Tomato twisted leaf virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_013088455.1 |
| Isolate |
Venezuela |
| Release date |
2021/6/1 |
| Submitter |
Romay,G., Geraud-Pouey,F., Chirinos,D.T., Mahillon,M., Gillis,A., Mahillon,J., Bragard,C. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
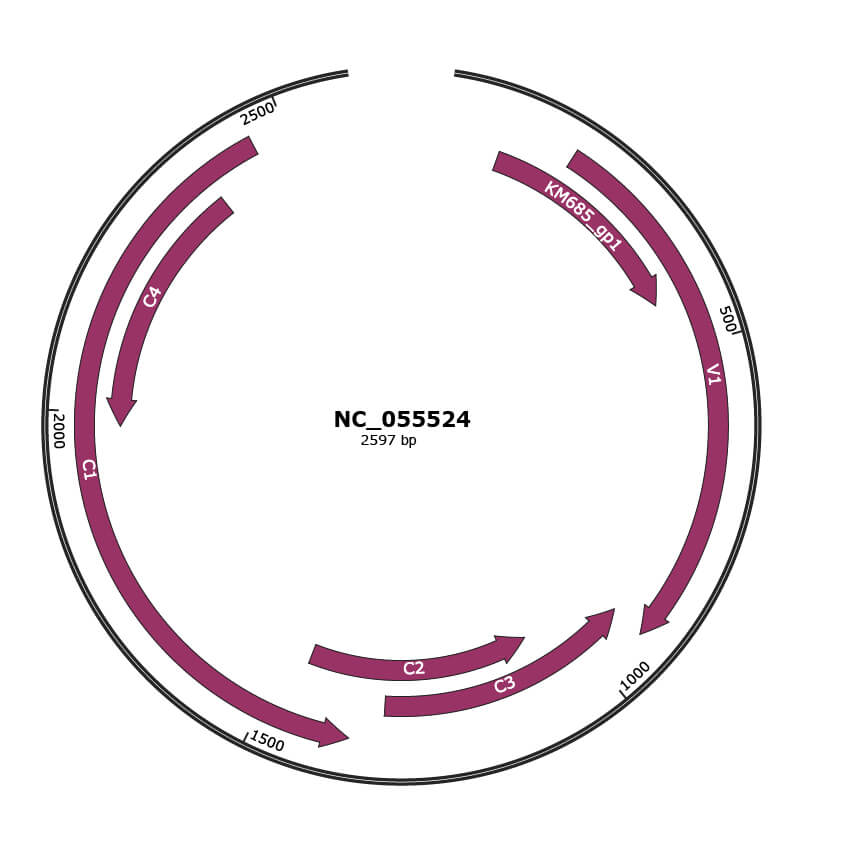
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTGTGGAGTCCCCGCTTTTCTGTGATTATTATTTGAATTAAAGTGTTTTACTTTCATGTGGACCAATGAGAGAGCGTCTGTGGAGCCTAGATATTATGACTTGGTCCCTAAGTTGTGGGCCTATAAAAGAAATGACGCTCTCTCTCTGTCACTTTAATTCGAAATGCCTAAGCGGGATGCCCCATGGCGCACTATTGCGGGGACCTCAAAGGTCTCTCGCTCTTCTACTCAGTCGCCTCGTGGTGGTATGGGCCCTAAGGCAACTGCTTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGAACTTGGAGATCACCTGACGTCCCCAAGGGATGTGAAGGCCCATGTAAGGTTCAGTCTTTTGAGCAGCGTCACGATATCTCTCATGTTGGGAAGGTGATCTGTATATCCGATGTTACTCGTGGTCCTGGTATCACTCACCGTGTTGGGAAACGTTTCTGCGTGAAGTCAGTCTACATTCTAGGCAAGATATGGATGGACGAGAACATCAAACTTAAGAACCACACTAACAGCGTCATGTTCTGGTTAGTTAGGGACAGGAGACCATATGGCACCCCCATGGATTTTGGCCAAGTTTTCAACATGTACGACAACGAGCCCAGTACTGCCACTGTGAAGAACGATCTCCGTGATCGTTTCCAAGTTATGCACAGGTTCTACGCTAAGGTTACCGGTGGTCAGTATGCTAGCAACGAGCAGGCTCTAGTCAGGCGATTTTGGAAGGTCCACAACCATGTGGTCTACAACCATCAGGAAGCTGGGAAGTACGAGAATCACACTGAGAACGCCCTATTATTGTATATGGCATGCACTCATGCCTCTAACCCTGTATATGCTACGTTGAAAATACGTAGCTATTTTTATGACTCGATCAGCAATTAATAAAAGTTGAATTTTATTTCATGATTCTCGTGTACATAATTTACATATGATTTGTCCGTTGCGAAACGAACTGCACGTATTACATTATTAATTCCGATAACACCTATCCTATCTAAATACAATAAAACTAAATATCTAAATCTATTTAAATATGTCGTCCCAGAAGCTCGAACTGATGTCGTCCAGACTTGGAAGTTCAGGAAAGCTTTGTGAAGATTCAACGCCCTCCTGAGGTTGTGGTTGAACCGGATCTGGATGTGGTAAATCCTGAGCGACGTGTGAATTGGATCCTCTACTTGTTGAATCTTGAAATAAAGGGGATTTGGAACCTCCCAGATAAAAACGGAACTCTCTGCCTGACGCACAGTGATGTTCTCCCCGGTGCGTGAATCCATTATTAGAGCAGTTGATGTGCATGAAGATTGAACAGCCGCAGTTCAAGTCAATGCGTCTCCGTCTGAGTGCCCTCTTCTTGGCGATTCTGTGCTGTGCCTTGATAGAGGGGGGCGTCGAGGAAGATGAATTTAGCATTCTTAAGCGTCCACGCCCTCAGAGCTGCATTTTCCTCTTTGTCGAGGAATTCTTTATAGCTGCTCCCCTCTCCTGGATTGCACAGCACGATTGATGGGATACCGCCTTTAATTTGAACTGGCTTTCCGTATTTACAGTTTGACTGCCAGTCCTTTTGAGCGCCAATTAACTCCTTCCAATGCTTTAACTTTAGATAATGCGGAGTTATGTCATCAATGACGTTATACTCCACTTCATTTGAATAGACCCTTGCATTGAAATCTAAATGACCGCTCAAATAATTGTGGGACCCCAATGCACGTGCCCACATGGTCTTCCCTGTACGACTATCACCTTCGACGATGATACTAATAGGTCTCTCCGGCCGCGCAGCGGAACTCCTCCCAAAGTAATCATCAGCCCACTCTTGCATCTCCTCCGGTACGTTAGTGAAAGAGGAGAGTTGAAACGGAGGAACCCATGGTTCTGGAGCCTTTTGAAAAAGACGTTCTAAATTCGATTTTATGTTATGGTAACTGACTATGAACGTCTTTGGATCTCCTGCACGGATAATGTCGATAGCTTCTCCCACACTAGATGCATGGACGGCGTTGTGATACACGTCGTCTTTATTTGACTTTGTTCCGCCAGACACTTTGTATTGTCCGGATTCACAATAATCACCCTCCTTGGTGATGTAGTTCTTGACGGCATTGGCGTCTTTGGCTGCCTGGACATTTGGGTGAAAAGTGGAAGACCTTCTGGGGTGAGTAAGGTCGAAAAACCTAGCATCCTTGATGTTTGACTTGCCGGAGAGCTGGATGAGACAGTGGAGATGTGGGAGACCGTCGGAGTGTTCCTCTCTTGCGACTCTGATGTAGGTTGGTTTGACGATTGACCATGAGAGTGCTTGAAGCATCTCAATAGCCTCATCTTTGGATATGTCGCACTGGGGATATGTTAAAAAGATATTTCTGGCTTGTAAGCGAAATGAATTAGGGTTTCGTGGCATATTTGTAAATATGAGAGGGGACTCCAGCTGAGGACTCCAGGGAGAGCTCTCAACTTCTGTGCTATATGCTGGAGTCCTGGAGTCCCATTTATACTAGAAGTCTCTGGGGTTAGATCAGCCACGTGGCGGCCATCCGCAATAATATT
Gene Information
|
NCBI Accession
|
YP_010087241.1
|
|
Location
|
85-426 |
|
Protein Name
|
hypothetical protein |
|
Coding Region
|
ATGAGAGAGCGTCTGTGGAGCCTAGATATTATGACTTGGTCCCTAAGTTGTGGGCCTATAAAAGAAATGACGCTCTCTCTCTGTCACTTTAATTCGAAATGCCTAAGCGGGATGCCCCATGGCGCACTATTGCGGGGACCTCAAAGGTCTCTCGCTCTTCTACTCAGTCGCCTCGTGGTGGTATGGGCCCTAAGGCAACTGCTTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGAACTTGGAGATCACCTGACGTCCCCAAGGGATGTGAAGGCCCATGTAAGGTTCAGTCTTTTGAGCAGCGTCACGATATCTCTCATGTTGGGAAGGTGA |
|
Protein Sequence
|
MRERLWSLDIMTWSLSCGPIKEMTLSLCHFNSKCLSGMPHGALLRGPQRSLALLLSRLVVVWALRQLLGLTGPCTGSPGSTELGDHLTSPRDVKAHVRFSLLSSVTISLMLGR |
|
NCBI Accession
|
YP_010087242.1
|
|
Location
|
183-929 |
|
Gene Name
|
V1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGGGATGCCCCATGGCGCACTATTGCGGGGACCTCAAAGGTCTCTCGCTCTTCTACTCAGTCGCCTCGTGGTGGTATGGGCCCTAAGGCAACTGCTTGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGAACTTGGAGATCACCTGACGTCCCCAAGGGATGTGAAGGCCCATGTAAGGTTCAGTCTTTTGAGCAGCGTCACGATATCTCTCATGTTGGGAAGGTGATCTGTATATCCGATGTTACTCGTGGTCCTGGTATCACTCACCGTGTTGGGAAACGTTTCTGCGTGAAGTCAGTCTACATTCTAGGCAAGATATGGATGGACGAGAACATCAAACTTAAGAACCACACTAACAGCGTCATGTTCTGGTTAGTTAGGGACAGGAGACCATATGGCACCCCCATGGATTTTGGCCAAGTTTTCAACATGTACGACAACGAGCCCAGTACTGCCACTGTGAAGAACGATCTCCGTGATCGTTTCCAAGTTATGCACAGGTTCTACGCTAAGGTTACCGGTGGTCAGTATGCTAGCAACGAGCAGGCTCTAGTCAGGCGATTTTGGAAGGTCCACAACCATGTGGTCTACAACCATCAGGAAGCTGGGAAGTACGAGAATCACACTGAGAACGCCCTATTATTGTATATGGCATGCACTCATGCCTCTAACCCTGTATATGCTACGTTGAAAATACGTAGCTATTTTTATGACTCGATCAGCAATTAA |
|
Protein Sequence
|
MPKRDAPWRTIAGTSKVSRSSTQSPRGGMGPKATAWVNRPMYRKPRIYRTWRSPDVPKGCEGPCKVQSFEQRHDISHVGKVICISDVTRGPGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMYDNEPSTATVKNDLRDRFQVMHRFYAKVTGGQYASNEQALVRRFWKVHNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRSYFYDSISN |
|
NCBI Accession
|
YP_010087243.1
|
|
Location
|
926-1324 |
|
Gene Name
|
C3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACCGGGGAGAACATCACTGTGCGTCAGGCAGAGAGTTCCGTTTTTATCTGGGAGGTTCCAAATCCCCTTTATTTCAAGATTCAACAAGTAGAGGATCCAATTCACACGTCGCTCAGGATTTACCACATCCAGATCCGGTTCAACCACAACCTCAGGAGGGCGTTGAATCTTCACAAAGCTTTCCTGAACTTCCAAGTCTGGACGACATCAGTTCGAGCTTCTGGGACGACATATTTAAATAGATTTAGATATTTAGTTTTATTGTATTTAGATAGGATAGGTGTTATCGGAATTAATAATGTAATACGTGCAGTTCGTTTCGCAACGGACAAATCATATGTAAATTATGTACACGAGAATCATGAAATAAAATTCAACTTTTATTAA |
|
Protein Sequence
|
MDSRTGENITVRQAESSVFIWEVPNPLYFKIQQVEDPIHTSLRIYHIQIRFNHNLRRALNLHKAFLNFQVWTTSVRASGTTYLNRFRYLVLLYLDRIGVIGINNVIRAVRFATDKSYVNYVHENHEIKFNFY |
|
NCBI Accession
|
YP_010087244.1
|
|
Location
|
1071-1460 |
|
Gene Name
|
C2 |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGCTAAATTCATCTTCCTCGACGCCCCCCTCTATCAAGGCACAGCACAGAATCGCCAAGAAGAGGGCACTCAGACGGAGACGCATTGACTTGAACTGCGGCTGTTCAATCTTCATGCACATCAACTGCTCTAATAATGGATTCACGCACCGGGGAGAACATCACTGTGCGTCAGGCAGAGAGTTCCGTTTTTATCTGGGAGGTTCCAAATCCCCTTTATTTCAAGATTCAACAAGTAGAGGATCCAATTCACACGTCGCTCAGGATTTACCACATCCAGATCCGGTTCAACCACAACCTCAGGAGGGCGTTGAATCTTCACAAAGCTTTCCTGAACTTCCAAGTCTGGACGACATCAGTTCGAGCTTCTGGGACGACATATTTAAATAG |
|
Protein Sequence
|
MLNSSSSTPPSIKAQHRIAKKRALRRRRIDLNCGCSIFMHINCSNNGFTHRGEHHCASGREFRFYLGGSKSPLFQDSTSRGSNSHVAQDLPHPDPVQPQPQEGVESSQSFPELPSLDDISSSFWDDIFK |
|
NCBI Accession
|
YP_010087245.1
|
|
Location
|
1372-2451 |
|
Gene Name
|
C1 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCACGAAACCCTAATTCATTTCGCTTACAAGCCAGAAATATCTTTTTAACATATCCCCAGTGCGACATATCCAAAGATGAGGCTATTGAGATGCTTCAAGCACTCTCATGGTCAATCGTCAAACCAACCTACATCAGAGTCGCAAGAGAGGAACACTCCGACGGTCTCCCACATCTCCACTGTCTCATCCAGCTCTCCGGCAAGTCAAACATCAAGGATGCTAGGTTTTTCGACCTTACTCACCCCAGAAGGTCTTCCACTTTTCACCCAAATGTCCAGGCAGCCAAAGACGCCAATGCCGTCAAGAACTACATCACCAAGGAGGGTGATTATTGTGAATCCGGACAATACAAAGTGTCTGGCGGAACAAAGTCAAATAAAGACGACGTGTATCACAACGCCGTCCATGCATCTAGTGTGGGAGAAGCTATCGACATTATCCGTGCAGGAGATCCAAAGACGTTCATAGTCAGTTACCATAACATAAAATCGAATTTAGAACGTCTTTTTCAAAAGGCTCCAGAACCATGGGTTCCTCCGTTTCAACTCTCCTCTTTCACTAACGTACCGGAGGAGATGCAAGAGTGGGCTGATGATTACTTTGGGAGGAGTTCCGCTGCGCGGCCGGAGAGACCTATTAGTATCATCGTCGAAGGTGATAGTCGTACAGGGAAGACCATGTGGGCACGTGCATTGGGGTCCCACAATTATTTGAGCGGTCATTTAGATTTCAATGCAAGGGTCTATTCAAATGAAGTGGAGTATAACGTCATTGATGACATAACTCCGCATTATCTAAAGTTAAAGCATTGGAAGGAGTTAATTGGCGCTCAAAAGGACTGGCAGTCAAACTGTAAATACGGAAAGCCAGTTCAAATTAAAGGCGGTATCCCATCAATCGTGCTGTGCAATCCAGGAGAGGGGAGCAGCTATAAAGAATTCCTCGACAAAGAGGAAAATGCAGCTCTGAGGGCGTGGACGCTTAAGAATGCTAAATTCATCTTCCTCGACGCCCCCCTCTATCAAGGCACAGCACAGAATCGCCAAGAAGAGGGCACTCAGACGGAGACGCATTGA |
|
Protein Sequence
|
MPRNPNSFRLQARNIFLTYPQCDISKDEAIEMLQALSWSIVKPTYIRVAREEHSDGLPHLHCLIQLSGKSNIKDARFFDLTHPRRSSTFHPNVQAAKDANAVKNYITKEGDYCESGQYKVSGGTKSNKDDVYHNAVHASSVGEAIDIIRAGDPKTFIVSYHNIKSNLERLFQKAPEPWVPPFQLSSFTNVPEEMQEWADDYFGRSSAARPERPISIIVEGDSRTGKTMWARALGSHNYLSGHLDFNARVYSNEVEYNVIDDITPHYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGSSYKEFLDKEENAALRAWTLKNAKFIFLDAPLYQGTAQNRQEEGTQTETH |
|
NCBI Accession
|
YP_010087246.1
|
|
Location
|
1980-2372 |
|
Gene Name
|
C4 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGAGGCTATTGAGATGCTTCAAGCACTCTCATGGTCAATCGTCAAACCAACCTACATCAGAGTCGCAAGAGAGGAACACTCCGACGGTCTCCCACATCTCCACTGTCTCATCCAGCTCTCCGGCAAGTCAAACATCAAGGATGCTAGGTTTTTCGACCTTACTCACCCCAGAAGGTCTTCCACTTTTCACCCAAATGTCCAGGCAGCCAAAGACGCCAATGCCGTCAAGAACTACATCACCAAGGAGGGTGATTATTGTGAATCCGGACAATACAAAGTGTCTGGCGGAACAAAGTCAAATAAAGACGACGTGTATCACAACGCCGTCCATGCATCTAGTGTGGGAGAAGCTATCGACATTATCCGTGCAGGAGATCCAAAGACGTTCATAG |
|
Protein Sequence
|
MRLLRCFKHSHGQSSNQPTSESQERNTPTVSHISTVSSSSPASQTSRMLGFSTLLTPEGLPLFTQMSRQPKTPMPSRTTSPRRVIIVNPDNTKCLAEQSQIKTTCITTPSMHLVWEKLSTLSVQEIQRRS |