Tomato yellow leaf curl Kanchanaburi virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000840985.1 |
| Isolate |
Thailand: Kanchanaburi |
| Release date |
2015/2/12 |
| Submitter |
Green,S.K., Tsai,W.S., Shih,S.L., Rezaian,M.A., Duangsong,U. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
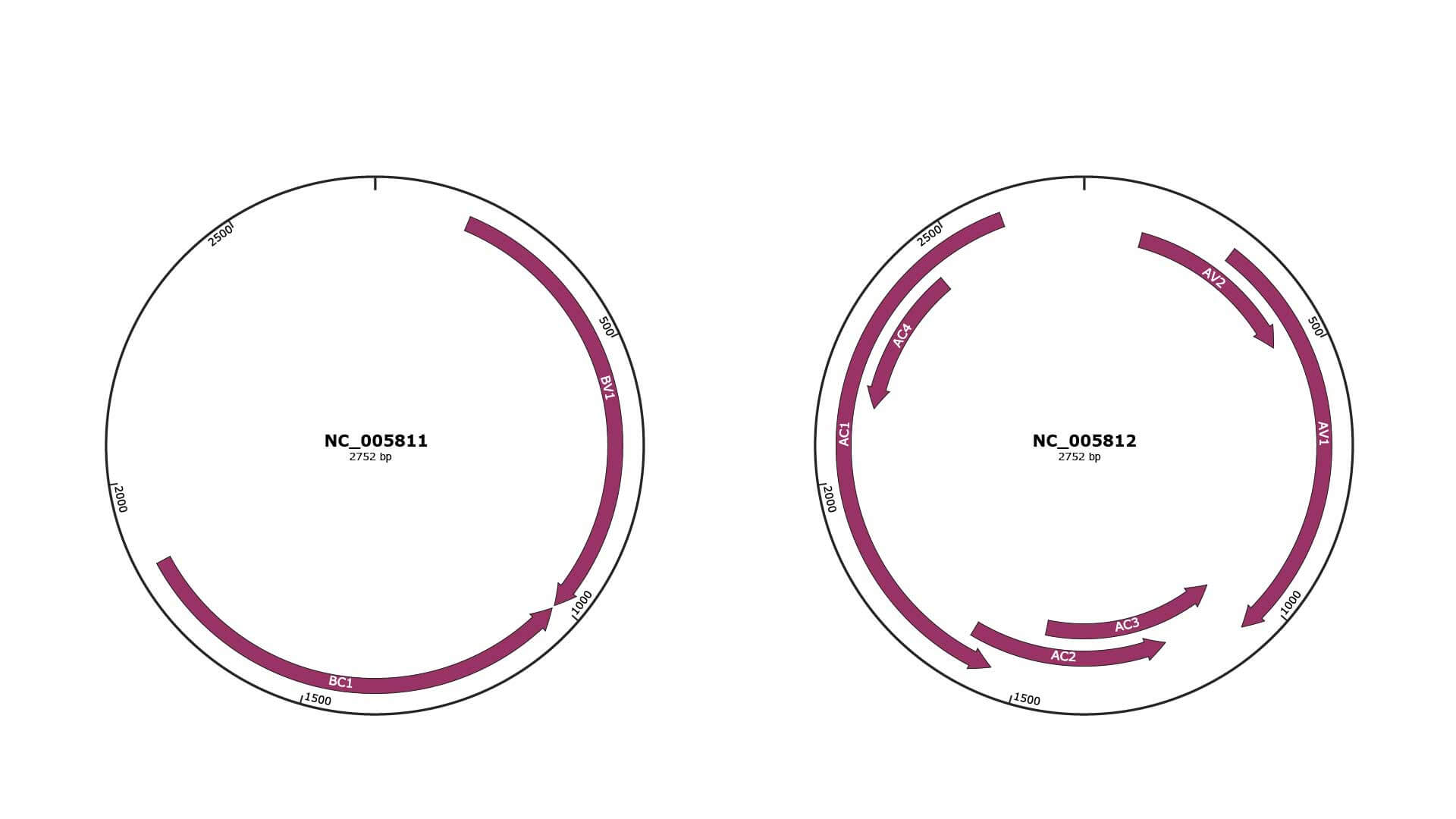
JBrowse
Genome
ACCGAGGGCCGCGGGTTTTTTGGTGTCCCGACCCCACTCCTGACATCATTGTCCCTTTTTGAATAATCTGAGCCGTTGCAAGGTAACACGTGTTACCATCTTAAGTCAGGAGCTTTTTAATGTTCTGACTATATATTGGTGTTATTTATTTTTCATCTCATTTGTAACTAAAAATGAGAGTTCCAATCCGGAGGAATTCAGGTTTTAATTCTGACCGTCGTCCTTCAAATGGTTCAATCCACCGGTGGAATTACCCATATTCCGGCTATTTTGGCAGGAGGATTGGCAACCGCGTATATGGCATGCCATTTGGAAGCCGTCAAGTTCAAAGACGTGAATTTCAGCAGACTCATCGTCCTATCAAGTTTTCTGACCATGTTTCTTCTCGGAGGAAGTTTATGAAGACTATAGAGGAAATTCACGATGGCACTGACTACTTGCTTTGCAATAACATGTCCAAGGTGTCATACATTAGTTACCCTCCTCTATCCGGTACTGAACATGGTAGTAGAGCTGAATCCTATCTCAAAGTCCTGGGTTTTAATGTATCTGGGTCTGTTGTGCTGAAGCAGCTGCACATGCGTGAAGCAGATATGTCTCAAGGAATTCATGGTATATTTACCACAGTAATTGTTCGTGATAAGAGACCATGTCAGTTCTCTGCTGTGGATCCTATCATCCCATTTGTTGAGTTATTTGGACCAGAAAAGAGAGCATGCTCCACATTACATGTTAGAGATTCTTATAAGAATCGATTTAGTGTTGTCTATCAAAAGAAACATGTTGTAAATAGTGCTCTGACAACACATGTATTTAGGTATAATTTTAATGTTAAGTTTTCTAGGTTTCCTTTCTGGGTGTCTTTCAAAGACACATCCAATGCAGAGCCTACTGGACTATATTCTAATGTTTCTAAGAACGCATTGGTGGTGTACTACGTGTGGCTGTGTGATTCAAATGTAACAGCCGAAGTGCACGTACAGTATGATTTGAACTATATTGGATAAATAAAATCATATTTTTTTTACATTTGAGGAGACATTACTCCCTTCCATACATAATTCAACTGTTTTTTTAATAATATTAATTACATCATCATTCACTTTGTTGCTACATGCAACAACTTCCGATGCCGAAGGGCCAGGATCTAGAGTTGCATCTTGCAGCTGATGCAAATGTCTGTATGGGTATTCCTCTATCTCGTTGTTCCCCACTGCGCTGGCTGAAGCCCAGGTATGCCCTTGTGGAATGGCATTTGTAGTGTATCTGGAAGACTGTGACCTCATTTGTGATAGGGCTTGTACTGGTTTCCTTGATACCTTGGACTGAGGCACATGCCAGAAATCTATGTGGTTCATGTTATATGCCTTTGACAGTATTACAATTTTTGGGGACTTAAATGTTATTTCAGATGACTGTTTTGCAGAGGACATTTTTAACTTCCCTTGCATCCTACAAAAGTGAACACCATTGACCACGTTAGTGTCGTCCACCCTGTACAGCACCCTCCATGGATTTGGATCTTTGGGGGAGAAGTATGAGGATGAGTAGTAGTGGATATTGCAGTTACACCCTATGGGTATTGTGAACTCAGCCTGCTTTGAGTCTCCTTCATGTAACCTTGTGTCGTGCATTTCTATGACCACATGCCCAGTTGCATTGACAGGTACTTGGTTCCTGTATTGGAGGATGACATGGTCAATCCTGAGACACTTTCCCAGGAGCATTGATAATTTTTGATCGACGGTTGAGGGAAACAACAGAGTGACTTCTGTTTTTTCATTGGACAGCTGAAATTCAGTCCTATCCGACGTCGTATAGGCAATACTGTTATTGTTGGACTCCATTATTGCTGATGCCAATATAATAATGATAATTCAGCTTTTTATAGACTTTTCAGAGACTGTCAGGATAGTGGAATGTGACTATTTCAGTCTATGCCTTTAAATTCCACTATCTTAAAGATCCAATGAGATACGTCCACGTATGTACTCAAACTGACAAGAGATAAGGTTATATACTTGGTTGTGGTTCAGCCACGTCGCATATTTAATAGTGGAATACAGCTGTATTCCACCATCACTTCCTTCCATTGGAAGTTTTGAAAGATATTATCTTGGCGTATTTTATAACAATAATAACTTAATTAATAATTTAATTAAGAATTAAATTAAGGAATTAGCTCCAAAGGACTATGTACTGCAGTACCACAACCTAAATGCTAATTTGGACAGGATATTTGCCCCAATCCAAGAATTATTTGTTAATCCTTACGAGTTGTCGTGAAATCGACAATTTAGAGTAATTTTTAACTGATCCAACAAACTAATTATGAGAAAACACACACGTTTGAACATCCTAATCTTGAGAAAATCCCGGCCGCGCAGCGGCTATGTTCCGAGAATTAATTAGAAATTTAGAAGTGTTAACCCCATTTATCATATATATTTAGAAAATAATTTAATGTAAATTATTTTTTGTTAAAGGTTATTCAGGTGTTATATGTATCACATTTAAATTGAAAAATATTAATGCAATATAATTATTGCATATTTAAAGGAAATATTAGAAATAAATTTTTAGAGAGAGAAAGTCTAGAGAGAAGGCAGACTGGTGTCTCTCCATTTATCACATATATTGGTGTATAAGAGTCCTATATATAGTAGAGACACTAAATGGCAATTTTGGTAATTTTGAGAGACACCAATCACTTTAATTTGAATTTGTACACGCGGCCCTCGTATATAATATT
ACCGAGGGCCGCGGGGTTTTGGAGTCTGGTCCCACATGTACTGCTGACCAATCAGCTTTCAGATTGAAAGCTATTTAAGTGCGTACCGCACTACAAAAGCAGTCATACTTACAGCTAATGGAAAACATGTGGGATCCATTGCTACATCCTTTTCCAGAGAGTTTGCACGGCTTTAGATGTATGCTTGCAATCAAGTATCTTCAAAGCTTACAGAGTAAGTATTCTCCTGATACTCTTGGGAGTGAATTCTTGAAGGATTTCATCTGCATCTTGCGGAGTAGAAATTATGCCGAAGCGTTCAATAGATACAGTGACGTCGTTGCCAATGTCTATAACACGCCGGAGGTTAAACTTCGGGAGTCAGTACAGTCTCCCTGCCTCTGCCCCCACTGCCCCAGGCATGTCGTACAAACGAAGAGCTTGGAAAAACCGTCCTATGTACACGAAGCCACGGTTTTATCGGTGGCGAAGGAGCAGTGATGTTCCACGGGGTTGTGAGGGTCCTTGTAAGGTTCAGTCCTTTGAGCAGAGACATGATATAACACACACCGGCAAGGTGTTGTGTGTGTCTGATGTTACTAGAGGCAATGGTATTACTCATAGAATAGGTAAAAGATTTTGCGTTAAGTCTGTTTATGTTATGGGCAAAATCTGGATGGATGAGAATATTAAATTGAAGAATCACACCAACACTGTTATGTTTTGGCTTGTTCGCGACAGAAGACCTGTTACTACCCCATATGGATTTGGAGAGTTATTCAACATGTATGACAACGAGCCCAGTACTGCAACAATAAAGAACGATCTTAGAGATCGTGTGCAAGTGCTTCATCGTTTCTCAGCATCATTAACTGGTGGTCAATATGCCAGCAAGGAACAAGCAGTTATTAAGAAGTTTTTTAGAGTTAATAATTATGTGGTGTACAATCACCAAGAAGCTGCTAAGTATGAAAATCATACTGAGAATGCTTTGCTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCAACACTTAAGATTAGAATTTATTTTTATGACAATGTAACTAATTAATAAATGTTGAATTTTATTATATGACATTGGTCTACATAACTTGTATTTTCCAATACATCCCACAATACATAATCAGCTGCGCGTATTACATTGTTAATTGAAACTATACCTAAGTTATTCAAATATTTCATACATTGATTTTTAAATACTCTTAAGAAATGCCAGGTCTGAGGTTGTAAAGGAGTCCATATTCTGAAGATCAGGAAACACTTGTGAATCCCCAACGCCTTCCTGAGGTTGTGGTTGAATTGGATCTGTATCTCCAAATAGTCGTTGTTGTCGTTGAATGGTTTGCTGTTGTGCTTCAGCACCTTGAAATACAGGGGATTTGGAACTTCCCATATATACACGCCATTCTGCGCTTGAGCTGCAGTAATGGTTTCCCCTGTGCGTAAATCCATATTTGTGACAATTAATGTTTACGTAATACGAACAGCCACAATCTAAGTCTACTCTGCGTCTTCTTGGTATTTTTTTCTTTGCAATTTTATGTTGTACTTTGACTGGTACAATTGTAGAGTGGCTGTTGGAGGGTGACGAATTCTGCATTTTTCAAAGCCCAATTTTTTAATGCCTCATTTTTTGGTTCGTCCAAAAACTCCTTAAAAGAGGAAGATGGACCAGGATTGCAGAGGAAGATAGTGGGAATTCCACCTTTAATTTGAATTGGTTTACCGTACTTTGTATTGCTTTGCCAGTCCCTCTGGGCCCCCATGAATTCTTTTAAGTGCTTTAGATAATGCGGATCTACGTCATCAATGACGTTATACCAAGCATCATTGCTGTACACTTTTGGGCTAAGGTCTAGATGTCCACACAAATAATTATGAGGGCCCAATGATCTGGCCCACATTGTTTTGCCGGTTCTAGATTCACCTTCAATCACCATTCCTATGGGTCTCCACGGCCGCGCAGCGGCATCACATACATTTTTCTCAGCCCAGGAGGCAAGTTCTTTTGGAACTTGATTGAAAGACGACAATTCGTAAGGATTAACAAATAATTCTTGGATTGGGGCAAATATCCGGTCCAAATTAGCATTTAGGTTGTGGTACTGCAGTACATAGTCCTTTGGAGCTAATTCCTTAAGGACTGCAAGAGCCTCCGACTTACTTCCGCAGTTAATTGCCTTTGCGTATGCGTCATTGGCGGATTGTTGTCCGCCTCTAGCAGATCTTCCATCAACCTGGAATTCTCCCCATTCAATTGTATCTCCGTCCTTCTCCAAATAGGACTTGACGTCGGAGCTTGATTTAGCTCCCTGAACATTTGGATGGAAATGTGCTGATCTGGTTGGGGAAACCAGGTCGAAGAATCTGTTATTTTTGCACTGGAATTTCCCTTCGAATTGAATGAGCACATGGAGATGAGGGCTCCCATCTTCGTGTAACTCCCTGCAGATTTTGATATATTTTTTTGAGGTTGGGGTTTGTAGTTCCTTCAATTGAGAGAGGGTTTCTTCCTTGCTCAGAGAGCACTGAGGATATGTGAGAAAATAGTTTTTGGCATTTATTCTGAATTTATTTAGAGAAGGCATGCTGACCTGTCTAATGGTGTCTCTCCATTTATCACATATATTGGTGTATAAGAGTCCTATATATAGTAGAGACACTAAATGGCAATTTTGGTAATTTTGAGAGACACCAATAACTTTATTTTGAATTTACAAAGCGGCCCTCGTATAATATT
Gene Information
|
NCBI Accession
|
NP_995300.1
|
|
Location
|
174-1007 |
|
Gene Name
|
BV1 |
|
Protein Name
|
BV1 protein |
|
Coding Region
|
ATGAGAGTTCCAATCCGGAGGAATTCAGGTTTTAATTCTGACCGTCGTCCTTCAAATGGTTCAATCCACCGGTGGAATTACCCATATTCCGGCTATTTTGGCAGGAGGATTGGCAACCGCGTATATGGCATGCCATTTGGAAGCCGTCAAGTTCAAAGACGTGAATTTCAGCAGACTCATCGTCCTATCAAGTTTTCTGACCATGTTTCTTCTCGGAGGAAGTTTATGAAGACTATAGAGGAAATTCACGATGGCACTGACTACTTGCTTTGCAATAACATGTCCAAGGTGTCATACATTAGTTACCCTCCTCTATCCGGTACTGAACATGGTAGTAGAGCTGAATCCTATCTCAAAGTCCTGGGTTTTAATGTATCTGGGTCTGTTGTGCTGAAGCAGCTGCACATGCGTGAAGCAGATATGTCTCAAGGAATTCATGGTATATTTACCACAGTAATTGTTCGTGATAAGAGACCATGTCAGTTCTCTGCTGTGGATCCTATCATCCCATTTGTTGAGTTATTTGGACCAGAAAAGAGAGCATGCTCCACATTACATGTTAGAGATTCTTATAAGAATCGATTTAGTGTTGTCTATCAAAAGAAACATGTTGTAAATAGTGCTCTGACAACACATGTATTTAGGTATAATTTTAATGTTAAGTTTTCTAGGTTTCCTTTCTGGGTGTCTTTCAAAGACACATCCAATGCAGAGCCTACTGGACTATATTCTAATGTTTCTAAGAACGCATTGGTGGTGTACTACGTGTGGCTGTGTGATTCAAATGTAACAGCCGAAGTGCACGTACAGTATGATTTGAACTATATTGGATAA |
|
Protein Sequence
|
MRVPIRRNSGFNSDRRPSNGSIHRWNYPYSGYFGRRIGNRVYGMPFGSRQVQRREFQQTHRPIKFSDHVSSRRKFMKTIEEIHDGTDYLLCNNMSKVSYISYPPLSGTEHGSRAESYLKVLGFNVSGSVVLKQLHMREADMSQGIHGIFTTVIVRDKRPCQFSAVDPIIPFVELFGPEKRACSTLHVRDSYKNRFSVVYQKKHVVNSALTTHVFRYNFNVKFSRFPFWVSFKDTSNAEPTGLYSNVSKNALVVYYVWLCDSNVTAEVHVQYDLNYIG |
|
NCBI Accession
|
NP_995301.1
|
|
Location
|
1014-1847 |
|
Gene Name
|
BC1 |
|
Protein Name
|
BC1 protein |
|
Coding Region
|
ATGGAGTCCAACAATAACAGTATTGCCTATACGACGTCGGATAGGACTGAATTTCAGCTGTCCAATGAAAAAACAGAAGTCACTCTGTTGTTTCCCTCAACCGTCGATCAAAAATTATCAATGCTCCTGGGAAAGTGTCTCAGGATTGACCATGTCATCCTCCAATACAGGAACCAAGTACCTGTCAATGCAACTGGGCATGTGGTCATAGAAATGCACGACACAAGGTTACATGAAGGAGACTCAAAGCAGGCTGAGTTCACAATACCCATAGGGTGTAACTGCAATATCCACTACTACTCATCCTCATACTTCTCCCCCAAAGATCCAAATCCATGGAGGGTGCTGTACAGGGTGGACGACACTAACGTGGTCAATGGTGTTCACTTTTGTAGGATGCAAGGGAAGTTAAAAATGTCCTCTGCAAAACAGTCATCTGAAATAACATTTAAGTCCCCAAAAATTGTAATACTGTCAAAGGCATATAACATGAACCACATAGATTTCTGGCATGTGCCTCAGTCCAAGGTATCAAGGAAACCAGTACAAGCCCTATCACAAATGAGGTCACAGTCTTCCAGATACACTACAAATGCCATTCCACAAGGGCATACCTGGGCTTCAGCCAGCGCAGTGGGGAACAACGAGATAGAGGAATACCCATACAGACATTTGCATCAGCTGCAAGATGCAACTCTAGATCCTGGCCCTTCGGCATCGGAAGTTGTTGCATGTAGCAACAAAGTGAATGATGATGTAATTAATATTATTAAAAAAACAGTTGAATTATGTATGGAAGGGAGTAATGTCTCCTCAAATGTAAAAAAAATATGA |
|
Protein Sequence
|
MESNNNSIAYTTSDRTEFQLSNEKTEVTLLFPSTVDQKLSMLLGKCLRIDHVILQYRNQVPVNATGHVVIEMHDTRLHEGDSKQAEFTIPIGCNCNIHYYSSSYFSPKDPNPWRVLYRVDDTNVVNGVHFCRMQGKLKMSSAKQSSEITFKSPKIVILSKAYNMNHIDFWHVPQSKVSRKPVQALSQMRSQSSRYTTNAIPQGHTWASASAVGNNEIEEYPYRHLHQLQDATLDPGPSASEVVACSNKVNDDVINIIKKTVELCMEGSNVSSNVKKI |
|
NCBI Accession
|
NP_995302.1
|
|
Location
|
118-480 |
|
Gene Name
|
AV2 |
|
Protein Name
|
pre-coat protein |
|
Coding Region
|
ATGGAAAACATGTGGGATCCATTGCTACATCCTTTTCCAGAGAGTTTGCACGGCTTTAGATGTATGCTTGCAATCAAGTATCTTCAAAGCTTACAGAGTAAGTATTCTCCTGATACTCTTGGGAGTGAATTCTTGAAGGATTTCATCTGCATCTTGCGGAGTAGAAATTATGCCGAAGCGTTCAATAGATACAGTGACGTCGTTGCCAATGTCTATAACACGCCGGAGGTTAAACTTCGGGAGTCAGTACAGTCTCCCTGCCTCTGCCCCCACTGCCCCAGGCATGTCGTACAAACGAAGAGCTTGGAAAAACCGTCCTATGTACACGAAGCCACGGTTTTATCGGTGGCGAAGGAGCAGTGA |
|
Protein Sequence
|
MENMWDPLLHPFPESLHGFRCMLAIKYLQSLQSKYSPDTLGSEFLKDFICILRSRNYAEAFNRYSDVVANVYNTPEVKLRESVQSPCLCPHCPRHVVQTKSLEKPSYVHEATVLSVAKEQ |
|
NCBI Accession
|
NP_995303.1
|
|
Location
|
287-1063 |
|
Gene Name
|
AV1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCGAAGCGTTCAATAGATACAGTGACGTCGTTGCCAATGTCTATAACACGCCGGAGGTTAAACTTCGGGAGTCAGTACAGTCTCCCTGCCTCTGCCCCCACTGCCCCAGGCATGTCGTACAAACGAAGAGCTTGGAAAAACCGTCCTATGTACACGAAGCCACGGTTTTATCGGTGGCGAAGGAGCAGTGATGTTCCACGGGGTTGTGAGGGTCCTTGTAAGGTTCAGTCCTTTGAGCAGAGACATGATATAACACACACCGGCAAGGTGTTGTGTGTGTCTGATGTTACTAGAGGCAATGGTATTACTCATAGAATAGGTAAAAGATTTTGCGTTAAGTCTGTTTATGTTATGGGCAAAATCTGGATGGATGAGAATATTAAATTGAAGAATCACACCAACACTGTTATGTTTTGGCTTGTTCGCGACAGAAGACCTGTTACTACCCCATATGGATTTGGAGAGTTATTCAACATGTATGACAACGAGCCCAGTACTGCAACAATAAAGAACGATCTTAGAGATCGTGTGCAAGTGCTTCATCGTTTCTCAGCATCATTAACTGGTGGTCAATATGCCAGCAAGGAACAAGCAGTTATTAAGAAGTTTTTTAGAGTTAATAATTATGTGGTGTACAATCACCAAGAAGCTGCTAAGTATGAAAATCATACTGAGAATGCTTTGCTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCAACACTTAAGATTAGAATTTATTTTTATGACAATGTAACTAATTAA |
|
Protein Sequence
|
MPKRSIDTVTSLPMSITRRRLNFGSQYSLPASAPTAPGMSYKRRAWKNRPMYTKPRFYRWRRSSDVPRGCEGPCKVQSFEQRHDITHTGKVLCVSDVTRGNGITHRIGKRFCVKSVYVMGKIWMDENIKLKNHTNTVMFWLVRDRRPVTTPYGFGELFNMYDNEPSTATIKNDLRDRVQVLHRFSASLTGGQYASKEQAVIKKFFRVNNYVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDNVTN |
|
NCBI Accession
|
NP_995304.1
|
|
Location
|
1060-1464 |
|
Gene Name
|
AC3 |
|
Protein Name
|
AC3 |
|
Coding Region
|
ATGGATTTACGCACAGGGGAAACCATTACTGCAGCTCAAGCGCAGAATGGCGTGTATATATGGGAAGTTCCAAATCCCCTGTATTTCAAGGTGCTGAAGCACAACAGCAAACCATTCAACGACAACAACGACTATTTGGAGATACAGATCCAATTCAACCACAACCTCAGGAAGGCGTTGGGGATTCACAAGTGTTTCCTGATCTTCAGAATATGGACTCCTTTACAACCTCAGACCTGGCATTTCTTAAGAGTATTTAAAAATCAATGTATGAAATATTTGAATAACTTAGGTATAGTTTCAATTAACAATGTAATACGCGCAGCTGATTATGTATTGTGGGATGTATTGGAAAATACAAGTTATGTAGACCAATGTCATATAATAAAATTCAACATTTATTAA |
|
Protein Sequence
|
MDLRTGETITAAQAQNGVYIWEVPNPLYFKVLKHNSKPFNDNNDYLEIQIQFNHNLRKALGIHKCFLIFRIWTPLQPQTWHFLRVFKNQCMKYLNNLGIVSINNVIRAADYVLWDVLENTSYVDQCHIIKFNIY |
|
NCBI Accession
|
NP_995305.1
|
|
Location
|
1205-1612 |
|
Gene Name
|
AC2 |
|
Protein Name
|
AC2 |
|
Coding Region
|
ATGCAGAATTCGTCACCCTCCAACAGCCACTCTACAATTGTACCAGTCAAAGTACAACATAAAATTGCAAAGAAAAAAATACCAAGAAGACGCAGAGTAGACTTAGATTGTGGCTGTTCGTATTACGTAAACATTAATTGTCACAAATATGGATTTACGCACAGGGGAAACCATTACTGCAGCTCAAGCGCAGAATGGCGTGTATATATGGGAAGTTCCAAATCCCCTGTATTTCAAGGTGCTGAAGCACAACAGCAAACCATTCAACGACAACAACGACTATTTGGAGATACAGATCCAATTCAACCACAACCTCAGGAAGGCGTTGGGGATTCACAAGTGTTTCCTGATCTTCAGAATATGGACTCCTTTACAACCTCAGACCTGGCATTTCTTAAGAGTATTTAA |
|
Protein Sequence
|
MQNSSPSNSHSTIVPVKVQHKIAKKKIPRRRRVDLDCGCSYYVNINCHKYGFTHRGNHYCSSSAEWRVYMGSSKSPVFQGAEAQQQTIQRQQRLFGDTDPIQPQPQEGVGDSQVFPDLQNMDSFTTSDLAFLKSI |
|
NCBI Accession
|
NP_995306.1
|
|
Location
|
1551-2600 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCTTCTCTAAATAAATTCAGAATAAATGCCAAAAACTATTTTCTCACATATCCTCAGTGCTCTCTGAGCAAGGAAGAAACCCTCTCTCAATTGAAGGAACTACAAACCCCAACCTCAAAAAAATATATCAAAATCTGCAGGGAGTTACACGAAGATGGGAGCCCTCATCTCCATGTGCTCATTCAATTCGAAGGGAAATTCCAGTGCAAAAATAACAGATTCTTCGACCTGGTTTCCCCAACCAGATCAGCACATTTCCATCCAAATGTTCAGGGAGCTAAATCAAGCTCCGACGTCAAGTCCTATTTGGAGAAGGACGGAGATACAATTGAATGGGGAGAATTCCAGGTTGATGGAAGATCTGCTAGAGGCGGACAACAATCCGCCAATGACGCATACGCAAAGGCAATTAACTGCGGAAGTAAGTCGGAGGCTCTTGCAGTCCTTAAGGAATTAGCTCCAAAGGACTATGTACTGCAGTACCACAACCTAAATGCTAATTTGGACCGGATATTTGCCCCAATCCAAGAATTATTTGTTAATCCTTACGAATTGTCGTCTTTCAATCAAGTTCCAAAAGAACTTGCCTCCTGGGCTGAGAAAAATGTATGTGATGCCGCTGCGCGGCCGTGGAGACCCATAGGAATGGTGATTGAAGGTGAATCTAGAACCGGCAAAACAATGTGGGCCAGATCATTGGGCCCTCATAATTATTTGTGTGGACATCTAGACCTTAGCCCAAAAGTGTACAGCAATGATGCTTGGTATAACGTCATTGATGACGTAGATCCGCATTATCTAAAGCACTTAAAAGAATTCATGGGGGCCCAGAGGGACTGGCAAAGCAATACAAAGTACGGTAAACCAATTCAAATTAAAGGTGGAATTCCCACTATCTTCCTCTGCAATCCTGGTCCATCTTCCTCTTTTAAGGAGTTTTTGGACGAACCAAAAAATGAGGCATTAAAAAATTGGGCTTTGAAAAATGCAGAATTCGTCACCCTCCAACAGCCACTCTACAATTGTACCAGTCAAAGTACAACATAA |
|
Protein Sequence
|
MPSLNKFRINAKNYFLTYPQCSLSKEETLSQLKELQTPTSKKYIKICRELHEDGSPHLHVLIQFEGKFQCKNNRFFDLVSPTRSAHFHPNVQGAKSSSDVKSYLEKDGDTIEWGEFQVDGRSARGGQQSANDAYAKAINCGSKSEALAVLKELAPKDYVLQYHNLNANLDRIFAPIQELFVNPYELSSFNQVPKELASWAEKNVCDAAARPWRPIGMVIEGESRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHLKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPSSSFKEFLDEPKNEALKNWALKNAEFVTLQQPLYNCTSQSTT |
|
NCBI Accession
|
NP_995307.1
|
|
Location
|
2141-2443 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGAGCCCTCATCTCCATGTGCTCATTCAATTCGAAGGGAAATTCCAGTGCAAAAATAACAGATTCTTCGACCTGGTTTCCCCAACCAGATCAGCACATTTCCATCCAAATGTTCAGGGAGCTAAATCAAGCTCCGACGTCAAGTCCTATTTGGAGAAGGACGGAGATACAATTGAATGGGGAGAATTCCAGGTTGATGGAAGATCTGCTAGAGGCGGACAACAATCCGCCAATGACGCATACGCAAAGGCAATTAACTGCGGAAGTAAGTCGGAGGCTCTTGCAGTCCTTAAGGAATTAG |
|
Protein Sequence
|
MGALISMCSFNSKGNSSAKITDSSTWFPQPDQHISIQMFRELNQAPTSSPIWRRTEIQLNGENSRLMEDLLEADNNPPMTHTQRQLTAEVSRRLLQSLRN |