Tomato yellow leaf deformation dwarf virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_018587685.1 |
| Isolate |
Brazil |
| Release date |
2021/6/1 |
| Submitter |
Pereira-Carvalho,R.C., Reis-Goncalves,V.P.M., Boiteux,L.S., Fonseca,M.E.N., Naito,F.Y., Rojas,M.R., Gilbertson,R.L. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
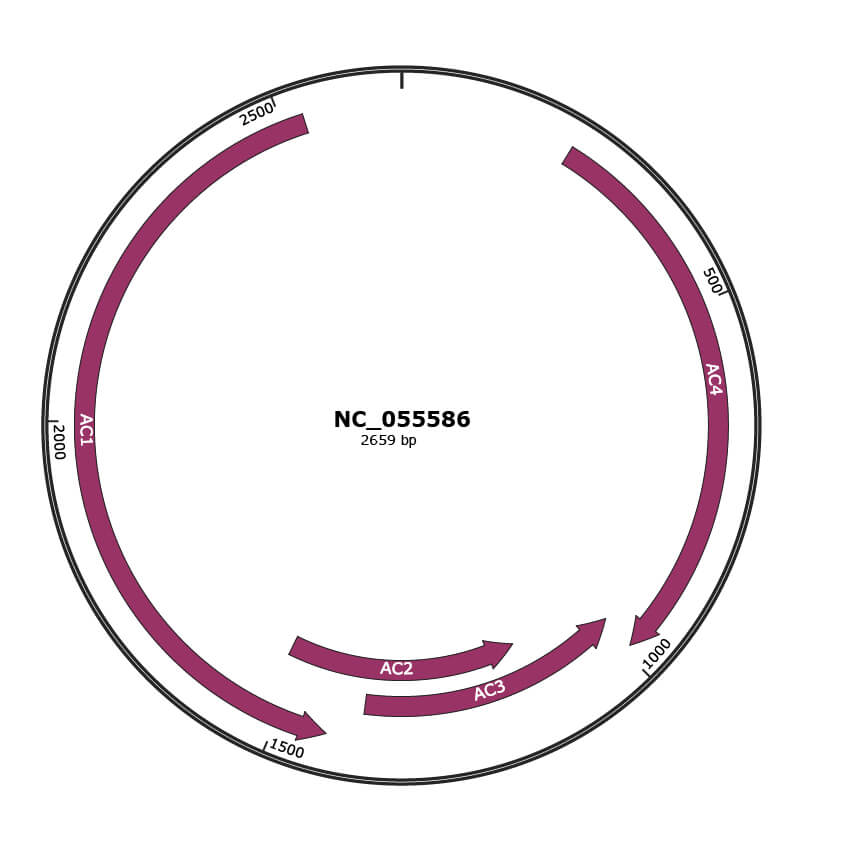
JBrowse
Genome
ACTGGATGGCCGCGATTTTTTTCCCCCCCTCATGACGTGGCGCTCGCTCCCCGACCCGCTCCCGCAATTCGCGCCGCATTGTCGGCCATTATATGTGGTCCCTTTCAGATAAAGACAAATTTGACTGACCAATCCGACTTGGGCCTCTGGGCCTATTTGTTTAAAAATACTTGGGCGCTAAGTTGTTATATAAAGGGTTATGATATGATGGCCCAATAAGCTTTATTTCAAAAATGCCTAAGCGGTATCCCCCATTCCGCACAACGGCGGGAACGTCCAAGATTTCCCGCACGTCCAATTTATCTCCTCGTGGGGGTGTTCGGCCCAAATTCGACAAGGCCGCAGAGTGGGTCAACAGGCCCATGTACAGGAAGCCCAGGATATACCGGACGTTGAGAAGCCCAGACATTCCGAGGGGTTGTGAAGGGCCTTGTAAAGTCCAATCGTTCGAACAGCGTCATGACGTCTCTCATACCGGGAAGGTGTTGTGTATATCTGATGTGACACGGGGTAATGGCATTACTCACCGTGTCGGTAAACGTTTTTGCGTTAAGTCTGTATATATATTAGGGAAGGTATGGATGGACGACAATATTAAGCTGAAGAACCATACGAATAGCGTATTGTTCTGGTTAGTTAGGGACAGGAGGCCGTATGGTACCCCTATGGACTTCGGCCAGGTGTTCAACATGTACGATAACGAGCCCAGTACTGCGACTGTGAAGAACGATCTCCGCGATCGTCTCCAAGTCATGCACAGGTTCTCCGCGAAGGTTACGGGTGGACAGTATGCCAGTAACGAGCAGGCTGTGGTGCGGCGTTTTTGGAAGGTGTACAATCATGTGGTCTACAACCATCAGGAGGCCGCGAAGTACGAGAAYCACACGGAGAATGCCCTGTTATTGTATATGGCATGTACTCATGCCTCGAACCCTGTATATGCAACCCTTAAGATCCGGATCTATTTTTATGATTCGATCTTAAATTAATAAAAATTGAACTTTATTGAATGATCCTCCAGTACATCTGTTACATACGTCTTGTCTGTTGCGAATTGAACAGCTCTAATGACATTATTAATTGAGATTACGCCTAATTGATCTAAATACATATTGACTAAGAATTTAAATCTATTTAAATAAGTCGTCCCAGAAGCTGTCAGAGAAGTCGTCCAGACTTGGAAGTTGAAGTATGCCTTGTGGAGATCCAACGCTCTCCTCAGGTTGTGGTTGAATCGTATCTGGACATGGTACACTGTCGTGTTGGCGTGGAGCAAAATCTCCACGTTGGTTATCTTGAAATACAGGGGATTTTGCACCTCCCAGGTATACACGCCATTCTCCGCTTGACGTCGCGTGATGCGTTCCCCTGTGCGTGAATCCATGTCCTCGGCAGTCGATGTGGAGGTATATTGAGCAACCGCACTCTAAATCAATTCGTCTTCTCCGAATGGCCCTCTTCTTCTTGGCTATTCTGTGTTGTGGTTTGATAGAGGGGGGAGTTGAGGAAGACGAATTTTGCATTGTGGAGAGTCCAGTTCTTGAGTGACAGATTCTCCTCTTTGTCGAGGAACTCTTTATAACTGGACCCCTCGCCTGGATTGCAAAGCACGATTGAGGGTATGCCGCCTTTAATTTGAACCGGCTTTCCGTATTTGCAATTTGATTGCCAGTCCCTTTGGGCCCCAATCAATTCTTTCCTGTGCTTCATCTTTAGGTAGTGCGGTGCGACGTCATCAATGACGTTATAATCCACATCATTTGAATAAACCCTAGAATTGAAATCCAGGTGTCCACTCAAATAATTGTGAGATCCCAAAGCACGTGCCCACATCGTCTTGCCGGTTCTTGAATCACCCTCCACGATGATGGACACTGGCCTGAGACTATTATGAAAATGTGGCCGCGCAGCGGAAAGACGACCAAAATAATCATCCGCCCACTCTTGCATCTCATCCGGAACGTTAGTGAAAGAGGAGAGTTGAAACGGAGGAGTCCATGGCTCCGGAGACTGAGCGAATATCTTGTGGATATTAGCACTGATGTTGTGATGTTGAACGATGAATGCCTTTGGATCTCCTGTCCGGATAATTGCAAGAGCCTCTGATGCAGAAGTGGCATTGATAGCGTTGTGATAGACGTCGTCTTTGTTGGTCTTTGTTCCGCCAGATATTTTGTATCGTCCGGATTCACAATAATCACCCTCTTTGGTGATGTAATTCTTGACGGCGTTGGCGTCTTTGGCTGCCTGGACGTTTGGGTGAAAATTGGCAGACCTTCTGGGGTGAGTAAGGTCGAAAAATCTAACATCCTTGATGTTCGACTTCCCTGATAGTTGTATGAGGCAGTGGAGATGAGGTTGTCCGTCAGTGTGTTCCTCTCTTGCGACTCTGATGTACGTCGGTTTGACGACCGTCCATTTGAGGGAATGAAGCATCCGAAGAACCTCATCTTTCTCTATGTCGCACTGTGGATAAGTGAGGAAGATGTTCTTAGCAGATAGCCTAAATGTAGTAGGTTGTCGTGGCATTTTTGTAAATATGAGCCAGGACACCAGGGATGGCTCTCAACTTCTGTGCTATTTGCTGGTGTCCTGGTGTCCCATTTATACTAAAACCTCCTTTGGACACCAGGGGTAAAAGCGGCCATCCTATAATATT
Gene Information
|
NCBI Accession
|
YP_010087798.1
|
|
Location
|
234-989 |
|
Gene Name
|
AC4 |
|
Protein Name
|
Cp |
|
Coding Region
|
ATGCCTAAGCGGTATCCCCCATTCCGCACAACGGCGGGAACGTCCAAGATTTCCCGCACGTCCAATTTATCTCCTCGTGGGGGTGTTCGGCCCAAATTCGACAAGGCCGCAGAGTGGGTCAACAGGCCCATGTACAGGAAGCCCAGGATATACCGGACGTTGAGAAGCCCAGACATTCCGAGGGGTTGTGAAGGGCCTTGTAAAGTCCAATCGTTCGAACAGCGTCATGACGTCTCTCATACCGGGAAGGTGTTGTGTATATCTGATGTGACACGGGGTAATGGCATTACTCACCGTGTCGGTAAACGTTTTTGCGTTAAGTCTGTATATATATTAGGGAAGGTATGGATGGACGACAATATTAAGCTGAAGAACCATACGAATAGCGTATTGTTCTGGTTAGTTAGGGACAGGAGGCCGTATGGTACCCCTATGGACTTCGGCCAGGTGTTCAACATGTACGATAACGAGCCCAGTACTGCGACTGTGAAGAACGATCTCCGCGATCGTCTCCAAGTCATGCACAGGTTCTCCGCGAAGGTTACGGGTGGACAGTATGCCAGTAACGAGCAGGCTGTGGTGCGGCGTTTTTGGAAGGTGTACAATCATGTGGTCTACAACCATCAGGAGGCCGCGAAGTACGAGAAYCACACGGAGAATGCCCTGTTATTGTATATGGCATGTACTCATGCCTCGAACCCTGTATATGCAACCCTTAAGATCCGGATCTATTTTTATGATTCGATCTTAAATTAA |
|
Protein Sequence
|
MPKRYPPFRTTAGTSKISRTSNLSPRGGVRPKFDKAAEWVNRPMYRKPRIYRTLRSPDIPRGCEGPCKVQSFEQRHDVSHTGKVLCISDVTRGNGITHRVGKRFCVKSVYILGKVWMDDNIKLKNHTNSVLFWLVRDRRPYGTPMDFGQVFNMYDNEPSTATVKNDLRDRLQVMHRFSAKVTGGQYASNEQAVVRRFWKVYNHVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSILN |
|
NCBI Accession
|
YP_010087799.1
|
|
Location
|
986-1384 |
|
Gene Name
|
AC3 |
|
Protein Name
|
Ren |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACGCATCACGCGACGTCAAGCGGAGAATGGCGTGTATACCTGGGAGGTGCAAAATCCCCTGTATTTCAAGATAACCAACGTGGAGATTTTGCTCCACGCCAACACGACAGTGTACCATGTCCAGATACGATTCAACCACAACCTGAGGAGAGCGTTGGATCTCCACAAGGCATACTTCAACTTCCAAGTCTGGACGACTTCTCTGACAGCTTCTGGGACGACTTATTTAAATAGATTTAAATTCTTAGTCAATATGTATTTAGATCAATTAGGCGTAATCTCAATTAATAATGTCATTAGAGCTGTTCAATTCGCAACAGACAAGACGTATGTAACAGATGTACTGGAGGATCATTCAATAAAGTTCAATTTTTATTAA |
|
Protein Sequence
|
MDSRTGERITRRQAENGVYTWEVQNPLYFKITNVEILLHANTTVYHVQIRFNHNLRRALDLHKAYFNFQVWTTSLTASGTTYLNRFKFLVNMYLDQLGVISINNVIRAVQFATDKTYVTDVLEDHSIKFNFY |
|
NCBI Accession
|
YP_010087800.1
|
|
Location
|
1131-1523 |
|
Gene Name
|
AC2 |
|
Protein Name
|
TRaP |
|
Coding Region
|
ATGCAAAATTCGTCTTCCTCAACTCCCCCCTCTATCAAACCACAACACAGAATAGCCAAGAAGAAGAGGGCCATTCGGAGAAGACGAATTGATTTAGAGTGCGGTTGCTCAATATACCTCCACATCGACTGCCGAGGACATGGATTCACGCACAGGGGAACGCATCACGCGACGTCAAGCGGAGAATGGCGTGTATACCTGGGAGGTGCAAAATCCCCTGTATTTCAAGATAACCAACGTGGAGATTTTGCTCCACGCCAACACGACAGTGTACCATGTCCAGATACGATTCAACCACAACCTGAGGAGAGCGTTGGATCTCCACAAGGCATACTTCAACTTCCAAGTCTGGACGACTTCTCTGACAGCTTCTGGGACGACTTATTTAAATAG |
|
Protein Sequence
|
MQNSSSSTPPSIKPQHRIAKKKRAIRRRRIDLECGCSIYLHIDCRGHGFTHRGTHHATSSGEWRVYLGGAKSPVFQDNQRGDFAPRQHDSVPCPDTIQPQPEESVGSPQGILQLPSLDDFSDSFWDDLFK |
|
NCBI Accession
|
YP_010087801.1
|
|
Location
|
1432-2529 |
|
Gene Name
|
AC1 |
|
Protein Name
|
REp |
|
Coding Region
|
ATGCCACGACAACCTACTACATTTAGGCTATCTGCTAAGAACATCTTCCTCACTTATCCACAGTGCGACATAGAGAAAGATGAGGTTCTTCGGATGCTTCATTCCCTCAAATGGACGGTCGTCAAACCGACGTACATCAGAGTCGCAAGAGAGGAACACACTGACGGACAACCTCATCTCCACTGCCTCATACAACTATCAGGGAAGTCGAACATCAAGGATGTTAGATTTTTCGACCTTACTCACCCCAGAAGGTCTGCCAATTTTCACCCAAACGTCCAGGCAGCCAAAGACGCCAACGCCGTCAAGAATTACATCACCAAAGAGGGTGATTATTGTGAATCCGGACGATACAAAATATCTGGCGGAACAAAGACCAACAAAGACGACGTCTATCACAACGCTATCAATGCCACTTCTGCATCAGAGGCTCTTGCAATTATCCGGACAGGAGATCCAAAGGCATTCATCGTTCAACATCACAACATCAGTGCTAATATCCACAAGATATTCGCTCAGTCTCCGGAGCCATGGACTCCTCCGTTTCAACTCTCCTCTTTCACTAACGTTCCGGATGAGATGCAAGAGTGGGCGGATGATTATTTTGGTCGTCTTTCCGCTGCGCGGCCACATTTTCATAATAGTCTCAGGCCAGTGTCCATCATCGTGGAGGGTGATTCAAGAACCGGCAAGACGATGTGGGCACGTGCTTTGGGATCTCACAATTATTTGAGTGGACACCTGGATTTCAATTCTAGGGTTTATTCAAATGATGTGGATTATAACGTCATTGATGACGTCGCACCGCACTACCTAAAGATGAAGCACAGGAAAGAATTGATTGGGGCCCAAAGGGACTGGCAATCAAATTGCAAATACGGAAAGCCGGTTCAAATTAAAGGCGGCATACCCTCAATCGTGCTTTGCAATCCAGGCGAGGGGTCCAGTTATAAAGAGTTCCTCGACAAAGAGGAGAATCTGTCACTCAAGAACTGGACTCTCCACAATGCAAAATTCGTCTTCCTCAACTCCCCCCTCTATCAAACCACAACACAGAATAGCCAAGAAGAAGAGGGCCATTCGGAGAAGACGAATTGA |
|
Protein Sequence
|
MPRQPTTFRLSAKNIFLTYPQCDIEKDEVLRMLHSLKWTVVKPTYIRVAREEHTDGQPHLHCLIQLSGKSNIKDVRFFDLTHPRRSANFHPNVQAAKDANAVKNYITKEGDYCESGRYKISGGTKTNKDDVYHNAINATSASEALAIIRTGDPKAFIVQHHNISANIHKIFAQSPEPWTPPFQLSSFTNVPDEMQEWADDYFGRLSAARPHFHNSLRPVSIIVEGDSRTGKTMWARALGSHNYLSGHLDFNSRVYSNDVDYNVIDDVAPHYLKMKHRKELIGAQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGSSYKEFLDKEENLSLKNWTLHNAKFVFLNSPLYQTTTQNSQEEEGHSEKTN |