Tomato yellow leaf curl Mali virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_001028945.1 |
| Isolate |
Burkina Faso |
| Release date |
2015/6/17 |
| Submitter |
Sattar,M.N., Koutou,M., Husseini,S., Leke,W.N., Brown,J.K., Kvarnheden,A. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
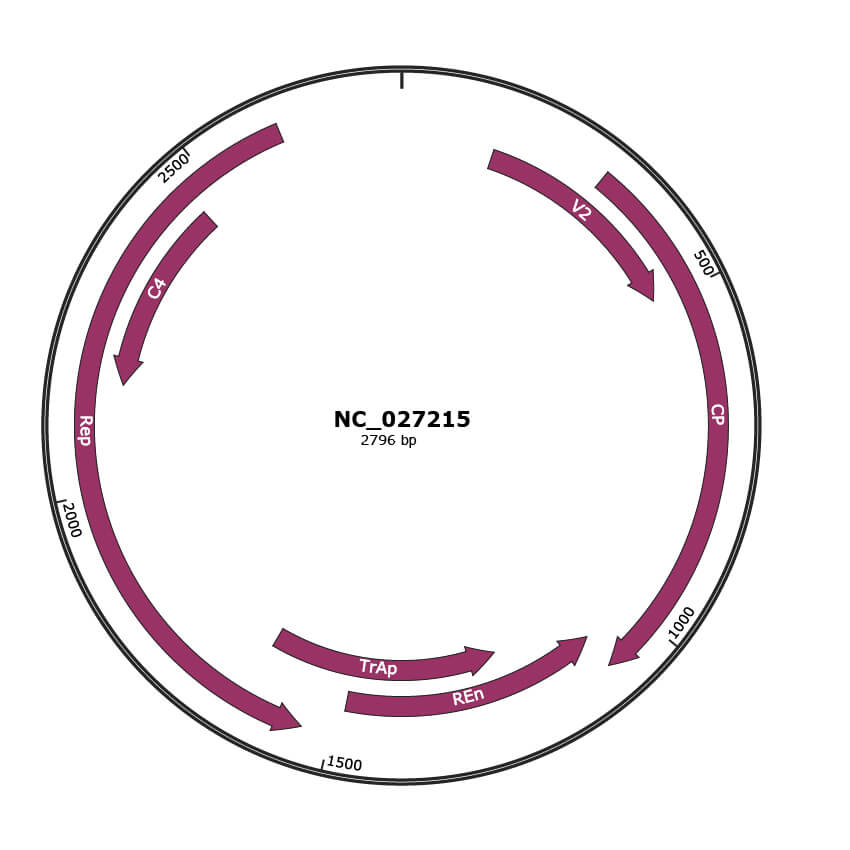
JBrowse
Genome
ACCGGATGGCCGCGCCCTTCCTTTTGTGGTCCCCATTCGGGTCCTATAGACGTCACTATCAACCAATCAAATTGCATCCTCAAACGTTAGATAAGTGTTTATTTGTCTTTATATACTTGTTCTCCAAGTTTTTTGTCATATAATATGTGGGATCCACTCTTAAATGAATTCCCTGAATCTGTTCACGGATTTCGTTGTATGTTAGCTGTTAAATATTTGCAGGCCGTTGAGGAAACATATGAGCCCAATACTTTGGGCCACGATTTAATTAGGGATCTTATATCTGTTGTAAGGGCCCGTGACTATGTTGAAGCGACCCGGCGATATAATCATTTCCACACCCGCCTCGAAGGTTCGCCGAAGGCTGAACTTCGACAGCCCATACAGCAGCCGTGCTGCTGCCCCCATTGTCCAAGGCATAAACAAGCGACGGTCATGGACGTACAGGCCCATGTACCGAAAGCCCAGAATATACAGAATGTATCGAAGCCCTGATGTTCCCCGTGGATGTGAAGGCCCATGTAAGGTCCAATCTTATGAGCAACGGGATGACATTAAGCATACTGGTATTGTTCGTTGTGTTAGTGATGTTACTCGTGGTTCTGGTATTACCCACAGAGTGGGTAAGAGGTTCTGTGTTAAGTCCATTTATTTTTTAGGTAAGGTCTGGATGGATGAAAATATCAAGAAGCAGAACCATACTAATCAAGTCATGTTCTTCTTGGTCCGTGATAGAAGGCCCTATGGAAACAGCCCAATGGATTTTGGACAGGTTTTTAATATGTTCGATAATGAGCCGAGTACCGCAACAGTGAAGAATGATCTCCGGGATAGGTTTCAAGTGATGAGGAAATTTCATGCTACCGTTATTGGTGGGCCTTCTGGAATGAAGGAACAGGCTTTAGTTAAGAGATTCTTTAGAGTTAACAGTCATGTAACTTATAATCATCAGGAGGCAGCCAAGTATGAGAATCATACTGAAAACGCCTTGTTATTGTATATGGCATGTACTCATGCCTCTAATCCAGTGTATGCAACTATGAAAATACGCATCTACTTCTATGATTCAATATCAAATTAATAAAAATTAAATTTTATATCATGGGTTTCTGTTACATCTATTGTCTTTTCAAGTACATCATACAATACATGGTCAACTGCTCTAATTACATTGTTAATGGAAATTACACCTAAACTATCTAAATACTTAAGAACTTGATATCTTCTAAATACTTTTAAGAAACGACCAGTCTGAGGCCGTAAGGTCGTCCAGATTCGGAAGTTGAGAAAACATTTGTGAATCCCCAGTACCTTCCTGATGTTGTGATTGAAGCGGATCTGCATTGAAATGATGTCGTGATCCATGTTGAATGGTTTCTGGCTGTGTTCTGTTATCTTGAAATATAGGGGATTGTTTATCTCCCAGATAAAAACGCCATTCTCTGCTTGAGGAGCAGTGATGAGTTCCCCTGTGCGCAAATCCATGGTTGATGCAGTTGATGTGAAGATAGTATGAGCAGCCACAGTCTAGGTCTACACGCTTACGCCTGATTGGTTTCTTCTTGGCTATCTTGTGTTGGACCTTGATTGGTACTTGAGAACAGTGGCTTATAGAGGGTGATGAAGGTTGCATTCTTGAGAGCCCAATTTTTCAATGACAGGTTTTTTTCTTCATCTAGATATTCTCTATACGATGAAGTAGGTCCTGGATTGCAGAGGAAGATAGTGGGAATTCCACCTTTAATTTGAATGGGTTTCCCGTATTTTGTGTTGCTCTGCCAGTCCCTTTGGGCCCCCATGAATTCTTTAAAGTGCTTTAAATAATGCGGGTCTACGTCATCAATGACGTTGTACCACGCATCATTTGAAAATATCTTAGGGCTGAGATCGAGATGTCCACACAAATAATTGTGTGGACCTAACGATCGTGCCCACATTGTTTTTCCGGTACGACTATCACCTTCGATTACAATACTATCAGGTCTCCATGGCCGCGCAGCGGAAGACATGACGTTCTCGGACACCCATACCTCAAGTTCCTCTGGAACTTGATTAAAAGAAGAAGATAAAAAAGGAGAAATATAAGGACCTGGAGGCTCCTGAAAAATTCTATCTAAATTACTATTTAAATTATGAAACTGTAAAACGTAATCTTTGGGGGCTAGTTCCCTAATGACTCTAAGAGCTTCCGACTTACTTCTTGAGTTAAGAGCTGCTGCGTAAGCATCGTTTGCAGATTGTTGTCCCCCCCTTGCAGACCTTCCATCGATCTGAAACTCTCCCCAATCGATGGTGTCTCCATCCTTATCGATGTAGGACTTGACATCAGATGATGATTTAGCTCCCTGAATGTTTGGATGGAAATGTGTTGATCTACTTGGGGATACCAGGTCGAAGAATCTGTTATTTGTGCACTGGTACTTTCCTTCGAACTGAACAAGGGCATGCAGATGAGGTTCCCCATTTTCGTGAAGCTCTCTGCAAATTTTAATGTATAATTTATTTACAGGAGTTTCTAGGGTTTGTAGTTGGGAAAGGGCTTCAGTTAATGAAAGAGAACACTGGGGATAAGTAAGGAAATAATTTTTGGCATTTATTTTAAAACGCTTTGGGGGAGCCATTTGGTCAATGTACCCCGATTGACTTGGATTTCATTTGGCACCTGCAATCGGTGTAATGGGGTACAATTTATACTTGTACCCCAAATGGCAATGTTGTAATTTTGCAAAAGTAAATTGCAATTAAAAATTCAAAATTCAAAAATCAAATCATTAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_009143522.1
|
|
Location
|
145-495 |
|
Gene Name
|
V2 |
|
Protein Name
|
pre coat protein |
|
Coding Region
|
ATGTGGGATCCACTCTTAAATGAATTCCCTGAATCTGTTCACGGATTTCGTTGTATGTTAGCTGTTAAATATTTGCAGGCCGTTGAGGAAACATATGAGCCCAATACTTTGGGCCACGATTTAATTAGGGATCTTATATCTGTTGTAAGGGCCCGTGACTATGTTGAAGCGACCCGGCGATATAATCATTTCCACACCCGCCTCGAAGGTTCGCCGAAGGCTGAACTTCGACAGCCCATACAGCAGCCGTGCTGCTGCCCCCATTGTCCAAGGCATAAACAAGCGACGGTCATGGACGTACAGGCCCATGTACCGAAAGCCCAGAATATACAGAATGTATCGAAGCCCTGA |
|
Protein Sequence
|
MWDPLLNEFPESVHGFRCMLAVKYLQAVEETYEPNTLGHDLIRDLISVVRARDYVEATRRYNHFHTRLEGSPKAELRQPIQQPCCCPHCPRHKQATVMDVQAHVPKAQNIQNVSKP |
|
NCBI Accession
|
YP_009143523.1
|
|
Location
|
305-1081 |
|
Gene Name
|
CP |
|
Protein Name
|
Coat Protein |
|
Coding Region
|
ATGTTGAAGCGACCCGGCGATATAATCATTTCCACACCCGCCTCGAAGGTTCGCCGAAGGCTGAACTTCGACAGCCCATACAGCAGCCGTGCTGCTGCCCCCATTGTCCAAGGCATAAACAAGCGACGGTCATGGACGTACAGGCCCATGTACCGAAAGCCCAGAATATACAGAATGTATCGAAGCCCTGATGTTCCCCGTGGATGTGAAGGCCCATGTAAGGTCCAATCTTATGAGCAACGGGATGACATTAAGCATACTGGTATTGTTCGTTGTGTTAGTGATGTTACTCGTGGTTCTGGTATTACCCACAGAGTGGGTAAGAGGTTCTGTGTTAAGTCCATTTATTTTTTAGGTAAGGTCTGGATGGATGAAAATATCAAGAAGCAGAACCATACTAATCAAGTCATGTTCTTCTTGGTCCGTGATAGAAGGCCCTATGGAAACAGCCCAATGGATTTTGGACAGGTTTTTAATATGTTCGATAATGAGCCGAGTACCGCAACAGTGAAGAATGATCTCCGGGATAGGTTTCAAGTGATGAGGAAATTTCATGCTACCGTTATTGGTGGGCCTTCTGGAATGAAGGAACAGGCTTTAGTTAAGAGATTCTTTAGAGTTAACAGTCATGTAACTTATAATCATCAGGAGGCAGCCAAGTATGAGAATCATACTGAAAACGCCTTGTTATTGTATATGGCATGTACTCATGCCTCTAATCCAGTGTATGCAACTATGAAAATACGCATCTACTTCTATGATTCAATATCAAATTAA |
|
Protein Sequence
|
MLKRPGDIIISTPASKVRRRLNFDSPYSSRAAAPIVQGINKRRSWTYRPMYRKPRIYRMYRSPDVPRGCEGPCKVQSYEQRDDIKHTGIVRCVSDVTRGSGITHRVGKRFCVKSIYFLGKVWMDENIKKQNHTNQVMFFLVRDRRPYGNSPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMRKFHATVIGGPSGMKEQALVKRFFRVNSHVTYNHQEAAKYENHTENALLLYMACTHASNPVYATMKIRIYFYDSISN |
|
NCBI Accession
|
YP_009143524.1
|
|
Location
|
1078-1485 |
|
Gene Name
|
REn |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTTGCGCACAGGGGAACTCATCACTGCTCCTCAAGCAGAGAATGGCGTTTTTATCTGGGAGATAAACAATCCCCTATATTTCAAGATAACAGAACACAGCCAGAAACCATTCAACATGGATCACGACATCATTTCAATGCAGATCCGCTTCAATCACAACATCAGGAAGGTACTGGGGATTCACAAATGTTTTCTCAACTTCCGAATCTGGACGACCTTACGGCCTCAGACTGGTCGTTTCTTAAAAGTATTTAGAAGATATCAAGTTCTTAAGTATTTAGATAGTTTAGGTGTAATTTCCATTAACAATGTAATTAGAGCAGTTGACCATGTATTGTATGATGTACTTGAAAAGACAATAGATGTAACAGAAACCCATGATATAAAATTTAATTTTTATTAA |
|
Protein Sequence
|
MDLRTGELITAPQAENGVFIWEINNPLYFKITEHSQKPFNMDHDIISMQIRFNHNIRKVLGIHKCFLNFRIWTTLRPQTGRFLKVFRRYQVLKYLDSLGVISINNVIRAVDHVLYDVLEKTIDVTETHDIKFNFY |
|
NCBI Accession
|
YP_009143525.1
|
|
Location
|
1226-1633 |
|
Gene Name
|
TrAp |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCAACCTTCATCACCCTCTATAAGCCACTGTTCTCAAGTACCAATCAAGGTCCAACACAAGATAGCCAAGAAGAAACCAATCAGGCGTAAGCGTGTAGACCTAGACTGTGGCTGCTCATACTATCTTCACATCAACTGCATCAACCATGGATTTGCGCACAGGGGAACTCATCACTGCTCCTCAAGCAGAGAATGGCGTTTTTATCTGGGAGATAAACAATCCCCTATATTTCAAGATAACAGAACACAGCCAGAAACCATTCAACATGGATCACGACATCATTTCAATGCAGATCCGCTTCAATCACAACATCAGGAAGGTACTGGGGATTCACAAATGTTTTCTCAACTTCCGAATCTGGACGACCTTACGGCCTCAGACTGGTCGTTTCTTAAAAGTATTTAG |
|
Protein Sequence
|
MQPSSPSISHCSQVPIKVQHKIAKKKPIRRKRVDLDCGCSYYLHINCINHGFAHRGTHHCSSSREWRFYLGDKQSPIFQDNRTQPETIQHGSRHHFNADPLQSQHQEGTGDSQMFSQLPNLDDLTASDWSFLKSI |
|
NCBI Accession
|
YP_009143526.1
|
|
Location
|
1542-2621 |
|
Gene Name
|
Rep |
|
Protein Name
|
Replication Associate Protein |
|
Coding Region
|
ATGGCTCCCCCAAAGCGTTTTAAAATAAATGCCAAAAATTATTTCCTTACTTATCCCCAGTGTTCTCTTTCATTAACTGAAGCCCTTTCCCAACTACAAACCCTAGAAACTCCTGTAAATAAATTATACATTAAAATTTGCAGAGAGCTTCACGAAAATGGGGAACCTCATCTGCATGCCCTTGTTCAGTTCGAAGGAAAGTACCAGTGCACAAATAACAGATTCTTCGACCTGGTATCCCCAAGTAGATCAACACATTTCCATCCAAACATTCAGGGAGCTAAATCATCATCTGATGTCAAGTCCTACATCGATAAGGATGGAGACACCATCGATTGGGGAGAGTTTCAGATCGATGGAAGGTCTGCAAGGGGGGGACAACAATCTGCAAACGATGCTTACGCAGCAGCTCTTAACTCAAGAAGTAAGTCGGAAGCTCTTAGAGTCATTAGGGAACTAGCCCCCAAAGATTACGTTTTACAGTTTCATAATTTAAATAGTAATTTAGATAGAATTTTTCAGGAGCCTCCAGGTCCTTATATTTCTCCTTTTTTATCTTCTTCTTTTAATCAAGTTCCAGAGGAACTTGAGGTATGGGTGTCCGAGAACGTCATGTCTTCCGCTGCGCGGCCATGGAGACCTGATAGTATTGTAATCGAAGGTGATAGTCGTACCGGAAAAACAATGTGGGCACGATCGTTAGGTCCACACAATTATTTGTGTGGACATCTCGATCTCAGCCCTAAGATATTTTCAAATGATGCGTGGTACAACGTCATTGATGACGTAGACCCGCATTATTTAAAGCACTTTAAAGAATTCATGGGGGCCCAAAGGGACTGGCAGAGCAACACAAAATACGGGAAACCCATTCAAATTAAAGGTGGAATTCCCACTATCTTCCTCTGCAATCCAGGACCTACTTCATCGTATAGAGAATATCTAGATGAAGAAAAAAACCTGTCATTGAAAAATTGGGCTCTCAAGAATGCAACCTTCATCACCCTCTATAAGCCACTGTTCTCAAGTACCAATCAAGGTCCAACACAAGATAGCCAAGAAGAAACCAATCAGGCGTAA |
|
Protein Sequence
|
MAPPKRFKINAKNYFLTYPQCSLSLTEALSQLQTLETPVNKLYIKICRELHENGEPHLHALVQFEGKYQCTNNRFFDLVSPSRSTHFHPNIQGAKSSSDVKSYIDKDGDTIDWGEFQIDGRSARGGQQSANDAYAAALNSRSKSEALRVIRELAPKDYVLQFHNLNSNLDRIFQEPPGPYISPFLSSSFNQVPEELEVWVSENVMSSAARPWRPDSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKIFSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYREYLDEEKNLSLKNWALKNATFITLYKPLFSSTNQGPTQDSQEETNQA |
|
NCBI Accession
|
YP_009143527.1
|
|
Location
|
2162-2464 |
|
Gene Name
|
C4 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGGGAACCTCATCTGCATGCCCTTGTTCAGTTCGAAGGAAAGTACCAGTGCACAAATAACAGATTCTTCGACCTGGTATCCCCAAGTAGATCAACACATTTCCATCCAAACATTCAGGGAGCTAAATCATCATCTGATGTCAAGTCCTACATCGATAAGGATGGAGACACCATCGATTGGGGAGAGTTTCAGATCGATGGAAGGTCTGCAAGGGGGGGACAACAATCTGCAAACGATGCTTACGCAGCAGCTCTTAACTCAAGAAGTAAGTCGGAAGCTCTTAGAGTCATTAGGGAACTAG |
|
Protein Sequence
|
MGNLICMPLFSSKESTSAQITDSSTWYPQVDQHISIQTFRELNHHLMSSPTSIRMETPSIGESFRSMEGLQGGDNNLQTMLTQQLLTQEVSRKLLESLGN |