Tomato yellow leaf curl Indonesia virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000869285.1 |
| Isolate |
Indonesia:Lembang |
| Release date |
2015/2/13 |
| Submitter |
Tsai,W.S., Shih,S.L., Green,S.K., Akkermans,D., Jan,F.-J. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
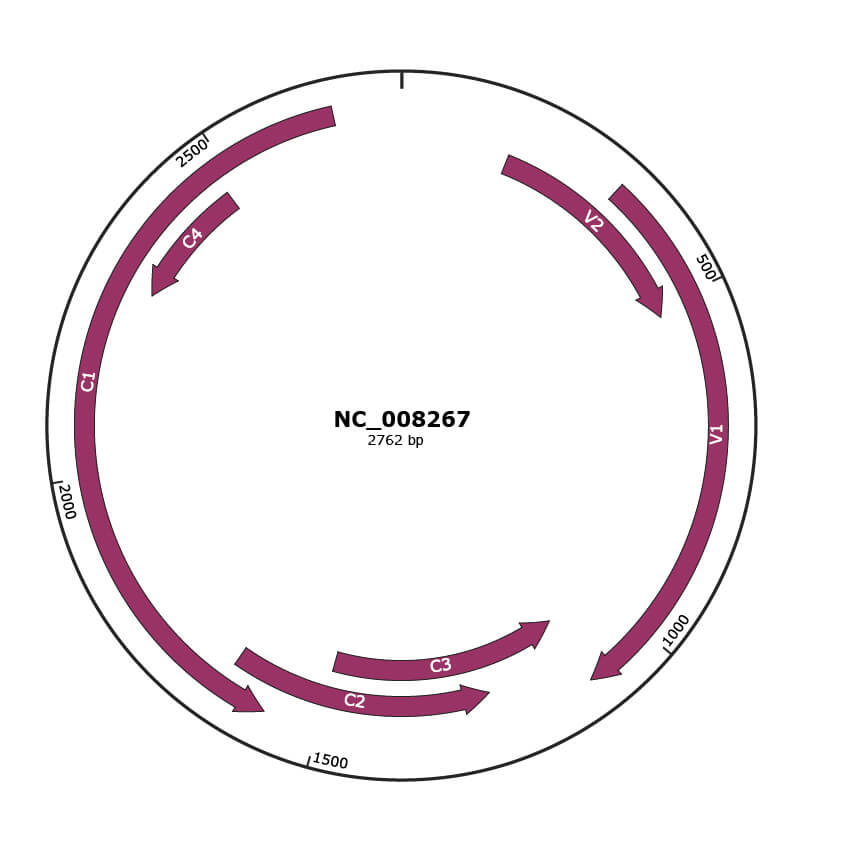
JBrowse
Genome
ACCTACAGGCCGCCGGGGCCCGGGGTCACTATGGTCCCCCCCCACTTTAGCTGCTTTTGCTTTTGCTTTAATGTGGTCCCGTAATAAATGAGAGAGCGCGATGAGCGCTTAGTTGATTTGTGGTCCTTCTATAAAACGTGCTGGGCACGGAGAAAGCTGAATAGCCATGTGGGATCCTCTTTTAAACGAATTTCCGGATTCTGTTCACGGTTTTCGGTGTATGCTCGCAATAAAGTATTTGCAAGGCGTTGAAGCAACCTACGCCCCTGATACTGTCGGTTACGACCTAGTTCGAGATCTGATCTCAGTTGTTCGTGCGAGCAATTATGCTGAAGCGTGCCGGAGATATAGCCTTTTCCGGTCCCGTATCGAAAGTACGCCGTCGTCTCAATTACGACAGCCCAGGTACCAGCCGTGCTGCTGTACTCACTGCCCTCGGCATAAATCGAAAGAAGTCTTGGACTTCTCGGCCTATGTACCGGAAGCCCAGGATTTACCGGATGTACCGAACAGCTGATGTCCCTAGGGGATGTGAAGGTCCTTGCAAGATTCAATCCTTTGAATCTCGACATGATATTGCTCACACCGGTAAGGTTATGTGTGTGACGGATGTTACTCGTGGCGGTGGTTTAACCCACCGTACTGGGAAGAGATTTTGCGTTAAGTCCCTCTATATCCTTGGCAAAATCTGGATGGATGAAAATATCAAGACTAAGAATCACACTAACACGGTCATGTTCTATGTTGTTCGGGATCGTAGACCCTATGGTACTCCTCAAGATTTTGGACAAGTGTTTAACATGTTCGATAACGAACCTAGCACTGCAACTGTCAAGAATGATCTTCGAGATCGGTTTCAAGTTTTGCGGAAGTTCACGGCAACTGTTGTTGGTGGTCAGTATGCTTGTAAGGAACAAACGTTAGTTAGGAAGTTCATGAGATTGAACAATTATGTTGTTTACAACCATCAGGAAACCGCAAAATATGAGAATCATACAGAGAATGCTCTGTTATTGTACATGGCATCTACGCATGCCTCTAACCCTGTGTATGCAACTTTGAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAATAAATGTTGAATTTTATTTCATAATCTGGTTGTACATCAATAGTGCGTTCTAGCACTTTAAACAAGACATGGTCTACAGCTCTAATTACATTATTAATTGAAATTACACCTAAATTATTCAAGTATTTAATACATTGAGTCTTAAAGACTTTTAAGAAAAGCCCAGTCGGAGGGTGTAAGTAAGTCCAAACTTGGAACGTCAGAAAACACCGGTGTATTCCCAACGCTTTCCTCAGGTTGTGGTTGAACTGCAGCCGTATTGTTATCACGTCGTGGTTCGTGTTGAACGGCCGGCTGTGATGGCTGAGTATCTTGAAATAGAGGGGATTTTGAATCTCCCAAATATAGACGCCATTCCTGGCTTGAGCTGCAGTGATGTACTCCCCTGTGCGTAAATCCATGATTAGCACAGTTTATTGACACGTAGTATGAGCAACCGCAATTAAGGTCTACCCGCCGTCGTCTTATTATCTTCTTTTTAGCAATCCGGTGCTGGACTTTGATGGGAACCTGAGTACAGTGGTCTCTCGAGGGTGATGAATTCTGCATTATGAAGAGACCAATTTTTAAGTGCGATGTTTTTAGGTTCGTCTAAAAACTCTTTATATGAAGATGTGGGTCCAGCATTACATAAAAAGATGGTCGGTATCCCGCCTTTAATTTGAATGGGTCTACCATACTTTGTATTGCTTTGCCAGTCCATCTGGGCCCCCATAAACTCTTTAAAGTGCTTTAGGTAATGCGGATCGACGTCATCAATGACGTTATACCATGCGTCATTTGAGTAAACCCTAGGATTGAGATCTAGATGGCCGCACAAGTAATTGTGCCTACCAAGCGATCTAGCCCACATGGTTTTACCTGTACGACTATCACCTTGTAACACCAGACTCTTTGGTCTTAATGGCCGCGCAGCGGGGTCGACTATGTTCTCGGCGACCCATTCTTCAAGTTCTTCAGGAACCTGGTCAAAGGATGAAGATAAGAATGGAGAGGTAAAGACTGGTTGCGGAGTCATGAAGATCTTGTCAAGATTTGTGTTCAAGTTATGAAACTGCAAGATGTAATCTTTAGGCGCAAGTTCTTTAAGAATATTCAGAGCCTCCGCTTTGTTTCCTGCATTCATAGCTTTTGCATAAGCGTCGTTAGCGGATTGCTTTCCGCCTCTTGAAGATCTTCCATCTATTTGGAAGGTACCCCATTCAAGGGTATCACCATCCTTTTCGATATATGCTTTGACATCGGAGCTTGATTTAGCTCCCTGAATGTTCGGATGGAAATGTGTTGATCTGGTTGGGGATACCAGATCGAAGAACCTCTTGTTCTTTGTCTTGAACTTACCCTCAAATTGGATAAGCACATGGAGATGTGGTTCCCCATCCTCGTGAAGCTCTGAGCAGATTTTGATATATTTTTTATTTGTTGGGGTATTCAAATTTCTAATTTGAGAGAGAGCTTCGCTTTTAGAGAGAGAGCAGTGAGGATAGGTGAGGAAATAGTTTTTAGCGTTTATTTGAAAACGCTTTGTGAGAGAGTTATTAGAGGGGGTTCCCCGATTGCTCTCCATTCCATCTATCGTATGTATATTGGGGAACGGGGACCTATAAATACTTCTGTCCCCAATAGGTTTTGTGCTTACGTGGCGGCCTGTAGTATAATATT
Gene Information
|
NCBI Accession
|
YP_699989.1
|
|
Location
|
167-517 |
|
Gene Name
|
V2 |
|
Protein Name
|
precoat protein |
|
Coding Region
|
ATGTGGGATCCTCTTTTAAACGAATTTCCGGATTCTGTTCACGGTTTTCGGTGTATGCTCGCAATAAAGTATTTGCAAGGCGTTGAAGCAACCTACGCCCCTGATACTGTCGGTTACGACCTAGTTCGAGATCTGATCTCAGTTGTTCGTGCGAGCAATTATGCTGAAGCGTGCCGGAGATATAGCCTTTTCCGGTCCCGTATCGAAAGTACGCCGTCGTCTCAATTACGACAGCCCAGGTACCAGCCGTGCTGCTGTACTCACTGCCCTCGGCATAAATCGAAAGAAGTCTTGGACTTCTCGGCCTATGTACCGGAAGCCCAGGATTTACCGGATGTACCGAACAGCTGA |
|
Protein Sequence
|
MWDPLLNEFPDSVHGFRCMLAIKYLQGVEATYAPDTVGYDLVRDLISVVRASNYAEACRRYSLFRSRIESTPSSQLRQPRYQPCCCTHCPRHKSKEVLDFSAYVPEAQDLPDVPNS |
|
NCBI Accession
|
YP_699990.1
|
|
Location
|
327-1100 |
|
Gene Name
|
V1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCTGAAGCGTGCCGGAGATATAGCCTTTTCCGGTCCCGTATCGAAAGTACGCCGTCGTCTCAATTACGACAGCCCAGGTACCAGCCGTGCTGCTGTACTCACTGCCCTCGGCATAAATCGAAAGAAGTCTTGGACTTCTCGGCCTATGTACCGGAAGCCCAGGATTTACCGGATGTACCGAACAGCTGATGTCCCTAGGGGATGTGAAGGTCCTTGCAAGATTCAATCCTTTGAATCTCGACATGATATTGCTCACACCGGTAAGGTTATGTGTGTGACGGATGTTACTCGTGGCGGTGGTTTAACCCACCGTACTGGGAAGAGATTTTGCGTTAAGTCCCTCTATATCCTTGGCAAAATCTGGATGGATGAAAATATCAAGACTAAGAATCACACTAACACGGTCATGTTCTATGTTGTTCGGGATCGTAGACCCTATGGTACTCCTCAAGATTTTGGACAAGTGTTTAACATGTTCGATAACGAACCTAGCACTGCAACTGTCAAGAATGATCTTCGAGATCGGTTTCAAGTTTTGCGGAAGTTCACGGCAACTGTTGTTGGTGGTCAGTATGCTTGTAAGGAACAAACGTTAGTTAGGAAGTTCATGAGATTGAACAATTATGTTGTTTACAACCATCAGGAAACCGCAAAATATGAGAATCATACAGAGAATGCTCTGTTATTGTACATGGCATCTACGCATGCCTCTAACCCTGTGTATGCAACTTTGAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAA |
|
Protein Sequence
|
MLKRAGDIAFSGPVSKVRRRLNYDSPGTSRAAVLTALGINRKKSWTSRPMYRKPRIYRMYRTADVPRGCEGPCKIQSFESRHDIAHTGKVMCVTDVTRGGGLTHRTGKRFCVKSLYILGKIWMDENIKTKNHTNTVMFYVVRDRRPYGTPQDFGQVFNMFDNEPSTATVKNDLRDRFQVLRKFTATVVGGQYACKEQTLVRKFMRLNNYVVYNHQETAKYENHTENALLLYMASTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_699991.1
|
|
Location
|
1097-1501 |
|
Gene Name
|
C3 |
|
Protein Name
|
C3 protein |
|
Coding Region
|
ATGGATTTACGCACAGGGGAGTACATCACTGCAGCTCAAGCCAGGAATGGCGTCTATATTTGGGAGATTCAAAATCCCCTCTATTTCAAGATACTCAGCCATCACAGCCGGCCGTTCAACACGAACCACGACGTGATAACAATACGGCTGCAGTTCAACCACAACCTGAGGAAAGCGTTGGGAATACACCGGTGTTTTCTGACGTTCCAAGTTTGGACTTACTTACACCCTCCGACTGGGCTTTTCTTAAAAGTCTTTAAGACTCAATGTATTAAATACTTGAATAATTTAGGTGTAATTTCAATTAATAATGTAATTAGAGCTGTAGACCATGTCTTGTTTAAAGTGCTAGAACGCACTATTGATGTACAACCAGATTATGAAATAAAATTCAACATTTATTAA |
|
Protein Sequence
|
MDLRTGEYITAAQARNGVYIWEIQNPLYFKILSHHSRPFNTNHDVITIRLQFNHNLRKALGIHRCFLTFQVWTYLHPPTGLFLKVFKTQCIKYLNNLGVISINNVIRAVDHVLFKVLERTIDVQPDYEIKFNIY |
|
NCBI Accession
|
YP_699992.1
|
|
Location
|
1242-1649 |
|
Gene Name
|
C2 |
|
Protein Name
|
C2 protein |
|
Coding Region
|
ATGCAGAATTCATCACCCTCGAGAGACCACTGTACTCAGGTTCCCATCAAAGTCCAGCACCGGATTGCTAAAAAGAAGATAATAAGACGACGGCGGGTAGACCTTAATTGCGGTTGCTCATACTACGTGTCAATAAACTGTGCTAATCATGGATTTACGCACAGGGGAGTACATCACTGCAGCTCAAGCCAGGAATGGCGTCTATATTTGGGAGATTCAAAATCCCCTCTATTTCAAGATACTCAGCCATCACAGCCGGCCGTTCAACACGAACCACGACGTGATAACAATACGGCTGCAGTTCAACCACAACCTGAGGAAAGCGTTGGGAATACACCGGTGTTTTCTGACGTTCCAAGTTTGGACTTACTTACACCCTCCGACTGGGCTTTTCTTAAAAGTCTTTAA |
|
Protein Sequence
|
MQNSSPSRDHCTQVPIKVQHRIAKKKIIRRRRVDLNCGCSYYVSINCANHGFTHRGVHHCSSSQEWRLYLGDSKSPLFQDTQPSQPAVQHEPRRDNNTAAVQPQPEESVGNTPVFSDVPSLDLLTPSDWAFLKSL |
|
NCBI Accession
|
YP_699993.1
|
|
Location
|
1579-2667 |
|
Gene Name
|
C1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGGAGAGCAATCGGGGAACCCCCTCTAATAACTCTCTCACAAAGCGTTTTCAAATAAACGCTAAAAACTATTTCCTCACCTATCCTCACTGCTCTCTCTCTAAAAGCGAAGCTCTCTCTCAAATTAGAAATTTGAATACCCCAACAAATAAAAAATATATCAAAATCTGCTCAGAGCTTCACGAGGATGGGGAACCACATCTCCATGTGCTTATCCAATTTGAGGGTAAGTTCAAGACAAAGAACAAGAGGTTCTTCGATCTGGTATCCCCAACCAGATCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCCGATGTCAAAGCATATATCGAAAAGGATGGTGATACCCTTGAATGGGGTACCTTCCAAATAGATGGAAGATCTTCAAGAGGCGGAAAGCAATCCGCTAACGACGCTTATGCAAAAGCTATGAATGCAGGAAACAAAGCGGAGGCTCTGAATATTCTTAAAGAACTTGCGCCTAAAGATTACATCTTGCAGTTTCATAACTTGAACACAAATCTTGACAAGATCTTCATGACTCCGCAACCAGTCTTTACCTCTCCATTCTTATCTTCATCCTTTGACCAGGTTCCTGAAGAACTTGAAGAATGGGTCGCCGAGAACATAGTCGACCCCGCTGCGCGGCCATTAAGACCAAAGAGTCTGGTGTTACAAGGTGATAGTCGTACAGGTAAAACCATGTGGGCTAGATCGCTTGGTAGGCACAATTACTTGTGCGGCCATCTAGATCTCAATCCTAGGGTTTACTCAAATGACGCATGGTATAACGTCATTGATGACGTCGATCCGCATTACCTAAAGCACTTTAAAGAGTTTATGGGGGCCCAGATGGACTGGCAAAGCAATACAAAGTATGGTAGACCCATTCAAATTAAAGGCGGGATACCGACCATCTTTTTATGTAATGCTGGACCCACATCTTCATATAAAGAGTTTTTAGACGAACCTAAAAACATCGCACTTAAAAATTGGTCTCTTCATAATGCAGAATTCATCACCCTCGAGAGACCACTGTACTCAGGTTCCCATCAAAGTCCAGCACCGGATTGCTAA |
|
Protein Sequence
|
MESNRGTPSNNSLTKRFQINAKNYFLTYPHCSLSKSEALSQIRNLNTPTNKKYIKICSELHEDGEPHLHVLIQFEGKFKTKNKRFFDLVSPTRSTHFHPNIQGAKSSSDVKAYIEKDGDTLEWGTFQIDGRSSRGGKQSANDAYAKAMNAGNKAEALNILKELAPKDYILQFHNLNTNLDKIFMTPQPVFTSPFLSSSFDQVPEELEEWVAENIVDPAARPLRPKSLVLQGDSRTGKTMWARSLGRHNYLCGHLDLNPRVYSNDAWYNVIDDVDPHYLKHFKEFMGAQMDWQSNTKYGRPIQIKGGIPTIFLCNAGPTSSYKEFLDEPKNIALKNWSLHNAEFITLERPLYSGSHQSPAPDC |
|
NCBI Accession
|
YP_699994.1
|
|
Location
|
2283-2480 |
|
Gene Name
|
C4 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGGGAACCACATCTCCATGTGCTTATCCAATTTGAGGGTAAGTTCAAGACAAAGAACAAGAGGTTCTTCGATCTGGTATCCCCAACCAGATCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCAAGCTCCGATGTCAAAGCATATATCGAAAAGGATGGTGATACCCTTGAATGGGGTACCTTCCAAATAG |
|
Protein Sequence
|
MGNHISMCLSNLRVSSRQRTRGSSIWYPQPDQHISIRTFRELNQAPMSKHISKRMVIPLNGVPSK |