Tomato yellow leaf curl Axarquia virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000880235.1 |
| Isolate |
Italy: Sicily, Ragusa |
| Release date |
2015/2/22 |
| Submitter |
Davino,S., Napoli,C., Dellacroce,C., Miozzi,L., Noris,E., Davino,M., Accotto,G.P. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
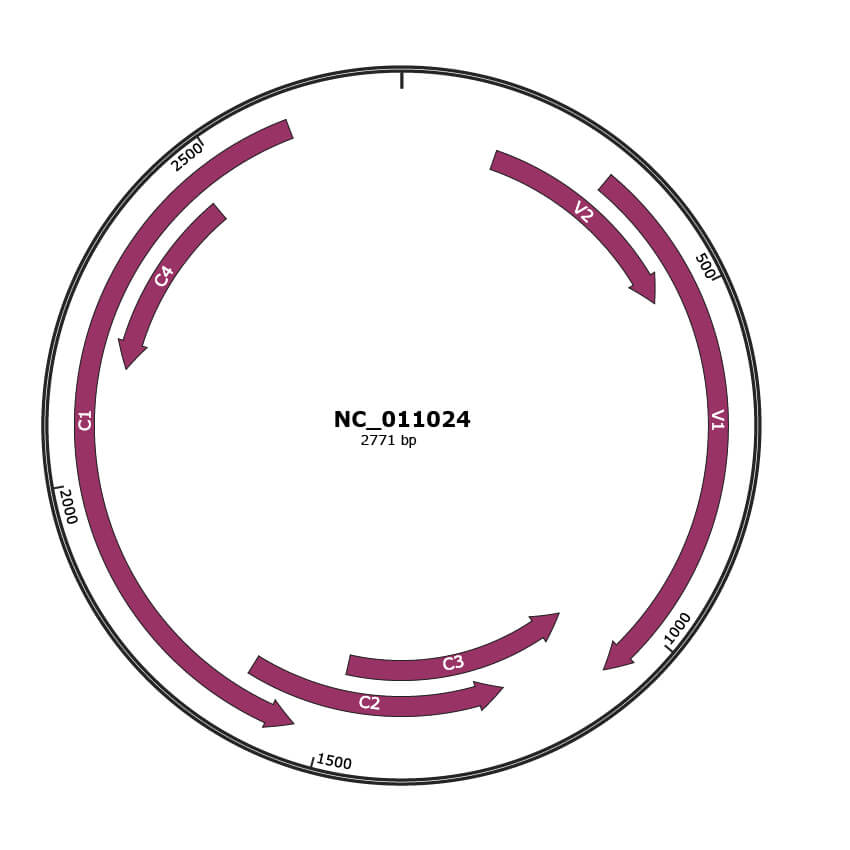
JBrowse
Genome
TAATATTACCGGATGGCCGCGCTCCCCGATAAAGAAGTGGGTCCTACGCAGTAATTTCTGTCGACCAATGAAATTCCAGCCTCAAAGCTTAAATAATTGTTTAGCTTTCTTATAAACTTGCTCACTAAGTTTTAAAAATACCACAAAATGTGGGATCCATTATTAAATGAATTTCCTGATTCTGTCCATGGTCTCCGATGCATGCTCGCAATTAAATATTTGCAGCTAGTTGAAGAAACCTACGAACCTAATACCCTTGGTCACGACCTAATTAGGGATCTCATCTCCGTCATTCGTGCTCGTGACTATGCCGAAGCGAACCGGCGATATACTAATTTCAACGCCCGTCTCGAAGGTTCGTCGAAGACTGAACTTCGACAGCCCGTATACCAGCCGTGCTGCTGCCCCCACTGTCCAAGGCATCAAGCGTCGATCATGGACTTACAGGCCCATGTATCGAAAGCCGCGGATGTACAGAATGTACAGAAGCCCTGATGTACCTCCGGGTTGTGAAGGTCCCTGTAAAGTTCAGTCCTATGAGCAGCGTGATGACGTCAAGCATACCGGTGTTGTGCGTTGTGTTAGTGATGTTACTAGGGGTTCTGGTATTACTCATAGAGTTGGTAAACGTTTTTGTATTAAGTCAATTTATATTTTAGGGAAGATTTGGATGGATGAAAATATAAAAAAACAAAATCATACTAACCAGGTTATGTTTTTCCTTGTTCGAGACCGAAGGCCTTATGGAACTAGTCCTATGGATTTTGGTCAAGTTTTTAACATGTTTGATAATGAACCCAGTACTGCTACGGTGAAGAACGACTTAAGGGATAGGTATCAAGTAATGAGGAAGTTTCATGCTACGGTTGTTGGAGGTCCGTCAGGGATGAAGGAGCAGTGTTTGCTGAAGAGATTTTTTAAAATTAATACCCATGTAGTTTATAATCATCAAGAGCAGGCGAAGTATGAGAATCATACTGAGAATGCCTTGTTATTGTATATGGCTTGTACTCATGCTTCTAACCCAGTGTACGCTACATTGAAAATACGTATTTATTTTTATGATGCTGTAACAAATTAATAAAGATTAAATTTTATTTCATGATTTTCAGCTACATCAATTGTTCCTTCAAATACATCATACAATACATAATCAACTGCTCTAATAACATTATTTAAAGAAATTACACCCAAATTATTCAAATATTTACAAACTTGATATTTAAATACTCTTAAAAAATGACCAGTCGGAGACTGTAAAGTCGTCCAAATGCGGAAGTTGAGAAAACATTTGTGAATCCCCAGTTCCTTCCTCAAATTGTGGTTGAATCTGATTTGGAATATTAGTGTGTTGTACTTGTTGTTGAATGGGTTCTGATTGTGTTTGGTTATCTTGAAATATAGGGGATTTGTTATCCCGAAGGTATAAACGCCACTCGTTGCTTGAAGCGCAGTGATGTACTCCCCTGTGCGTAAATCCATGATTTATGCAGTCTAAGTGTATGTAATATGAGCATCCACAGTCCAGATCGACCCTTCTACGCCTCACCTGCCTCTTCTTGGCGATGTGGTGTTGTATTTTGATGGGTATCTGTGAACAATGGCTGGTGGATGGTGACGAAGATCGCATTCTTAATAGCCCAATTTTTTAATGGTTGGTTTTTTTCTTCGTCGAGATATTCTTTAAATGATGATTGTGGGCCTGGATTGCAGAGGAAGATAGTGGGAATGCCTCCTTTAATTTGAATGGGCTTCCCATACTTGGTGTTGCTCTGCCAGTCTCTTTGGGCCCCCATAAACTCTTTAAAGTGCTTTAAATAATGCGGGTCGACGTCATCAATGACGTTATACCAAGCATTATTGCTGTATACTTTTTGACTGAGGTCAAGATGGCCGCACAAATAATTATGTGGGCCTAAGGAACGGGCCCACATGGTCTTTCCTGTCCGGCTGTCACCCTCAATCACTATACTTACCGGTCTCCAAGGCCGCGCAGCGGCATCCATGACGTTCTCGGCGACCCACTCTTCAAGTTCATCTGGAACTTGATTAAAAGAAGAAGAAAGAAATGGAGAAACATAAACTTCTAAAGGAGGACTAAAAATCCTATCTAAATTTGAACTTAAATTATGAAATTGTAAAATATAGTCCTTTGGGGCCTTCTCTTTTAATATATTGAGGGCCTCGGATTTACTGCCTGAATTGAGTGCTTCGGCATATGCGTCGTTGGCAGATTGCTGACCTCCTCTAGCTGATCTGCCATCGATTTGGAAAACTCCAAAATCAATGAATTCTCCGTCTTTCTCCACGTAGGTCTTGACATCTGTTGAGCTCTTAGCTGCCTGAATGTTCGGATGGAAATGTGCTGACCTGTTTGGGGATACCAGGTCGAAGAACCGTTGGTTTTTACATTGGTATTTGCCTTCGAATTGGATAAGCACATGGAGATGTGGTTCCCCATTCTCGTGGAATTCTCTGCAAACTTTGATGTATTTTTTATTTGTTGGGGTTTCTAGGTTTTTTAATTGGGAAAGTGCTTCCTCTTTAGAGAGATAACAATTGGGATATGTCAGGAAATAATTTTTGGCATATATTTTAAATAAACGAGGCATGTTGAAATGAATCGGTGTCCCTCACAGCTCTATGGCAATCGGTGTATTGGTGTCTTACTTATACCTGGACACCTAATGGCTATATGGTAATTTAATAAATGTTTATTGCAATTCAAAATTCAAACTTCAAAAATCAAATCATTAAAGCGGCCATCCGTA
Gene Information
|
NCBI Accession
|
YP_001994907.1
|
|
Location
|
148-495 |
|
Gene Name
|
V2 |
|
Protein Name
|
precoat protein |
|
Coding Region
|
ATGTGGGATCCATTATTAAATGAATTTCCTGATTCTGTCCATGGTCTCCGATGCATGCTCGCAATTAAATATTTGCAGCTAGTTGAAGAAACCTACGAACCTAATACCCTTGGTCACGACCTAATTAGGGATCTCATCTCCGTCATTCGTGCTCGTGACTATGCCGAAGCGAACCGGCGATATACTAATTTCAACGCCCGTCTCGAAGGTTCGTCGAAGACTGAACTTCGACAGCCCGTATACCAGCCGTGCTGCTGCCCCCACTGTCCAAGGCATCAAGCGTCGATCATGGACTTACAGGCCCATGTATCGAAAGCCGCGGATGTACAGAATGTACAGAAGCCCTGA |
|
Protein Sequence
|
MWDPLLNEFPDSVHGLRCMLAIKYLQLVEETYEPNTLGHDLIRDLISVIRARDYAEANRRYTNFNARLEGSSKTELRQPVYQPCCCPHCPRHQASIMDLQAHVSKAADVQNVQKP |
|
NCBI Accession
|
YP_001994908.1
|
|
Location
|
308-1081 |
|
Gene Name
|
V1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCGAAGCGAACCGGCGATATACTAATTTCAACGCCCGTCTCGAAGGTTCGTCGAAGACTGAACTTCGACAGCCCGTATACCAGCCGTGCTGCTGCCCCCACTGTCCAAGGCATCAAGCGTCGATCATGGACTTACAGGCCCATGTATCGAAAGCCGCGGATGTACAGAATGTACAGAAGCCCTGATGTACCTCCGGGTTGTGAAGGTCCCTGTAAAGTTCAGTCCTATGAGCAGCGTGATGACGTCAAGCATACCGGTGTTGTGCGTTGTGTTAGTGATGTTACTAGGGGTTCTGGTATTACTCATAGAGTTGGTAAACGTTTTTGTATTAAGTCAATTTATATTTTAGGGAAGATTTGGATGGATGAAAATATAAAAAAACAAAATCATACTAACCAGGTTATGTTTTTCCTTGTTCGAGACCGAAGGCCTTATGGAACTAGTCCTATGGATTTTGGTCAAGTTTTTAACATGTTTGATAATGAACCCAGTACTGCTACGGTGAAGAACGACTTAAGGGATAGGTATCAAGTAATGAGGAAGTTTCATGCTACGGTTGTTGGAGGTCCGTCAGGGATGAAGGAGCAGTGTTTGCTGAAGAGATTTTTTAAAATTAATACCCATGTAGTTTATAATCATCAAGAGCAGGCGAAGTATGAGAATCATACTGAGAATGCCTTGTTATTGTATATGGCTTGTACTCATGCTTCTAACCCAGTGTACGCTACATTGAAAATACGTATTTATTTTTATGATGCTGTAACAAATTAA |
|
Protein Sequence
|
MPKRTGDILISTPVSKVRRRLNFDSPYTSRAAAPTVQGIKRRSWTYRPMYRKPRMYRMYRSPDVPPGCEGPCKVQSYEQRDDVKHTGVVRCVSDVTRGSGITHRVGKRFCIKSIYILGKIWMDENIKKQNHTNQVMFFLVRDRRPYGTSPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMRKFHATVVGGPSGMKEQCLLKRFFKINTHVVYNHQEQAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDAVTN |
|
NCBI Accession
|
YP_001994909.1
|
|
Location
|
1078-1482 |
|
Gene Name
|
C3 |
|
Protein Name
|
REn protein |
|
Coding Region
|
ATGGATTTACGCACAGGGGAGTACATCACTGCGCTTCAAGCAACGAGTGGCGTTTATACCTTCGGGATAACAAATCCCCTATATTTCAAGATAACCAAACACAATCAGAACCCATTCAACAACAAGTACAACACACTAATATTCCAAATCAGATTCAACCACAATTTGAGGAAGGAACTGGGGATTCACAAATGTTTTCTCAACTTCCGCATTTGGACGACTTTACAGTCTCCGACTGGTCATTTTTTAAGAGTATTTAAATATCAAGTTTGTAAATATTTGAATAATTTGGGTGTAATTTCTTTAAATAATGTTATTAGAGCAGTTGATTATGTATTGTATGATGTATTTGAAGGAACAATTGATGTAGCTGAAAATCATGAAATAAAATTTAATCTTTATTAA |
|
Protein Sequence
|
MDLRTGEYITALQATSGVYTFGITNPLYFKITKHNQNPFNNKYNTLIFQIRFNHNLRKELGIHKCFLNFRIWTTLQSPTGHFLRVFKYQVCKYLNNLGVISLNNVIRAVDYVLYDVFEGTIDVAENHEIKFNLY |
|
NCBI Accession
|
YP_001994910.1
|
|
Location
|
1223-1630 |
|
Gene Name
|
C2 |
|
Protein Name
|
TrAP protein |
|
Coding Region
|
ATGCGATCTTCGTCACCATCCACCAGCCATTGTTCACAGATACCCATCAAAATACAACACCACATCGCCAAGAAGAGGCAGGTGAGGCGTAGAAGGGTCGATCTGGACTGTGGATGCTCATATTACATACACTTAGACTGCATAAATCATGGATTTACGCACAGGGGAGTACATCACTGCGCTTCAAGCAACGAGTGGCGTTTATACCTTCGGGATAACAAATCCCCTATATTTCAAGATAACCAAACACAATCAGAACCCATTCAACAACAAGTACAACACACTAATATTCCAAATCAGATTCAACCACAATTTGAGGAAGGAACTGGGGATTCACAAATGTTTTCTCAACTTCCGCATTTGGACGACTTTACAGTCTCCGACTGGTCATTTTTTAAGAGTATTTAA |
|
Protein Sequence
|
MRSSSPSTSHCSQIPIKIQHHIAKKRQVRRRRVDLDCGCSYYIHLDCINHGFTHRGVHHCASSNEWRLYLRDNKSPIFQDNQTQSEPIQQQVQHTNIPNQIQPQFEEGTGDSQMFSQLPHLDDFTVSDWSFFKSI |
|
NCBI Accession
|
YP_001994911.1
|
|
Location
|
1539-2612 |
|
Gene Name
|
C1 |
|
Protein Name
|
Rep protein |
|
Coding Region
|
ATGCCTCGTTTATTTAAAATATATGCCAAAAATTATTTCCTGACATATCCCAATTGTTATCTCTCTAAAGAGGAAGCACTTTCCCAATTAAAAAACCTAGAAACCCCAACAAATAAAAAATACATCAAAGTTTGCAGAGAATTCCACGAGAATGGGGAACCACATCTCCATGTGCTTATCCAATTCGAAGGCAAATACCAATGTAAAAACCAACGGTTCTTCGACCTGGTATCCCCAAACAGGTCAGCACATTTCCATCCGAACATTCAGGCAGCTAAGAGCTCAACAGATGTCAAGACCTACGTGGAGAAAGACGGAGAATTCATTGATTTTGGAGTTTTCCAAATCGATGGCAGATCAGCTAGAGGAGGTCAGCAATCTGCCAACGACGCATATGCCGAAGCACTCAATTCAGGCAGTAAATCCGAGGCCCTCAATATATTAAAAGAGAAGGCCCCAAAGGACTATATTTTACAATTTCATAATTTAAGTTCAAATTTAGATAGGATTTTTAGTCCTCCTTTAGAAGTTTATGTTTCTCCATTTCTTTCTTCTTCTTTTAATCAAGTTCCAGATGAACTTGAAGAGTGGGTCGCCGAGAACGTCATGGATGCCGCTGCGCGGCCTTGGAGACCGGTAAGTATAGTGATTGAGGGTGACAGCCGGACAGGAAAGACCATGTGGGCCCGTTCCTTAGGCCCACATAATTATTTGTGCGGCCATCTTGACCTCAGTCAAAAAGTATACAGCAATAATGCTTGGTATAACGTCATTGATGACGTCGACCCGCATTATTTAAAGCACTTTAAAGAGTTTATGGGGGCCCAAAGAGACTGGCAGAGCAACACCAAGTATGGGAAGCCCATTCAAATTAAAGGAGGCATTCCCACTATCTTCCTCTGCAATCCAGGCCCACAATCATCATTTAAAGAATATCTCGACGAAGAAAAAAACCAACCATTAAAAAATTGGGCTATTAAGAATGCGATCTTCGTCACCATCCACCAGCCATTGTTCACAGATACCCATCAAAATACAACACCACATCGCCAAGAAGAGGCAGGTGAGGCGTAG |
|
Protein Sequence
|
MPRLFKIYAKNYFLTYPNCYLSKEEALSQLKNLETPTNKKYIKVCREFHENGEPHLHVLIQFEGKYQCKNQRFFDLVSPNRSAHFHPNIQAAKSSTDVKTYVEKDGEFIDFGVFQIDGRSARGGQQSANDAYAEALNSGSKSEALNILKEKAPKDYILQFHNLSSNLDRIFSPPLEVYVSPFLSSSFNQVPDELEEWVAENVMDAAARPWRPVSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSQKVYSNNAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPQSSFKEYLDEEKNQPLKNWAIKNAIFVTIHQPLFTDTHQNTTPHRQEEAGEA |
|
NCBI Accession
|
YP_001994912.1
|
|
Location
|
2168-2461 |
|
Gene Name
|
C4 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGGGAACCACATCTCCATGTGCTTATCCAATTCGAAGGCAAATACCAATGTAAAAACCAACGGTTCTTCGACCTGGTATCCCCAAACAGGTCAGCACATTTCCATCCGAACATTCAGGCAGCTAAGAGCTCAACAGATGTCAAGACCTACGTGGAGAAAGACGGAGAATTCATTGATTTTGGAGTTTTCCAAATCGATGGCAGATCAGCTAGAGGAGGTCAGCAATCTGCCAACGACGCATATGCCGAAGCACTCAATTCAGGCAGTAAATCCGAGGCCCTCAATATATTAA |
|
Protein Sequence
|
MGNHISMCLSNSKANTNVKTNGSSTWYPQTGQHISIRTFRQLRAQQMSRPTWRKTENSLILEFSKSMADQLEEVSNLPTTHMPKHSIQAVNPRPSIY |