Tomato mottle Taino virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000838745.1 |
| Release date |
2015/2/12 |
| Submitter |
Ramos,P.L., Guerra,O., Peral,P., Oramas,P., Guevara,R.G., Rivera-Bustamante,R., Guevara-Gonzalez,R., Peral,R. |
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
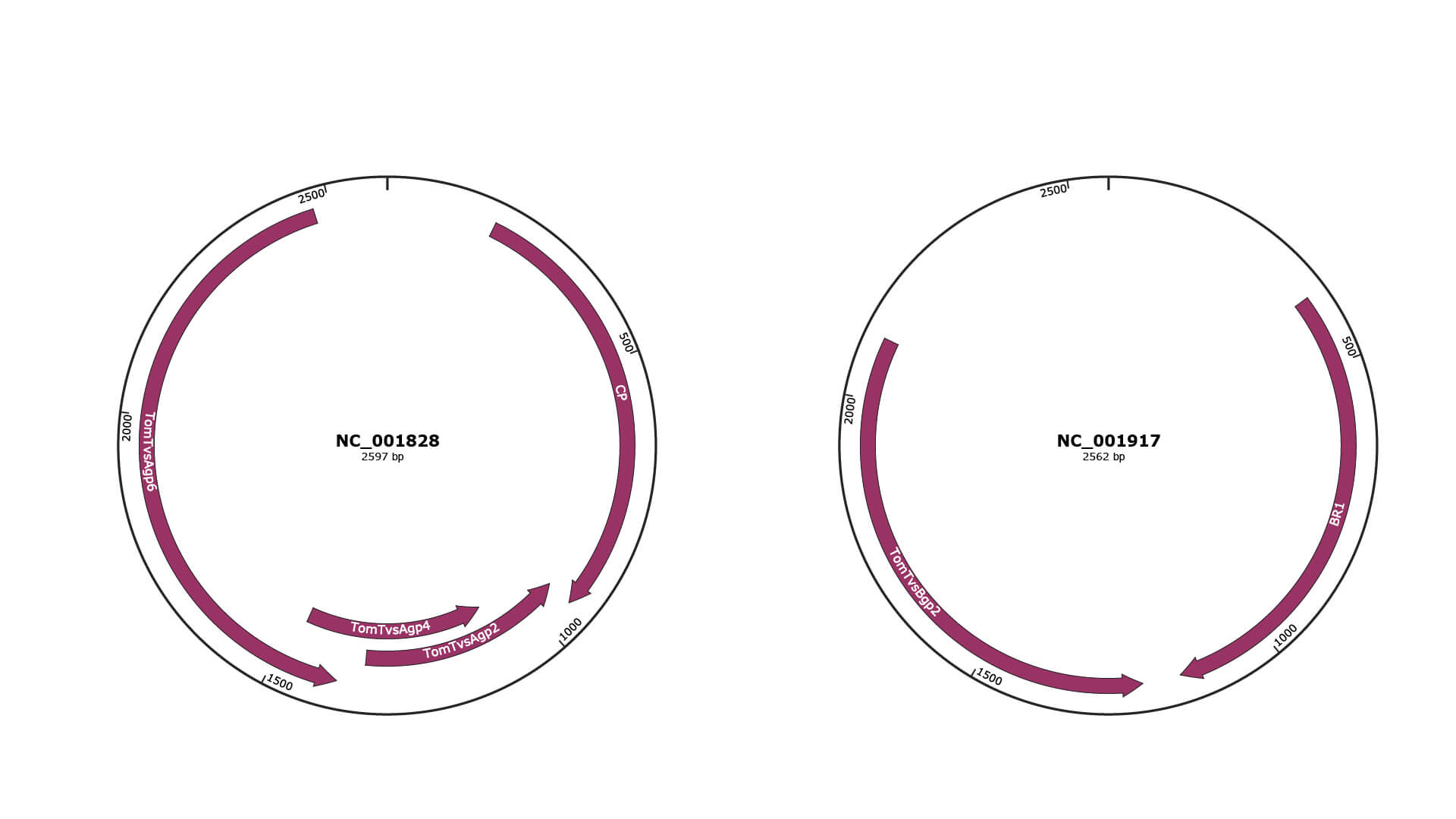
JBrowse
Genome
GGCCATCCGCTATAATATTACCGGATGGCCGCGCGAAATTTCCCCCCTTTTTCGGGTTTGGGCTCTCTTTAATTTGCACGACCAATCATAATGCGTCTTCTAGGCTTAGTTATGTACAACAACTTGGGCCTGAAGTTGTTGGGCCTTTATAAATTAAAGAGTATTCGGCCCACTATCTTTAATTCAAAATGCCTAAGCGCGATCGTACATGGCGTTCTATCGCGGGAACCTCAAAGGTTAGCCGCAATGCTAACTACTCGCCTCGTACAGGAAGTGGGCCGATAGGTAACAAGGCATCCGAATGGGTTAATAGGCCCATGTACAGGAAGCCCAAGATCTACCGGATGATGAGGACCCCCGATGTGCCCAGAGGATGTGAAGGCCCATGTAAGGTCCAGTCCTACGAACAGCGCCATGATATTTCACATGTCGGGAAGGTCATGTGTGTCTCTGACGTGACACGTGGTAATGGCATTACCCATCGTGTGGGCAAGCGCTTCTGTGTTAAGTCTGTGTATATTCTAGGCAAGATATGGATGGATGAGAACATCAAACTGAAGAACCACACGAACAGCGTCATGTTTTGGCTAGTACGAGACCGGAGACCTTATGGAACTCCCATGGATTTCGGACAGGTGTTCAACATGTACGACAACGAGCCCAGTACTGCCACTGTGAAGAACGACCTCCGGGATCGTTACCAAGTTATGCACAGGTTCCATACTAAGGTGACTGGTGGTCAGTATGCGAGCAACGAGCAGGCTCTGGTTCGACGGTTCTGGAAAGTGAACAACCACGTGGTGTACAATCACCAGGAAGCCGCGAAGTACGAGAATCATACGGAGAACGCCCTATTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTATATGCAACGCTTAAGATCCGGATCTATTTTTATGATTCGATCTTGAATTAATAAAATTTGAATTTTATTGAATGATTCTCCAGTACATAATTTACATATGCTCTGTTTGTTGCGAATCGAACAGCTCTAATTACATTGTTAATTGAAATGACGCCTATCTGATCTAAATACATATTAACTAAAAATCTAAACCTAGCTAAATATGTTGATCCAGAAGCTGTCGTCGATGTCGTCCAGACTTGGAAGTTCAGGTAGGCTTTGTGGAGATGCAACGCTCTCCTCAGGTTGTGGTTGAATCGTATTTGTGCGTGGTATACCCTGGTTCTGGTGAACAGCAAGTCCTCTACTCTGTACATCTTGAAATAAAGGGGATTTTGTATTTCCCAGATATACACGCCATTCTCCGCCTGATGTGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGTCCCGCACAGTTTAAGTGGAAGTATATGGAGCACCCGCACTGCAGATCAACACGCCGTCTCCTGATTGCCCTCTTCTTGCCTTGCCTGTGTGCTATCTTGATAGAGGGGGGTTGTGAGGGTGATGAACATCGCATTCTTGATAGTCCAGTCTCTGAGAGATGTGTTCTCGTCTTTGCTGAGGAAGTCTTTATAGCTGGCACCCTCACCAGGATTGCAAAGCACGATTGCTGGGATTCCGCCTTTAATTTGAACTGGCTTACCGTACTTGCAGTTTGATTGCCAATCTCTCTGGGCCCCCAGCAATTCTTTCCAGTGCTTTAGCTTTAGATAATGCGGTGCGATGTCATCAATGACGTTATACTGCACGTCGTTTGAATAGACCCTGGTATTGAAGTCCAAATGTCCACTCAGATAATTATGTGGGCCTAACGCACGCGCCCACATCGTCTTCCCTGTCCTTGAATCACCTTCTATGACAATACTCATGGGTCTATTTGGCCGCGCAGCGGAACCAGCTCCAAAATAAACATCCGCCCACTCTTGCATCTCATCGGGAACGTTAGTGAAAGACGAGAGGGGAAACGGAGGAACCCATGGTTCCGGAGCCTTGGCGAATATTCTTTCTAGATTTGAGCGGATGTTATGATTATGCAGGACAAAATCTTTTGGCTGTTCTTCTTTTAAAACTGCCATGGCAGACTGAACATTTCCTGCATTTAACGCCTTTGCATATGAATCGTTAGCTGATTGTTGACCTCCCCTAGCAGACCTACCGTCGATCTGGAATTCTCCCCATTCCAGTGTGTCTCCGTCCTTGGTAATGTATGTTTTGACGTCGGAGCTGGATTTAGCTCCCTGTATGTTCGGATGGAAATGTGCTGACCTGGTTGGGGAGACCACATCGAAGAATCTGTTATTCGTGCAGTTGTATTTGCCTTCGAATTGGACAAGCACGTGGAGATGAGGTTCCCCATTTTCATGCAACTCTCTGCAGATCTTGATGAATTTCTTGTCTACTGGTGTGTTTAGGTTTTGTATTTGGGAAAGTGCTTCTTCTTTACTAAGGGAACACTGTGGATACGTGAGGAAATAATTTTTGGCTTTAACTGAGAAAGAACCCTTCCGTGGCATATTTGTAAATATATGATGTTCCCCCAATTGCTCTCTCTCACAAAACTCATATCAATTGGGGGAACTGGGGGAACATTTATACTACAACCCTCTATAGAACTTTTAATCTCATTCATACACGTGGC
GGCCATCCGCTATAATATTACCGGATGGCCGCGCCCGCCCCCCCTCTCTCCACGCGCGCATCTTTTGTTGTTGTTCCACGCTCCTTCCTATTGGTACGTGTCCTTCACTTTCTCATCTTTTGAGTGGCCTTTAATTCAAATTGAAGGATAAAACTTTCCTCGCGTGATTTTCTTTTTCGAATTTATTAACACGCGATGAATTATTTATGTCCTACYGATTATGTGAAGGACGTGGCTTTATTTGGACCATGCTGCTGAGTTTATTTGCGATTGAAGTCTATCGATAGTCTATATATTTAACCTGTCAGTTAWGTCTGTTTATCCAACTCAGCAGCATACCACGTTTATATTGTTAGCTCTGTTTTATTTATATTYACAGCATGATAATGTATCAGTCAAAAGGTAAACGTGGTTTTCATATGACTAACCGACGATATAACTCTCGTTATTCTATGTTTAACCGTATGACCGCTATTAAACGACATGATGGAAAACGTCGAGGAGGAATGTTATCAAAGCCCACTGATGAGCCCAAGATGACAGCCCAACGTATACATGAGAATCAGTATGGGCCAGATTTTGTCCTGGCCCATAATTCAGCTATCTCAACGTTTATCAGCTACCCTTGCTTGGGCAAAATCGAACCGAACCGGAGCAGGTCCTATATCAAACTGAAACGCCTACGTTTCAAAGGGACTGTGAAGATTGAACGTGTCCAAATGGACATGAACATGGACGGATCTGCCCCTAAGGTTGAAGGAGTGTTCTCACTCGTCGTGGTTATGGATCGTAAACCACATCTTAGCGGGTCTGGTTGTCTGCATACATTTGACGAACTATTTGGTGCAAGGATCCATAGCCATGGTACTCTTAACATAGTACCTTCTTTGAAAGACCGGTTTTATATAAGACACGTGTTCAAACGTGTATTATCTGTTGAAAAGGATACGCTTATGGTGGACGTGGAAGGTACTACTGCTCTTTCAACCAGGCGTTTCAATTGCTGGGCTACGTTCAAGGATCTTGATCGTGATTCATGCAAAGGTGTATATGACAACGTCAGCAAGAACGCCATTTTAGTTTATTATTGTTGGATGTCAGATACTGTATCTAAGGCATCCTCTTTTGTATCGTTTGACCTTGATTACGTCGGATGATTAATGCGCAATAATAAACTAATATATTAATAGACAGTCTAACATCGAGTAACTAAACATGAATATTATTTTAATGATTTGGGCTGAGAAGCCTTACAATTACTATTAATACATTCCTGGACTGTCGTCCTAACTAATTCATTTAACTGCCCCATTGACATGGTAATGCTCGATTCAGCTCTCTGGGCTCCCACAATAGAAGCAGACTCTCCTGGGTCCATAACAGCTGTTCCTAGTCTGTTTAGGTGTTTGTATGGGTGGAGTTCGTTTTCCACCTCCGAGTCCGCATCTGATAGACCTGGGCCTACTGTACTTCTTGAAGCCCACGACTCACCAGGCCTGATTTCAATTGGGCCTCGAAGCCCAATTCTGGACATGGACGCGCATCTAATGGGCTTCCTCTCCCATTTTCCGTAGTCCACATGGGAAAAGTCCACATCTTTGTCCGTGAACTGTTTGGACAGGATCTTTACTGTTGGTGCCCGGAAGGGGATGTCTACTGAGTGTTTGGCTGTGGACAATTTCAGCTTCCCCTTGAACTTAGCGAAGTGGGTCCGCTGATGAACATTCGTATCGCAAACCCTGTAGTACAACTTCCATGGAATTGGGTCTTTCACGGAGAAGAATGAAGCTGAAAAATAGTGGAGATCTATGTTGCACCTGATCGGAAATGTCCATGACGCCTGTAATGACTCATTCTCCGTCATCCTTTTATCGTGAATCTCCACTATTACCGACCCGGTGGCGTTTATTGGTACCTGCTGTCTGTACTCTATGACGCAGTGGTCAATCTTCATGCAGCTACGACTGAGTCTAGCTGTCAACTGAGACGCCGTGGACGGAAATTGCAGTATTATCTCAGTTAGGTCATGAGAAAGCTGATATTCGTCGCGATGCGACTCTATGTAATTAAATGCGCTTGGAGGATTAACTAACTGAGAATCCATATAATGAAATAAAGGCCGCGCAGCGGCACCAACAGACGAAATTTAACCGACAGGGAGATGAACAAGTTATGAAACGGCAGTTTCGTTCTCGAAGAAGATGAACATGTATCCCTCTATATTTTATCTAAGAATTCAGCTGTGCTGAAAGTTATGACTATGCGGAGAGAATATGATTAAAACGATCAGGAATCTGATTGTTTGAGAAAGAAAAGAGAGATGCTGGAGAAATCTAGAGAGAAGTGATTATGAAAGCACTTGTATATGAACTGAAAGAACTAGGGTTCATGGGGATTTATATTGGTAAAGTGTTCAGCTCATATGATATGAGGGCATATTTGTAAATATAGAGTGTTCCCCCGAATGCTCTCTCTCACAAAACTCATATCAATTGGGGGAACTGGGGGAACATATATACTAGAACCCTCTATAGAACTTTTAATCTCATTCACACACGTGGC
Gene Information
|
NCBI Accession
|
NP_044922.1
|
|
Location
|
189-944 |
|
Gene Name
|
CP |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGCGATCGTACATGGCGTTCTATCGCGGGAACCTCAAAGGTTAGCCGCAATGCTAACTACTCGCCTCGTACAGGAAGTGGGCCGATAGGTAACAAGGCATCCGAATGGGTTAATAGGCCCATGTACAGGAAGCCCAAGATCTACCGGATGATGAGGACCCCCGATGTGCCCAGAGGATGTGAAGGCCCATGTAAGGTCCAGTCCTACGAACAGCGCCATGATATTTCACATGTCGGGAAGGTCATGTGTGTCTCTGACGTGACACGTGGTAATGGCATTACCCATCGTGTGGGCAAGCGCTTCTGTGTTAAGTCTGTGTATATTCTAGGCAAGATATGGATGGATGAGAACATCAAACTGAAGAACCACACGAACAGCGTCATGTTTTGGCTAGTACGAGACCGGAGACCTTATGGAACTCCCATGGATTTCGGACAGGTGTTCAACATGTACGACAACGAGCCCAGTACTGCCACTGTGAAGAACGACCTCCGGGATCGTTACCAAGTTATGCACAGGTTCCATACTAAGGTGACTGGTGGTCAGTATGCGAGCAACGAGCAGGCTCTGGTTCGACGGTTCTGGAAAGTGAACAACCACGTGGTGTACAATCACCAGGAAGCCGCGAAGTACGAGAATCATACGGAGAACGCCCTATTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTATATGCAACGCTTAAGATCCGGATCTATTTTTATGATTCGATCTTGAATTAA |
|
Protein Sequence
|
MPKRDRTWRSIAGTSKVSRNANYSPRTGSGPIGNKASEWVNRPMYRKPKIYRMMRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCVSDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMYDNEPSTATVKNDLRDRYQVMHRFHTKVTGGQYASNEQALVRRFWKVNNHVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSILN |
|
NCBI Accession
|
NP_044923.1
|
|
Location
|
941-1339 |
|
Protein Name
|
AL3 protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCACATCAGGCGGAGAATGGCGTGTATATCTGGGAAATACAAAATCCCCTTTATTTCAAGATGTACAGAGTAGAGGACTTGCTGTTCACCAGAACCAGGGTATACCACGCACAAATACGATTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGACGACAGCTTCTGGATCAACATATTTAGCTAGGTTTAGATTTTTAGTTAATATGTATTTAGATCAGATAGGCGTCATTTCAATTAACAATGTAATTAGAGCTGTTCGATTCGCAACAAACAGAGCATATGTAAATTATGTACTGGAGAATCATTCAATAAAATTCAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGELITAHQAENGVYIWEIQNPLYFKMYRVEDLLFTRTRVYHAQIRFNHNLRRALHLHKAYLNFQVWTTSTTASGSTYLARFRFLVNMYLDQIGVISINNVIRAVRFATNRAYVNYVLENHSIKFKFY |
|
NCBI Accession
|
NP_044924.1
|
|
Location
|
1086-1475 |
|
Protein Name
|
transactivator protein |
|
Coding Region
|
ATGCGATGTTCATCACCCTCACAACCCCCCTCTATCAAGATAGCACACAGGCAAGGCAAGAAGAGGGCAATCAGGAGACGGCGTGTTGATCTGCAGTGCGGGTGCTCCATATACTTCCACTTAAACTGTGCGGGACATGGATTCACGCACAGGGGAACTCATCACTGCACATCAGGCGGAGAATGGCGTGTATATCTGGGAAATACAAAATCCCCTTTATTTCAAGATGTACAGAGTAGAGGACTTGCTGTTCACCAGAACCAGGGTATACCACGCACAAATACGATTCAACCACAACCTGAGGAGAGCGTTGCATCTCCACAAAGCCTACCTGAACTTCCAAGTCTGGACGACATCGACGACAGCTTCTGGATCAACATATTTAGCTAG |
|
Protein Sequence
|
MRCSSPSQPPSIKIAHRQGKKRAIRRRRVDLQCGCSIYFHLNCAGHGFTHRGTHHCTSGGEWRVYLGNTKSPLFQDVQSRGLAVHQNQGIPRTNTIQPQPEESVASPQSLPELPSLDDIDDSFWINIFS |
|
NCBI Accession
|
NP_044925.1
|
|
Location
|
1387-2472 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGCCACGGAAGGGTTCTTTCTCAGTTAAAGCCAAAAATTATTTCCTCACGTATCCACAGTGTTCCCTTAGTAAAGAAGAAGCACTTTCCCAAATACAAAACCTAAACACACCAGTAGACAAGAAATTCATCAAGATCTGCAGAGAGTTGCATGAAAATGGGGAACCTCATCTCCACGTGCTTGTCCAATTCGAAGGCAAATACAACTGCACGAATAACAGATTCTTCGATGTGGTCTCCCCAACCAGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAAACATACATTACCAAGGACGGAGACACACTGGAATGGGGAGAATTCCAGATCGACGGTAGGTCTGCTAGGGGAGGTCAACAATCAGCTAACGATTCATATGCAAAGGCGTTAAATGCAGGAAATGTTCAGTCTGCCATGGCAGTTTTAAAAGAAGAACAGCCAAAAGATTTTGTCCTGCATAATCATAACATCCGCTCAAATCTAGAAAGAATATTCGCCAAGGCTCCGGAACCATGGGTTCCTCCGTTTCCCCTCTCGTCTTTCACTAACGTTCCCGATGAGATGCAAGAGTGGGCGGATGTTTATTTTGGAGCTGGTTCCGCTGCGCGGCCAAATAGACCCATGAGTATTGTCATAGAAGGTGATTCAAGGACAGGGAAGACGATGTGGGCGCGTGCGTTAGGCCCACATAATTATCTGAGTGGACATTTGGACTTCAATACCAGGGTCTATTCAAACGACGTGCAGTATAACGTCATTGATGACATCGCACCGCATTATCTAAAGCTAAAGCACTGGAAAGAATTGCTGGGGGCCCAGAGAGATTGGCAATCAAACTGCAAGTACGGTAAGCCAGTTCAAATTAAAGGCGGAATCCCAGCAATCGTGCTTTGCAATCCTGGTGAGGGTGCCAGCTATAAAGACTTCCTCAGCAAAGACGAGAACACATCTCTCAGAGACTGGACTATCAAGAATGCGATGTTCATCACCCTCACAACCCCCCTCTATCAAGATAGCACACAGGCAAGGCAAGAAGAGGGCAATCAGGAGACGGCGTGTTGA |
|
Protein Sequence
|
MPRKGSFSVKAKNYFLTYPQCSLSKEEALSQIQNLNTPVDKKFIKICRELHENGEPHLHVLVQFEGKYNCTNNRFFDVVSPTRSAHFHPNIQGAKSSSDVKTYITKDGDTLEWGEFQIDGRSARGGQQSANDSYAKALNAGNVQSAMAVLKEEQPKDFVLHNHNIRSNLERIFAKAPEPWVPPFPLSSFTNVPDEMQEWADVYFGAGSAARPNRPMSIVIEGDSRTGKTMWARALGPHNYLSGHLDFNTRVYSNDVQYNVIDDIAPHYLKLKHWKELLGAQRDWQSNCKYGKPVQIKGGIPAIVLCNPGEGASYKDFLSKDENTSLRDWTIKNAMFITLTTPLYQDSTQARQEEGNQETAC |
|
NCBI Accession
|
NP_047198.1
|
|
Location
|
381-1157 |
|
Gene Name
|
BR1 |
|
Protein Name
|
nuclear shuttle |
|
Coding Region
|
ATGATAATGTATCAGTCAAAAGGTAAACGTGGTTTTCATATGACTAACCGACGATATAACTCTCGTTATTCTATGTTTAACCGTATGACCGCTATTAAACGACATGATGGAAAACGTCGAGGAGGAATGTTATCAAAGCCCACTGATGAGCCCAAGATGACAGCCCAACGTATACATGAGAATCAGTATGGGCCAGATTTTGTCCTGGCCCATAATTCAGCTATCTCAACGTTTATCAGCTACCCTTGCTTGGGCAAAATCGAACCGAACCGGAGCAGGTCCTATATCAAACTGAAACGCCTACGTTTCAAAGGGACTGTGAAGATTGAACGTGTCCAAATGGACATGAACATGGACGGATCTGCCCCTAAGGTTGAAGGAGTGTTCTCACTCGTCGTGGTTATGGATCGTAAACCACATCTTAGCGGGTCTGGTTGTCTGCATACATTTGACGAACTATTTGGTGCAAGGATCCATAGCCATGGTACTCTTAACATAGTACCTTCTTTGAAAGACCGGTTTTATATAAGACACGTGTTCAAACGTGTATTATCTGTTGAAAAGGATACGCTTATGGTGGACGTGGAAGGTACTACTGCTCTTTCAACCAGGCGTTTCAATTGCTGGGCTACGTTCAAGGATCTTGATCGTGATTCATGCAAAGGTGTATATGACAACGTCAGCAAGAACGCCATTTTAGTTTATTATTGTTGGATGTCAGATACTGTATCTAAGGCATCCTCTTTTGTATCGTTTGACCTTGATTACGTCGGATGA |
|
Protein Sequence
|
MIMYQSKGKRGFHMTNRRYNSRYSMFNRMTAIKRHDGKRRGGMLSKPTDEPKMTAQRIHENQYGPDFVLAHNSAISTFISYPCLGKIEPNRSRSYIKLKRLRFKGTVKIERVQMDMNMDGSAPKVEGVFSLVVVMDRKPHLSGSGCLHTFDELFGARIHSHGTLNIVPSLKDRFYIRHVFKRVLSVEKDTLMVDVEGTTALSTRRFNCWATFKDLDRDSCKGVYDNVSKNAILVYYCWMSDTVSKASSFVSFDLDYVG |
|
NCBI Accession
|
NP_047199.1
|
|
Location
|
1223-2104 |
|
Protein Name
|
cell-to-cell movement protein |
|
Coding Region
|
ATGGATTCTCAGTTAGTTAATCCTCCAAGCGCATTTAATTACATAGAGTCGCATCGCGACGAATATCAGCTTTCTCATGACCTAACTGAGATAATACTGCAATTTCCGTCCACGGCGTCTCAGTTGACAGCTAGACTCAGTCGTAGCTGCATGAAGATTGACCACTGCGTCATAGAGTACAGACAGCAGGTACCAATAAACGCCACCGGGTCGGTAATAGTGGAGATTCACGATAAAAGGATGACGGAGAATGAGTCATTACAGGCGTCATGGACATTTCCGATCAGGTGCAACATAGATCTCCACTATTTTTCAGCTTCATTCTTCTCCGTGAAAGACCCAATTCCATGGAAGTTGTACTACAGGGTTTGCGATACGAATGTTCATCAGCGGACCCACTTCGCTAAGTTCAAGGGGAAGCTGAAATTGTCCACAGCCAAACACTCAGTAGACATCCCCTTCCGGGCACCAACAGTAAAGATCCTGTCCAAACAGTTCACGGACAAAGATGTGGACTTTTCCCATGTGGACTACGGAAAATGGGAGAGGAAGCCCATTAGATGCGCGTCCATGTCCAGAATTGGGCTTCGAGGCCCAATTGAAATCAGGCCTGGTGAGTCGTGGGCTTCAAGAAGTACAGTAGGCCCAGGTCTATCAGATGCGGACTCGGAGGTGGAAAACGAACTCCACCCATACAAACACCTAAACAGACTAGGAACAGCTGTTATGGACCCAGGAGAGTCTGCTTCTATTGTGGGAGCCCAGAGAGCTGAATCGAGCATTACCATGTCAATGGGGCAGTTAAATGAATTAGTTAGGACGACAGTCCAGGAATGTATTAATAGTAATTGTAAGGCTTCTCAGCCCAAATCATTAAAATAA |
|
Protein Sequence
|
MDSQLVNPPSAFNYIESHRDEYQLSHDLTEIILQFPSTASQLTARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDKRMTENESLQASWTFPIRCNIDLHYFSASFFSVKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGKWERKPIRCASMSRIGLRGPIEIRPGESWASRSTVGPGLSDADSEVENELHPYKHLNRLGTAVMDPGESASIVGAQRAESSITMSMGQLNELVRTTVQECINSNCKASQPKSLK |