAGTCGACATGGTTGAAGTCCACATCTTTATCGGTGAACTGTTTCGACAGGATCTTTACTGTCGGTGCTCGGAATGGGATGTCGACGGAATGCTTCGCCGTTGATAGTTTCAGTTTCCCTTTGAACTTGGCGAAGTGGGTCCTCTGATGAACATTCGTATCGGAAACCCTGTAGTACAACTTCCATGGAATTGGGTCTTTCAAGGAGAAGAACGAAGCCGAGAAATAGTGGAGATCTATGTTGCATCTGATCGGAAAGGTCCACGACGCCTGTAATGACTCGTTGTCTGTCATCCTCTTGTCGTGGATCTCCACAATTACCGACCCGGTTGCGTTAATCGGCACTTGTTGCCTGTACTCTATGACGCAGTGATCGATCTTCATGCAGCTACGACTGAGTCTAGCTGTCAACTGAGACGCCGTCGACGGAAATTGCAGTACGATCTCAGTTAAGTCATGGGAAAGCTGGTACTCGTCACGGTGTGACTCTATGTAGTTGAAAGCGTTCGGAGGATTAGCTAACTGAGACTCCATATGAAGAACAATGGCCGCGCAGCGGAATCGCTTGTTGAACTTCAACTGGTTATGAAAATTCTGGGAATTTTGTTAGAACAAGAAAAGAAGCTGTTTGAGAAAGACGATAATGGCGATTTAGAAATTGGCTGAATAAACCTACTTTGACGGTGGTCTGTGGAACTATTGAGCGTAATTAAGTGAATATGAAACTAAATTCAATATTTCAGCCAACGATTCACTAATTTTTTCTGGGTTGTATGTTTATGAGAAGTTGTACATGTTGAAGTTGATATGAGGATGAACTAGCTTATATAGAAACCCAGAACTCGTTCAGTGGCATTTTTGTAATAAGAGGGGTGTACCCCGATTGAGCTCTCTCAAAACTTGCTCTATGAATTGGGGTCTGGGGTCTCATTTATACTAGAAGGCTCTATAGAACTCTCAATCTCGTTCGCACACGTGGCGGCCATCCGCTATAATATT
Gene Information
|
NCBI Accession
|
YP_002268202.1
|
|
Location
|
204-959 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGCGATCTTCCATGGCGCTCGATCGCGGGAACGTCAAAGGTGAGCCGCAATGCGAATTACTCACCACGTGGCGGTATGGGCCCAAAATTCAACAAGGCCCAGGCTTGGGTTGATCGGCCTATGTTCAAGAAGCCCAGGATATATCGGACTTTGACCAGTCCAGATGTGCCACGAGGCTGTGAAGGGCCTTGTAAGATCCAGTCGTTTGAGCAAAGGCATGACATCTCTCATGTCGGTAAGGTCATGTGTATATCCGATGTCACACGTGGCAATGGCATTACCCACCGTGTGGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATTTTAGTTAAGGTATGGATGGATGAGAACATCAAGCTCAAGAATCACACGAACAGTGTGATGTTCTGGTTGGTCCGAGACCGTCGACCGTATGGTACGCCTATGGATTTCGGTCAGGTGTTCAACATGTTCGACAACGAGCCTAGTACAGCCACGGTTAAGAACGATCTGCGTGATCGTTTCCAGGTATTGCACAAGTTCTACTCGAAGGTGACAGGTGGACAGTATGCCAGTAATGAACAGGCGCTGGTCAAGCGTTTCTGGAAGGTCAATACTCGTGTCGTCTACAACCACCAGGAAGCCGCTAAGTACGAGAATCATACGGAGAACGCCCTGTTATTGTACATGGCATGTACTCATGCCTCTAACCCCGTGTATGCAACCTTGAAGATTCGGATCTATTTTTACGATTCGATCATGAATTAA |
|
Protein Sequence
|
MPKRDLPWRSIAGTSKVSRNANYSPRGGMGPKFNKAQAWVDRPMFKKPRIYRTLTSPDVPRGCEGPCKIQSFEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILVKVWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVLHKFYSKVTGGQYASNEQALVKRFWKVNTRVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
|
NCBI Accession
|
YP_002268203.1
|
|
Location
|
956-1354 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancement protein |
|
Coding Region
|
ATGGATTCACGCACCGGGGAACTCATCACTGCACGTCAGGCGGAGAATGGCGTGTATACCTGGGAGATAGAAAATCCCCTGTATTTCAAGATGTACAGGGTAGAGGATCCGTTGTACACCAGGACAAGGGTCTACCATATCCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCTTACCTGAACTTCCAAGTCTGGACGACATCGATGAAAGCTTCTGGGTCAACTTATTTAATTAGGTTTAGACATTTAGTTAACATGTACTTAGATCAGTTAGGCGTGATTTGCATAAACAATGTAATCAGAGCTGTTCGATTCGCGACAGACAGATCGTATGTGAGTCATGTACTGGAAAATCATTCAATAAAATTTAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGELITARQAENGVYTWEIENPLYFKMYRVEDPLYTRTRVYHIQIRFNHNLRRALHLHKAYLNFQVWTTSMKASGSTYLIRFRHLVNMYLDQLGVICINNVIRAVRFATDRSYVSHVLENHSIKFKFY |
|
NCBI Accession
|
YP_002268204.1
|
|
Location
|
1101-1490 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transactivator protein |
|
Coding Region
|
ATGCGATCTTCATCACCCTCACATCCGCCCTCTATCAAGAAGGCACACAGGCAGGCCAAGAAGAGGGCGATCAGGAGGAGGCGGATTGATCTGGAGTGCGGTTGCTCCATCTACTTCCACATAGGCTGCACGGGACATGGATTCACGCACCGGGGAACTCATCACTGCACGTCAGGCGGAGAATGGCGTGTATACCTGGGAGATAGAAAATCCCCTGTATTTCAAGATGTACAGGGTAGAGGATCCGTTGTACACCAGGACAAGGGTCTACCATATCCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCTTACCTGAACTTCCAAGTCTGGACGACATCGATGAAAGCTTCTGGGTCAACTTATTTAATTAG |
|
Protein Sequence
|
MRSSSPSHPPSIKKAHRQAKKRAIRRRRIDLECGCSIYFHIGCTGHGFTHRGTHHCTSGGEWRVYLGDRKSPVFQDVQGRGSVVHQDKGLPYPDTVQPQPEESVASPQSLPELPSLDDIDESFWVNLFN |
|
NCBI Accession
|
YP_002268205.1
|
|
Location
|
1402-2487 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCATCGGTTAAGCGTTTCAAAGTCTCAGCCAAAAACTATTTCCTCACTTATCCACAGTGCTCTCTGACAAAAGAAGAGGCACTTTCCCAATTACAAAACCTTGAAACACCAGTTAACAAGAAGTTCATCAAAATCTGCAGAGAGCTTCATGAGAATGGGGAGCCTCATCTCCATGTGCTCATACAGTTCGAAGGAAAATACCAATGCAAGAATAACAGATTCTTCGATCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACACTGGAATGGGGAGAATTCCAGATCGACGGCAGATCTGCTAGAGGAGGCAAGCAGTCTGCTAATGATTCATATGCCAAGGCGTTAAATGCAGATTCTGTTCAATCTGCCATGGCGGTTTTAAGGGAAGAACAGCCAAAAGATTTCGTCTTGCAGAATCATAACATCCGCTCCAATCTAGAGAGGATATTCAAAAAGGCTCCGGAACCGTGGGTTCCTCCGTTTCAACTCTCGTCCTTCACTAACGTTCCCGATGAGATGCAGGAGTGGGCGGATGATTATTTTGGAAGAGGTTCCGCTGCGCGGCCACAGAGACCATTGAGTATCATCGTAGAAGGTGATTCAAGGACAGGGAAGACCATGTGGGCTCGTGCGTTAGGCCCACATAATTATCTAAGTGGACACCTGGACTTCAATGGTCGAGTCTTTTCGAATGAAGTGGAGTATAACGTCATTGATGACGTCGCACCGCACTATCTAAAGCTAAAGCACTGGAAAGAATTGATCGGGGCCCAAAAAGACTGGCAGTCAAATTGCAAATACGGCAAGCCAGTTCAAATTAAAGGTGGAATCCCATCAATCGTGCTTTGCAATCCTGGTGAGGGTGCTAGCTATAAAGCTTTCCTGGACAAAGAGGAAAACGCATCTCTCAGGAACTGGACTGTCAAGAATGCGATCTTCATCACCCTCACATCCGCCCTCTATCAAGAAGGCACACAGGCAGGCCAAGAAGAGGGCGATCAGGAGGAGGCGGATTGA |
|
Protein Sequence
|
MPSVKRFKVSAKNYFLTYPQCSLTKEEALSQLQNLETPVNKKFIKICRELHENGEPHLHVLIQFEGKYQCKNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGKQSANDSYAKALNADSVQSAMAVLREEQPKDFVLQNHNIRSNLERIFKKAPEPWVPPFQLSSFTNVPDEMQEWADDYFGRGSAARPQRPLSIIVEGDSRTGKTMWARALGPHNYLSGHLDFNGRVFSNEVEYNVIDDVAPHYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKAFLDKEENASLRNWTVKNAIFITLTSALYQEGTQAGQEEGDQEEAD |
|
NCBI Accession
|
YP_002268206.1
|
|
Location
|
2073-2336 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGAGAATGGGGAGCCTCATCTCCATGTGCTCATACAGTTCGAAGGAAAATACCAATGCAAGAATAACAGATTCTTCGATCTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACACTGGAATGGGGAGAATTCCAGATCGACGGCAGATCTGCTAGAGGAGGCAAGCAGTCTGCTAATGATTCATATGCCAAGGCGTTAA |
|
Protein Sequence
|
MRMGSLISMCSYSSKENTNARITDSSIWSPQPGQHISIRTYRELNPAPTSSPTSTRTEIHWNGENSRSTADLLEEASSLLMIHMPRR |
|
NCBI Accession
|
YP_006331058.1
|
|
Location
|
415-1182 |
|
Gene Name
|
bv1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTATCCTTTGAGAAGTAAACGTGGTTCATTTTTTACGCCACGTCGTTTTTATCCACGTAACACTGTCCTCAAGCGTTCAACCTCGTCGAAGAGACATGACTCGAAACGTCGACTTGTTAATTCCAACAAGCCCAGTGATGAGCCCAAGATGTCAGTCCAACGCATTCATGAGAATCAGTATGGGCCAGATTTCTCTATGGCCCATAATTCAGCTGTCTCGACGTATGTCAGTTATCCTAGCCTGGGAAAGTCCGAACCCAACCGAAGCAGGTCCTATATTAAGTTGAAACAGCTACGTTTCAAAGGGACTGTGAAGATTGAACGTGTTCAGACGGACCTGAACATGGACGGTTCTACCCCCAAGTTGAAGAGTCTTCTCCATGTGATTGTTGTGGATCGCAAACCCCACTTGGGTCCTTCTGGATGTCTACATACGTTTGACGAGCTATTCGGTGCTAGGATCCACAGTCATGGTAACCTCAGCGTTACCCCTTCCTTGAAAGATCGTTATTACATCCGCCACGTGTGCAAACGTGTATTATCTGTCGAGAAGGATACGCTTATGGTAGACGTGGAAGGATCTATTTCACTCTCTAACAGGCGTTTTAGTTGTTGGTCTACGTTTAAGGATCTTGATCGTGATTCGTGCAAGGGTGTTTATGATAATATAAGCAAGAACGCCCTACTAGTTTATTACTGCTGGATGTCCGATACGCCTTCAAAGGCATCGACATTTGTATCATTTGATCTTGATTACGTTGGTTAA |
|
Protein Sequence
|
MYPLRSKRGSFFTPRRFYPRNTVLKRSTSSKRHDSKRRLVNSNKPSDEPKMSVQRIHENQYGPDFSMAHNSAVSTYVSYPSLGKSEPNRSRSYIKLKQLRFKGTVKIERVQTDLNMDGSTPKLKSLLHVIVVDRKPHLGPSGCLHTFDELFGARIHSHGNLSVTPSLKDRYYIRHVCKRVLSVEKDTLMVDVEGSISLSNRRFSCWSTFKDLDRDSCKGVYDNISKNALLVYYCWMSDTPSKASTFVSFDLDYVG |
|
NCBI Accession
|
YP_006331059.1
|
|
Location
|
1243-2124 |
|
Gene Name
|
bc1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGAGTCTCAGTTAGCTAATCCTCCGAACGCTTTCAACTACATAGAGTCACACCGTGACGAGTACCAGCTTTCCCATGACTTAACTGAGATCGTACTGCAATTTCCGTCGACGGCGTCTCAGTTGACAGCTAGACTCAGTCGTAGCTGCATGAAGATCGATCACTGCGTCATAGAGTACAGGCAACAAGTGCCGATTAACGCAACCGGGTCGGTAATTGTGGAGATCCACGACAAGAGGATGACAGACAACGAGTCATTACAGGCGTCGTGGACCTTTCCGATCAGATGCAACATAGATCTCCACTATTTCTCGGCTTCGTTCTTCTCCTTGAAAGACCCAATTCCATGGAAGTTGTACTACAGGGTTTCCGATACGAATGTTCATCAGAGGACCCACTTCGCCAAGTTCAAAGGGAAACTGAAACTATCAACGGCGAAGCATTCCGTCGACATCCCATTCCGAGCACCGACAGTAAAGATCCTGTCGAAACAGTTCACCGATAAAGATGTGGACTTCAACCATGTCGACTACGGGAAATGGGAAAGGAAGCCCATTAGATGCGCGTCCATGTCAAGGCTTGGAATAAGAGGCCCAATTGAGATAAGGCCTGGAGAGTCATGGGCTTCCAGGAGTACTATAGGAACAGGCCTGTCAGAGGCGGATTCAGAGGTGGAGAACGAGCTCCATCCATACAGGCACCTCAACAGGCTAGGGACCAGCGTTATGGATCCGGGAGAGTCTGCCTCCATTGTAGGGGCCCAGAGAGCCGAGTCCAATATCACGATGTCTATGGCCCAATTAAATGATTTGGTTAGGACAACTGTCCAAGAGTGTATTAACAATAACTGTCAGGCTTCCAAGCCCAAATCATTTCAATAA |
|
Protein Sequence
|
MESQLANPPNAFNYIESHRDEYQLSHDLTEIVLQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFNHVDYGKWERKPIRCASMSRLGIRGPIEIRPGESWASRSTIGTGLSEADSEVENELHPYRHLNRLGTSVMDPGESASIVGAQRAESNITMSMAQLNDLVRTTVQECINNNCQASKPKSFQ |